2025版最新大模型微调教程,零基础入门到精通,收藏这篇就够了
最近huggingface开源了一个微调大模型免费课程,然后最近自己也在学习,想着边学习边分享,开源地址会放在文章结尾,进度快的小伙伴可以自己看一下。首先,让我们理解什么是聊天模板以及为什么它们如此重要:聊天模板本质上是一个结构化的对话格式系统,就像是AI模型与人类交谈时需要遵循的"礼仪规则"。想象一下,如果我们在参加一个正式的商务会议,我们需要遵循特定的沟通规则和格式 - 聊天模板就是AI模型的
最近huggingface开源了一个微调大模型免费课程,然后最近自己也在学习,想着边学习边分享,开源地址会放在文章结尾,进度快的小伙伴可以自己看一下。
首先,让我们理解什么是聊天模板以及为什么它们如此重要:
聊天模板本质上是一个结构化的对话格式系统,就像是AI模型与人类交谈时需要遵循的"礼仪规则"。想象一下,如果我们在参加一个正式的商务会议,我们需要遵循特定的沟通规则和格式 - 聊天模板就是AI模型的这样一个规则系统。
让我们先来理解两种重要的模型类型:
1. 基础模型(Base Models):
这类模型就像是一个刚刚学会说话的孩子,它们能够预测下一个词应该是什么,但可能不太懂得如何进行得体的对话。比如SmolLM2-135M(我们这个教程所用到的开源模型)就是这样的基础模型。
2. 指令模型(Instruct Models):
这类模型就像是经过礼仪培训的人,它们知道如何恰当地回应指令和进行对话。比如SmolLM2-135M-Instruct就是经过专门训练的指令模型。
让我来用一个具体的例子说明聊天模板是如何工作的:
```python
# 一个典型的对话示例
messages = [
{"role": "system", "content": "你是一位专业的中文教师,善于用生动的例子解释语言知识。"},
{"role": "user", "content": "什么是成语?"},
{"role": "assistant", "content": "成语是汉语中的一种固定词组,通常由四个字组成..."},
{"role": "user", "content": "能给我举个例子吗?"}
]
```
这个格式就像是一个剧本,其中:
1. 系统消息(System Messages)就像是导演给演员的整体指示,它设定了AI助手应该扮演的角色和行为方式。
2. 用户消息(User Messages)就像是对话中的提问方。
3. 助手消息(Assistant Messages)则是AI的回应。
在实际应用中,这些消息会被转换成特定的格式,例如:
```sh
<|im_start|>system
你是一位专业的中文教师。
<|im_end|>
<|im_start|>user
什么是成语?
<|im_end|>
<|im_start|>assistant
```
在实际使用中,我们可以使用transformers库来处理这些模板。这就像是有一个翻译官,帮助我们将普通的对话转换成AI能够理解的格式:
```python
from transformers import AutoTokenizer
