
2024年6月27日Arxiv人工智能相关论文
原标题作者机构: 北京邮电大学摘要: 二进制恶意软件摘要旨在从可执行文件中自动生成人类可读的恶意软件行为描述,以便于进行恶意软件破解和检测等任务。基于大型语言模型(LLMs)的先前方法显示出了巨大的潜力。然而,它们仍然面临重大问题,包括用户体验差、解释不准确和摘要不完整,主要是由于模糊的伪代码结构和缺乏恶意软件训练摘要。此外,涉及二进制恶意软件内部丰富交互的函数调用关系仍然大部分未被探索。
cs.AI: 通过强化学习从人类反馈中实现AI对齐?矛盾和限制
原标题: AI Alignment through Reinforcement Learning from Human Feedback? Contradictions and Limitations
作者: Adam Dahlgren Lindström, Leila Methnani, Lea Krause, Petter Ericson, Íñigo Martínez de Rituerto de Troya, Dimitri Coelho Mollo, Roel Dobbe
机构: 乌默奥大学 荷兰自由大学 鹿特丹理工大学
摘要: 这篇论文批判性地评估了通过反馈强化学习(RLxF)方法,尤其是大型语言模型(LLMs)与人类价值观和意图对齐的尝试,涉及人类反馈(RLHF)或AI反馈(RLAIF)。具体来说,我们展示了广泛追求的诚实、无害和有益等对齐目标的局限性。通过多学科的社会技术批判,我们不仅考察了RLxF技术的理论基础,还考察了其实现的实践,揭示了它们在捕捉人类伦理复杂性和促进AI安全方面的显著局限性。我们强调了RLxF目标内在的紧张和矛盾。此外,我们讨论了在关于对齐和RLxF的讨论中往往被忽视的伦理相关问题,其中包括友好性与欺骗、灵活性与可解释性以及系统安全之间的权衡。我们总结时呼吁研究人员和实践者共同批判性地评估RLxF的社会技术影响,倡导在AI开发中应用RLxF时采取更细致和反思性的方法。
论文链接: https://arxiv.org/pdf/2406.18346
cs.AI: 富有多维物理环境的规划与移动
原标题: PlaMo: Plan and Move in Rich 3D Physical Environments
作者: Assaf Hallak, Gal Dalal, Chen Tessler, Kelly Guo, Shie Mannor, Gal Chechik
机构: 以色列特拉维夫大学 美国NVIDIA 公司
摘要: 在复杂的物理模拟世界中控制人形机器人是一个长期存在的挑战,具有在游戏、模拟和视觉内容创作中的众多应用。在我们的设置中,用户提供了一个丰富而复杂的3D场景,并提供了由目标位置和运动类型组成的指令列表。为了解决这个任务,我们提出了PlaMo,一个场景感知路径规划器和一个稳健的基于物理的控制器。路径规划器产生一系列运动路径,考虑了场景对运动的各种限制,比如位置、高度和速度。作为规划器的补充,我们的控制策略生成了丰富和逼真的物理运动,符合计划。我们演示了这两个模块的结合如何使得在各种形式的复杂地形中穿行,并对环境中的实时变化做出响应。视频:this https URL 。
论文链接: https://arxiv.org/pdf/2406.18237
其他链接: https://youtu.be/wWlqSQlRZ9M
cs.AI: 骑士不确定性游戏
原标题: Games of Knightian Uncertainty
作者: Spyridon Samothrakis, Dennis J.N.J. Soemers, Damian Machlanski
机构: 埃塞克斯大学 马斯特里赫特大学
摘要: 毫无疑问,对于20世纪后期和21世纪初期的后半段,游戏被视为人工智能的果蝇。游戏是一系列令人兴奋的测试平台,其解决方案(在识别最优玩家方面)将导致拥有某种形式的通用智能的机器,或者至少帮助我们获得构建智能机器的见解。在传统棋盘游戏如围棋、国际象棋和扑克,以及视频游戏如2600系列 Atari 的成功应用之后,这一点是显而易见的。游戏已被成功攻克,但我们离通用人工智能(AGI)的发展(或者,更苛刻的批评者可能会说,有用的AI发展)还远得很。在这篇简短的愿景论文中,我们主张,为了使游戏研究再次对AGI路径产生相关性,我们需要能够在游戏的背景下解决Knightian不确定性,即代理需要能够适应在没有任何警告、没有先前数据和没有模型访问的情况下游戏规则的快速变化。
