人工智能大模型入门分享(一)——利用ollama搭建本地大模型服务(DeepSeek-R1)
DeepSeek, Qwen的大火,是否激发你动手玩大模型的DNA,本分享教你使用Ollama在本地管理使用大模型,并搭配page assit快速搭建Web服务访问大模型,动手操作起来吧!
前言
随着DeepSeek V3/R1 在全世界范围内的爆火,紧接着Qwen Max在Arena榜单上的屠榜,两模型发布前后不到2个月的时间,国产大模型彻彻底底震撼了世界!外网都在感叹: 中国人别卷了,你们开发大模型的速度是认真的嘛~, 那身为骄傲的中国人,我们更应该掌握人工智能大模型的基本知识。如果你还是AI小白的话或只在浏览器中使用过大模型服务,不要紧,这篇文章将结合我的使用经验,教你使用ollama 平台 5步搭建运行在你自己电脑上的本地大模型服务。(温馨提示:本分享是系列分享,会结合我工作生活以及大模型学习经验向大家分享大模型的知识,撒娇打滚求关注~)
Ollama是什么?
首先大家需要了解ollama是什么,简单来说,它就是你的本地大模型管家。如果你是python程序员,必然使用过anaconda管理不同python版本的工具,如果你是js程序员,必然使用过nvm 管理不同node.js版本的工具,如果你不是程序员,也必然使用过电脑管家来管理应用程序。Ollama就是帮你在这台电脑上安装、运行和管理各种大模型的得力助手。
Ollama可以在本地电脑上开启大模型服务,使你可以访问你本地拥有的各种大模型。同时也可以构造api请求,搭建你自己的大模型应用。此外Ollama支持Windows、macOS和Linux三大主流操作系统,无论你是哪个阵营的勇士,都能找到适合自己的武器。关于Ollama的其它优势我这里就不展开了,感兴趣大家可以自行百度。废话不多说,既然这玩意儿这么好用,那我们就赶快在自己电脑上配置Ollama,开始你的大模型之旅吧。