# 创建一个分词器
tokenizer = AutoTokenizer.from_pretrained(“HuggingFaceTB/SmolLM2-135M-Instruct”)
# 定义我们的对话
messages = [
{"role": "system", "content": "你是一位语言教师"},
{"role": "user", "content": "请解释什么是成语"},
]
# 应用聊天模板
formatted_chat = tokenizer.apply_chat_template(
messages,
tokenize=False,
add\_generation\_prompt=True
)
```
聊天模板最强大的特点之一是它能够处理多轮对话。就像在现实生活中的对话一样,AI需要记住之前说过的话才能做出合适的回应。例如:
```python
messages = [
{"role": "system", "content": "你是一位数学老师"},
{"role": "user", "content": "什么是加法?"},
{"role": "assistant", "content": "加法是最基本的算术运算之一..."},
{"role": "user", "content": "那乘法呢?"},
{"role": "assistant", "content": "乘法其实可以看作是重复的加法..."}
]
```
这就像是在课堂上,老师需要记住之前讲过的内容,才能把新的知识点和已经讲过的内容联系起来。
通过这样的结构化对话格式,AI模型能够:
- 保持对话的连贯性
- 理解上下文
- 提供更准确和相关的回答
- 维持特定的角色设定
这种结构化的方式确保了AI模型能够像一个训练有素的专业人士一样进行对话,而不是随机地产生回答。就像在正式场合中,我们会遵循特定的沟通规则一样,AI模型通过聊天模板来保持专业和得体的对话方式。
如果大家还是没有很懂的话,我来用代码详细给大家讲一下:
# Install the requirements in Google Colab
# !pip install transformers datasets trl huggingface_hub
# Authenticate to Hugging Face
from huggingface_hub import login
login()
# for convenience you can create an environment variable containing your hub token as HF_TOKEN
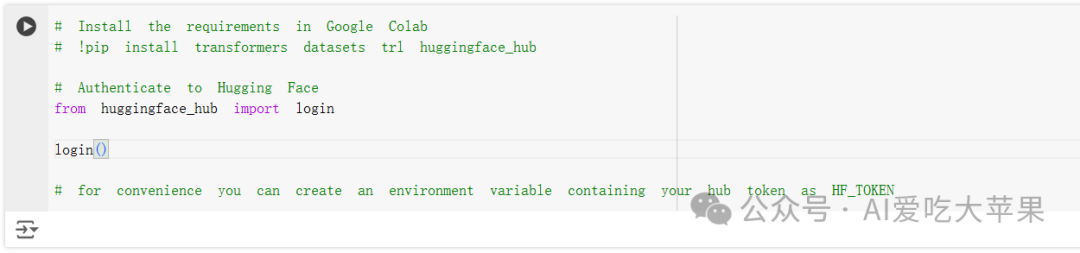
运行这个代码会让你填huggingface的令牌:
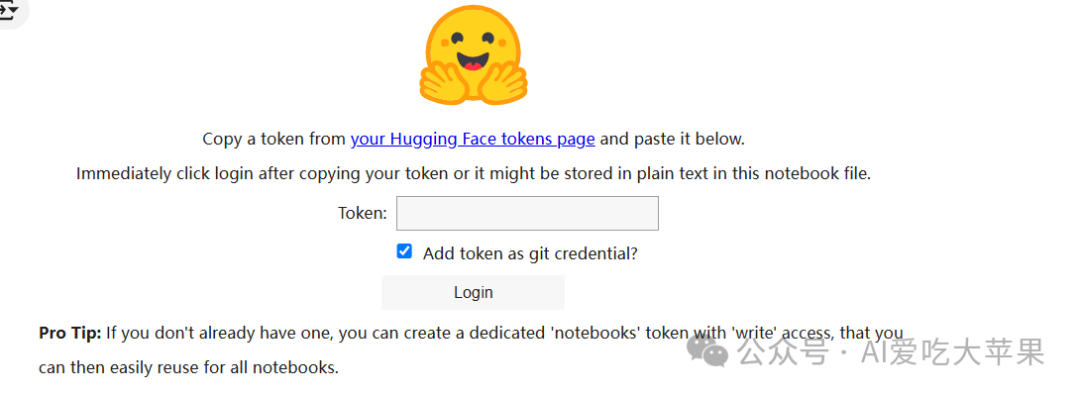
令牌的TOKEN需要登录huggingface,然后点击右上角的头像,找到access Tokens选项


点击create new token
