
用vLLM部署DeepSeek,算力减半,吞吐量剧增。
它支持分布式张量并行推理和服务,利用先进的技术在多个GPU上优化性能,其核心功能基于Megatron-LM的张量并行算法,允许有效模型分布。引擎参数请查询网站:https://docs.vllm.ai/en/latest/serving/engine_args.html。高效的企业生产环境应该使用的一般都采用 vllm、sglang 进行部署,本文是用 vLLM 部署 DeepSeek-R1模型。
前言:
为什么要用VLLM呢?
Ollama非常方便快捷,适合个人快速部署使用,高并发的场景下就捉襟见肘了!
高效的企业生产环境应该使用的一般都采用 vllm、sglang 进行部署,本文是用 vLLM 部署 DeepSeek-R1模型。
vLLM 是一个开源的大型语言模型(LLM)推理和服务框架,它强调速度和易用性,能够即开即用。它支持分布式张量并行推理和服务,利用先进的技术在多个GPU上优化性能,其核心功能基于Megatron-LM的张量并行算法,允许有效模型分布。此外,vLLM 还支持在线服务的流水线并行作为测试版功能,增强了部署选项的灵活性。
VLLM 的核心和特点:
vLLM 设计为灵活易用,提供以下功能:
- 与流行的HuggingFace模型无缝集成
- 通过各种解码算法(包括并行采样和束搜索)实现高吞吐量服务
- 在分布式推理中支持张量和流水线并行
- 支持实时应用的流式输出
- 兼容NVIDIA和AMD GPU
- 提供OpenAI兼容的API服务器
- 实验性功能,如前缀缓存和多lora支持。
vLLM 还提供了实验性支持视觉语言模型(VLMs),并强调开发过程的协作性质。核心开发团队与更广泛的社区一起,为生态系统中支持的第三方模型的稳健性和多样性做出贡献。
vLLM 通常在处理并发请求方面表现优异,特别是在企业级应用中,需要高并发的场景。它利用PagedAttention技术进行细粒度的资源管理,实现显著的吞吐量改进。vLLM 的效率在于其能够高效处理多个并发请求,这使其非常适合高需求场景。
vLLM 文档:https://docs.vllm.ai/en/latest/index.html 如果要进一步可以到这里看一下文档
准备环境:
Ubuntu 20.04
环境配置:Ubuntu 20.04, Driver 525.105.17, Python 3.8, CUDA 12.0, cuDNN 8
算力类型:两卡GPU基础型 - 2*16GB+ | 16+TFlops SP | CPU - 16 核 | 内存 - 64GB
安装 Conda
使用 conda 创建 python 环境,直接贴脚本:
-
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh && chmod +x Miniconda3-latest-Linux-x86_64.sh
-
./Miniconda3-latest-Linux-x86_64.sh -b
-
source /root/miniconda3/bin/activate
-
conda init
-
conda config --set auto_activate_base false
使用 vLLM 部署 DeepSeek-R1
使用 conda 创建 python 环境,命令如下:
-
conda create -n vllm python=3.12 -y
-
conda activate vllm
安装 vllm、modelscope,命令如下:
-
pip install vllm modelscope
使用 modelscope 下载 DeepSeek-R1 模型,命令如下:
-
mkdir -p /data/models && modelscope download --model 'deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B' --local_dir '/data/models/DeepSeek-R1-Distill-Qwen-1.5B'
参考:https://modelscope.cn/docs/models/download
使用 vllm 启动 deepseek 模型,命令如下:
-
vllm serve "/data/models/DeepSeek-R1-Distill-Qwen-1.5B" --served-model-name "DeepSeek-R1" --load-format "safetensors" --gpu-memory-utilization 0.8 --tensor-parallel-size 2 --dtype half --port 8000
-
如果遇到“Bfloat16 is only supported on GPUs with compute capability of at least 8.0. Your Tesla T4 GPU has compute capability 7.5. You can use float16 instead by explicitly setting the`dtype` flag in CLI, for example: --dtype=half.”警告,根据警告添加参数即可。
备注:
-
--tensor-parallel-size 和 GPU 数量设置一致
-
--gpu-memory-utilization 控制使用显存的百分比
-
--served-model-name API 中使用的模型名称
引擎参数请查询网站:https://docs.vllm.ai/en/latest/serving/engine_args.html
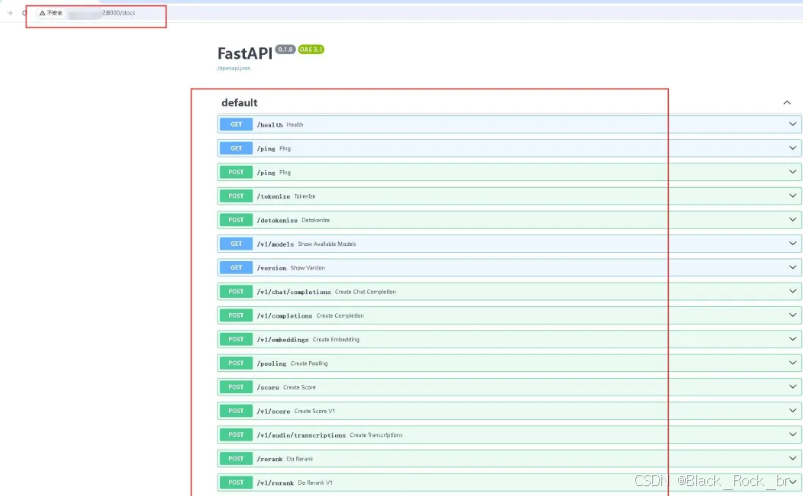
浏览器打开:http://ip:8000/
接口文档:http://ip:8000/docs
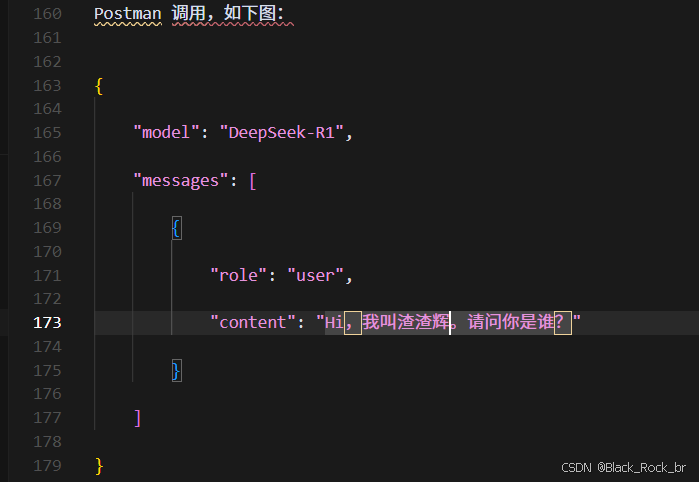
-
wget https://raw.githubusercontent.com/vllm-project/vllm/refs/heads/main/benchmarks/benchmark_utils.py
-
wget https://raw.githubusercontent.com/vllm-project/vllm/refs/heads/main/benchmarks/benchmark_throughput.py
执行命令如下:
-
python benchmark_throughput.py --model "/data/models/DeepSeek-R1-Distill-Qwen-1.5B" --backend vllm --input-len 128 --output-len 512 --num-prompts 50 --seed 1100 --dtype half
结果:Throughput: 2.43 requests/s, 1669.25 total tokens/s, 1235.01 output tokens/s

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)