【AI大模型】不知道部署哪个版本?一文看懂Qwen3本地部署的配置要求,收藏这一篇就够了!!
本次Qwen3系列开源模型一共发布了8个不同尺寸,尺寸越大,显存占用越高。8个模型中有6个Dense(密集)模型,2个MoE(混合专家)模型。密集模型在推理过程中会激活所有参数,而 MoE 模型则采用稀疏激活策略,每次前向传递只激活一部分专家参数,在有限的计算预算下性能更高。
模型规模
本次Qwen3系列开源模型一共发布了8个不同尺寸,尺寸越大,显存占用越高。
8个模型中有6个Dense(密集)模型,2个MoE(混合专家)模型。密集模型在推理过程中会激活所有参数,而 MoE 模型则采用稀疏激活策略,每次前向传递只激活一部分专家参数,在有限的计算预算下性能更高。

量化权重
量化是指降低模型权重的数值精度,以显著减少显存占用和存储空间并可能提高推理速度的技术。未量化的模型显存占用非常高,很难本地部署。
本地部署起来最方便的Ollama,提供了三种量化权重的Qwen3模型,分别是Q4_K_M(默认)、Q8_0和FP16。
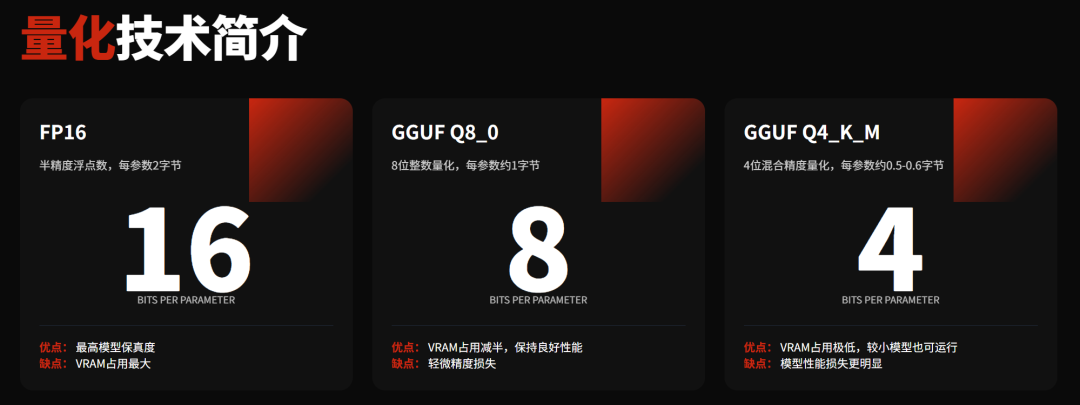
KV缓存