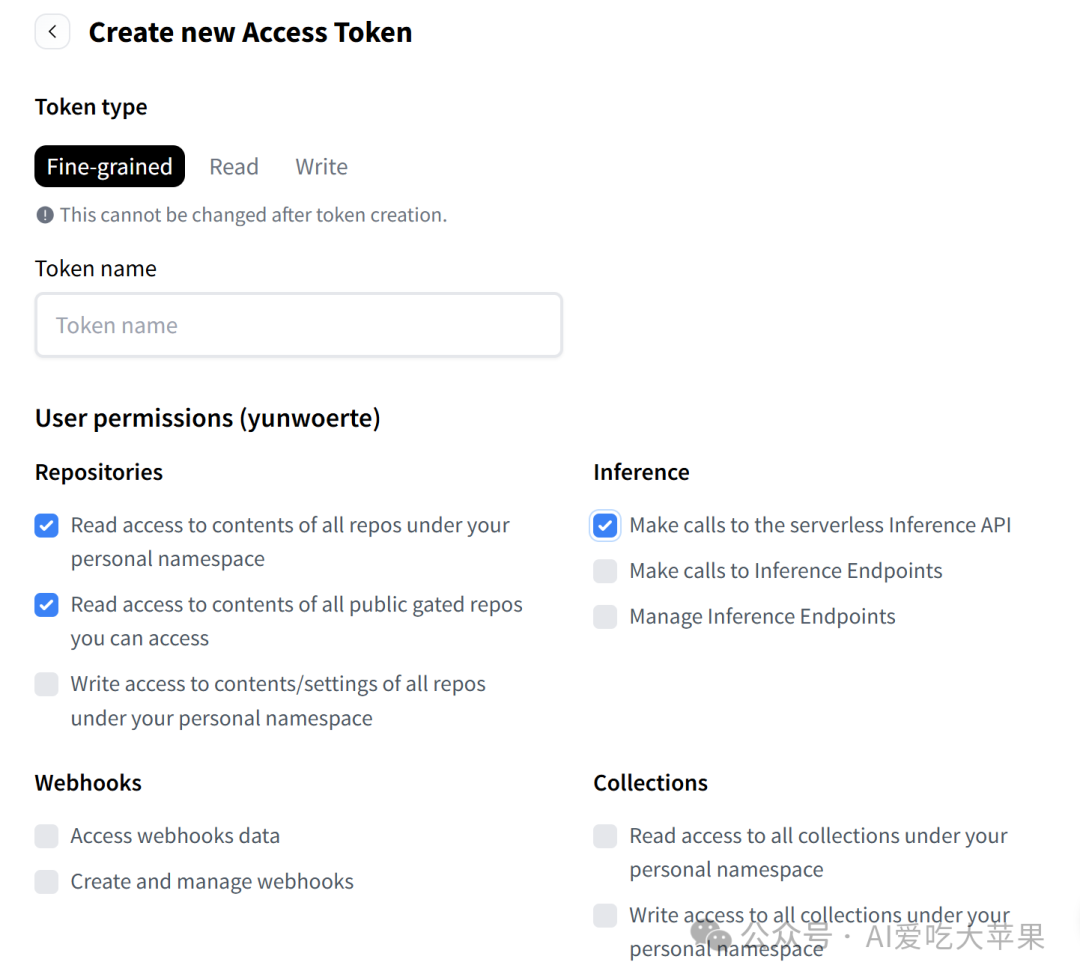

最后点击create token就好了。
需要先安装这个环境:
!pip install trl
这几行代码就是加载一些库用来调用
# Import necessary libraries
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import setup_chat_format
import torch

让我通过一个生动的例子来解释这段代码。想象你要开一家新餐厅:
- 首先是选择厨房设备(device的设置):
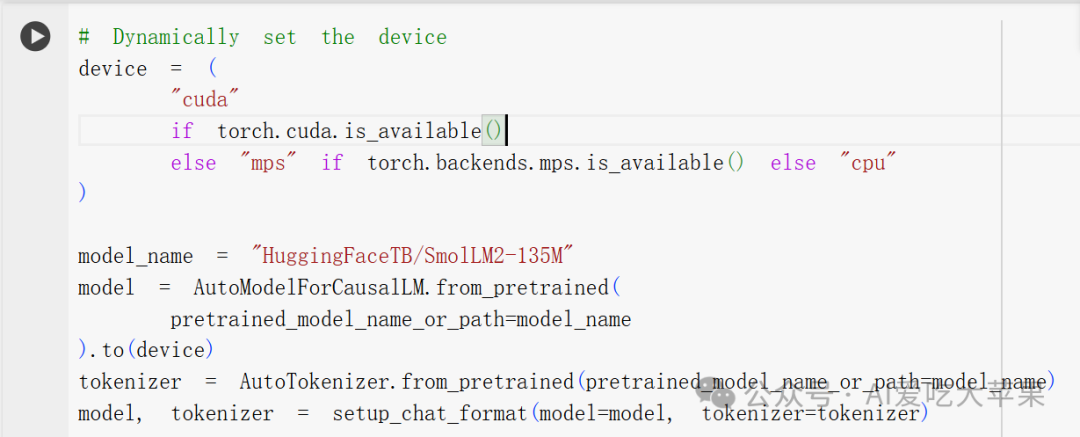
device = (
"cuda" if torch.cuda.is\_available() # 检查是否有专业厨房设备(GPU)
else "mps" if torch.backends.mps.is\_available() # 检查是否有家用厨具(Apple芯片)
else "cpu" # 如果都没有,就用基础厨具(CPU)
)
这就像在决定用什么设备烹饪:
-
CUDA (GPU):就像有一个专业的商用厨房,可以快速处理大量订单
-
MPS (Apple芯片):像是一个高级家用厨房,效率不错
-
CPU:就像只有基本的厨具,可以完成工作但速度较慢
- 选择和加载模型:
model_name = “HuggingFaceTB/SmolLM2-135M” # 选择使用哪个主厨
model = AutoModelForCausalLM.from_pretrained(
pretrained\_model\_name\_or\_path=model\_name
).to(device) # 请这位主厨到指定的厨房工作
这就像:
-
选择一位有经验的主厨(SmolLM2-135M模型)
-
让这位主厨到我们准备好的厨房(device)工作
-
AutoModelForCausalLM就像是一个招聘系统,帮我们找到合适的主厨
- 设置语言翻译器:
tokenizer = AutoTokenizer.from_pretrained(model_name) # 配备翻译员
这就像:
-
雇佣一位翻译(tokenizer)
-
这位翻译精通主厨(模型)的语言
-
能够将顾客的要求转换成主厨理解的形式
- 设置交流格式
model, tokenizer = setup_chat_format(model=model, tokenizer=tokenizer)
这就像:
-
建立主厨和翻译之间的标准沟通方式
-
确保所有的对话都遵循同一个格式
-
让整个团队能够高效合作
实际运行时的场景可能是这样的:
-
顾客下单(用户输入): “我想要一个芝士汉堡”
-
翻译员(tokenizer)将订单转换成厨房用语
-
主厨(model)在指定的厨房(device)制作食物
-
翻译员将成品描述转换回顾客能理解的语言
这整个系统就像一个精心设计的餐厅,每个部分都有其特定的角色和功能,共同协作来服务顾客(用户)。
接下来是:

这段代码定义了一个简单的对话示例,让我们用一个真实场景来理解它:想象你走进一家咖啡店,与服务员的对话。
messages = [
# 顾客打招呼
{
"role": "user", # 这是顾客的角色
"content": "Hello, how are you?" # 顾客说的话
},
# 服务员回应
{
"role": "assistant", # 这是服务员的角色
"content": "I'm doing well, thank you! How can I assist you today?" # 服务员的回答
}
]
这个结构可以被分解为几个关键部分:
-
messages是一个列表,就像一个对话记录本,按时间顺序记录每句话。 -
每句话都是一个字典(dictionary),包含两个重要信息:
-
"role": 说话的人是谁(类似于剧本中的角色标注) -
"content": 具体说了什么(实际的对话内容)
想象一个更复杂的对话场景:
messages = [
{
"role": "user",
"content": "我想点一杯咖啡"
},
{
"role": "assistant",
"content": "好的,我们有美式咖啡、拿铁和卡布奇诺,您想要哪种呢?"
},
{
"role": "user",
"content": "我要一杯拿铁"
},
{
"role": "assistant",
"content": "好的,一杯拿铁。您想要热的还是冰的?"
}
]
这种结构的重要性在于:
-
清晰的角色划分(user/assistant)帮助AI理解谁在说话
-
按顺序排列的消息帮助AI理解对话的上下文
-
标准的格式让AI能够正确理解和回应对话
就像在一个剧本中:
-
“role” 就像角色名(比如:顾客、服务员)
-
“content” 就像台词内容
-
整个messages列表就像一个完整的对话场景
这种结构使得AI能够:
-
清楚地知道谁在说话
-
理解对话的前后关系
-
基于上下文提供合适的回应
接下来是这三部分代码,我希望一起讲一下:

让我通过一个详细的例子来解释这三段代码的区别。继续用我们的咖啡厅场景,但这次让我们更深入地看看每个步骤。
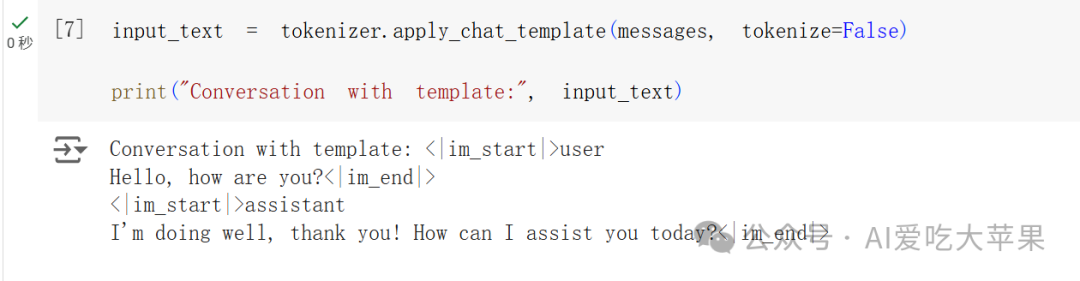
第一段代码:基本格式转换
```python
input_text = tokenizer.apply_chat_template(messages, tokenize=False)
print(“Conversation with template:”, input_text)
```
输出:
```
Conversation with template: <|im_start|>user
Hello, how are you?<|im_end|>
<|im_start|>assistant
I’m doing well, thank you! How can I assist you today?<|im_end|>
```
这就像是把普通的对话记录转换成标准的服务手册格式:
- 原来是:
```
顾客:“您好!”
