VideoLLaMA3:阿里达摩院开源专注于视觉理解的多模态基础模型,具备多语言视频理解能力
VideoLLaMA3 是阿里巴巴开源的多模态基础模型,专注于图像和视频理解,支持多语言生成、视频内容分析和视觉问答任务,适用于多种应用场景。
·
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日分享大模型与 AI 领域的最新开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
🚀 快速阅读
- 多模态输入:支持视频和图像输入,生成自然语言描述,适用于视频内容分析和视觉问答任务。
- 多语言支持:具备跨语言视频理解能力,支持多语言生成,适用于国际化场景。
- 高效时空建模:优化的时空建模能力使其能够处理长视频序列,适用于复杂的视频理解任务。
正文(附运行示例)
VideoLLaMA3 是什么
VideoLLaMA3 是阿里巴巴达摩院开源的多模态基础模型,专注于图像和视频理解。基于 Qwen 2.5 架构,结合了先进的视觉编码器(如 SigLip)和强大的语言生成能力,能够高效处理长视频序列,支持多语言的视频内容分析和视觉问答任务。
VideoLLaMA3 提供多种预训练版本(如 2B 和 7B 参数规模),针对大规模数据进行了优化,具备高效的时空建模能力和跨语言理解能力。该模型支持视频、图像输入,生成自然语言描述,适用于视频内容分析、视觉问答和多模态应用等多种场景。
VideoLLaMA3 的主要功能
- 多模态输入与语言生成:支持视频和图像的多模态输入,能生成自然语言描述,帮助用户快速理解视觉内容。
- 视频内容分析:用户可以上传视频,模型会提供详细的自然语言描述,适用于快速提取视频核心信息。
- 视觉问答:结合视频或图像输入问题,模型能生成准确的答案,适用于复杂的视觉问答任务。
- 多语言支持:具备跨语言视频理解能力,支持多语言生成。
- 高效的时空建模:优化的时空建模能力使其能够处理长视频序列,适用于复杂的视频理解任务。
- 多模态融合:结合视频和文本数据进行内容生成或分类任务,提升模型在多模态应用中的性能。
- 灵活的部署方式:支持本地部署和云端推理,适应不同的使用场景。
VideoLLaMA3 的技术原理
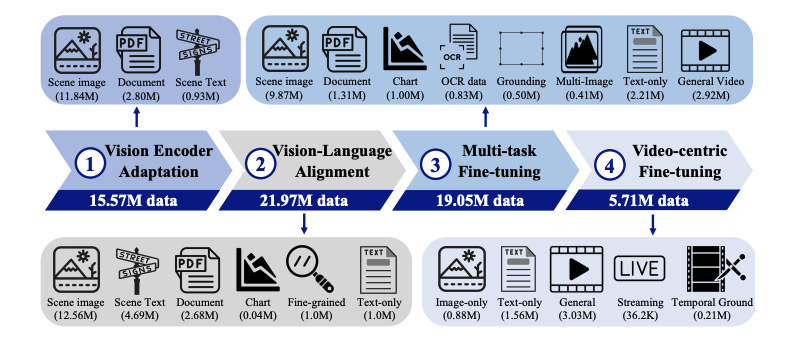
- 视觉为中心的训练范式:VideoLLaMA3 的核心在于高质量的图像文本数据,非大规模的视频文本数据。其训练分为四个阶段:视觉对齐阶段、视觉语言预训练阶段、多任务微调阶段和视频为中心的微调阶段。
- 视觉为中心的框架设计:视觉编码器被优化为能根据图像尺寸生成相应数量的视觉标记,更好地捕捉图像中的细粒度细节。对于视频输入,模型通过减少视觉标记的数量来提高表示的精确性和紧凑性。
- 基于 Qwen 2.5 架构的多模态融合:VideoLLaMA3 基于 Qwen 2.5 架构,结合了先进的视觉编码器(如 SigLip)和强大的语言生成能力,能高效处理复杂的视觉和语言任务。
如何运行 VideoLLaMA3
1. 安装依赖
首先,确保你的环境满足以下要求:
- Python >= 3.10
- Pytorch >= 2.4.0
- CUDA Version >= 11.8
- transformers >= 4.46.3
安装所需的依赖包:
pip install torch==2.4.0 torchvision==0.17.0 --extra-index-url https://download.pytorch.org/whl/cu118
pip install flash-attn --no-build-isolation
pip install transformers==4.46.3 accelerate==1.0.1
pip install decord ffmpeg-python imageio opencv-python
2. 运行推理代码
以下是一个简单的推理示例,展示如何使用 VideoLLaMA3 进行视频内容分析:
import torch
from transformers import AutoModelForCausalLM, AutoProcessor
device = "cuda:0"
model_path = "DAMO-NLP-SG/VideoLLaMA3-7B"
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
device_map={"": device},
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
conversation = [
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{"type": "video", "video": {"video_path": "./assets/cat_and_chicken.mp4", "fps": 1, "max_frames": 128}},
{"type": "text", "text": "What is the cat doing?"},
]
},
]
inputs = processor(
conversation=conversation,
add_system_prompt=True,
add_generation_prompt=True,
return_tensors="pt"
)
inputs = {k: v.to(device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
if "pixel_values" in inputs:
inputs["pixel_values"] = inputs["pixel_values"].to(torch.bfloat16)
output_ids = model.generate(**inputs, max_new_tokens=128)
response = processor.batch_decode(output_ids, skip_special_tokens=True)[0].strip()
print(response)
资源
- GitHub 仓库:https://github.com/DAMO-NLP-SG/VideoLLaMA3
- HuggingFace 仓库:https://huggingface.co/papers/2501.13106
- arXiv 技术论文:https://arxiv.org/pdf/2501.13106
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日分享大模型与 AI 领域的最新开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 15
15 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)