
InternVL1.5:How Far Are We to GPT-4V?Closing the Gap to Commercial Multimodal Models
1、持续学习策略:针对大规模基础视觉模型InternVit-6B提升能力的同时还能够被其他LLMs复用2、动态高分辨率:根据输入图像的宽高比和分辨率,将图像划分为1到40个448×448像素的patch,支持高达4K分辨率的输入3、高质量双语数据集:涵盖常见场景、图像,并用英语和中文问答标注InternVL1.5在18个多模态benchmark中达到sota(8项最佳)4、跟1.0比起来:去掉了Q
一、TL;DR
- 持续学习策略:针对大规模基础视觉模型InternVit-6B提升能力的同时还能够被其他LLMs复用
- 动态高分辨率:根据输入图像的宽高比和分辨率,将图像划分为1到40个448×448像素的patch,支持高达4K分辨率的输入
- 高质量双语数据集:涵盖常见场景、图像,并用英语和中文问答标注
- InternVL1.5在18个多模态benchmark中达到sota(8项最佳)
- 跟1.0比起来:去掉了QLLaMA,增加了上述三点,还有更换了LLM的组件进行组合
二、方法和贡献
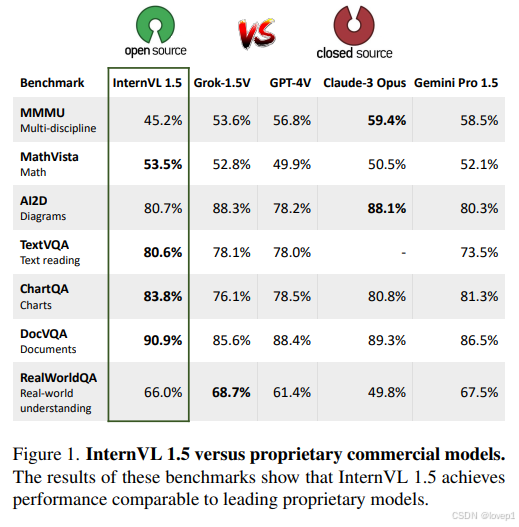
MLLMs近些时间取得了显著的成就,但是开源模型与专有商业模型(GPT-4v/Gemini系列和Qwen-VL-Max)等存在显著的能力差距,差距主要体现在3点:
- 参数规模:专有商业MLLMs≥1000亿参数,开源模型的视觉基础模型≥3亿参数,且LLMs只有70亿或者130亿参数
- 图像分辨率:专业模型采用动态分辨率方法,保留原始宽高比,开源模型是固定分辨率
- 多语言能力:商业模型多语言数据,开源模型fix英语数据
针对上述问题,InternVL1.5的3个贡献/带来的优势:
-
持续学习策略-强大的视觉表征能力:对InternViT-6B采用持续学习方法,使用高质量的图文数据进行优化。提升了模型对视觉内容的理解能力和增强了其在不同LLMs中的适应性。此外,还使用InternLM2-20B作为语言基础模型,为其提供了强大的初始语言处理能力。
-
动态高分辨率策略-灵活的分辨率(GPT-4V):采用动态高分辨率策略,将图像划分为448×448像素的patch,patch数量根据图像的宽高比和分辨率从1到40(即4K分辨率)不等。此外,还增加了缩略图视图以捕捉全局上下文。
-
多样化数据集-双语能力:收集了涵盖高质量自然场景、图表、文档以及英语和中文对话的公开数据集。此外,我们开发了一个使用开源LLMs的数据翻译pipeline,可以轻松扩展到更多语言。(没太看到消融实验,其实我感觉是不是这一点才是最重要的?)