(一)安装Ollama
你可以在任何平台上安装Ollama, 为方便大多数读者,我这里使用的是windows 11安装Ollama。特别注意: 很多人听说大模型要运行在gpu上,ollama可以自动检测本地电脑gpu, 在运行大模型时自动将其移到gpu上,即使你电脑没有gpu也不用在意, ollama也会利用cpu计算返回大模型响应,不过响应速度会慢很多,而且不太适合参数大于10B的模型,容易烧电脑。
首先下载安装包,进入ollama 官网 , 点击Download, 根据你的平台安装响应ollama, 我这里是windows 11 ,选windows。
鉴于国内网络不稳定,有时出现连接不上ollama下载地址的情况,我这里也把最新版本的ollama分享到我的阿里云盘上,大家可以自取下载:
OllamaSetup.exe https://www.alipan.com/s/QjLe1ixGtLB 提取码: 1hd6
下载完成后是一个OllamaSetup.exe文件,我们直接双击运行, 一路install即可。
安装完成后,运行cmd 打开命令行窗口输入 ollama, 出现下图所示即为运行成功。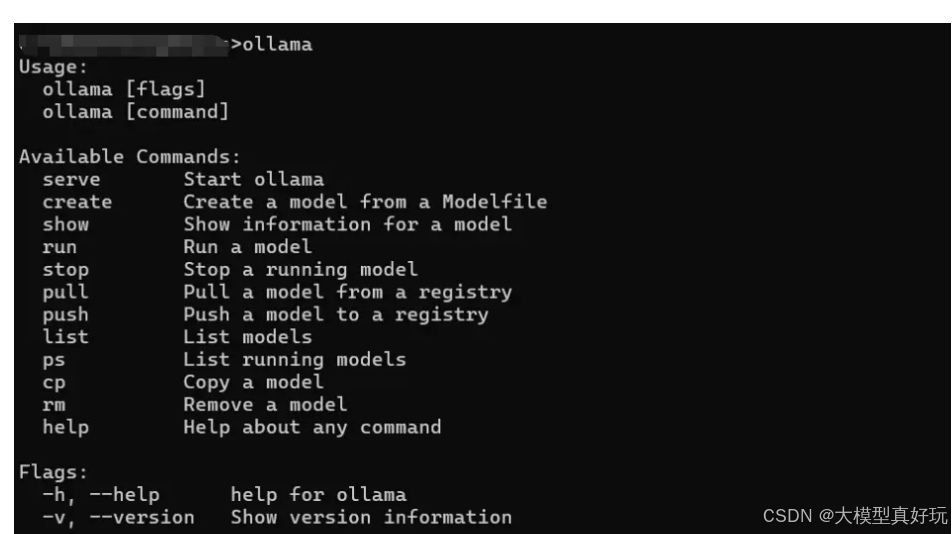
(二)Ollama下载大模型,给你的Ollama装上“大脑”
