聊聊心理咨询大模型——SoulChat2.0
过往的工作没有充分考虑到不同的心理咨询师具有不同的个人风格,包括语言风格和疗法风格等等,从而导致微调好的心理健康LLMs难以满足来访者对于不同咨询风格咨询师的个人需求。此外,将不同咨询风格的多轮对话数据进行混合微调容易造成LLM回复的不稳定。
聊聊心理咨询大模型——SoulChat2.0
原创 阿郎小哥 阿郎小哥的随笔驿站 2024年12月30日 08:55 湖北
概述
出发点
过往的工作没有充分考虑到不同的心理咨询师具有不同的个人风格,包括语言风格和疗法风格等等,从而导致微调好的心理健康LLMs难以满足来访者对于不同咨询风格咨询师的个人需求。此外,将不同咨询风格的多轮对话数据进行混合微调容易造成LLM回复的不稳定。
解决方案
华南理工大学未来技术学院-广东省数字孪生人重点实验室在灵心大模型(SoulChat1.0)基础上,首次推出了心理咨询师数字孪生大语言模型SoulChat2.0[1]。
心理咨询师数字孪生大语言模型SoulChat2.0包含2个部分:
-
心理咨询师数字孪生数据生成
-
心理咨询师数字孪生建模
总的来说,从高质量的训练数据到模型训练,两个方面。主要的是集中在前者,毕竟设计的出发点是设计出咨询师的不同咨询风格。
设计
数据生成
官方描述:
要实现特定的心理咨询师的数字孪生,前提是能获取该心理咨询师的大量咨询案例,但是这对于心理咨询师个体而言,难度极大。一方面,需要考虑心理咨询的伦理要求和隐私保护,另一方面,数据的采集也非常繁琐。为此,有必要建立一种仅需少量咨询案例的心理咨询师数字孪生数据生成框架。心理咨询师的每个咨询案例都体现了本人的语言风格与咨询技术应用方式,这可以借助于现有的先进的LLMs的语言总结能力去提取。同时,为了保证生成的数据的多样性,需要尽可能建模用户的个性特质,我们以常用的大五人格为参考,对单轮对话咨询数据库中的来访者进行了大五人格分析。通过综合真实世界咨询师的语言风格、咨询技术、来访者大五人格,结合真实世界咨询案例,对于单轮对话进行心理咨询师数字孪生数据生成。采取我们的框架生成的多轮对话数据,能有效表征特定心理咨询师的语言风格与咨询技术应用方式。为了综合考虑成本与效果,我们设定了用于心理咨询师数字孪生数据生成的单轮对话咨询数据库的规模为5000个,特定心理咨询师的咨询案例数目设定为12个(为保证低成本,一般不多于20个)。最终,只需要给定任意心理咨询师的少量咨询案例,我们的框架即可快速生成批量用于该心理咨询师数字孪生建模的咨询案例。
其流程如下所示(框出的部分):
