【AI大模型】一个简单程序看透 RAG 的核心原理,理解优化 RAG 的关键要点
想让大语言模型不再胡说八道,检索增强生成(RAG)是一个可靠的解决方案。但很多人对 RAG 的印象可能是:需要复杂的架构、繁琐的组件配置、以及大量的调优工作。事实上,通过一个不到 200 行的 Python 程序,我们就能完整展示 RAG 是如何工作的。在这篇文章中,你将看到:
前言
想让大语言模型不再胡说八道,检索增强生成(RAG)是一个可靠的解决方案。但很多人对 RAG 的印象可能是:需要复杂的架构、繁琐的组件配置、以及大量的调优工作。
事实上,通过一个不到 200 行的 Python 程序,我们就能完整展示 RAG 是如何工作的。在这篇文章中,你将看到:
-
如何用最简单的代码实现一个完整的 RAG 系统
-
每个核心组件(检索器、向量数据库、大语言模型)是如何协同工作的
-
最关键的是:你会明白为什么检索的准确性决定了整个系统的表现
我们将通过 LangChain 框架来实现这个示例。当你看完这篇文章,不仅能理解 RAG 的工作原理,还能知道在实际应用中应该把注意力放在哪里。
您可以在文章末尾找到本文中的完整程序。
RAG 的工作原理
RAG 系统通过以下 5 个关键步骤来工作:
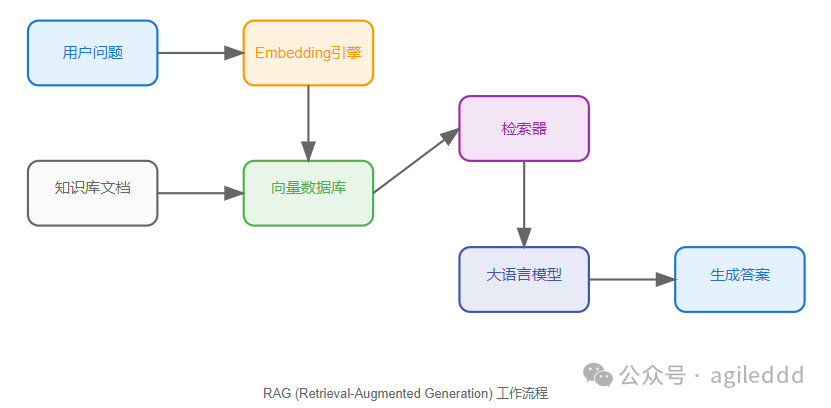
1. 准备文档
首先,我们需要准备知识库文档。在示例代码中,我们创建了一个包含宠物相关信息的简单文档集合:
from langchain_core.documents import Document
documents = [
Document(
page_content="狗是很好的伴侣,以忠诚和友好而闻名。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫是独立的宠物,通常喜欢自己的空间。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="金鱼是初学者喜欢的宠物,只需要相对简单的照顾。",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="鹦鹉是聪明的鸟类,能够模仿人类说话。",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="兔子是社交动物,需要大量空间来跳跃。",
metadata={"source": "mammal-pets-doc"},
),
]
每个文档都包含实际内容(page_content)和元数据(metadata)。元数据可以用来标记文档的来源、类型等信息。
2. 向量化存储
下一步是将文档转换为向量并存储到向量数据库中:
from langchain_chroma import Chroma
from langchain_openai import AzureOpenAIEmbeddings
embeddings = AzureOpenAIEmbeddings(
azure_endpoint=env_vars.get("AZURE_OPENAI_ENDPOINT"),
azure_deployment=env_vars.get("AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME"),
openai_api_version=env_vars.get("AZURE_OPENAI_EMBEDDING_API_VERSION"),
api_key=env_vars.get("AZURE_OPENAI_API_KEY"),
)
vectorstore = Chroma.from_documents(
documents,
embedding=embeddings,
)
这个步骤中:
-
使用 AzureOpenAIEmbeddings 将文本转换为向量
-
使用 Chroma 向量数据库存储这些向量
-
每个文档的内容都被转换为高维向量,便于后续相似性搜索
3. 创建检索器
创建一个检索器(retriever)用于后续的文档检索:
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 1},
)
这里我们:
-
使用 similarity 搜索方式,基于向量相似度检索文档
-
设置 k=1 表示每次检索返回最相关的一个文档
4. 准备提示模板
定义用于 RAG 的标准提示词模板:
template = """
根据提供的上下文回答这个问题。
问题: {question}
上下文:
{context}
回答:
"""
prompt = ChatPromptTemplate.from_template(template)
提示词模板:
-
清晰定义了问题、上下文和答案的结构
-
指导模型使用检索到的上下文来生成回答
5. 实现 RAG 链
最后,将所有组件组合成完整的 RAG 链:
def rag_chain(question: str) -> str:
# 检索相关文档
retrieved_docs = retriever.invoke(question)
# 将检索到的文档格式化为上下文
context = "\n".join(doc.page_content for doc in retrieved_docs)
# 使用问题和上下文格式化提示
formatted_prompt = prompt.format(question=question, context=context)
# 获取模型的响应
response = model.invoke(formatted_prompt)
return response.content
在这个实现中,检索器(retriever)和 embeddings 引擎扮演着核心角色:
- 检索器的关键作用:
-
检索器负责理解用户问题并找到相关文档
-
它通过 embeddings 引擎将问题转换为向量
-
在向量空间中查找最相似的文档
-
将找到的相关文档作为上下文提供给大模型
- 工作流程:
-
用户提出问题(如"最好的宠物是什么?")
