复现心得与代码复盘:多模态大模型调用+机械臂抓取(一)
基于大模型的智能体机械臂抓取实验设计【实物】【仿真】【UI界面】【多种可切换大模型】【本地部署+API调用】面向大模型下的机械臂控制教学实验设计,包含实物控制、仿真平台和交互界面三大模块。 通过多种类大模型实现自然语言理解、目标检测和动作编排,支持不同部署模式的大模型灵活切换,创造出一个简单的具身智能体。实验的最终目标是向终端给出非固定的文本或语音指令后,机械臂可以按要求完成相应基础动作和目标抓取
本来是做的同济子豪兄的代码复现,将其代码复现到自己的机械臂上,并借此快速入门,后来又在它的框架基础上加上了很多改进(比如添加不同的模型切换、部署本地模型等等),又做了仿真和UI界面,基本上算是形成一个完整的体系了,这里简单介绍一下我修改后的代码。
github代码即将上传:Agent_Dobot/README.md at main · ZZZdebug1/Agent_Dobot
感兴趣可以蹲蹲,研究生一枚,无商业用途,如有任何侵权请告知。
【实物篇】
我这里设备为dobot桌面机械臂+吸泵+Realsense D435i相机
代码目录如下:
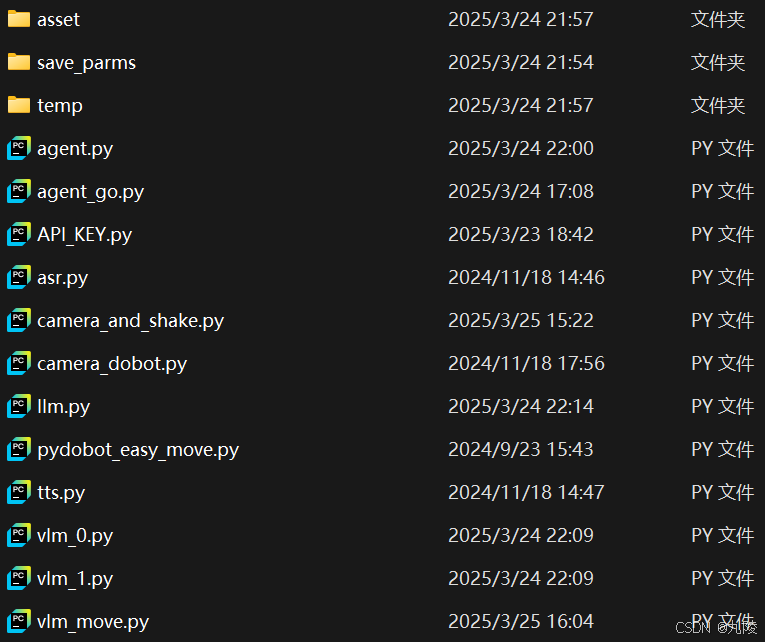
其中:
agent_go为主程序,负责串联调用其他模块,同时负责打印用户提示,接收输入指令等。
# 机械臂+大模型+多模态+语音识别=具身智能体Agent
# 导入常用函数
from asr import * # 录音+语音识别
from camera_and_shake import * # 连接机械臂
from llm import * # 大语言模型API
from camera_and_shake import * # 机械臂运动
from vlm_move import * # 多模态大模型识别图像,吸泵吸取并移动物体
from agent import * # 智能体Agent编排
from tts import * # 语音合成模块
print('播放欢迎词')
pump_off()
# back_zero()
play_wav('asset/welcome.wav')
# 用户选择使用的语言模型
llm_choice = input('请选择使用的大语言模型:\n按 e 键使用 DeepSeek 语言模型\n按 f 键使用 Yi 语言模型\n输入:')
if llm_choice not in ['e', 'f']:
raise ValueError("无效输入,请输入 'e' 或 'f'!")