KV缓存是大语言模型推理过程中的一个重要技术概念。简单来说,如果没有KV缓存,每生成一个新token,整个序列的注意力都要重新计算,一次生成过程的计算量将呈指数增长。而有了KV缓存,则只需要计算新token的向量再与缓存交互即可,大大减少了计算量。
KV缓存是让大语言模型实用化的关键技术,但也是显存消耗的主要来源之一。KV缓存的大小随上下文长度线性增长,上下文越长,显存占用越高。
Qwen3系列模型原生上下文长度32K,4B及以上尺寸可扩展至128K。但这个上下文长度对消费级显卡来说不太现实,一般高端显卡(24GB+)可能只能处理8K-16K的上下文。
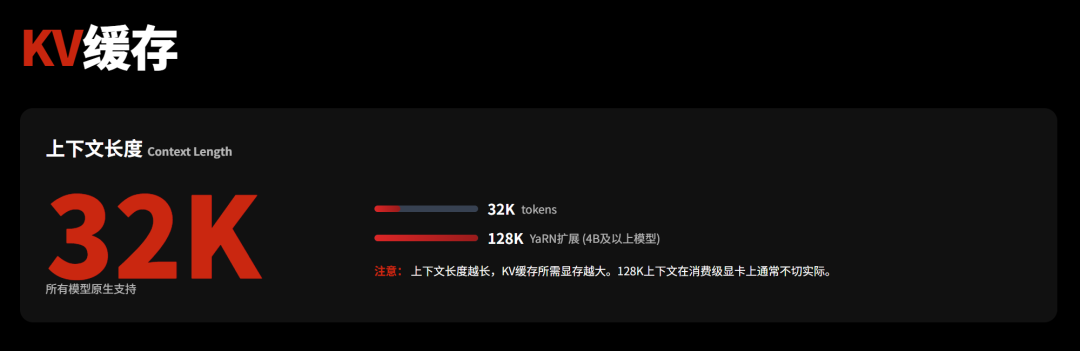
了解了上面三个基本信息和概念,接下来就要说到显存了。
显存占用
本地部署运行大语言模型,显存占用的构成主要来源于三部分:模型权重(包括参数规模和量化)、KV缓存、激活值与开销。
模型权重就是存储/加载模型参数所需的空间,取决于模型的参数量和使用的数值精度(即量化级别)。例如,一个 140 亿参数的模型,如果使用 FP16(半精度浮点数,每个参数 2 字节)存储,大约需要 28GB 显存。