Ollama可以管理特别多的模型,我们可以在ollama 官方网站上点击Models查看ollama支持的模型,也可以在搜索框定位所需模型。我们可以看到deepseek-r1, phi4这些模型都支持。这里以deepseek-r1(7b,70亿参数,占用空间4.7GB )为例(别骂啦,手头电脑性能有限)。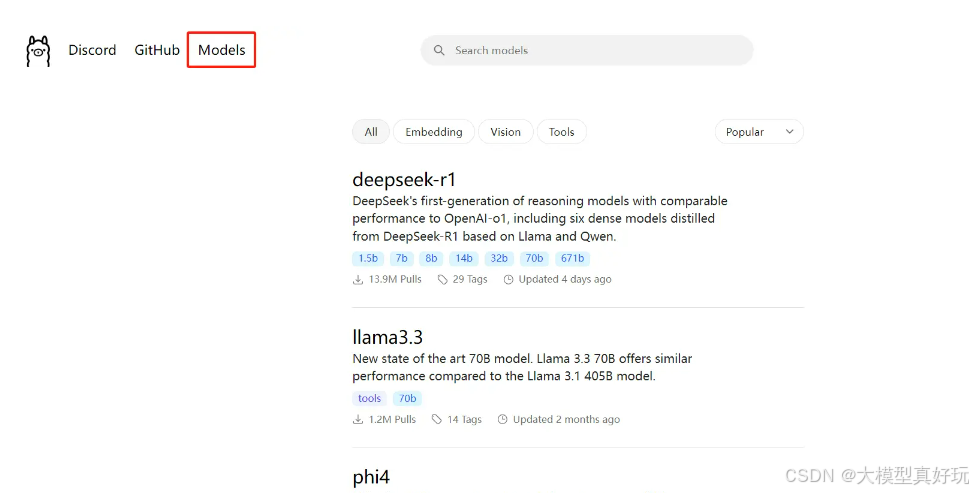
在下载模型前我们需要进行一个设置,默认ollama会把模型下载到C盘C:\Users\<username>\.ollama\models中,我们不想占用系统盘的空间。首先应该设置环境变量OLLAMA_MODELS指定大模型要保存的路径,修改之后要Quit Ollama程序(右下角小任务栏)或者重启电脑,再运行Ollama(这一步非常重要,否则配置可能不会生效)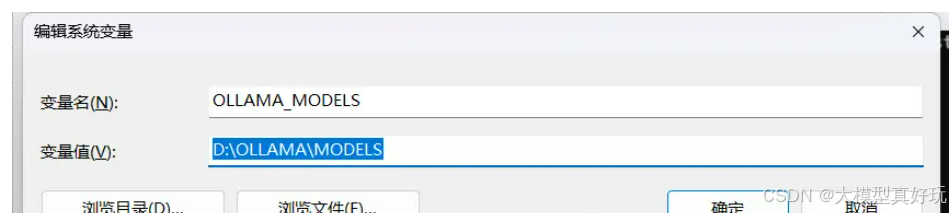
我们在搜索框搜索deepseek-r1, 点进去,可以看到其中有不同的参数,而且有下载模型需要执行的命令。打开命令行cmd,执行ollama run deepseek-r1即可下载模型。
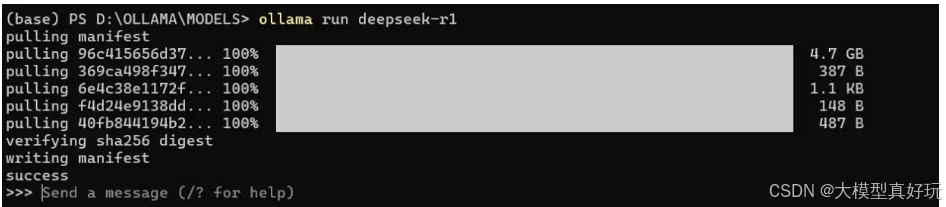
下载的过程如下图所示:

下载完成后ollama 会自动运行大模型,你就可以愉快的与大模型开启对话啦,当然我们也可以在我们配置的OLLAMA_MODELS环境变量对应的文件夹中找到相关模型,其中bolbs文件夹存储大模型文件,manifest文件夹存储大模型文件的相关说明,如图所示:
bolbs下文件: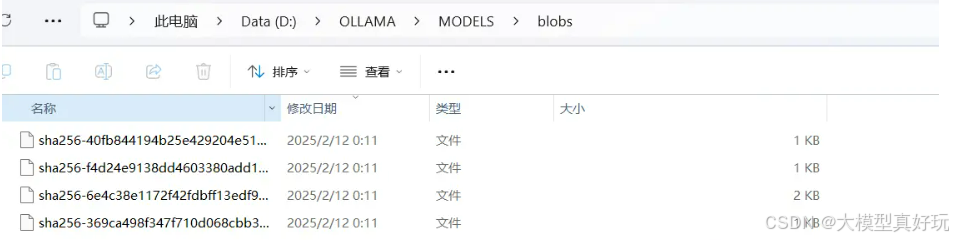
manifest下文件:
此刻我们就成功安装了大模型DeepSeek-R1 (其实Ollama 提供的deepseek-r1小参数版本是在qwen和llama基础上通过deepseek-r1蒸馏得到的,这个我们后面会出deepseek-r1/v3相关分享,大家点个关注哦)。
(三)运行模型,体会大模型“真好玩”!
执行完ollama run deepseek-r1指令之后,我们发现大模型已经运行起来啦,按照提示 send a message,我们问大模型一个简单的问题:1+1等于?, 大模型会输出如下回答:
还真是神奇,这里我们使用的是DeepSeek R1模型(相当于我们在DeepSeek网站问答时勾上深度思考),所以回答还有 think 标签包含了模型的思考过程。(之后也会出文章分享如何训练有思考能力的模型),看到这里大家是不是觉着ollama 超级方便,都跃跃欲试了。
这里出个小练习:按照上面步骤在本地部署qwen2.5-coder模型,相信大家都分分钟搞定。(qwen模型的输出就不带有think了,毕竟不是思考模型)
(四)工欲善其事必先利其器,Ollama 常用命令
Ollama是大模型开发利器,掌握基础使用后,我们进一步学习Ollama相关知识。Ollama作为大模型管理工具自然有很多功能,可以使用 ollama -h显示, 我们结合工作开发中常用的几条来说明:
ollama list: 列出本地安装的所有大模型
ollama restart: 重启ollama服务
ollama update: 更新ollama到最新版本
ollama serve: 启动 Ollama 服务以在后台运行(一般会自启动)