论文链接: https://arxiv.org/pdf/2406.18178
cs.AI: 从零开始:自动知识图谱补全的三元组预测
原标题: Start from Zero: Triple Set Prediction for Automatic Knowledge Graph Completion
作者: Wen Zhang, Yajing Xu, Peng Ye, Zhiwei Huang, Zezhong Xu, Jiaoyan Chen, Jeff Z. Pan, Huajun Chen
机构: 清华大学 南京大学 东南大学 暨南大学
摘要: 知识图谱(KG)完成旨在找出知识图谱中的缺失三元组。一些任务,如链接预测和实例完成,已被提出用于知识图谱完成。它们是三元组级任务,其中给定了缺失三元组中的一些元素以预测三元组的缺失元素。然而,提前知道缺失三元组中的一些元素并不总是一个现实的设置。在本文中,我们提出了一种新的图级自动知识图谱完成任务,称为三元组集预测(TSP),它假设缺失三元组中的元素都没有给定。TSP是为了预测一组缺失的三元组,给定一组已知的三元组。为了正确和准确地评估这一新任务,我们提出了4个评估指标,包括3个分类指标和1个排名指标,考虑了部分开放世界和封闭世界的假设。此外,为了应对预测的大量候选三元组,我们提出了一种新颖而高效的基于子图的方法 GPHT,可以快速预测三元组集。为了公平比较TSP的结果,我们还提出了两种类型的方法 RuleTensor-TSP 和 KGE-TSP,将现有的基于规则和嵌入的方法应用于TSP作为基准线。在实验过程中,我们根据我们提出的关系相似性部分开放世界假设,对从维基数据中提取的两个数据集上的提出的方法进行评估,并创建了一个完整的家庭数据集,以评估TSP结果,遵循封闭世界的假设。结果表明,这些方法可以成功生成一组缺失的三元组,并在新任务上取得了合理的分数,而 GPHT 的预测时间明显比基线更短。实验的数据集和代码可在以下网址获得:https://…(链接地址)。
论文链接: https://arxiv.org/pdf/2406.18166
Github: https://github.com/zjukg/GPHT-for-TSP
cs.AI: 不使用光谱的星系光谱学:利用有条件扩散模型从光度图像中获取星系特性
原标题: Galaxy spectroscopy without spectra: Galaxy properties from photometric images with conditional diffusion models
作者: Lars Doorenbos, Eva Sextl, Kevin Heng, Stefano Cavuoti, Massimo Brescia, Olena Torbaniuk, Giuseppe Longo, Raphael Sznitman, Pablo Márquez-Neila
机构: 伯尔尼大学 纽伦堡大学 慕尼黑大学 那不勒斯大学 那不勒斯大学费德里科二世大学 博洛尼亚大学
摘要: 现代光谱调查只能针对广域调查中光度编目的一小部分进行观测。在这里,我们报告了一种生成式人工智能方法的开发,能够仅通过光度宽波段图像预测光学星系光谱。这种方法借鉴了扩散模型和对比网络的最新进展。我们将多波段星系图像输入到架构中,以获得光学光谱。通过这些光谱,可以利用光谱工具箱中的任何方法推导出星系属性的稳健值,例如标准的群体合成技术和Lick指数。在斯隆数字化天空调查的64x64像素图像上进行训练和测试时,光度空间中星形和静止星系的全局双峰性得以恢复,以及星形星系的质量-金属丰度关系。观测和人工创建的光谱之间的比较显示出在整体金属丰度、年龄、Dn4000、恒星速度色散和E(B-V)值方面的良好一致性。我们的生成算法的光度红移估计可以与其他当前的专门深度学习技术竞争。此外,这项工作是文献中首次尝试从光度图像中推断速度色散。此外,我们可以预测活跃星系核的存在,准确率高达82%。通过我们的方法,通常需要光谱输入的科学上有趣的星系属性可以仅通过大规模光度调查的未来数据集获得。通过人工智能进行光谱预测还可以帮助创建逼真的模拟编目。
论文链接: https://arxiv.org/pdf/2406.18175
cs.AI: 多模态基础世界模型用于通用体验智能体