KV缓存与以序列长度(上下文长度)、批处理大小(Batch Size)、模型维度(层数、隐藏层大小)以及缓存精度(不必与模型权重精度相同,通常为FP16 精度)等多个因素密切相关,可以按照公式VRAMkvcache≈2×层数×隐藏层维度×序列长度×批处理大小×每个值的字节数进行估算,这里就不做展开了。
激活值与开销即推理过程中中间计算结果(激活值)以及运行框架(如 CUDA 核函数、驱动程序、操作系统等)自身占用的显存,一般也就1-2G左右。
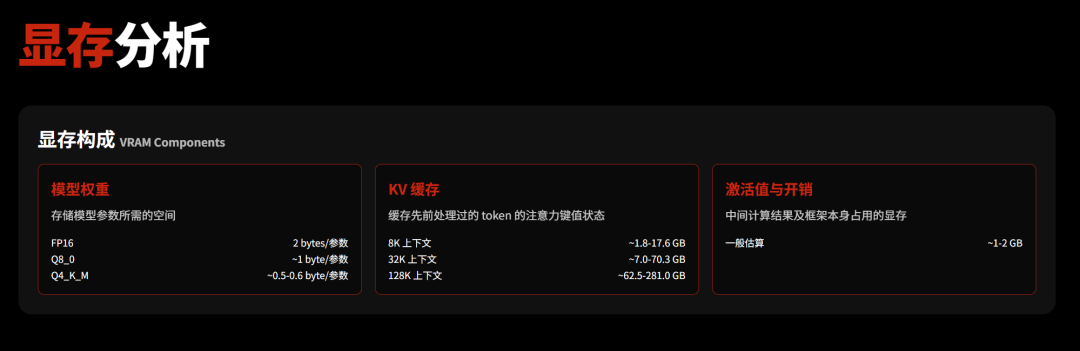
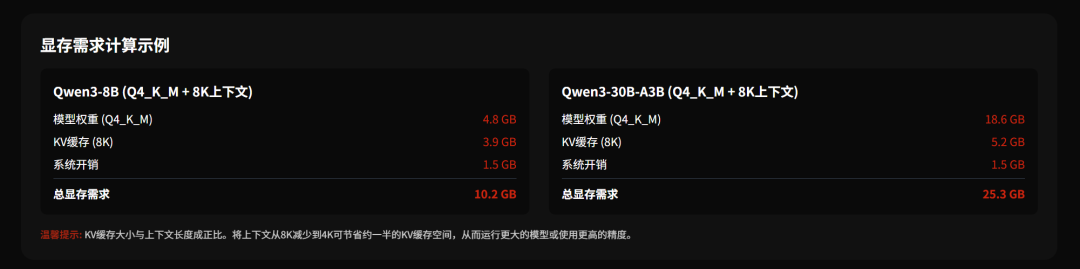
对于Qwen3系列模型,可以直接查看下面这个表格,表格中上下文长度统一按照8K计算。
例如,部署Q4_K_M的Qwen3-32B模型,所需要的显存大概为约19.8G(模型权重)+约14G(8K上下文KV缓存)+约1~2G(开销),一共大约35.3G。
当然,提前防杠一下。在实际使用过程中,上下文是根据实际情况变化并逐渐累积的,并不是一开始就直接占用掉大概14G的空间,所以即便没有达到表格中写的总需求,也并不代表一点也不能用。
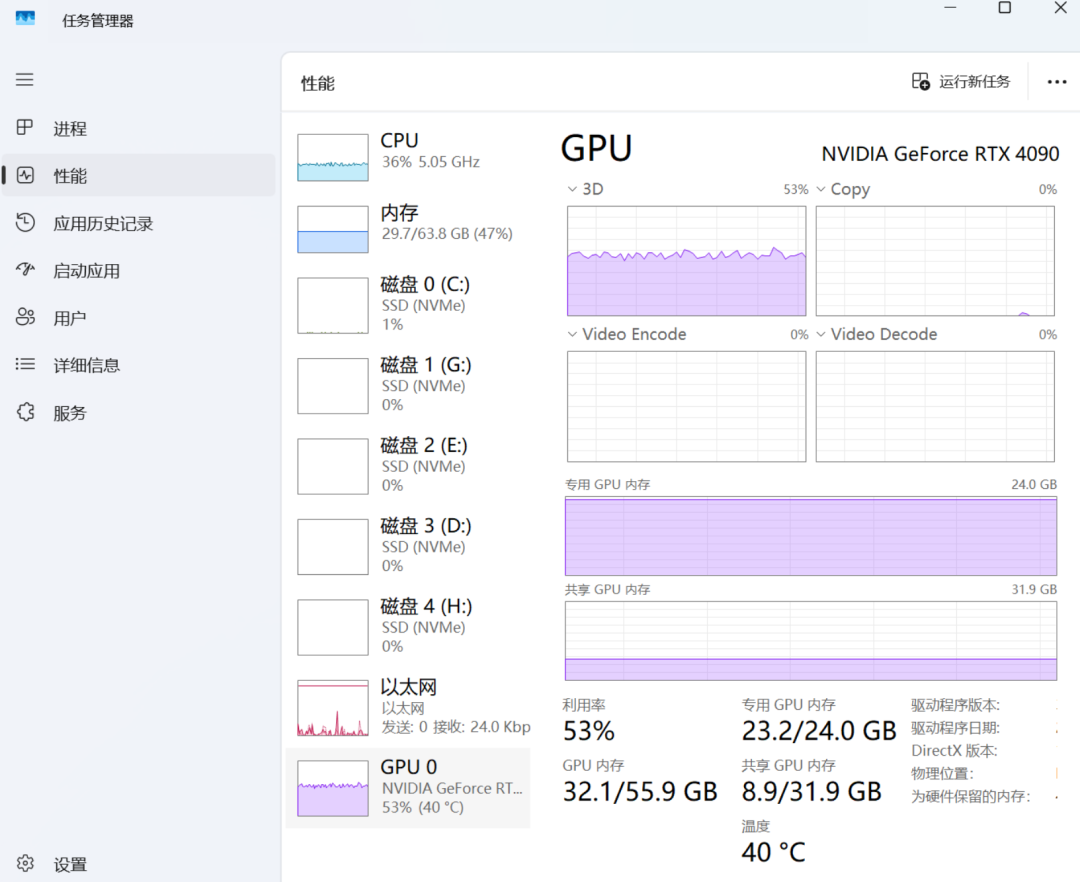