三、详细模型结构和训练过程
3.1 总体架构
如图3所示,InternVL 1.5采用了具体是“ViT-MLP-LLM”配置,将预训练的InternViT-6B与预训练的InternLM2-20B通过一个随机初始化的MLP投影器集成在一起(注意:这里跟1.0比起来没有QLLaMA了哈,事实证明QLLaMA可能是个冗余操作)。
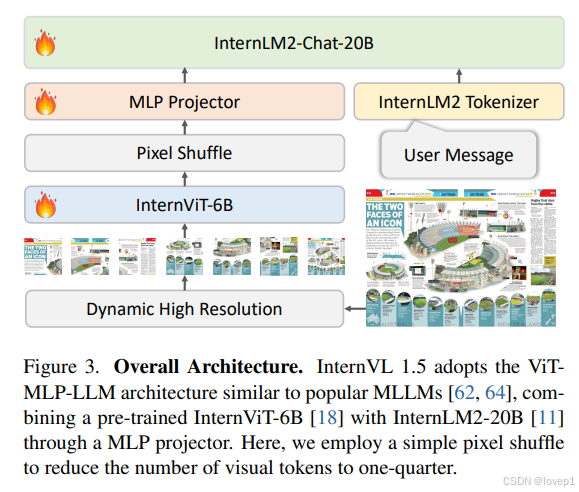
在训练过程中,我们实施了动态分辨率策略,根据输入图像的宽高比和分辨率,将图像划分为大小为448×448像素的patch,patch数量从1到12不等。在测试时,这一策略可以zero-shot的扩展到40个patch(即4K分辨率)。为了增强对高分辨率的支持,我们简单地使用pixel shuffle操作将视觉token的数量减少到原来的四分之一。因此,在我们的模型中,一个448×448的图像由256个视觉token表示。
3.2 强大的视觉编码器
常见的Vit是在224x224的数据集上做预训练,由于数据通常是从互联网上的图文对进行训练的,但是处理高分辨率或者非互联网来源的图像时,其性能会下降(什么叫持续预训练?就是不停的增加数据,修改网络结构,变更分辨率训练,把炼老汤变得高大上了。。。,具体如下V1.0 -> V1.2 -> V1.5):
InternViT-6B-448px-V1.2
为解决这一问题,InternVL 1.2版本对InternViT-6B模型进行了持续预训练。
- 首先,paper直接丢弃了最后三层的权重(发现倒数第四层的特征在多模态任务中表现最佳),将InternViT-6B从48层减少到45层。
- 然后,输入分辨率从224提升到448,并将其与Nous-Hermes-2-Yi-34B集成。
- 为了使模型具备高分辨率处理和OCR能力,视觉编码器和MLP都被激活用于训练
- 使用了图像caption和OCR特定数据集的混合数据。得到的新InternViT权重release为InternViT-6B-448px-V1.2。
InternViT-6B-448px-V1.5
InternViT-6B-448px-V1.2的强大基础预训练得到InternVL 1.5。
- 训练图像的分辨率从固定的448×448扩展到动态的448×448,其中基本patch大小为448×448,patch数量从1到12不等。
- 此外,我们增强了预训练数据集的规模、质量和多样性,从而赋予了1.5版本模型强大的鲁棒性、OCR能力和高分辨率处理能力。动态分辨率和训练数据集的详细信息在下图中给出
值得注意的是,尽管InternVL 1.5中的LLM从Nous-Hermes-2-Yi-34B 更改为 InternLM2-20B,但InternViT与新的LLM保持了出色的兼容性和可移植性。这表明InternViT-6B在MLLMs的预训练阶段学到的视觉特征具有广泛的适用性,并不严格依赖于特定的LLM。
3.3 动态高分辨率
受UReader的启发,paper采用了动态高分辨率训练方法,能够有效适应输入图像的不同分辨率和宽高比。这种方法利用将图像划分为patch的灵活性,增强了模型处理详细视觉信息的能力,同时适应多种图像分辨率。
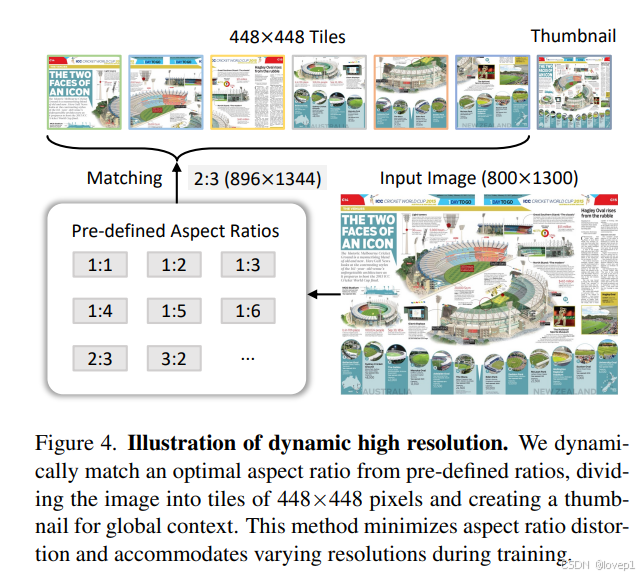
这里看paper有点绕,我用大白话讲一下:
- 首先input image是800*1300,此时448*2 = 896,448*3=1344,则输入的宽高比最佳是2:3,此时先将input image进行resize到896*1344