原标题: Multimodal foundation world models for generalist embodied agents
作者: Pietro Mazzaglia, Tim Verbelen, Bart Dhoedt, Aaron Courville, Sai Rajeswar
机构: IDLab, 根特大学 VERSES AI 研究实验室 Mila, 蒙特利尔大学 ServiceNow 研究
摘要: 学习通用的具身智能体,能够解决不同领域的多种任务是一个长期存在的问题。强化学习(RL)很难扩展,因为它需要为每个任务设计复杂的奖励机制。相比之下,语言可以以更自然的方式指定任务。当前的基础视觉语言模型(VLMs)通常需要微调或其他适应性才能发挥作用,因为存在显著的领域差距。然而,在这些领域缺乏多模态数据是发展具身应用基础模型的障碍。在这项工作中,我们通过提出多模态基础世界模型来克服这些问题,能够将基础VLMs的表示与RL的生成世界模型的潜在空间连接和对齐,而无需任何语言注释。由此产生的智能体学习框架GenRL允许通过视觉和/或语言提示指定任务,在具身领域的动态中加以确认,并在想象中学习相应的行为。通过大规模多任务基准测试,GenRL在几个运动和操作领域展现出强大的多任务泛化性能。此外,通过引入无数据的RL策略,它为基于基础模型的RL为通用具身智能体奠定了基础。
论文链接: https://arxiv.org/pdf/2406.18043
cs.AI: 创新为了未来:SE与绿色AI的融合
原标题: Innovating for Tomorrow: The Convergence of SE and Green AI
作者: Luís Cruz, Xavier Franch Gutierrez, Silverio Martínez-Fernández
机构: 代尔夫特理工大学 西班牙加泰罗尼亚理工大学
摘要: 机器学习的最新进展,特别是在基础模型方面的进展,正在彻底改变现有软件工程(SE)流程的边界。这是一个双向现象,一方面,软件系统现在需要为用户提供AI增强的功能;另一方面,AI被用于软件开发生命周期中的自动化任务。在可持续性成为紧迫社会问题的时代,我们的社区需要制定一个长期计划,以实现与环境可持续性价值观相一致的有意识转变。在这篇论文中,我们反思了采用环保实践以创建AI增强的软件系统的影响,并考虑了使用基础模型进行软件开发的环境影响。
论文链接: https://arxiv.org/pdf/2406.18142
cs.AI: “跨域小说类别发现的专有风格去除”
原标题: Exclusive Style Removal for Cross Domain Novel Class Discovery
作者: Yicheng Wang, Feng Liu, Junmin Liu, Zhen Fang, Kai Sun
摘要: 作为开放世界学习中的一个有前途的领域,“新类别发现”(NCD)通常是一个任务,根据同一领域内有标签数据的先验知识,在未标记的集合中对未见过的新类别进行聚类。然而,当新类别从与有标签类别不同的分布中抽样时,现有的NCD方法的性能可能会严重受损。在本文中,我们探讨并建立了NCD在跨领域设置中的可解性,必要条件是必须去除风格信息。基于理论分析,我们引入了一个专门的风格去除模块,用于提取与基线特征有所不同的风格信息,从而促进推理。此外,这个模块很容易与其他NCD方法集成,作为一个插件,以改善在具有不同分布的新类别上的性能,与已见的有标签集合相比。此外,我们认识到不同的骨干网络和预训练策略对NCD方法的性能有着不可忽视的影响,我们为未来的NCD研究建立了一个公平的基准。对三个常见数据集的大量实验表明了我们提出的模块的有效性。
论文链接: https://arxiv.org/pdf/2406.18140
cs.AI: BiTrack:使用相机-LiDAR数据进行双向离线3D多目标跟踪
原标题: BiTrack: Bidirectional Offline 3D Multi-Object Tracking Using Camera-LiDAR Data
作者: Kemiao Huang, Meiying Zhang, Qi Hao
机构: 清华大学 中国 科学技术大学