# 用户选择使用哪套逻辑
model_choice = input('请选择使用的视觉检测模型:\n按 m 键使用 Grounding DINO 模型\n按 n 键使用 QwenVL 模型\n输入:')
if model_choice not in ['m', 'n']:
raise ValueError("无效输入,请输入 'm' 或 'n'!")
def agent_play(llm_choice, model_choice):
'''
主函数,语音控制机械臂智能体编排动作
'''
# 归零
# initial_pos = [200, 0, 0] # Example initial position, adjust as needed
back_zero(device)
# 输入指令
# 先回到原点,再把LED灯改为墨绿色,然后把绿色方块放在篮球上
start_record_ok = input('是否开启录音,输入数字录音指定时长,按k打字输入,按c输入默认指令:\n')
if str.isnumeric(start_record_ok):
DURATION = int(start_record_ok)
record(DURATION=DURATION) # 录音
order = speech_recognition() # 语音识别
elif start_record_ok == 'k':
order = input('请输入指令:\n')
elif start_record_ok == 'c':
order = '先归零,再点头,然后把蓝色三角片放在白色方块上'
else:
print('无指令,退出')
# exit()
raise NameError('无指令,退出')
# 智能体Agent编排动作
agent_plan_output = agent_plan(order, llm_choice)
print('智能体编排动作如下\n', agent_plan_output)
# plan_ok = input('是否继续?按c继续,按q退出')
plan_ok = 'c'
if plan_ok == 'c':
response = agent_plan_output['response'] # 获取机器人想对我说的话
print('开始语音合成')
tts(response) # 语音合成,导出wav音频文件
play_wav('temp/tts.wav') # 播放语音合成音频文件
for each in agent_plan_output['function']: # 运行智能体规划编排的每个函数
print('开始执行动作', each)
if "vlm_move" in each:
vlm_move(PROMPT=order, model_choice=model_choice, llm_choice=llm_choice)
else:
exec(each)
elif plan_ok =='q':
# exit()
raise NameError('按q退出')
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()
def main():
while True:
agent_play(llm_choice, model_choice)
plan_ok = input('是否继续?按c继续,按q退出:\n')
if plan_ok == 'q':
print('退出所有进程并释放资源')
break # 退出循环
# agent_play()
if __name__ == '__main__':
main()asset文件夹负责存放字体和生成的欢迎词:
字体在vlm中调用,欢迎词在上面agent_go中生成随机调用。
save_parms文件夹用于存放手眼标定文件。
temp文件夹用于临时存放相机拍照图片和大模型识别后的标记图片;用户说话录音speech_record.wav和大模型生成回复语音tts.wav。
其他大致作用先见上面代码注释。
首先,在线大模型api分别调用了
“零一万物” 的大语言模型 "Yi - spark"、
百度智能云千帆AppBuilder模型:主要负责语音识别及合成、
阿里Qwen-VL大模型:主要负责多模态视觉分析。
本地部署的模型有:
Deepseek-R1-8b (通过Ollama部署,自行查阅教程)
IDEA-Grounding-DINO-Base (Github有开源可下载)
准备阶段需查阅并下载其对应的SDK.分别注册它们的账号,三个平台均赠送了免费的额度,其中零一万物大模型平台在API KEY管理中直接创建新密钥然后引用即可;
千帆AppBuilder亦是在密钥管理中新增并引用,注意要领取免费额度,不然引用会失败报错,可截取相关代码先行测试调用是否成功;千帆ModelBuilde则需先在模型服务-应用接入中创建应用,领取额度,然后在头像-安全认证处(不知道为什么直接用在该程序会报错,单独使用官方文档调用是可以的,没太仔细看这块)找到对应access_key和secret_key引用。以上密钥均复制到API_KEY.py对应处即可。
阿里百炼账号正常可使用支付宝注册,在模型广场搜索该模型即可。
llm.py负责了封装调用千帆ModelBuilder和零一万物大模型
print('导入大模型API模块')
import os
import qianfan
def llm_qianfan(PROMPT='你好,你是谁?'):
'''
百度智能云千帆大模型平台API
'''
# 传入 ACCESS_KEY 和 SECRET_KEY
os.environ["QIANFAN_ACCESS_KEY"] = QIANFAN_ACCESS_KEY