但是,如果你本地部署完大模型,刚开始执行一个简单小任务就是下面这种显存拉满的状态,那大概率可以判断它后面很难支持复杂任务,最好换成尺寸更小的模型或者低精度量化模型。
另外,对于混合专家模型,需要单独补充说明一下。在显存占用方面,它和密集模型并没有太大区别,装入显存时依旧需要为全部参数分配显存空间,但因为只有一部分参数被激活并参与实际计算,推理速度会比同等显存占用的密集模型快得多。装入显存时,看总参数量;运行速度时,看激活参数量。
消费级显卡兼容
典型的消费级显卡和模型的兼容可以查看下面这张图:
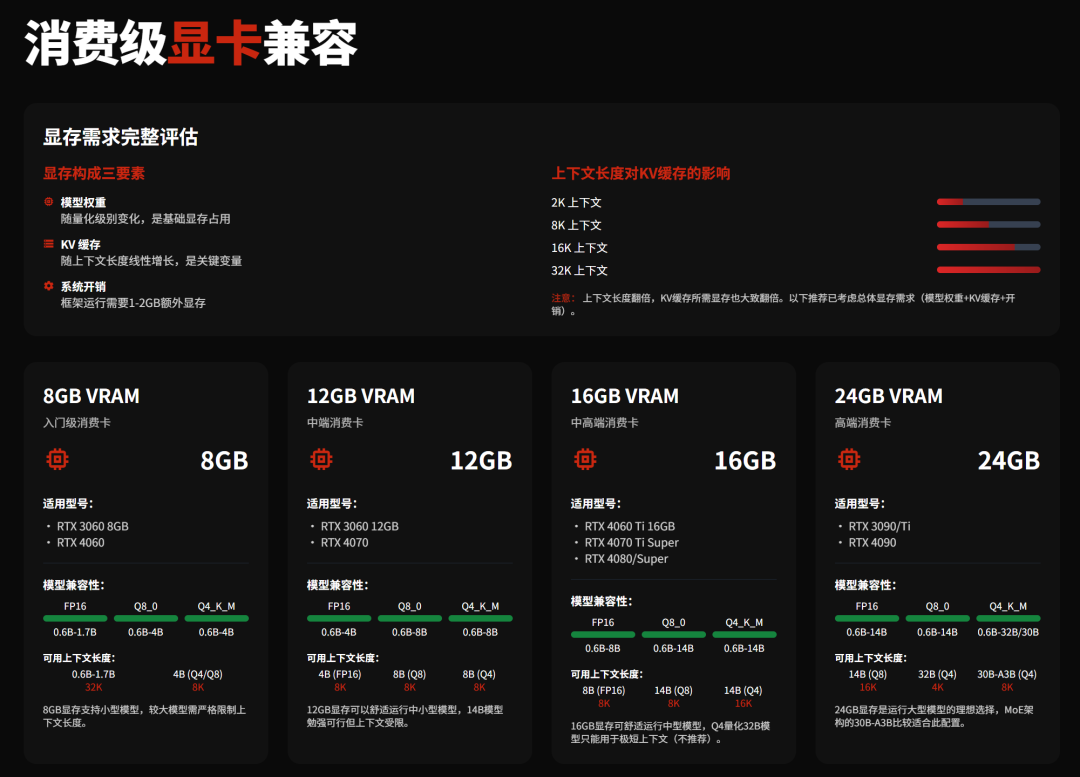
理论上,对于24G显存的高端显卡来说,跟Q4_K_M量化的Qwen3-30B-A3B在显存占用上十分契合。如果你使用3090/4090,可以优先测试一下这个模型。
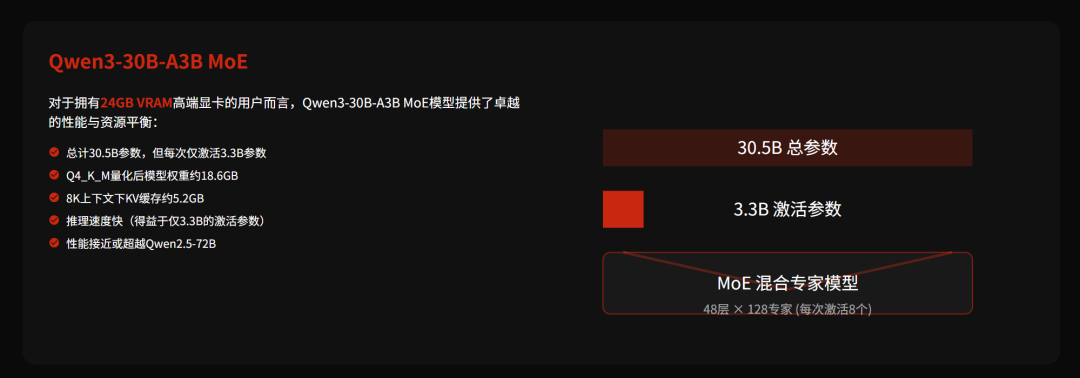
从参数综合来看,不同配置对本地部署Qwen3模型的选择可以参考这张图:

不同尺寸&量化权重Qwen3实际测试
依旧是上篇文章的测试题目:Qwen3值不值得普通用户本地部署?3个落地场景,30道题,300条回答,10模型大混测,豆包AI打分!