摘要: 与实时多目标跟踪(MOT)相比,离线多目标跟踪(OMOT)具有执行2D-3D检测融合、错误链接校正和完整轨迹优化的优势,但必须应对边界框错位和轨迹评估、编辑和细化等挑战。本文提出了一种名为“BiTrack”的3D OMOT框架,其中包括2D-3D检测融合模块、初始轨迹生成模块和双向轨迹重新优化模块,以实现从摄像机-LiDAR数据中获得最佳跟踪结果。本文的创新之处包括三个方面:(1)开发了一种基于点级对象注册技术,利用基于密度的相似度度量实现了2D-3D检测结果的准确融合;(2)开发了一组数据关联和轨迹管理技能,利用基于顶点的相似度度量以及误报拒绝和轨迹恢复机制生成可靠的双向对象轨迹;(3)开发了一种轨迹重新优化方案,以贪婪的方式重新组织不同忠实度的轨迹片段,并利用完成和平滑技术对每条轨迹进行细化。在KITTI数据集上的实验结果表明,BiTrack在3D OMOT任务的准确性和效率方面实现了最先进的性能。
论文链接: https://arxiv.org/pdf/2406.18414
cs.AI: 在未知动态环境中的开放词汇移动操作与3D语义地图
原标题: Open-vocabulary Mobile Manipulation in Unseen Dynamic Environments with 3D Semantic Maps
作者: Dicong Qiu, Wenzong Ma, Zhenfu Pan, Hui Xiong, Junwei Liang
机构: 香港科技大学(广州) 爱可欧智能
摘要: 开放词汇移动操作(OVMM)是自主机器人的关键能力,特别是面对未知和动态环境带来的挑战。这项任务要求机器人探索并建立对周围环境的语义理解,生成可行的计划以实现操作目标,适应环境变化,并理解来自人类的自然语言指令。为了解决这些挑战,我们提出了一个新颖的框架,利用预训练视觉-语言模型(VLMs)的零样本检测和基于实体的识别能力,结合密集的3D实体重建来构建3D语义地图。此外,我们利用大型语言模型(LLMs)进行空间区域抽象和在线规划,结合人类指令和空间语义上下文。我们已经建立了一个包含10个自由度的移动操作机器人平台JSR-1,并在真实世界的机器人实验中证明,我们提出的框架可以有效捕捉空间语义,并处理动态环境设置下零样本OVMM任务的自然语言用户指令,其整体导航和任务成功率为105个周期内的80.95%和73.33%,相比基线,SFT和SPL分别提高了157.18%和19.53%。此外,当初始计划失败时,该框架能够根据从3D语义地图中得出的空间语义上下文重新规划到下一个最有可能的候选位置,保持平均成功率为76.67%。
论文链接: https://arxiv.org/pdf/2406.18115
cs.AI: 少样本医学图像分割与高保真原型
原标题: Few-Shot Medical Image Segmentation with High-Fidelity Prototypes
作者: Song Tang, Shaxu Yan, Xiaozhi Qi, Jianxin Gao, Mao Ye, Jianwei Zhang, Xiatian Zhu
机构: University of Shanghai for Science and Technology, Universit¨ at Hamburg, University of Electronic Science and Technology of China, University of Surrey, Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences
摘要: 少样本语义分割(FSS)旨在通过每个类别仅使用一个标记的训练样本来适应预训练模型的新类别。尽管基于原型的方法已经取得了显著的成功,但现有的模型仅限于具有明显不同对象和不太复杂背景的成像场景,例如自然图像。这使得这些模型在两个条件都无效时对医学成像来说是次优的。为了解决这个问题,我们提出了一种名为详细自我精炼原型网络(DSPNet)的新型方法,用于构建能够更全面地表示对象前景和背景的高保真原型。具体来说,为了在保持捕获的细节语义的同时构建全局语义,我们通过聚类模型多模态结构来学习前景原型,然后在通道级上进行融合。考虑到背景在空间维度上通常没有明显的语义关系,我们在稀疏通道感知调节下整合了特定通道的结构信息。在三个具有挑战性的医学图像基准上进行的广泛实验表明,DSPNet在以前最先进的方法中具有优势。
