Valley:字节跳动开源小体积的多模态模型,在小于 10B 参数的模型中排名第二
Valley 是字节跳动推出的多模态大模型,能够处理文本、图像和视频数据,在电子商务和短视频领域表现优异,并在 OpenCompass 测试中排名第二。
·
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日跟你分享最新的 AI 资讯和开源应用,也会不定期分享自己的想法和开源实例,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
原文链接:https://mp.weixin.qq.com/s/-W-nCb9_PzZokttQT01fpw
🚀 快速阅读
- 功能:Valley 能够处理文本、图像和视频数据,支持多种多模态任务。
- 性能:在电子商务和短视频基准测试中表现优异,OpenCompass 测试中排名第二。
- 技术:结合 LargeMLP 和 ConvAdapter,引入 VisionEncoder 增强模型性能。
正文(附运行示例)
Valley 是什么
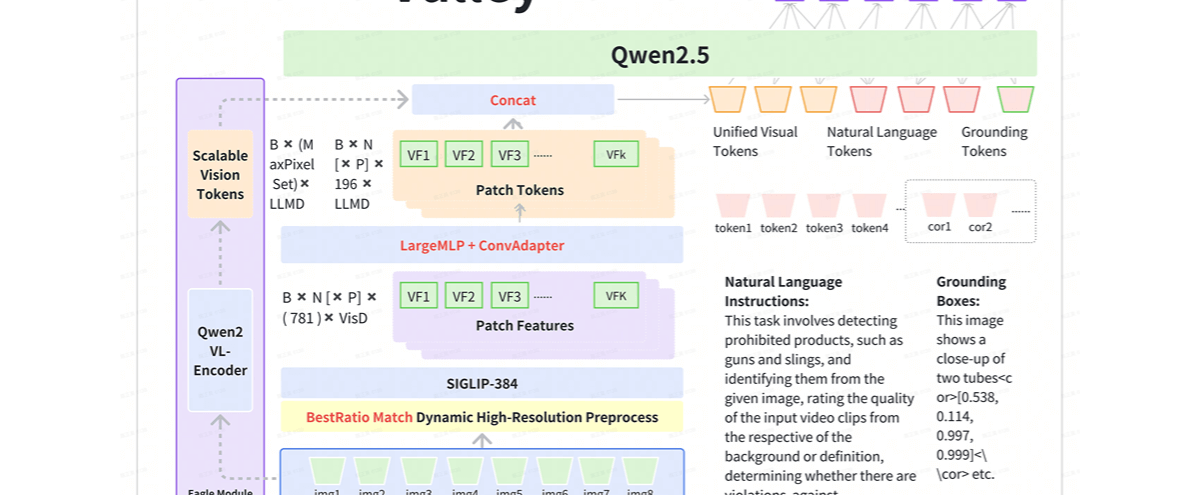
Valley 是字节跳动推出的多模态大模型,专门用于处理涉及文本、图像和视频数据的多样化任务。该模型在内部电子商务和短视频基准测试中取得了最佳成绩,并在 OpenCompass 测试中展现出色性能,尤其是在小于 10B 参数规模的模型中排名第二。
Valley-Eagle 版本基于引入 VisionEncoder 增强模型在极端场景下的性能,能灵活调整令牌数量,并与原始视觉令牌并行处理。这使得 Valley 在处理复杂多模态数据时表现出色,尤其是在需要高效处理大量视觉数据的场景中。
Valley 的主要功能
- 多模态理解:能处理文本、图像和视频数据,提供对不同模态数据的深入理解。
- 任务处理:支持多种涉及多模态数据的任务,如图像和视频描述、内容分析等。
- 性能优化:在内部基准测试和 OpenCompass 测试中展现出色性能,特别是在电子商务和短视频领域。
- 模型扩展性:引入 VisionEncoder,Valley 能灵活调整令牌数量,增强在极端场景下的性能。
Valley 的技术原理
- LargeMLP 和 ConvAdapter:结合 LargeMLP(大型多层感知机)和 ConvAdapter(卷积适配器)构建投影器,有助于模型在处理视觉数据时的性能。
- VisionEncoder:Valley-Eagle 版本引入 VisionEncoder,一个额外的编码器,能并行处理视觉令牌,且能灵活调整令牌数量,适应不同的处理需求。
- 并行处理:与原始视觉令牌并行处理,增强模型在处理大量视觉数据时的效率和效果。
- 模型对齐:Valley 与 Siglip 和 Qwen2.5 等其他模型对齐,在设计上参考这些模型的成功元素,确保性能和兼容性。
如何运行 Valley
环境配置
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
单张图片推理示例
from valley_eagle_chat import ValleyEagleChat
model = ValleyEagleChat(
model_path='bytedance-research/Valley-Eagle-7B',
padding_side = 'left',
)
url = 'http://p16-goveng-va.ibyteimg.com/tos-maliva-i-wtmo38ne4c-us/4870400481414052507~tplv-wtmo38ne4c-jpeg.jpeg'
img = urllib.request.urlopen(url=url, timeout=5).read()
request = {
"chat_history": [
{'role': 'system', 'content': 'You are Valley, developed by ByteDance. Your are a helpfull Assistant.'},
{'role': 'user', 'content': 'Describe the given image.'},
],
"images": [img],
}
result = model(request)
print(f"\n>>> Assistant:\n")
print(result)
视频推理示例
from valley_eagle_chat import ValleyEagleChat
import decord
import requests
import numpy as np
from torchvision import transforms
model = ValleyEagleChat(
model_path='bytedance-research/Valley-Eagle-7B',
padding_side = 'left',
)
url = 'https://videos.pexels.com/video-files/29641276/12753127_1920_1080_25fps.mp4'
video_file = './video.mp4'
response = requests.get(url)
if response.status_code == 200:
with open("video.mp4", "wb") as f:
f.write(response.content)
else:
print("download error!")
exit(1)
video_reader = decord.VideoReader(video_file)
decord.bridge.set_bridge("torch")
video = video_reader.get_batch(
np.linspace(0, len(video_reader) - 1, 8).astype(np.int_)
).byte()
print([transforms.ToPILImage()(image.permute(2, 0, 1)).convert("RGB") for image in video])
request = {
"chat_history": [
{'role': 'system', 'content': 'You are Valley, developed by ByteDance. Your are a helpfull Assistant.'},
{'role': 'user', 'content': 'Describe the given video.'},
],
"images": [transforms.ToPILImage()(image.permute(2, 0, 1)).convert("RGB") for image in video],
}
result = model(request)
print(f"\n>>> Assistant:\n")
print(result)
资源
- GitHub 仓库:https://github.com/bytedance/Valley
- HuggingFace 模型库:https://huggingface.co/bytedance-research/Valley
- 项目主页:https://hyggge.github.io/projects/valley/index.html
- ModelScope 模型库:https://www.modelscope.cn/models/Hyggge/Valley-Eagle-7B
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日跟你分享最新的 AI 资讯和开源应用,也会不定期分享自己的想法和开源实例,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 27
27 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)