- 然后根据448x448的patch进行不做任何overlap的切割,比如第一个patch是(0, 0, 448, 448),第二个patch是(448, 0, 896, 0),第三个patch是(896,0,1344, 0),第四个patch是(0,448, 448, 896)依次类推,
- 最后一个Thumbnail是说直接将原图resize到448*448,这样不丢失全图信息
- 最后再接入pixel shuffle(这个操作有专门的paper讲),这样能够减少计算量,再接入MLP对齐,然后接入LLM
paper原文说的主要步骤是:
动态宽高比匹配
如上图所示,为了在处理过程中保持自然宽高比,我们从预定义的宽高比集合中动态匹配最优宽高比。由于计算资源有限,我们在训练中允许的最大patch数量为12个。因此,该集合包括由1到12个patch形成的35种可能的宽高比组合,例如{1:1, 1:2, 2:1, 3:1, ..., 2:6}。在匹配过程中,对于每张输入图像,我们计算其宽高比,并通过测量绝对差值将其与35种预定义宽高比进行比较。如果多个预定义宽高比匹配(例如1:1和2:2),我们优先选择不超过输入图像面积两倍的那个,从而防止低分辨率图像过度放大。
图像划分与缩略图
确定合适的宽高比后,图像会被调整到相应的分辨率。例如,一个800×1300的图像会被调整为896×1344。调整大小后的图像随后被划分为448×448像素的patch。除了patch外,我们还包含了一个整个图像的缩略图,以捕捉全局上下文。该缩略图被缩小到448×448,帮助模型理解整个场景。因此,在训练期间,视觉标记的数量从256到3,328不等。在测试时,patch数量可以增加到最多40个,从而产生10,496个视觉token。
3.4 高质量双语数据集
本节总结:
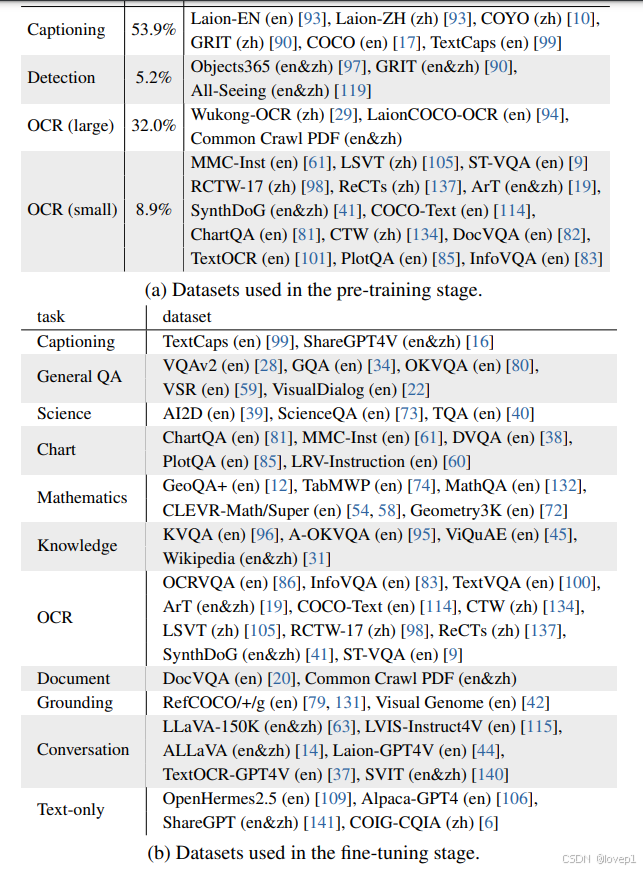
- 预训练数据集:
- 图像caption占比3.9%,主要包括Laion-EN、Laion-ZH、COYO和GRIT
- 大型OCR数据集占比32.%,主要包括Wukong、LaionCOCO
- 小型OCR数据集占比8.9%,主要包括MMC-Inst、LSVT、ST-VQA、RCTW-17、ArT
- 目标检测和定位占比5.2%:主要包括Objects365、GRIT和All-Seeing
- 微调数据集:
- 图像caotion:TextCaps和双语ShareGPT4V
- 通用问答:VQAv2、GQA和VisualDialog
- 科学图像理解:AI2D、ScienceQA和TQA
- 图表解读:ChartQA、MMC-Inst[和PlotQA
- 数学数据集:GeoQA+[12]、TabMWP[74]和MathQA,引入复杂的数值和几何问题
- 知识的问答:KVQA和双语维基百科
- OCR:OCRVQA、TextVQA以及专注于中文和英文文本识别的多个数据集,如SynthDoG
- 文档理解:DocVQA和Common Crawl PDF
- 视觉定位:RefCOCO和Visual Genome
跟1.0比起来,尤其是finetune-stage里面,增加了大量的文档、science等数据集):
四、Experiments
InternVL1.5是基于 InternLM2-20B 的对话版本而非基础模型构建的。训练分为两个阶段。预训练阶段,重点是训练 InternViT-6B 视觉编码器和 MLP ,以优化视觉特征提取。finetune阶段对整个模型的260 亿参数进行了调整,以增强多模态能力。在训练的这两个阶段中,我们都使用了 4096 的上下文长度,并采用了与 LLaVA 1.5 相同的响应格式化提示。此外,评估主要由 VLMEvalKit 提供支持。



欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)