论文链接: https://arxiv.org/pdf/2406.18074
cs.AI: AlphaForge 是一个框架,用于挖掘和动态组合公式化阿尔法因子。
原标题: AlphaForge: A Framework to Mine and Dynamically Combine Formulaic Alpha Factors
作者: Hao Shi, Cuicui Luo, Weili Song, Xinting Zhang, Xiang Ao
机构: University of Chinese Academy of Sciences
Renaissance Era Investment Management Co., Ltd
University of Nottingham
Institute of Computing Technology, Chinese Academy of Sciences
摘要: 金融数据的变异性和低信噪比,再加上对可解释性的必要性,使得Alpha因子挖掘工作流成为量化投资的关键组成部分。从早期的手动提取过渡到遗传编程,目前在这一领域中最先进的方法是利用强化学习来挖掘一组具有固定权重的组合因子。然而,由此产生的Alpha因子的表现存在不一致性,而固定因子权重的不灵活性在适应金融市场的动态性方面表现不足。为解决这一问题,本文提出了一个两阶段的公式化Alpha生成框架AlphaForge,用于Alpha因子挖掘和因子组合。该框架利用生成-预测神经网络来生成因子,利用深度学习固有的强大空间探索能力,同时保持多样性。框架内的组合模型结合了因子的时间性能进行选择,并动态调整分配给每个组件Alpha因子的权重。在真实数据集上进行的实验表明,我们提出的模型在公式化Alpha因子挖掘方面优于当代基准。此外,我们的模型在量化投资领域的投资组合回报方面表现出显著的提升。
论文链接: https://arxiv.org/pdf/2406.18394
cs.AI: SAM: 半主动机制用于可扩展连续操纵器以及实时滞后补偿控制算法
原标题: SAM: Semi-Active Mechanism for Extensible Continuum Manipulator and Real-time Hysteresis Compensation Control Algorithm
作者: Junhyun Park, Seonghyeok Jang, Myeongbo Park, Hyojae Park, Jeonghyeon Yoon, Minho Hwang
摘要: 电缆驱动连续操作器(CDCM)通过自然孔道实现无瘢痕手术,并通过曲线路径改善目标病变的可及性。然而,由于非线性电缆效应引起滞后,CDCM在工作空间和控制精度方面存在局限性。本文介绍了一种具有半主动机制(SAM)的可扩展CDCM,通过平移运动扩展工作空间,而无需额外的机械元件或驱动。我们使用8个基准标记和RGBD感知收集了一个滞后数据集。基于这个数据集,我们使用经过训练的时间卷积网络(TCN)开发了一个实时滞后补偿控制算法,具有1毫秒的时间延迟,有效估计操作器的滞后行为。通过随机轨迹跟踪测试和指向方框任务的性能验证表明,所提出的控制器在关节空间中将滞后显著减少了高达69.5%,在指向方框任务中减少了约26%。
论文链接: https://arxiv.org/pdf/2406.18388
cs.AI: MALSIGHT:探索恶意源代码和良性伪代码,用于迭代式二进制恶意软件摘要。
原标题: MALSIGHT: Exploring Malicious Source Code and Benign Pseudocode for Iterative Binary Malware Summarization
作者: Haolang Lu, Hongrui Peng, Guoshun Nan, Jiaoyang Cui, Cheng Wang, Weifei Jin
机构: 北京邮电大学