服务员:“您好,需要什么帮助?”
```
- 转换后是:
```
[开始服务]顾客
您好![顾客话结束]
[开始服务]服务员
您好,需要什么帮助?[服务员话结束]
```
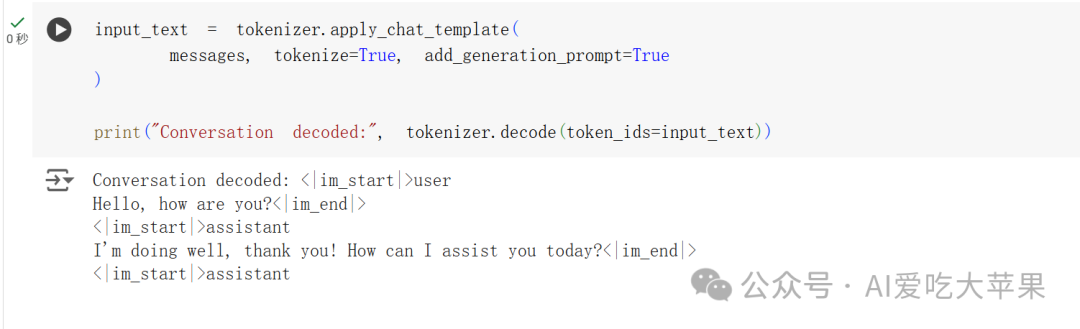
第二段代码:编码并添加提示
```python
input_text = tokenizer.apply_chat_template(
messages,
tokenize=True, # 转换成数字编码
add\_generation\_prompt=True # 添加"该AI回应了"的提示
)
print(“Conversation decoded:”, tokenizer.decode(token_ids=input_text))
```
输出:
```
Conversation decoded: <|im_start|>user
Hello, how are you?<|im_end|>
<|im_start|>assistant
I’m doing well, thank you! How can I assist you today?<|im_end|>
<|im_start|>assistant
```
这就像是:
1. 把对话转换成内部编码
2. 在最后加上一个"服务员请说话"的提示牌
3. 然后又解码回来让我们能看懂
就像咖啡厅的:
```
[对话开始]顾客
您好![顾客结束]
[对话开始]服务员
您好,需要什么帮助?[服务员结束]
[服务员,请继续说…] <- 这是新加的提示
```
第三段代码:查看数字编码
```python
input_text = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
print(“Conversation tokenized:”, input_text)
```
输出:
```
Conversation tokenized: [1, 4093, 198, 19556, 28, 638, 359, 346, 47, 2, …]
```
这就像是看到了咖啡厅内部的订单编码系统:
- “您好” → [198, 19556]
- “需要帮助” → [638, 359, 346]
- 每个数字都代表了特定的词或短语
三者的关系是:
1. 第一段代码:把对话变成标准格式(类似翻译成英语)
2. 第二段代码:把标准格式转成数字,加上提示,然后解码回来看(类似翻译成密码再解回来)
3. 第三段代码:直接看数字编码(类似直接看密码本)
这三种表示方式各有用途:
- 第一种让人能看懂对话的结构
- 第二种让AI知道该说话了
- 第三种是AI实际处理的形式
就像咖啡厅可能有:
- 顾客看的菜单(人类可读版本)
- 服务员用的点单本(标准格式版本)
- 厨房用的订单代码(数字编码版本)
接下来的代码就是加载数据集了:数据的格式就是一问一答的形式:
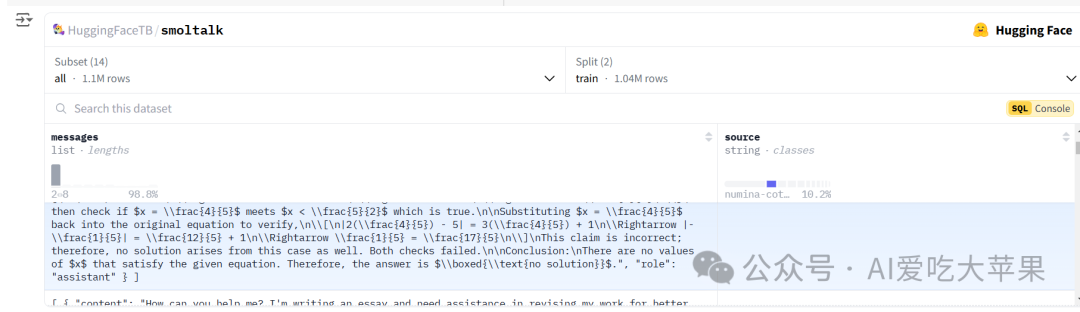
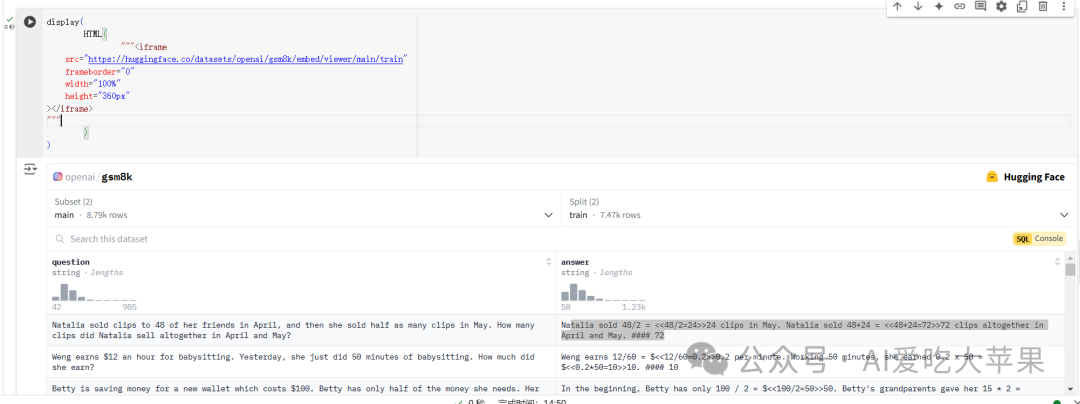
这是一个来自HuggingFace的数据集界面,让我们一步步解析它:
- 数据集基本信息:
-
这是
HuggingFaceTB/smoltalk数据集 -
总共有1.1M条数据(1.1M rows)
-
数据集被分成了训练集(train,1.04M行)和其他部分
-
显示的具体内容:这里展示了一个数学问题的对话示例
-
数据集结构:
-
messages:显示对话内容的列
-
source:显示数据来源(这里显示是 ‘numina-cot-100k’,可能是某种数学问题集)
-
左侧有数据统计图表,显示数据的分布情况
这个数据集似乎是用来训练AI进行数学问题对话的。每条数据都包含:
-
一个数学问题(用户提问)
-
预期的解答方式(AI应该如何回答)
就像是在准备一个数学老师的"教学参考资料":
-
收集了大量的数学问题和标准答案
-
每个问题都有特定的解题思路
-
这些数据用来训练AI如何像数学老师一样回答问题

这段代码就是我们的小练习:
-
把数据样本转换成聊天格式 (🐢 表示这是最基础的难度级别)
-
使用分词器的方法来应用聊天模板
from datasets import load_dataset
ds = load_dataset(“HuggingFaceTB/smoltalk”, “everyday-conversations”)
def process_dataset(sample):
"""
将数据集样本转换为标准的聊天格式并应用模板
参数:
sample: 数据集中的一个样本,包含对话内容
返回:
处理后的样本,包含格式化的对话文本
"""
# 第一步:将样本转换为标准的消息格式
# messages 列表中的每个元素都是一个字典,包含 role 和 content
messages = \[
{"role": "user", "content": sample\["messages"\]\[0\]\["content"\]},
{"role": "assistant", "content": sample\["messages"\]\[1\]\["content"\]}
\]
# 第二步:使用分词器应用聊天模板
# tokenize=False 表示我们要得到文本格式而不是token IDs
formatted\_text = tokenizer.apply\_chat\_template(
messages,
tokenize=False
)
# 第三步:返回处理后的样本
# 我们保留原始样本的同时,添加格式化后的文本
return {
"original\_messages": sample\["messages"\],
"formatted\_text": formatted\_text
}
ds = ds.map(process_dataset)
处理后的格式,只是格式,不是真实数据,如下所示:
# 假设我们有这样一个输入样本:
sample = {
"messages": \[
{
"content": "今天天气怎么样?",
"role": "user"
},
{
"content": "今天阳光明媚,非常适合外出活动。",
"role": "assistant"
}
\]
}
# 处理后,它会变成:
processed = {
"original\_messages": \[原始消息保持不变\],
"formatted\_text": """<|im\_start|>user
今天天气怎么样?<|im_end|>
<|im_start|>assistant
今天阳光明媚,非常适合外出活动。<|im_end|>“”"
}
第二个练习就是,加载openai的数据,左边问题,右边答案:
display(
HTML(
"""<iframe
src=“https://huggingface.co/datasets/openai/gsm8k/embed/viewer/main/train”
frameborder=“0”
width=“100%”
height=“360px”
>
“”"
)
)
1. **第一个要求: “Convert the sample into a chat format”**
```python
def process_dataset(sample):
# 这个要求在整个函数中体现,它是我们的总目标
# 我们需要将样本转换成聊天格式
```
2. **第二个要求: “create a message format with the role and content”**
