
【Coggle 30 Days of ML】汽车领域多语种迁移学习挑战赛(4)
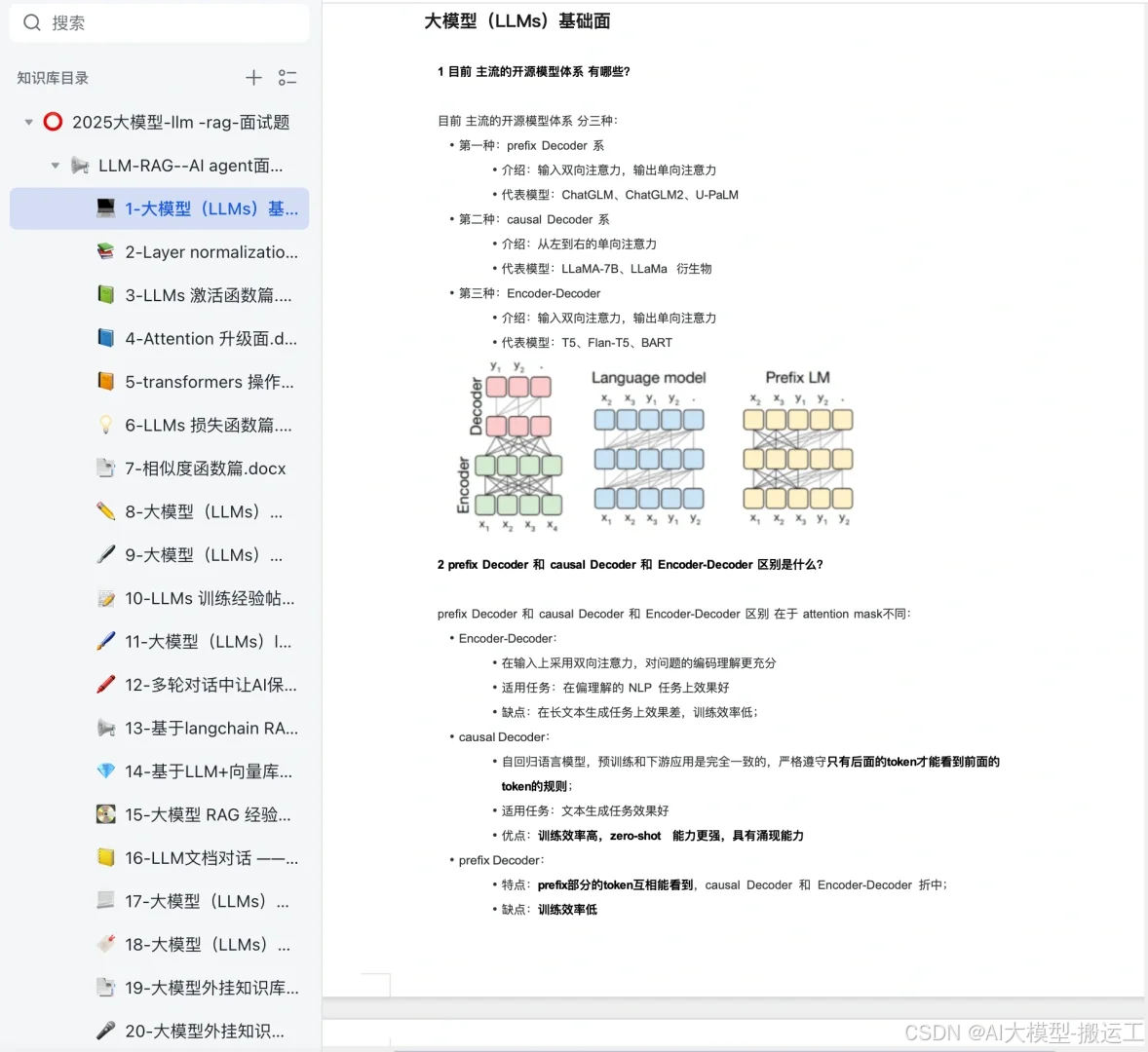
定义数据集读取类和模型类#数据集读取#读取单个样本,0,
目录
任务
-
任务5:BERT模型入门
- 学习transformers库中pipline和加载模型的过程
- 学习transformers库的使用:包括定义数据集,定义模型和训练模型
- 学习资料:
 https://huggingface.co/docs/transformers/main_classes/pipelines
https://huggingface.co/docs/transformers/main_classes/pipelines-
任务6:BERT文本分类
- 步骤1使用BERT完成意图识别(文本分类)
- 步骤2:将步骤1预测的结果文件提交到比赛,截图分数;
- 学习资料:
 https://gitee.com/coggle/competition-baseline/blob/master/tutorial/bert/bert-cls-example.ipynb
https://gitee.com/coggle/competition-baseline/blob/master/tutorial/bert/bert-cls-example.ipynbJust Do It!