摘要: 二进制恶意软件摘要旨在从可执行文件中自动生成人类可读的恶意软件行为描述,以便于进行恶意软件破解和检测等任务。基于大型语言模型(LLMs)的先前方法显示出了巨大的潜力。然而,它们仍然面临重大问题,包括用户体验差、解释不准确和摘要不完整,主要是由于模糊的伪代码结构和缺乏恶意软件训练摘要。此外,涉及二进制恶意软件内部丰富交互的函数调用关系仍然大部分未被探索。为此,我们提出了MALSIGHT,这是一个新颖的代码摘要框架,可以通过探索恶意源代码和良性伪代码来迭代生成二进制恶意软件的描述。具体来说,我们使用LLM构建了第一个恶意软件摘要MalS和MalP,并通过人工努力手动完善了这一数据集。在训练阶段,我们在MalS数据集和良性伪代码数据集上调整了我们提出的MalT5,这是一个新颖的基于LLM的代码模型。然后,在测试阶段,我们迭代地将伪代码函数输入MalT5以获得摘要。这样的过程有助于理解伪代码结构,并捕捉函数之间复杂的交互,从而有利于摘要的可用性、准确性和完整性。此外,我们提出了一个新颖的评估基准BLEURT-sum,用于衡量摘要的质量。对三个数据集的实验显示了提出的MALSIGHT的有效性。值得注意的是,我们提出的MalT5,仅具有0.77B参数,提供了与更大的ChatGPT3.5相当的性能。
论文链接: https://arxiv.org/pdf/2406.18379
cs.AI: 学习纯量子态(几乎)无悔
原标题: Learning pure quantum states (almost) without regret
作者: Josep Lumbreras, Mikhail Terekhov, Marco Tomamichel
机构: 新加坡国立大学 瑞士洛桑联邦理工学院
摘要: 我们开始研究具有最小后悔的量子态测量。学习者对未知的纯量子态具有顺序 Oracle 访问,并在每一轮中选择一个纯净的探测态。如果未知态被测量与此探测态正交,就会产生后悔,学习者的目标是在 T T T 轮中最小化预期累积后悔。挑战在于在最具信息量的测量和产生最小后悔的测量之间找到平衡。我们展示了使用基于中位数的均值最小二乘估计的新测量算法,累积后悔的规模为 Θ ( polylog T ) \Theta(\operatorname{polylog} T) Θ(polylogT)。该算法采用偏向于未知态的测量,并产生在线估计,其在观察样本数量上是最优的(至多对数项)。
论文链接: https://arxiv.org/pdf/2406.18370
cs.AI: 稳定扩散分割用于具有单步反向过程的生物医学图像
原标题: Stable Diffusion Segmentation for Biomedical Images with Single-step Reverse Process
作者: Tianyu Lin, Zhiguang Chen, Zhonghao Yan, Fudan Zheng, Weijiang Yu
机构: 中山大学生物医学工程学院 中国 北京邮电大学国际学院
摘要: 扩散模型已经在各种生成任务中展示了它们的有效性。然而,当应用于医学图像分割时,这些模型面临着一些挑战,包括显著的资源和时间需求。它们还需要一个多步骤的反向过程和多个样本来产生可靠的预测。为了解决这些挑战,我们引入了第一个潜在扩散分割模型,名为SDSeg,建立在稳定扩散(SD)之上。SDSeg结合了一种简单的潜在估计策略,以促进单步反向过程,并利用潜在融合串联来消除多个样本的必要性。大量实验证明,SDSeg在五个具有不同成像模态的基准数据集上超越了现有的最先进方法。值得注意的是,SDSeg能够通过单一的反向步骤和样本生成稳定的预测,体现了模型的稳定性,正如其名称所暗示的那样。代码可在此网址获取。
论文链接: https://arxiv.org/pdf/2406.18361
Github: https://github.com/lin-tianyu/Stable-Diffusion-Seg
cs.AI: 使用内部-外部手语关注的连续手语识别
原标题: Continuous Sign Language Recognition Using Intra-inter Gloss Attention
作者: Hossein Ranjbar, Alireza Taheri
机构: 沙力夫科技大学 伊朗