os.environ["QIANFAN_SECRET_KEY"] = QIANFAN_SECRET_KEY
# 选择大语言模型
MODEL = "ERNIE-Lite-8K"
# MODEL = "ERNIE Speed"
# MODEL = "ERNIE-Lite-8K"
# MODEL = 'ERNIE-Tiny-8K'
chat_comp = qianfan.ChatCompletion(model=MODEL)
# 输入给大模型
resp = chat_comp.do(
messages=[{"role": "user", "content": PROMPT}],
top_p=0.8,
temperature=0.3,
penalty_score=1.0
)
response = resp["result"]
return response
import openai
from openai import OpenAI
from API_KEY import *
def llm_yi(PROMPT='你好,你是谁?'):
'''
零一万物大模型API
'''
os.environ["YI_KEY"] = YI_KEY
API_BASE = "https://api.lingyiwanwu.com/v1"
API_KEY = YI_KEY
MODEL = 'yi-spark'
# MODEL = 'yi-medium'
# MODEL = 'yi-spark'
# 访问大模型API
client = OpenAI(api_key=API_KEY, base_url=API_BASE)
completion = client.chat.completions.create(model=MODEL, messages=[{"role": "user", "content": PROMPT}])
result = completion.choices[0].message.content.strip()
return resultasr.py负责录音和语音识别,注意更改自身麦克风序列号,注释部分可单独测试该程序是否可以正确录音及识别。
# 录音+语音识别
from appbuilder import AppBuilderServerException
print('导入录音+语音识别模块')
import pyaudio
import wave
import numpy as np
import os
import sys
from API_KEY import *
import sounddevice as sd
from pydub import AudioSegment
# 确定麦克风索引号
# print(sd.query_devices())
def record(MIC_INDEX=1, DURATION=4):
'''
调用麦克风录音,录音时长由DURATION参数指定
'''
print('开始 {} 秒录音'.format(DURATION))
p = pyaudio.PyAudio()
# 初始化录音流
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
input_device_index=MIC_INDEX,
frames_per_buffer=1024)
frames = []
for _ in range(0, int(16000 / 1024 * DURATION)):
data = stream.read(1024)
frames.append(data)
# 停止录音
stream.stop_stream()
stream.close()
p.terminate()
# 保存录音文件
output_path = 'temp/speech_record.wav'
wf = wave.open(output_path, 'wb')
wf.setnchannels(1)
wf.setsampwidth(p.get_sample_size(pyaudio.paInt16))
wf.setframerate(16000)
wf.writeframes(b''.join(frames))
wf.close()
print('录音结束,保存文件至', output_path)
def record_auto(MIC_INDEX=1):
'''
开启麦克风录音,保存至'temp/speech_record.wav'音频文件
音量超过阈值自动开始录音,低于阈值一段时间后自动停止录音
MIC_INDEX:麦克风设备索引号
'''
CHUNK = 1024 # 采样宽度
RATE = 16000 # 采样率
QUIET_DB = 2000 # 分贝阈值,大于则开始录音,否则结束
delay_time = 2 # 声音降至分贝阈值后,经过多长时间,自动终止录音
FORMAT = pyaudio.paInt16
CHANNELS = 1 # 采样通道数
# 初始化录音
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK,
input_device_index=MIC_INDEX)
frames = [] # 所有音频帧
flag = False # 是否已经开始录音
quiet_flag = False # 当前音量小于阈值
temp_time = 0 # 当前时间是第几帧
last_ok_time = 0 # 最后正常是第几帧
START_TIME = 0 # 开始录音是第几帧
END_TIME = 0 # 结束录音是第几帧
print('可以说话啦!')