-
检索器利用 embeddings 进行向量相似度搜索
-
找到最相关的文档(比如关于不同宠物的描述)
-
大模型根据这些相关文档和原始问题生成最终答案
- 答案生成过程:
-
检索器找到相关文档
-
文档内容被格式化为上下文
-
大模型根据上下文和问题生成答案
-
最终答案会基于检索到的具体知识,而不是模型的泛化能力
这个过程充分展示了检索增强生成(RAG)的核心理念:检索器负责找到相关信息,而大模型负责理解和生成答案。这种分工使得系统能够提供更准确、更有依据的回答。需要特别强调的是,检索器的准确性直接决定了最终答案的质量 —— 如果检索器无法提供正确的上下文信息,即使是最强大的语言模型也无法生成准确的答案。这就像是在考试中,如果提供给学生的参考资料是错误的或不相关的,那么无论学生多么优秀,也无法得出正确的答案。因此,在构建 RAG 系统时,确保检索器的准确性和可靠性是至关重要的。
RAG 的局限性
虽然 RAG 是一个强大的架构,但也存在一些局限:
-
向量相似度的局限:基于向量相似度的检索可能无法捕捉到语义层面的细微差别,有时会检索到表面相似但实际不相关的内容。
-
上下文窗口限制:由于模型的输入长度限制,我们往往只能提供有限的上下文内容,可能会遗漏重要信息。
-
检索质量依赖于文档质量:如果知识库文档质量不高或不完整,即使检索系统工作正常,也无法提供好的答案。
-
计算成本:向量化和存储大量文档需要较大的计算和存储资源,特别是在大规模应用中。
总结
通过这个简单的程序,我们不仅看到了 RAG 系统的完整实现,更重要的是理解了每个组件的作用和importance。特别是检索器的准确性,它直接决定了整个系统的表现。在实际应用中,除了选择合适的大语言模型,我们更应该关注如何提升检索的准确性,包括:
-
优化文档的切分策略
-
选择合适的 embedding 模型
-
调整向量检索的参数
-
改进相似度计算方法
只有确保检索器能够准确找到相关文档,RAG 系统才能充分发挥其潜力,帮助大语言模型生成更准确的答案。
附:完整程序代码
import os
from dotenv import load_dotenv, dotenv_values
from langchain_openai import AzureChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_core.messages import AIMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import AzureOpenAIEmbeddings
from langchain.schema import StrOutputParser
# Get the directory of the current script
current_dir = os.path.dirname(os.path.abspath(__file__))
# Construct the path to the .env file in the same directory as rag.py
env_path = os.path.join(current_dir, '.env')
# Load environment variables from .env file
load_dotenv(env_path)
# Load .env file contents as a dictionary
env_vars = dotenv_values(env_path)
# Load LangSmith configuration from environment variables
LANGCHAIN_TRACING_V2 = os.getenv("LANGCHAIN_TRACING_V2", "false").lower() == "true"
LANGCHAIN_API_KEY = os.getenv("LANGCHAIN_API_KEY")
from langchain_core.documents import Document
documents = [
Document(
page_content="狗是很好的伴侣,以忠诚和友好而闻名。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫是独立的宠物,通常喜欢自己的空间。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="金鱼是初学者喜欢的宠物,只需要相对简单的照顾。",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="鹦鹉是聪明的鸟类,能够模仿人类说话。",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="兔子是社交动物,需要大量空间来跳跃。",
metadata={"source": "mammal-pets-doc"},
),
]
from langchain_chroma import Chroma
# 设置 Azure OpenAI Embeddings
# 注意:嵌入模型的质量对检索结果有重大影响
# 确保使用适合中文的高质量嵌入模型
embeddings = AzureOpenAIEmbeddings(
azure_endpoint=env_vars.get("AZURE_OPENAI_ENDPOINT"),
azure_deployment=env_vars.get("AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME"),
openai_api_version=env_vars.get("AZURE_OPENAI_EMBEDDING_API_VERSION"),
api_key=env_vars.get("AZURE_OPENAI_API_KEY"),
)
vectorstore = Chroma.from_documents(
documents,
embedding=embeddings,
)
from langchain_core.documents import Document
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 1},
)
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
model = AzureChatOpenAI(
model_name="gpt-4o",
azure_endpoint=env_vars.get("AZURE_OPENAI_ENDPOINT"),
azure_deployment=env_vars.get("AZURE_OPENAI_DEPLOYMENT_NAME"),
openai_api_version=env_vars.get("AZURE_OPENAI_API_VERSION"),
api_key=env_vars.get("AZURE_OPENAI_API_KEY"),
)
template = """
根据提供的上下文回答这个问题。
问题: {question}
上下文:
{context}
回答:
"""
prompt = ChatPromptTemplate.from_template(template)
def rag_chain(question: str) -> str:
# 检索相关文档
retrieved_docs = retriever.invoke(question)
# 将检索到的文档格式化为单个上下文字符串
context = "\n".join(doc.page_content for doc in retrieved_docs)
# 使用问题和上下文格式化提示
formatted_prompt = prompt.format(question=question, context=context)
# 获取模型的响应
response = model.invoke(formatted_prompt)
return response.content
# 使用示例
response = rag_chain("最好的宠物是什么?")
print(response)
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 7
7 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)