摘要: 许多连续手语识别(CSLR)研究采用基于转换器的架构进行序列建模,因为它们具有捕捉全局上下文的强大能力。然而,作为转换器核心模块的原始自我注意力计算所有时间步骤的加权平均值,因此可能无法充分利用手语视频中的局部时间语义。在本研究中,我们引入了一种新的模块,称为词组内-词组间手势注意力模块,在手语识别研究中,旨在利用词组内帧的关系以及视频中词组之间的语义和语法依赖性。在词组内注意力模块中,视频被分为等大小的块,并在每个块内应用自我注意力机制。这种局部自我注意力显著减少了复杂性,并消除了考虑非相关帧引入的噪声。在词组间注意力模块中,我们首先通过沿时间维度的平均池化对每个词组块内的块级特征进行聚合。随后,对所有块级特征应用多头自我注意力。鉴于签名者-环境交互的无关紧要性,我们使用分割来移除视频的背景。这使提出的模型能够将注意力集中在签名者上。在PHOENIX-2014基准数据集上的实验结果表明,我们的方法能够以端到端的方式有效地提取手语特征,无需任何先验知识,提高了CSLR的准确性,并在测试集上以20.4的词错误率(WER)达到与使用额外监督的最先进的方法相竞争的结果。
论文链接: https://arxiv.org/pdf/2406.18333
cs.AI: 在多对象场景中的视不变像素级异常检测与自适应视合成
原标题: View-Invariant Pixelwise Anomaly Detection in Multi-object Scenes with Adaptive View Synthesis
作者: Subin Varghese, Vedhus Hoskere
机构: 空字符串 Subin Varghese Vedhus Hoskere
摘要: 对基础设施资产的检查和监测通常需要定期识别随时间周期性拍摄的场景中的视觉异常。手动收集的图像或者通过无人机等机器人从不同时间点拍摄的同一场景的图像通常不是完全对齐的。监督分割方法可用于识别已知问题,但当出现未知异常时,需要采用无监督异常检测方法。当前的无监督像素级异常检测方法主要针对相机位置已知且恒定的工业环境进行开发。然而,我们发现这些方法在图像不完全对齐的情况下无法推广。我们将在两组不完全对齐的图像之间进行无监督异常检测的问题称为场景异常检测(Scene AD)。我们提出了一种名为OmniAD的新型网络来解决提出的场景异常检测问题。具体来说,我们改进了异常检测方法逆向蒸馏,使像素级异常检测性能提高了40%。我们进一步证明,该网络的性能通过提出的两种新数据增强策略得到改善,这些策略利用了新颖的视图合成和相机定位来提高泛化能力。我们通过定性和定量结果在新数据集ToyCity上验证了我们的方法,这是第一个具有多个对象的场景异常检测数据集,以及在已建立的以单个对象为中心的数据集MAD上验证了我们的方法。链接
论文链接: https://arxiv.org/pdf/2406.18012
Github: https://drags99.github.io/OmniAD/
cs.AI: 通过1对K对比学习提高跨语言跨模态检索的一致性
原标题: Improving the Consistency in Cross-Lingual Cross-Modal Retrieval with 1-to-K Contrastive Learning
作者: Zhijie Nie, Richong Zhang, Zhangchi Feng, Hailang Huang, Xudong Liu
机构: 北航大学
摘要: 跨语言跨模态检索(CCR)是网络搜索中的一个重要任务,旨在同时打破模态和语言之间的障碍,并通过单一模型在多语境情况下实现图像-文本检索。近年来,基于跨语言跨模态预训练取得了显著进展;特别是基于大规模数据的对比学习方法显著改进了检索任务。然而,这些方法直接遵循了现有的跨语言或跨模态领域的预训练方法,导致了CCR中的两个不一致问题:采用跨语言风格的方法遭受模态内误差传播,导致整个数据集中不同语言的召回性能不一致。采用跨模态风格的方法遭受模态间优化方向偏差,导致每个实例在不同语言中的排名不一致,这不能通过Recall@K来反映。为了解决这些问题,我们提出了一种简单但有效的1对K对比学习方法,平等对待每种语言,消除了误差传播和优化偏差。此外,我们提出了一个新的评估指标,平均排名方差(MRV),以反映每个实例在不同语言中的排名不一致性。对四个CCR数据集的大量实验表明,我们的方法在较小规模的预训练数据上提高了召回率和MRV,实现了新的最先进水平。
论文链接: https://arxiv.org/pdf/2406.18254
cs.AI: 利用显式程序知识指导视频预测
原标题: Guiding Video Prediction with Explicit Procedural Knowledge
作者: Patrick Takenaka, Johannes Maucher, Marco F. Huber
