基于内容的电影推荐系统-tdidf doc2vec文本相似推荐及热评分榜、cf模型推荐
首先使用的数据是movielens(用的是10m大小的这份,用户100万数据打分):http://files.grouplens.org/datasets/movielens/ml-10m-README.html1、关于电影hot排行榜统计import pandas as pdcolumn_names = ['user_id', 'item_id', 'rating', 'timesta...
·
首先使用的数据是movielens(用的是10m大小的这份,用户100万数据打分):http://files.grouplens.org/datasets/movielens/ml-10m-README.html
1、关于电影hot排行榜统计
import pandas as pd
column_names = ['user_id', 'item_id', 'rating', 'timestamp']
links = pd.read_csv('/Users/lonng/Desktop/推荐学习/movie_rec/ml-10M100K/ratings.dat',sep="::",names=column_names)
column_names1 = ['item_id', 'title', 'movietype']
movies = pd.read_csv('/Users/lonng/Desktop/推荐学习/movie_rec/ml-10M100K/movies.dat',sep="::",names=column_names1)
movies.head(5)
df = pd.merge(links,movies, on="item_id")
df.head(5)
df = df.drop(columns=['timestamp'])
df.dropna()
df.shape
# # genres and their count
genre_labels = set()
for gen in df['movietype'].str.split('|').values:
genre_labels = genre_labels.union(set(gen))
for x in genre_labels:
print(x, len(df[df['movietype'].str.contains(x)].index))
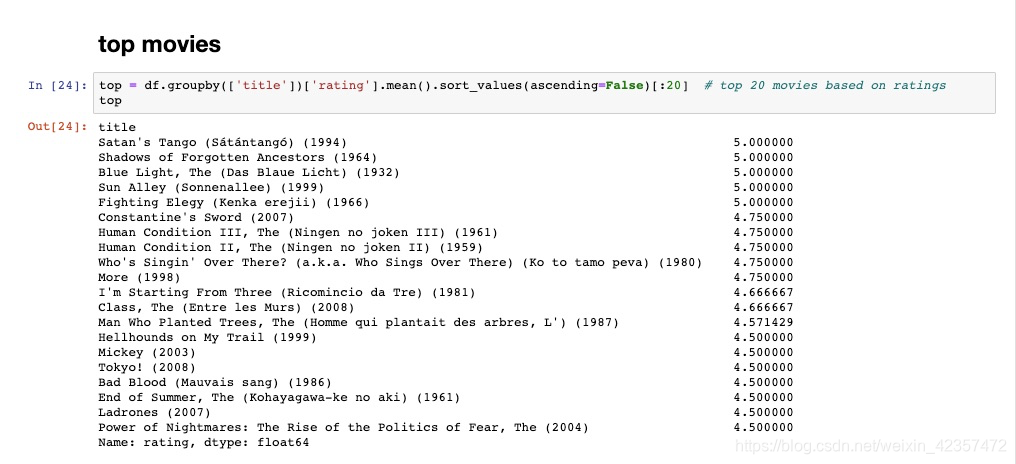
# # top movies
top = df.groupby(['title'])['rating'].mean().sort_values(ascending=False)[:20] # top 20 movies based on ratings
df.groupby(['title'])['rating'].mean()
2、idtdf相识度推荐
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.metrics.pairwise import linear_kernel
movie_types = set()
kk = []
a = open('/Users/lonng/Desktop/推荐学习/movie_rec/ml-10M100K/movies.dat')
for i in a:
# if linenum>5:
# break
# linenum +=1
# print (i)
iteam = i.strip().split('::')
movieid,title,movietype = iteam[0],iteam[1],iteam[2]
mm =''
for j in movietype.split('|'):
movie_types.add(j)
mm += j+" "
ss = {"movieid":movieid,"title":title,"movietype":mm}
kk.append(ss)
movies = pd.DataFrame(kk)
def combine(x):
return x['title'] + " " + x['movietype']
movies['Combined_Data'] = movies.apply(lambda x: combine(x),axis=1)
CountVectorizer与TfidfVectorizer,这两个类都是特征数值计算的常见方法。对于每一个训练文本,CountVectorizer只考虑每种词汇在该训练文本中出现的频率,而TfidfVectorizer除了考量某一词汇在当前训练文本中出现的频率之外,同时关注包含这个词汇的其它训练文本数目的倒数
#Using TFIDF
tf = TfidfVectorizer()
count_matrix = tf.fit_transform(movies["Combined_Data"])
cosine_sim_tf = cosine_similarity(count_matrix)
#cosine_sim_tf
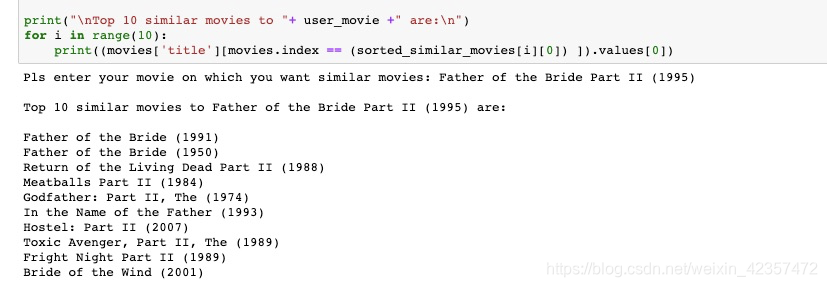
user_movie = input('Pls enter your movie on which you want similar movies: ')
user_index = movies[movies.title == user_movie].index.values[0]