```python
# 这部分在代码中是这样实现的:
messages = \[
{
"role": "user",
"content": sample\["question"\]
},
{
"role": "assistant",
"content": sample\["answer"\]
}
\]
```
3. **第三个要求: “apply the chat template to the samples using the tokenizer’s method”**
```python
# 这部分在代码中是这样实现的:
formatted\_text = tokenizer.apply\_chat\_template(
messages,
tokenize=False
)
```
是的,我的代码确实包含了所有三个部分。让我重新组织一下代码,使这三个部分更加清晰:
```python
def process_dataset(sample):
"""
将数学问题数据集转换为聊天格式
"""
\# 第一个要求:整体转换目标
try:
# 第二个要求:创建消息格式
messages = \[
{
"role": "user",
"content": sample\["question"\]
},
{
"role": "assistant",
"content": sample\["answer"\]
}
\]
# 第三个要求:应用聊天模板
formatted\_text = tokenizer.apply\_chat\_template(
messages,
tokenize=False
)
# 更新样本数据
sample\["formatted\_text"\] = formatted\_text
sample\["messages"\] = messages # 保存中间格式以便检查
sample\["status"\] = "success"
except Exception as e:
print(f"处理样本时出错: {str(e)}")
sample\["status"\] = "error"
return sample
# 应用处理函数到整个数据集
ds = ds.map(process_dataset)
```
1. **第一个要求(整体转换)**:
-
整个函数的目的就是将样本转换为聊天格式
-
我们加入了错误处理来确保转换的可靠性
2. **第二个要求(创建消息格式)**:
-
明确创建了包含role和content的消息格式
-
正确映射了问题到user角色,答案到assistant角色
3. **第三个要求(应用模板)**:
-
使用了tokenizer.apply_chat_template方法
-
设置了合适的参数(tokenize=False)来获得可读的输出
这样处理后,我们可以得到类似这样的输出:
```
<|im_start|>user
如果小明有5个苹果,给了小红2个,现在还剩几个?<|im_end|>
<|im_start|>assistant
让我们一步步解决:
-
开始时有5个苹果
-
给出了2个
-
5 - 2 = 3
所以剩下3个苹果<|im_end|>
```
原文教程地址:https://github.com/huggingface/smol-course?tab=readme-ov-file
希望大家可以上手跑一下代码,动手学才会更深刻一些,如果看到这的话想求个点赞和关注,谢谢大家!!!
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐



 22
22 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)