1.Bert模型入门
1.1前置知识
bert模型用的库主要是huggingface的transformers库
目前Transformers 库支持三个最流行的深度学习库(PyTorch、TensorFlow 和 JAX)。
Transformers 库比较重要的有:pipeline、AutoTokenizer、AutoModelForSequenceClassification等等的使用。
Pipeline
pipeline() 的作用是使用预训练模型进行推断,它支持从 这里 下载的所有模型。它将模型的预处理, 后处理等步骤包装起来,使得我们可以直接定义好任务名称后,输出文本,直接得到我们需要的结果。这是一个高级的API,可以让我们领略到transformers 这个库的强大且友好。
使用pipeline的api,可以使用transformers快速完成各种任务.
主要有以下三个步骤被包装起来了:
- 输入文本被预处理成机器可以理解的格式
- 被处理后的输入被传入模型中
- 模型的预测结果经过后处理,得到人类可以理解的结果
eg:
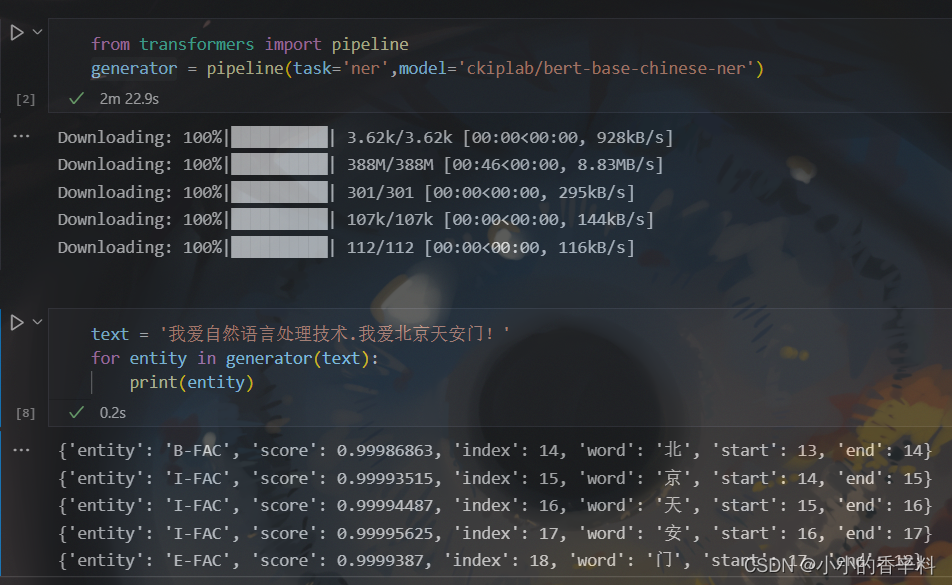
上述是调用pipeline快速使用transformer,上述选择模型部分除了指定model外,还可以使用本地加载。
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenizer
from transformers import pipeline
model_path = r"ckiplab/bert-base-chinese-ner"
model = AutoModelForSequenceClassification.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
classifier = pipeline(task='ner',model=model,tokenizer=tokenizer)
text = '我爱自然语言处理技术.我爱北京天安门!'