similar_movies = list(enumerate(cosine_sim_tf[user_index]))
sorted_similar_movies = sorted(similar_movies,key=lambda x:x[1],reverse=True)[1:]
#sorted_similar_movies
print("\nTop 10 similar movies to "+ user_movie +" are:\n")
for i in range(10):
print((movies['title'][movies.index == (sorted_similar_movies[i][0]) ]).values[0])
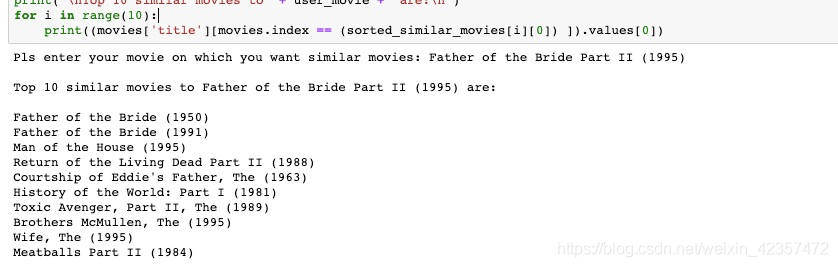
# Using Count Vectorizer
cv = CountVectorizer()
count_matrix = cv.fit_transform(movies["Combined_Data"])
cosine_sim = cosine_similarity(count_matrix)
#cosine_sim
user_movie = input('Pls enter your movie on which you want similar movies: ')
user_index = movies[movies.title == user_movie].index.values[0]
similar_movies = list(enumerate(cosine_sim[user_index]))
sorted_similar_movies = sorted(similar_movies,key=lambda x:x[1],reverse=True)[1:]
#sorted_similar_movies
print("\nTop 10 similar movies to "+ user_movie +" are:\n")
for i in range(10):
print((movies['title'][movies.index == (sorted_similar_movies[i][0]) ]).values[0])
3、doc2vec文本电影推荐
需要注意的是文本分词后的TaggedDocument加载需要的格式
# coding:utf-8
import jieba
import gensim
from gensim.models.doc2vec import Doc2Vec
import pandas as pd
TaggededDocument = gensim.models.doc2vec.TaggedDocument
def get_datasest():
a = open('/Users/lonng/Desktop/推荐学习/movie_rec/ml-10M100K/movies.dat')
x_train = []
df_title = []
for num,i in enumerate(a):
# if linenum>5:
# break
# linenum +=1
# print (i)
iteam = i.strip().split('::')
movieid,title,movietype = iteam[0],iteam[1],iteam[2]
df_title.append(title)
mm =''
for j in movietype.split('|'):
mm += j+" "
text = (title+" "+mm).replace("(","").replace(")","")
word_list = ' '.join(jieba.cut(text)).split(' ')
# print(word_list)
l = len(word_list)
word_list[l - 1] = word_list[l - 1].strip()
document = TaggededDocument(word_list, tags=[num])
x_train.append(document)
return x_train,pd.DataFrame({'Title':df_title})
def train(x_train, size=100, epoch_num=1): ##size 是你最终训练出的句子向量的维度,自己尝试着修改一下
model_dm = Doc2Vec(x_train, min_count=1, window=5, size=size, sample=1e-3, negative=5, workers=4)
model_dm.train(x_train, total_examples=model_dm.corpus_count, epochs=70)
model_dm.save('model_dm_wangyi1') ##模型保存的位置
return model_dm
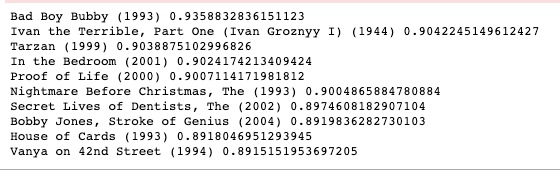
def test():
model_dm = Doc2Vec.load("model_dm_wangyi1")
test_text = ['Divide', '', '', 'and', '', '', 'Conquer', '', '', 'Why', '', '', 'We', '', '', 'Fight', ',', '', '', '3', '', '', '1943', '', '', 'Documentary', '', '', 'War']