ollama pull <model_name>: 从远程下载大模型,只下载不运行
ollama run <model_name>: 运行指定大模型,若本地没有,默认调用ollama pull先从远程下载后再运行
ollama rm <model_name>: 删除本地的指定大模型
Ollama 还支持导入导出模型,服务配置,api调用等众多功能,以后会在其余分享中实践和大家一起学习了解,大家也可以参考菜鸟教程的Ollama中文文档 快速学习。
(五)给大模型穿新衣,三步搭建本地大模型Web
经过上面分享我们可以轻松使用ollama 在本地运行大模型啦,但目前还有一个小问题,我们还只能在黑框框(命令行)中与大模型交互,对输出结果的查看很不直观,别着急,下面两步带你在浏览器中访问本地大模型:
Ollama开放了11434端口,网页端可以通过对 http://127.0.0.1:11434
发起请求获得结果。
1、在谷歌浏览器下载Page Assit扩展
首先你需要在谷歌浏览器下载Page Assit扩展, 如果无法进入谷歌浏览器扩展市场的可以访问 Crx扩展 网址,按图中所示操作安装Page Assit 扩展,该网站有详细说明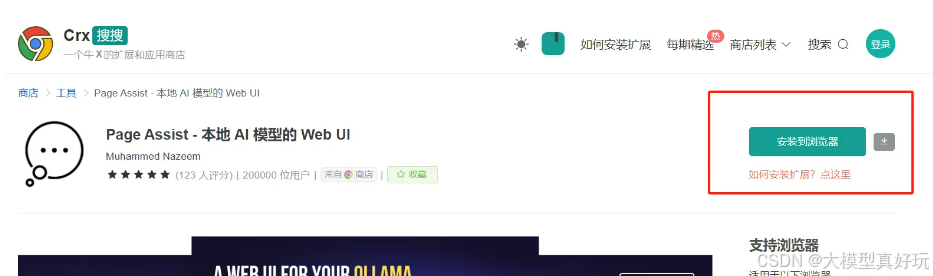
安装完成后点击浏览器扩展按钮我们可以发现Page Assist扩展,点击会打开一个新的标签页,就是我们熟悉的大模型对话风格: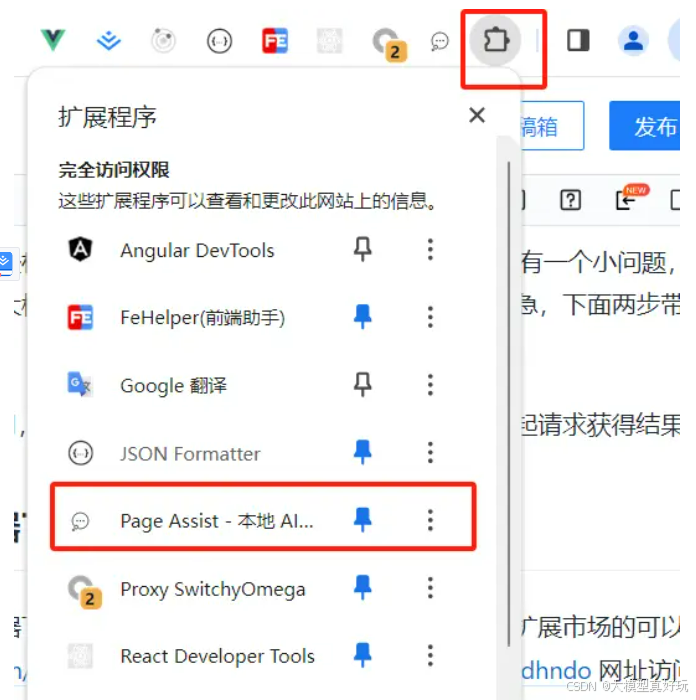
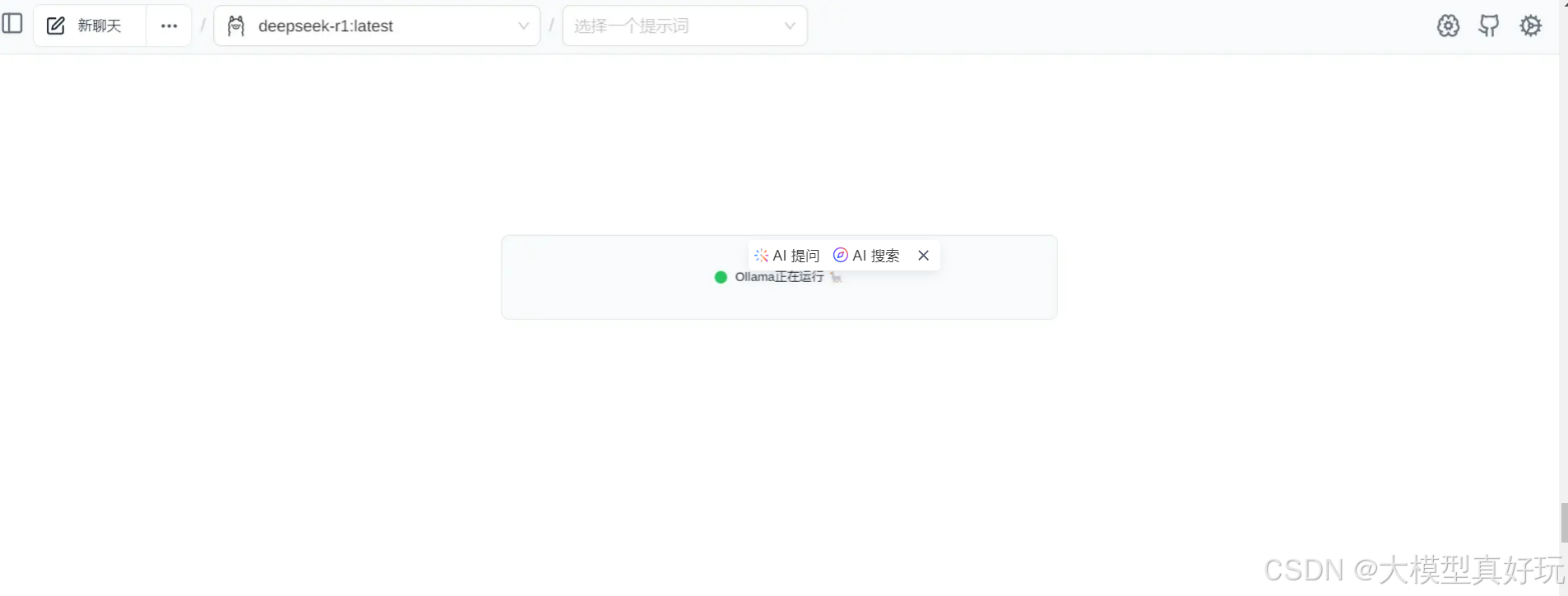
2、配置Page Assist访问大模型