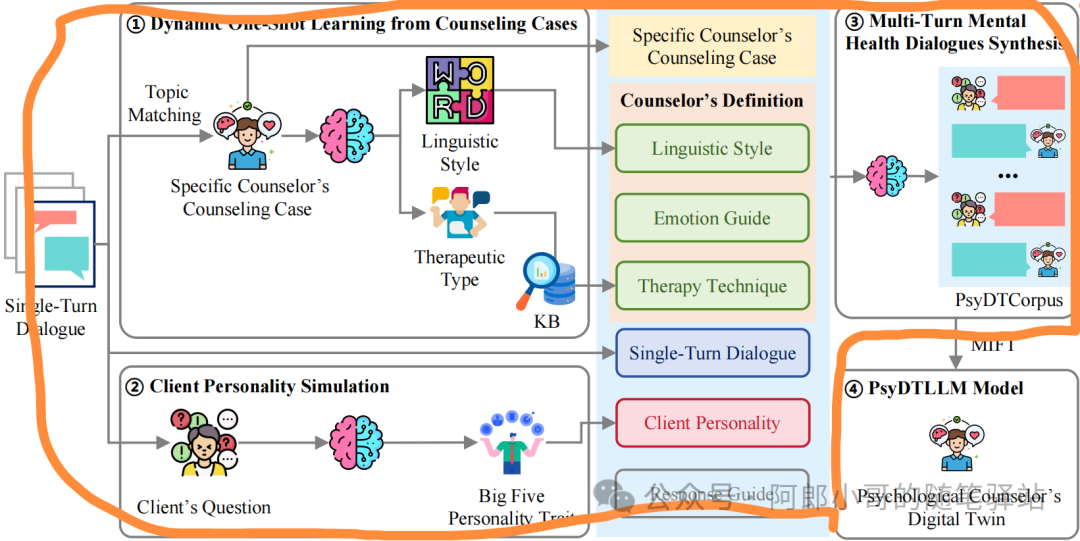
通过一个完善的流程,生成训练数据,最后提供给模型训练。最终生成的数据:PyDTCurpus[2]。
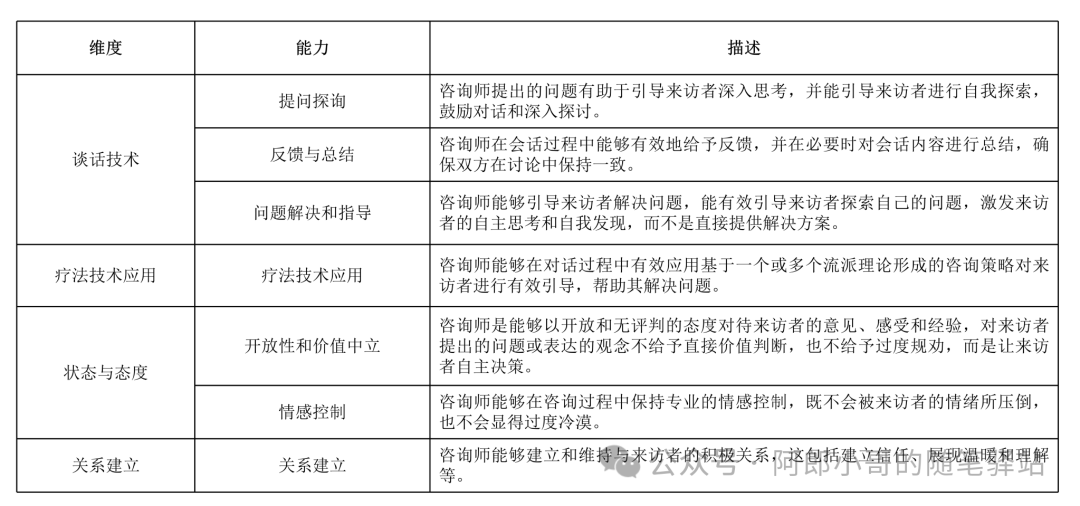
在官方还提供了专业的评估;仔细的分析了下,对于这些评估维度,是可以借鉴并直接拿来用的。如下所示:
小结
虽然官方并没有放出来数据生成的代码,当然一般都不会放出来的,但是这个流程是可以借鉴的,而且对于最后的评估策略还是可以很好的借鉴参考。在这个步骤中,最关键的就是生成高质量的咨询师的个性化的数据。毕竟后面的模型微调,就是依赖于这个数据质量。
微调模型
在官方文档也叫"心理咨询师数字孪生建模",基于生成的数据,在各个基座模型上训练,官方提供了完备的训练脚本,按说明执行即可:
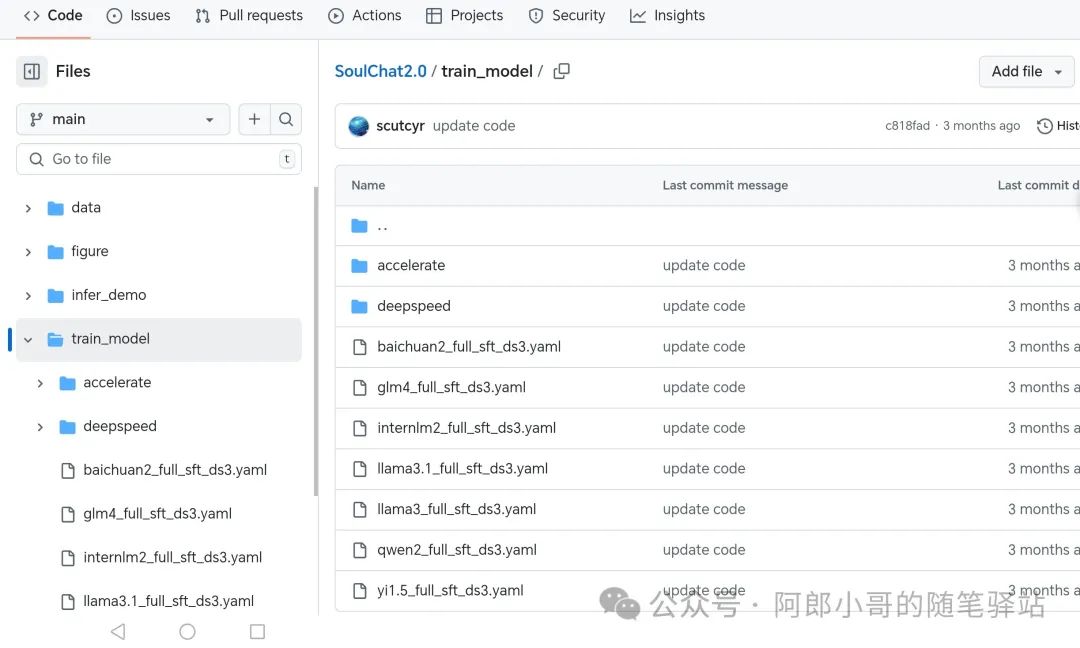
提供了基于deepspeed的训练,而且还支持到了offload级别,毕竟是全参数,有了offload的支持,哪怕GPU参数不够也是能用CPU顶上。官方的训练说明比较到位,参考说明即可。
不过官方提供了训练好的模型,可以直接下载使用。

如果有硬件条件的话,还是可以自己训练一遍,看看最终的效果,毕竟官方给出的训练脚本已经很详细了。
小结
在整个方案里面,主要的就是数据生成了,当然源码肯定没有放出来;而后就是基于数据做的训练,这里没什么特别的,就是正常的微调而已,不过训练脚本是可以参考一下的,还是很完善了。但我个人的话,对于专业评估部分来说,我觉得也是不错的,可以借鉴一下。毕竟整个的核心点就是在生成的数据质量。
但我个人对于最终是否能有理想中的效果,表示比较怀疑,毕竟模型最终的效果依赖于所谓的个性化的咨询师画像数据,还是有待商榷的;不过还是那句,最终的中西点还是在数据生成那部分。整个模型库最终开源的是设计流程和训练后模型,并没有源码相关;对于我们来说,更多的还是借鉴以及试玩,而没有实际的源码。
Reference
[1]
SoulChat2.0: https://github.com/scutcyr/SoulChat2.0
[2]
PyDTCurpus: https://modelscope.cn/datasets/YIRONGCHEN/PsyDTCorpus

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 20
20 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)