for entity in generator(text):
print(entity)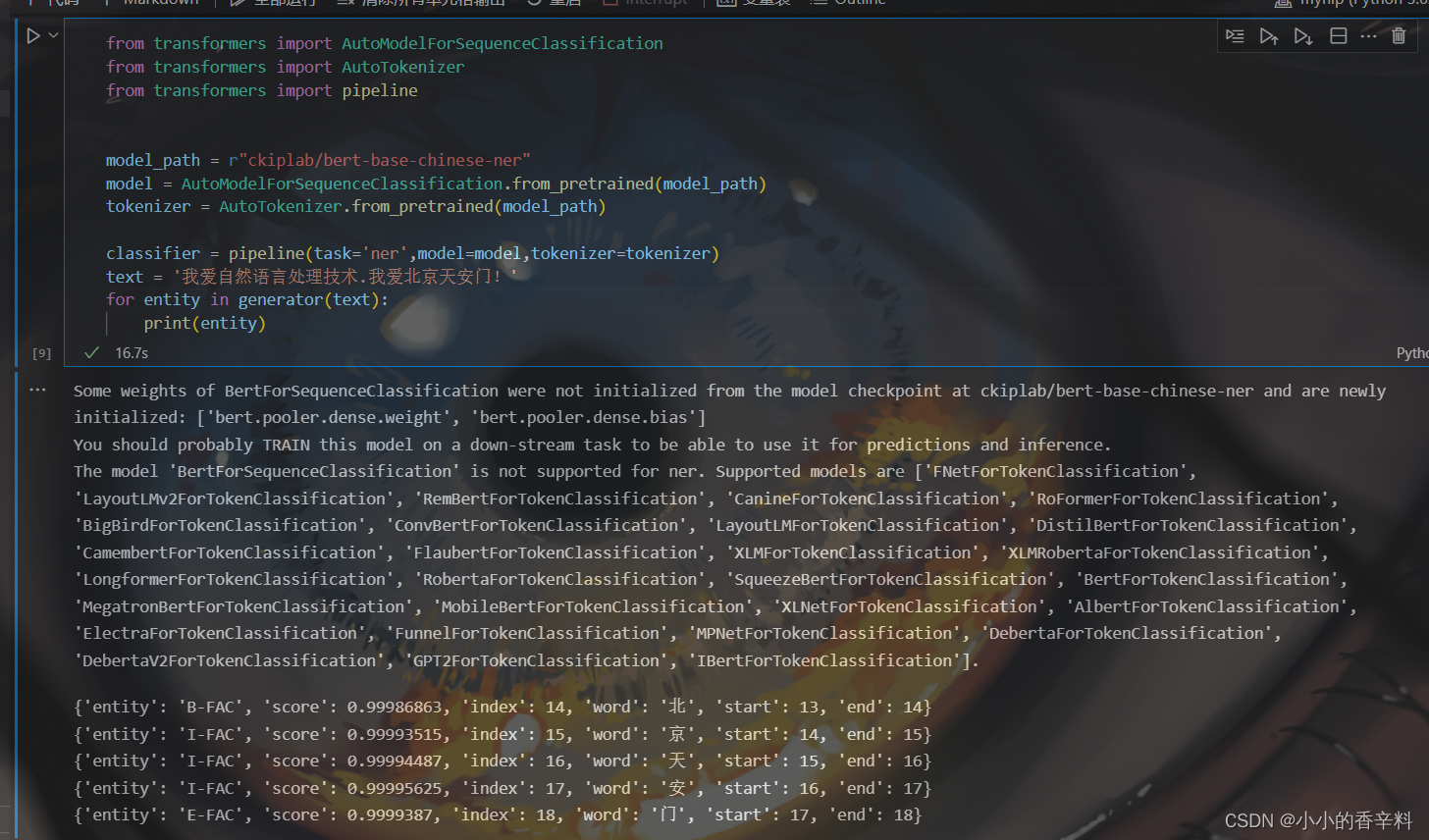
AutoTokenizer
这个类是用来自动下载与模型相关联的标记器,并且可以进行实例化。主要是在将数据喂给模型之前,将数据进行预处理(Tokenize、填充、截断等)。
AutoModelForSequenceClassification
主要是用来加载模型的。这个类是用来去下载模型本身。(注意:⚠️如果我们在别的任务上使用这个库,模型的类会发生改变)
我们已经得到了预训练模型,那么下面就要将输入转化为模型能够接受的形式。怎么转化呢?就是把输入的字符串通过刚刚导入的分词器tokenizer进行转化。
inputs = tokenizer(["阿水很帅,我也这样觉得。", "不对啊,你在欺骗我"], truncation=True, max_length=20, padding=True)
inputs
# input_ids:这个字在vocab次序
# token_type_ids:字符是第一个句子的,还是第二个句子的
# attention_mask:字符是不是padding的? tokenizer后的inputs为字典,包含三个键input_ids、token_type_ids、attention_mask。
tokenizer后的inputs为字典,包含三个键input_ids、token_type_ids、attention_mask。
inputs_ids:为输入字符串中的每个字对应到词典vocab中的序号。其中每句话的开头结尾都添加了特殊标记,开头的特殊标记经过tokenizer变成了101,结尾的编程102。
token_type_ids:字符是第一个句子的,还是第二个句子的。不同的句子对应的标记值也不一样。
attention_mask:主要输入的几个句子当中最长的一句,如果打开了padding,那他就会把其他比最长的一句用0给填补上。观察上图attention_mask的后面3个0就意味着填补。
前置知识了解的差不多了,下面对应到比赛中,步骤如下:
1.2导入预训练模型
我们要做的第一件事就是导入预训练模型
from transformers import AutoTokenizer, AutoModelForMaskedLM, AutoConfig, BertModel, AutoModel
model = AutoModel.from_pretrained("hfl/chinese-roberta-wwm-ext")
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
config = AutoConfig.from_pretrained("bert-base-multilingual-cased")1.3训练数据处理
我们需要先对训练集做一些处理,把训练集中的标签种类去掉。
for tag in ['intent', 'device', 'mode', 'offset', 'endloc', 'landmark', 'singer', 'song']:
train_ja['槽值1'] = train_ja['槽值1'].str.replace(f'{tag}:', '')
train_ja['槽值2'] = train_ja['槽值2'].str.replace(f'{tag}:', '')
train_cn['槽值1'] = train_cn['槽值1'].str.replace(f'{tag}:', '')
train_cn['槽值2'] = train_cn['槽值2'].str.replace(f'{tag}:', '')
train_en['槽值1'] = train_en['槽值1'].str.replace(f'{tag}:', '')
train_en['槽值2'] = train_en['槽值2'].str.replace(f'{tag}:', '')然后再将训练集中的中英日文拼接在一起,再使用pd.factorize对训练集进行编码。
pd.factorize简单来说就是将所有输入的字符做一个unique,去掉相同的字,只剩下两两互斥的列表,假设叫list_unique。然后遍历一遍输入的每个字,根据这个字在list_unique中的位置做一个编码。
train_df = pd.concat([
train_ja[['原始文本', '意图', '槽值1', '槽值2']],
train_cn[['原始文本', '意图', '槽值1', '槽值2']].sample(10000),
train_en[['原始文本', '意图', '槽值1', '槽值2']],
],axis = 0)
train_df = train_df.sample(frac=1.0)
train_df['意图_encode'], lbl_ecode = pd.factorize(train_df['意图'])1.4数据及读取及模型定义