while True:
# 获取当前chunk的声音
data = stream.read(CHUNK, exception_on_overflow=False)
frames.append(data)
# 获取当前chunk的音量分贝值
temp_volume = np.max(np.frombuffer(data, dtype=np.short))
if temp_volume > QUIET_DB and flag == False:
print("音量高于阈值,开始录音")
flag = True
START_TIME = temp_time
last_ok_time = temp_time
if flag: # 录音中的各种情况
if (temp_volume < QUIET_DB and quiet_flag == False):
print("录音中,当前音量低于阈值")
quiet_flag = True
last_ok_time = temp_time
if (temp_volume > QUIET_DB):
quiet_flag = False
last_ok_time = temp_time
if (temp_time > last_ok_time + delay_time * 15 and quiet_flag == True):
print("音量低于阈值{:.2f}秒后,检测当前音量".format(delay_time))
if (quiet_flag and temp_volume < QUIET_DB):
print("当前音量仍然小于阈值,录音结束")
END_TIME = temp_time
break
else:
print("当前音量重新高于阈值,继续录音中")
quiet_flag = False
last_ok_time = temp_time
temp_time += 1
if temp_time > 150: # 超时直接退出
END_TIME = temp_time
print('超时,录音结束')
break
# 停止录音
stream.stop_stream()
stream.close()
p.terminate()
# 导出wav音频文件
output_path = 'temp/speech_record.wav'
wf = wave.open(output_path, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames[START_TIME - 2:END_TIME]))
wf.close()
print('保存录音文件', output_path)
import appbuilder
# 配置密钥
os.environ["APPBUILDER_TOKEN"] = APPBUILDER_TOKEN
asr = appbuilder.ASR() # 语音识别组件
def speech_recognition(audio_path='temp/speech_record.wav'):
'''
AppBuilder-SDK语音识别组件
'''
print('开始语音识别')
try:
# 载入wav音频文件
audio = AudioSegment.from_wav(audio_path)
# 转换采样率为16000Hz
audio = audio.set_frame_rate(16000)
# 保存转换后的音频文件(如果需要)
new_audio_path = 'temp/speech_record.wav'
audio.export(new_audio_path, format='wav')
# 载入wav音频文件
with wave.open(audio_path, 'rb') as wav_file:
# 获取音频文件的基本信息
num_channels = wav_file.getnchannels()
sample_width = wav_file.getsampwidth()
framerate = wav_file.getframerate()
num_frames = wav_file.getnframes()
# 检查采样率
if framerate != 16000:
print(f"警告: 音频采样率为 {framerate},建议使用 16000Hz 采样率。")
# 获取音频数据
frames = wav_file.readframes(num_frames)
# 向API发起请求
content_data = {"audio_format": "wav", "raw_audio": frames, "rate": 16000}
message = appbuilder.Message(content_data)
# 执行识别请求
speech_result = asr.run(message).content['result'][0]
print('语音识别结果:', speech_result)
return speech_result
except AppBuilderServerException as e:
print(f"语音识别出错: {e}")
return None
except Exception as e:
print(f"发生了其他错误: {e}")
return None
# def main():
# print("请选择录音方式:")
# print("1. 手动录音(定时录音)")
# print("2. 自动录音(声音触发)")
# choice = input("请输入1或2来选择:")
#
# if choice == "1":
# # 手动录音,录音时长5秒,麦克风索引为1
# record(MIC_INDEX=1, DURATION=5)
# elif choice == "2":
# # 自动录音,麦克风索引为1
# record_auto(MIC_INDEX=1)
# else:
# print("无效输入,请输入1或2")
#
# # 执行语音识别
# print("开始进行语音识别测试...")
# speech_result = speech_recognition()
# print(f"识别结果: {speech_result}")
# if __name__ == '__main__':
# main()llm.py 中提供大语言模型:Yi-spark/Deepseek模型调用函数,方便切换
camera_and_shake.py 中提供机械臂控制代码、深度相机拍摄。
agent.py 中负责构成智能体编排动作:
其中涉及简单的提示词工程。
import json
from llm import *
# 全局定义机械臂助手的系统提示
AGENT_SYS_PROMPT = '''