inferred_vector_dm = model_dm.infer_vector(test_text)
# print (inferred_vector_dm)
sims = model_dm.docvecs.most_similar([inferred_vector_dm], topn=10)
return sims
if __name__ == '__main__':
x_train,df1 = get_datasest()
model_dm = train(x_train)
# print(x_train)
sims = test()
for count, sim in sims:
print(df1.loc[int(count), "Title"].strip(),sim)
4、cf模型als推荐:
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.sql import Row
import pandas as pd
import pandas as pd
import os
os.environ["PYSPARK_PYTHON"]="/Users/lonng/opt/anaconda3/python.app/Contents/MacOS/python"
spark = SparkSession\
.builder\
.appName("ALSExample")\
.getOrCreate()
column_names = ['user_id', 'item_id', 'rating', 'timestamp']
links = pd.read_csv('/Users/lonng/Desktop/推荐学习/movie_rec/ml-10M100K/ratings.dat',sep="::",names=column_names)
links.head(5)
ratings = spark.createDataFrame(links.iloc[:100000,:])
(training, test) = ratings.randomSplit([0.8, 0.2])
als = ALS(maxIter=5, regParam=0.01, userCol="user_id", itemCol="item_id", ratingCol="rating",
coldStartStrategy="drop")
model = als.fit(training)
# Evaluate the model by computing the RMSE on the test data
predictions = model.transform(test)
evaluator = RegressionEvaluator(metricName="rmse", labelCol="rating",
predictionCol="prediction")
rmse = evaluator.evaluate(predictions)
print("Root-mean-square error = " + str(rmse))
############直接模型预测和先计算出所有用户推荐结果再计算,后者更快
user_subset = ratings.where(ratings.user_id == 10)
user_subset_recs = model.recommendForUserSubset(user_subset, 10)
user_subset_recs.select("recommendations.item_id", "recommendations.rating").first()
# Generate top 10 movie recommendations for each user
userRecs = model.recommendForAllUsers(10)
userRecs.show()
userRecs.where(userRecs.user_id == 10).select("recommendations.item_id", "recommendations.rating").collect()
####################直接模型预测和先计算出所有用户推荐结果再计算,后者更快
item_subset = ratings.where(ratings.item_id == 2)
item_subset_recs = model.recommendForItemSubset(item_subset, 3)
item_subset_recs.select("recommendations.user_id", "recommendations.rating").first()
#Generate top 3 users recommendations for each movie
item_recs = model.recommendForAllItems(3)
item_recs.where(item_recs.item_id == 2)\
.select("recommendations.user_id", "recommendations.rating").collect()

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)