定义数据集读取类和模型类
from torch.utils.data import Dataset, DataLoader, TensorDataset
import torch
from torch import nn
# 数据集读取
class XunFeiDataset(Dataset):
def __init__(self, encodings, intent):
self.encodings = encodings
self.intent = intent
# 读取单个样本
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['label'] = torch.tensor(int(self.intent[idx]))
return item
def __len__(self):
return len(self.intent)
class XunFeiModel(nn.Module):
def __init__(self, num_labels):
super(XunFeiModel,self).__init__()
self.model = model = AutoModel.from_pretrained("bert-base-multilingual-cased")
self.dropout = nn.Dropout(0.1)
self.classifier = nn.Linear(768, num_labels)
def forward(self, input_ids=None, attention_mask=None,labels=None):
outputs = self.model(input_ids=input_ids, attention_mask=attention_mask)
sequence_output = self.dropout(outputs[0]) #outputs[0]=last hidden state
logits = self.classifier(sequence_output[:,0,:].view(-1,768))
return logits2.Bert文本分类
2.1开始读取数据集
train_encoding = tokenizer(train_df['原始文本'].tolist()[:-500], truncation=True, padding=True, max_length=40)
val_encoding = tokenizer(train_df['原始文本'].tolist()[-500:], truncation=True, padding=True, max_length=40)
train_dataset = XunFeiDataset(train_encoding, train_df['意图_encode'].tolist()[:-500])
val_dataset = XunFeiDataset(val_encoding, train_df['意图_encode'].tolist()[-500:])
# 单个读取到批量读取
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=16, shuffle=False)2.2加载模型
将模型加载到gpu上(如果有的话),没有gpu就用cpu加载。
model = XunFeiModel(18)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device = 'cpu'
model = model.to(device)2.3开始训练
from torch.nn import CrossEntropyLoss
from torch.optim import AdamW
loss_fn = CrossEntropyLoss() # ingore index = -1
optim = AdamW(model.parameters(), lr=5e-5)
def train():
model.train()
total_train_loss = 0
iter_num = 0
total_iter = len(train_loader)
for batch in train_loader:
# 正向传播
optim.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
label = batch['label'].to(device)
pred = model(
input_ids,
attention_mask
)
loss = loss_fn(pred, label)
# 反向梯度信息
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# 参数更新