你是我的机械臂助手,机械臂内置了一些函数,请你根据我的指令,以json形式输出要运行的对应函数和你给我的回复
【以下是所有内置函数介绍】
机械臂位置归零,所有关节回到原点:back_zero()
做出摇头动作:head_shake()
做出点头动作:head_nod()
打开吸泵:pump_on()
关闭吸泵:pump_off()
移动到指定XY坐标,比如移动到X坐标250,Y坐标-120:move_to_position(device, [250, -120, 0])
拍俯视图:realsense_video()
开启摄像头,在屏幕上实时显示摄像头拍摄的画面:realsense_video()
将一个物体移动到另一个物体的位置上,比如:vlm_move('帮我把红色方块放在小猪佩奇上')
休息等待,比如等待两秒:time.sleep(2)
【输出json格式】
你直接输出json即可,从{开始,不要输出包含```json的开头或结尾。
请确保JSON字符串的键和值均使用双引号(而不是单引号)。
在'function'键中,输出函数名列表,列表中每个元素都是字符串,代表要运行的函数名称和参数。每个函数既可以单独运行,也可以和其他函数先后运行。列表元素的先后顺序,表示执行函数的先后顺序
在'response'键中,根据我的指令和你编排的动作,以第一人称输出你回复我的话,不要超过20个字,可以幽默和发散,用上歌词、台词、互联网热梗、名场面。比如李云龙的台词、甄嬛传的台词、练习时长两年半。但注意不要输出有英文。
【以下是一些具体的例子】
我的指令:回到原点。你输出:{'function':['back_zero(device)'], 'response':'回家吧,回到最初的美好'}
我的指令:先回到原点,然后摇头。你输出:{'function':['back_zero(device)', 'head_shake(device)'], 'response':'达咩,不要'}
我的指令:先回到原点,然后移动到250, -90坐标。你输出:{'function':['back_zero(device)', 'move_to_position(device, [250, -90, 0])'], 'response':'小飞棍来咯'}
我的指令:先打开吸泵。你输出:{'function':['pump_on()'], 'response':'开吸'}
我的指令:移动到X为160,Y为-30的地方。你输出:{'function':['move_to_position(device, [160, -30, 0])'], 'response':'坐标移动已完成'}
我的指令:拍一张俯视图。你输出:{'function':['realsense_video()'], 'response':'可以开始按'c'键拍摄'}
我的指令:帮我把绿色方块放在小猪佩奇上面。你输出:{'function':[vlm_move('帮我把绿色方块放在小猪佩奇上面')], 'response':'它的弟弟乔治呢?'}
我的指令:帮我把红色方块放在李云龙的脸上。你输出:{'function':[vlm_move('帮我把红色方块放在李云龙的脸上')], 'response':'嘿,你他娘的真是个天才'}
我的指令:关闭吸泵,打开摄像头。你输出:{'function':[pump_off(), realsense_video()], 'response':'你是我的眼,带我阅读浩瀚的书海'}
我的指令:先回到原点,等待三秒,再打开吸泵,最后把绿色方块移动到摩托车上。你输出:{'function':['back_zero(device)', 'time.sleep(3)', 'pump_on()', vlm_move('把绿色方块移动到摩托车上'))], 'response':'如果奇迹有颜色,那一定是中国红'}
我的指令:先回到原点,然后点头。你输出:{'function':['back_zero(device)', 'head_nod(device)'], 'response':'嗯嗯好'}
【我现在的指令是】
'''
# 智能体动作编排
# 智能体动作编排
def agent_plan(AGENT_PROMPT='先回到原点,然后把蓝色三角片放在白色方块上', llm_choice='e'):
print('Agent智能体编排动作')
PROMPT = AGENT_SYS_PROMPT + AGENT_PROMPT
print(f"当前选择的模型是:{llm_choice}")
try:
# 根据用户选择调用不同的语言模型
if llm_choice == 'e':
print("使用 DeepSeek 模型")
response = llm_deepseek(PROMPT)
elif llm_choice == 'f':
print("使用 Yi 模型")
response = llm_yi(PROMPT)
else:
raise ValueError("无效的语言模型选择!")
# 使用正则表达式提取大括号中的 JSON 部分
match = re.search(r'(\{.*\})', response, flags=re.DOTALL)
if match:
clean_response = match.group(1).strip()
else:
raise ValueError("未找到有效的 JSON 数据")
print("清理后的 JSON 字符串:")
print(clean_response)
# 校验并返回 JSON 数据
return json.loads(clean_response)
except json.JSONDecodeError:
# 异常处理:返回空 JSON 提示解析失败
print("JSON 解析失败,返回内容如下:")
print(clean_response)
return {"function": [], "response": "请重复一遍"}
except Exception as e:
# 捕获其他异常
print(f"发生错误: {e}")
return {"function": [], "response": "系统错误"}
# 测试示例
# if __name__ == '__main__':
# instruction = "回到原点,然后摇头"
# result = agent_plan(instruction)
# print(result)
vlm_move.py 主要负责抓取动作逻辑、坐标转换、简单的运动规划。
vlm_0和vlm_1.py 文件 涉及视觉模型以及图像处理。
未完待续...
后续会简单写一下仿真和UI界面,原理框架大致还是一样的。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)