补充了不同尺寸和量化权重的Qwen3模型,供大家参考。
(PS:非严谨测试,结果仅供参考;模型名称未标明精度的即为默认Q4_K_M。)

文案项目:
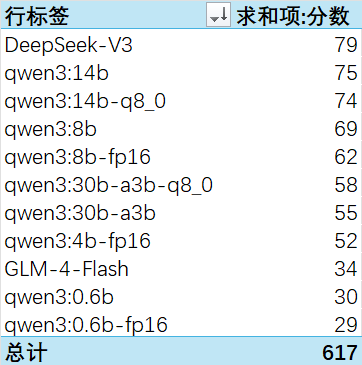
总结项目:
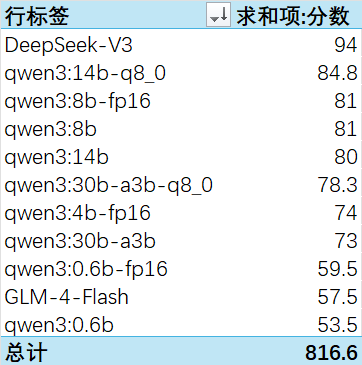
弱智吧项目:
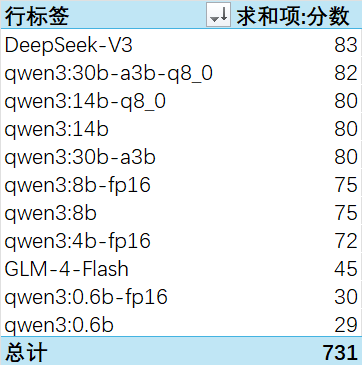
综合打分:
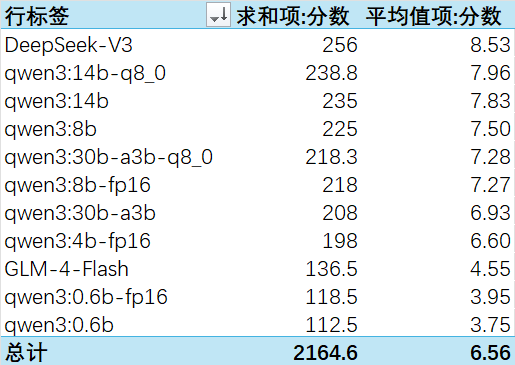
这三个项目中,综合评分依旧是全量DeepSeek-V3(硅基流动API)最高;因为加入了0.6B小模型,上篇测试中综合评分最低的GLM-4-Flash提升到倒数第三,但0.6B模型跟其他模型的差距并没有预想那么大;中间模型各位可自行参考。
测试详细内容见:https://ilovezhiwai.feishu.cn/wiki/TboCwTXPVi4vQqkHucuc7Dq4nkI
结合这几个我自己相对高频场景下的测试结果和理论数据,我个人最终会倾向选择Qwen3-14B (Q8_0)。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 31
31 0
0- 0



 已为社区贡献100条内容
已为社区贡献100条内容

所有评论(0)