optim.step()
iter_num += 1
if(iter_num % 100 == 0):
print("iter_num: %d, loss: %.4f, %.2f%% %.4f" % (
iter_num, loss.item(), iter_num/total_iter*100,
(pred.argmax(1) == label).float().data.cpu().numpy().mean(),
))
def validation():
model.eval()
label_acc = 0
for batch in val_dataloader:
with torch.no_grad():
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
label = batch['label'].to(device)
pred = model(
input_ids,
attention_mask
)
label_acc += (pred.argmax(1) == label).float().sum().item()
label_acc = label_acc / len(val_dataloader.dataset)
print("-------------------------------")
print("Accuracy: %.4f" % (label_acc))
print("-------------------------------")
for epoch in range(2):
train()
validation()2.4预测
def prediction():
model.eval()
test_label = []
for batch in test_dataloader:
with torch.no_grad():
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
pred = model(input_ids, attention_mask)
test_label += list(pred.argmax(1).data.cpu().numpy())
return test_label
test_encoding = tokenizer(test_en['原始文本'].tolist(), truncation=True, padding=True, max_length=40)
test_dataset = XunFeiDataset(test_encoding, [0] * len(test_en))
test_dataloader = DataLoader(test_dataset, batch_size=16, shuffle=False)
test_en_intent = prediction()
test_encoding = tokenizer(test_ja['原始文本'].tolist(), truncation=True, padding=True, max_length=40)
test_dataset = XunFeiDataset(test_encoding, [0] * len(test_ja))
test_dataloader = DataLoader(test_dataset, batch_size=16, shuffle=False)
test_ja_intent = prediction()
test_ja['意图'] = [lbl_ecode[x] for x in test_ja_intent]
test_en['意图'] = [lbl_ecode[x] for x in test_en_intent]
test_en['槽值1'] = np.nan
test_en['槽值2'] = np.nan
test_ja['槽值1'] = np.nan
test_ja['槽值2'] = np.nan
writer = pd.ExcelWriter('submit.xlsx')
test_en[['意图', '槽值1', '槽值2']].to_excel(writer, sheet_name='英文_testA', index=None)
test_ja[['意图', '槽值1', '槽值2']].to_excel(writer, sheet_name='日语_testA', index=None)
writer.save()
writer.close()
参考内容:
transformers库的使用【一】——pipeline的简单使用_桉夏与猫的博客-CSDN博客_transformers库使用
Transformers 库的基本使用_空杯的境界的博客-CSDN博客_transformers库

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)