机构: 应用人工智能研究所,斯图加特传媒大学,德国
斯图加特大学工业制造和管理研究所,德国
弗劳恩霍夫制造工程与自动化研究所,斯图加特,德国
摘要: 我们提出了一种将领域的程序化知识整合到深度学习模型中的通用方法。我们将其应用于视频预测案例,基于以物体为中心的深度模型,并展示这比仅使用数据驱动模型能够取得更好的性能。我们开发了一种架构,促进潜在空间的解耦,以利用整合的程序化知识,并建立了一个允许模型在潜在空间中学习程序接口的设置,使用视频预测的下游任务。我们将性能与最先进的数据驱动方法进行对比,并展示纯粹数据驱动方法难以处理的问题可以通过使用领域知识来解决,这为简单收集更多数据提供了替代方案。
论文链接: https://arxiv.org/pdf/2406.18220
cs.AI: AI 卡:基于欧盟AI法案灵感的可应用框架,用于机器可读的AI和风险文档
原标题: AI Cards: Towards an Applied Framework for Machine-Readable AI and Risk Documentation Inspired by the EU AI Act
作者: Delaram Golpayegani, Isabelle Hupont, Cecilia Panigutti, Harshvardhan J. Pandit, Sven Schade, Declan O’Sullivan, Dave Lewis
机构: 三一大学都柏林三一学院 意大利伊斯普拉欧洲委员会 能源与环境可持续性研究中心 都柏林城市大学
摘要: 随着欧盟AI法案的即将实施,高风险AI系统的文档和风险管理信息将成为法定要求,对于证明合规性将发挥关键作用。尽管其重要性,目前缺乏标准和指南来协助制定与AI法案一致的AI和风险文档。本文旨在通过深入分析AI法案关于技术文档的规定,特别关注AI风险管理,以填补这一空白。基于这一分析,我们提出AI卡片作为一个新颖的全面框架,用于代表AI系统的特定预期用途,包括技术规格、使用背景和风险管理的信息,既以人类可读格式,也以机器可读格式。AI卡片的人类可读表示为AI利益相关者提供了关于AI用例的透明和可理解的概述,其机器可读规范利用最先进的语义网络技术,体现了AI价值链内部交换文档所需的互操作性。这带来了反映应用于AI系统及其背景的变化所需的灵活性,提供了适应潜在法律要求修订的可扩展性,并实现了开发自动化工具以协助法律合规和一致性评估任务的可能性。为了巩固这些好处,我们提供了一个基于AI的学生监考系统的示例AI卡片,并进一步讨论了其在AI法案的背景内外的潜在应用。
论文链接: https://arxiv.org/pdf/2406.18211
cs.AI: MammothModa:多模态大语言模型
原标题: MammothModa: Multi-Modal Large Language Model
作者: Qi She, Junwen Pan, Xin Wan, Rui Zhang, Dawei Lu, Kai Huang
机构: ByteDance, Beijing, China
摘要: 在这份报告中,我们介绍了MammothModa,又一个多模态大语言模型(MLLM),旨在从基本基准开始实现最先进的性能。我们专注于三个关键设计见解:(i)在保持复杂语言理解的同时整合视觉能力:除了视觉编码器,我们还将视觉注意力专家整合到LLM中,以增强其视觉能力。(ii)扩展上下文窗口以获得高分辨率和长时间视觉特征:我们探索了视觉合并模块,有效减少了高分辨率图像的标记数量,并整合了帧位置ID以避免位置插值。(iii)高质量的双语数据集:我们精心策划和过滤了一个高质量的双语多模态数据集,以减少视觉幻觉。通过以上方法,我们构建了MammothModa,始终优于最先进的模型,例如LLaVA系列,在主要的现实世界视觉语言基准测试中,没有花哨的效果。
论文链接: https://arxiv.org/pdf/2406.18193

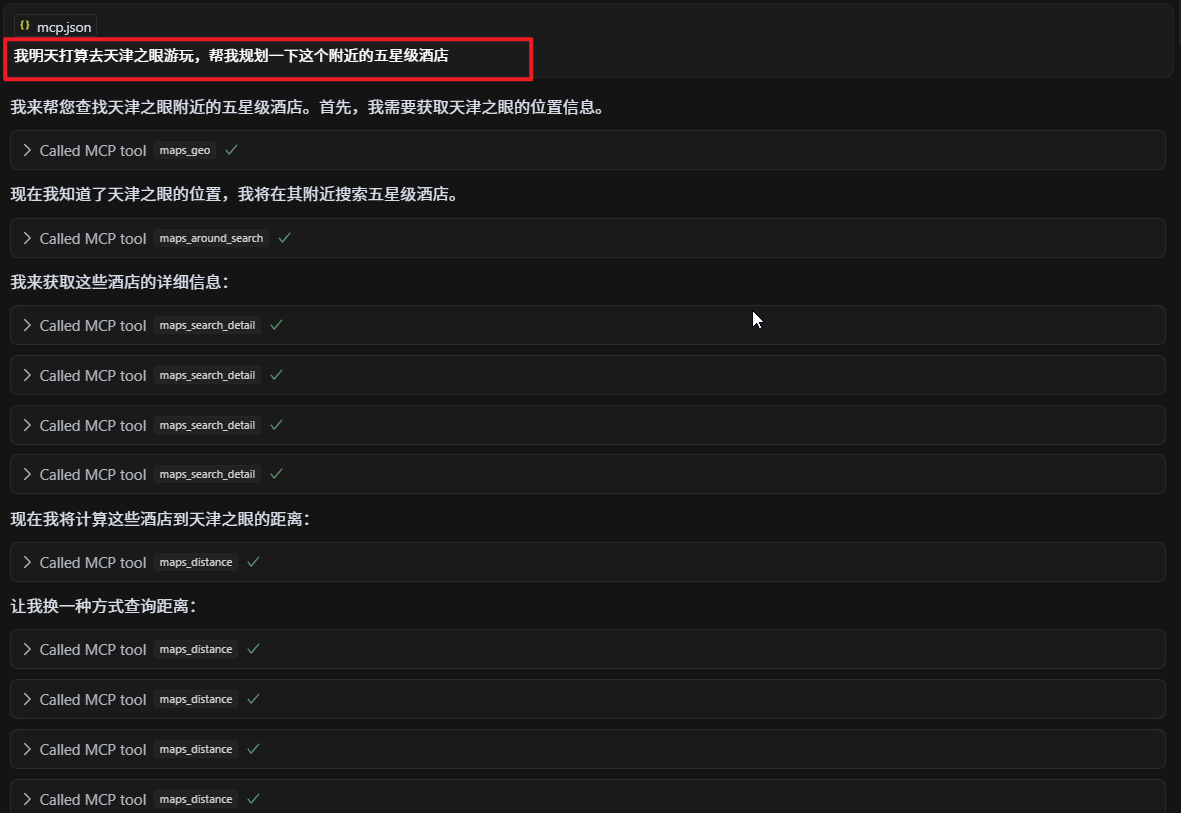
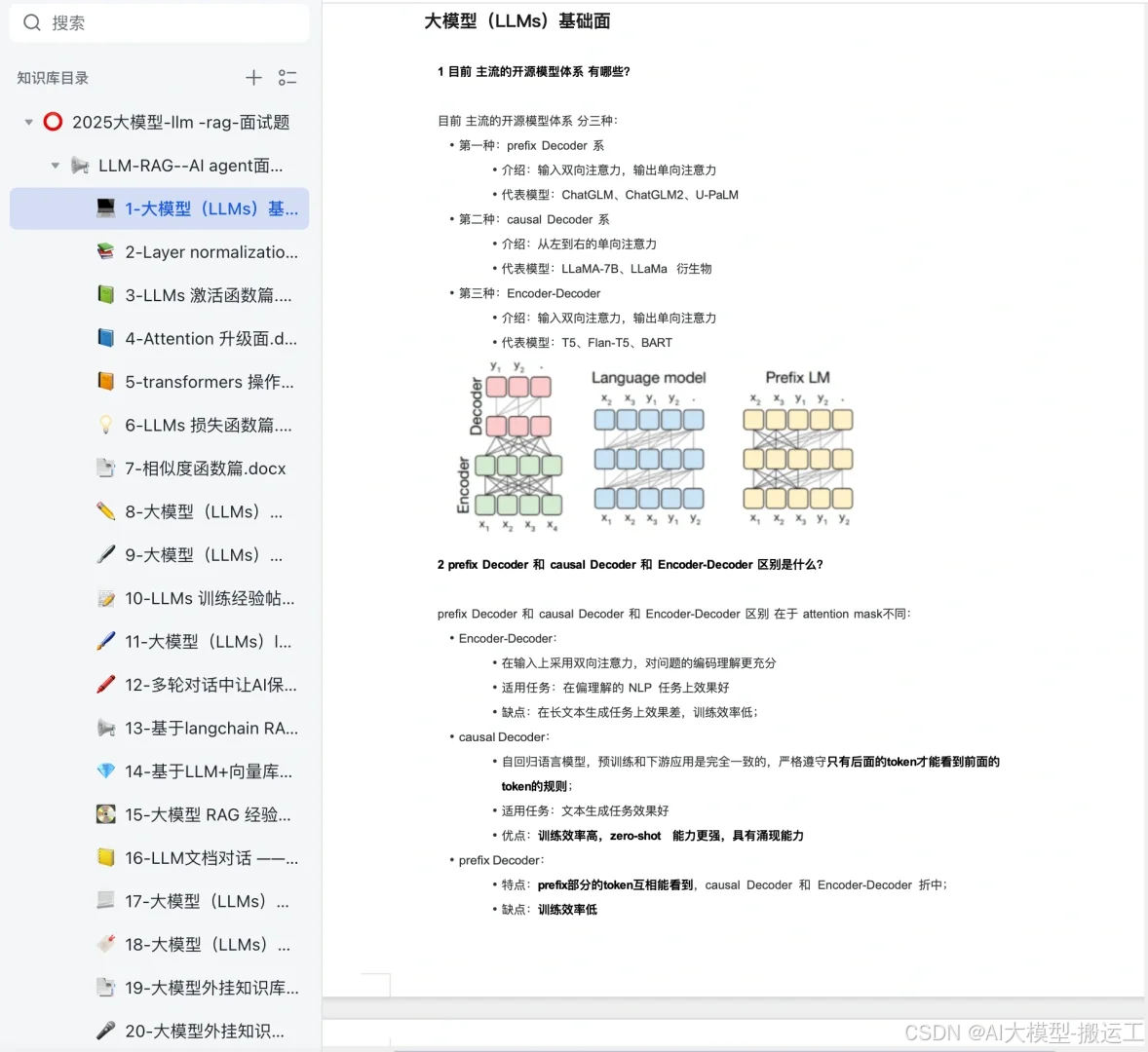
欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 19
19 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)