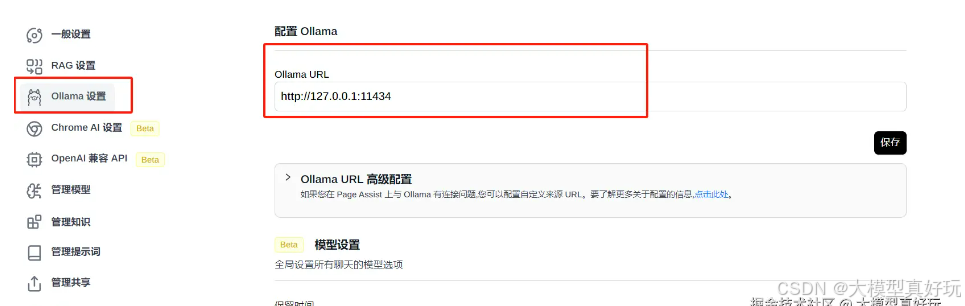
Page Assit可以自动识别本地正在运行的Ollama,如果没有正确识别,点击右上角的设置按钮,在Ollama设置中把Ollama URL中填入 http://127.0.0.1:11434
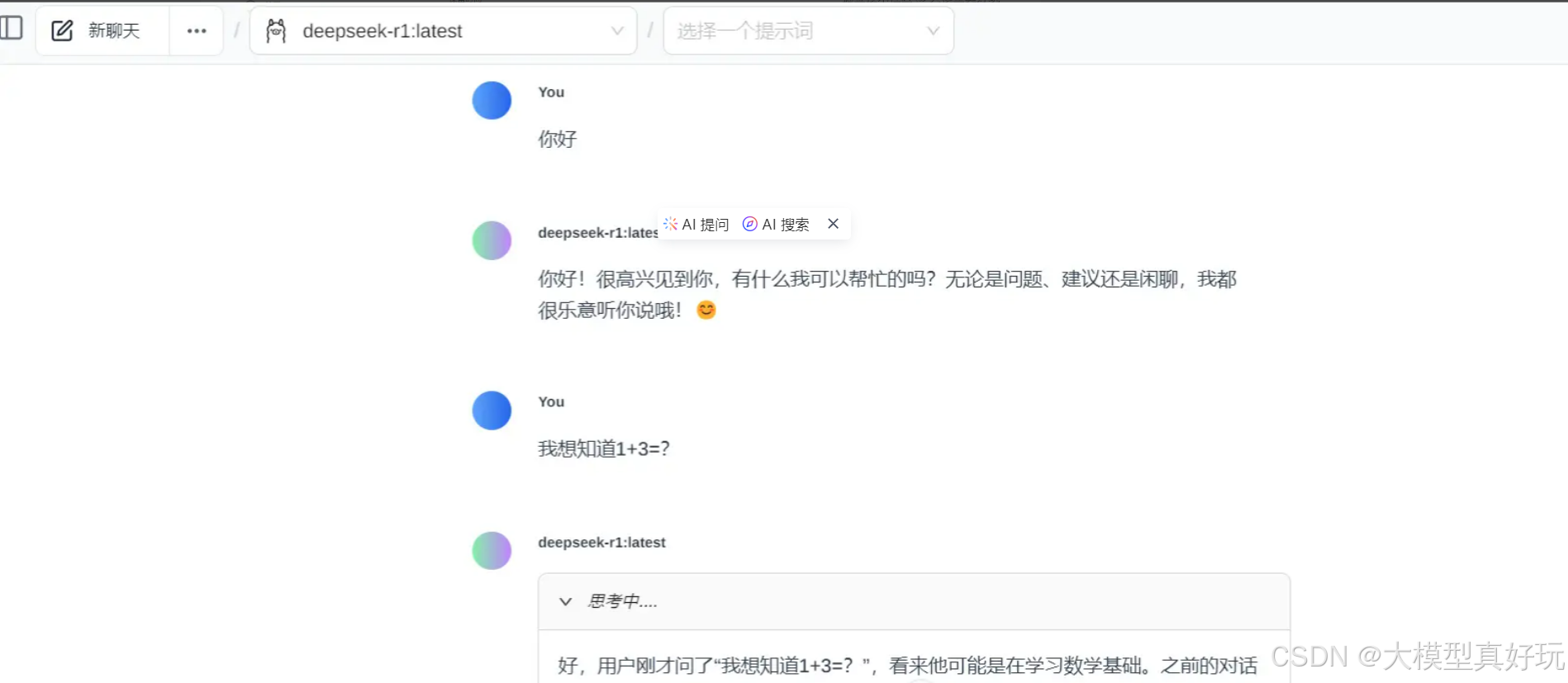
在Page Assit窗口我们可以选择需要对话的本地大模型,并在对话框中与大模型交互,当然,关于Page Assist还有好多功能可以使用包括提示词设置,知识库上传等,这里就不详细展开,等待大家自行探索了。
(六)总结
以上就是关于如何使用Ollama搭建本地大模型服务并在浏览器中Web访问的分享,内容还是很简单的,感兴趣大家可关注我微信公众号: 大模型真好玩, 实时分享工作学习中的大模型相关的经验~(透露一下:以后还会写从0到1利用Pytorch 编写大模型的教程,手把手教大家编写并训练属于自己的大模型)
小技巧——离线环境下使用ollama
工作中有时遇到需要在离线内网环境下搭建大模型服务,其实也很简单,先在联网电脑上下载ollama,pull下来所需模型,然后将ollama和配置的OLLAMA_MODELS文件夹内容拷贝到离线内网环境中,在离线内网环境中安装Ollama并配置OLLAMA_MODELS环境变量为拷贝文件夹目录,这样就可以轻松在离线环境中使用Ollama啦。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 22
22 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)