Scrapy框架——Downloader Middleware
新建了一个 Scrapy 项目,名为 scrapydownloadertest。pass修改 start_urls 为:[‘’]。随后将 parse() 方法添加一行日志输出,将 response 变量的 text 属性输出,这样我们便可以看到 Scrapy 发送的 Request 信息了。运行后,显示发送的 Request 信息q=0.9,*/*;q=0.8",},Scrapy 发送的 Requ
本文为学习笔记,部分内容为老师所写,非纯原创
目录
process_request(request, spider)
process_response(request, response, spider)
process_exception(request, exception, spider)
Downloader Middleware 的用法
Downloader Middleware 即下载中间件,它是处于 Scrapy 的 Request 和 Response 之间的处理模块。
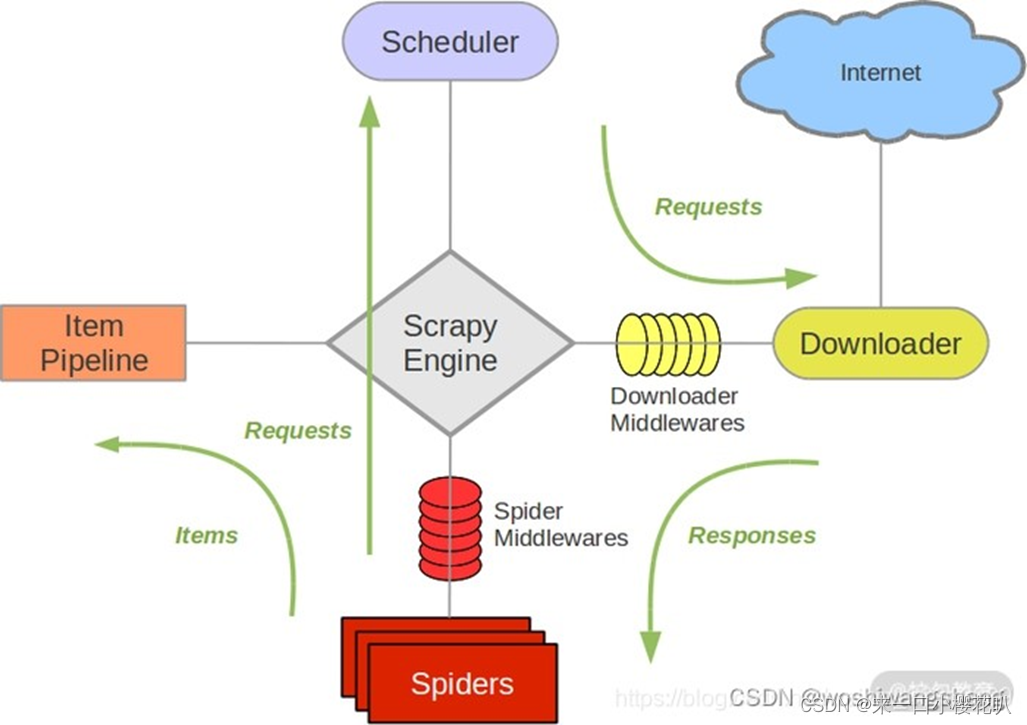
请求去回都要经过下载中间件,去的时候可以对请求进行加工,加headers等,回去的时候检测responses有没有正常返回(比如安居客),没有正常返回可以直接在下载中间件里修改。
可以有多个下载中间件,后边数字越小越靠近engine,request时越先执行,responses时越后执行。
DOWNLOADER_MIDDLEWARES = {
"xiaoshuo1.middlewares.Xiaoshuo1DownloaderMiddleware": 543,
}Downloader Middleware 的功能十分强大,修改 User-Agent、处理重定向、设置代理、失败重试、设置 Cookies 等功能都需要借助它来实现。下面我们来了解一下 Downloader Middleware 的详细用法。
核心方法
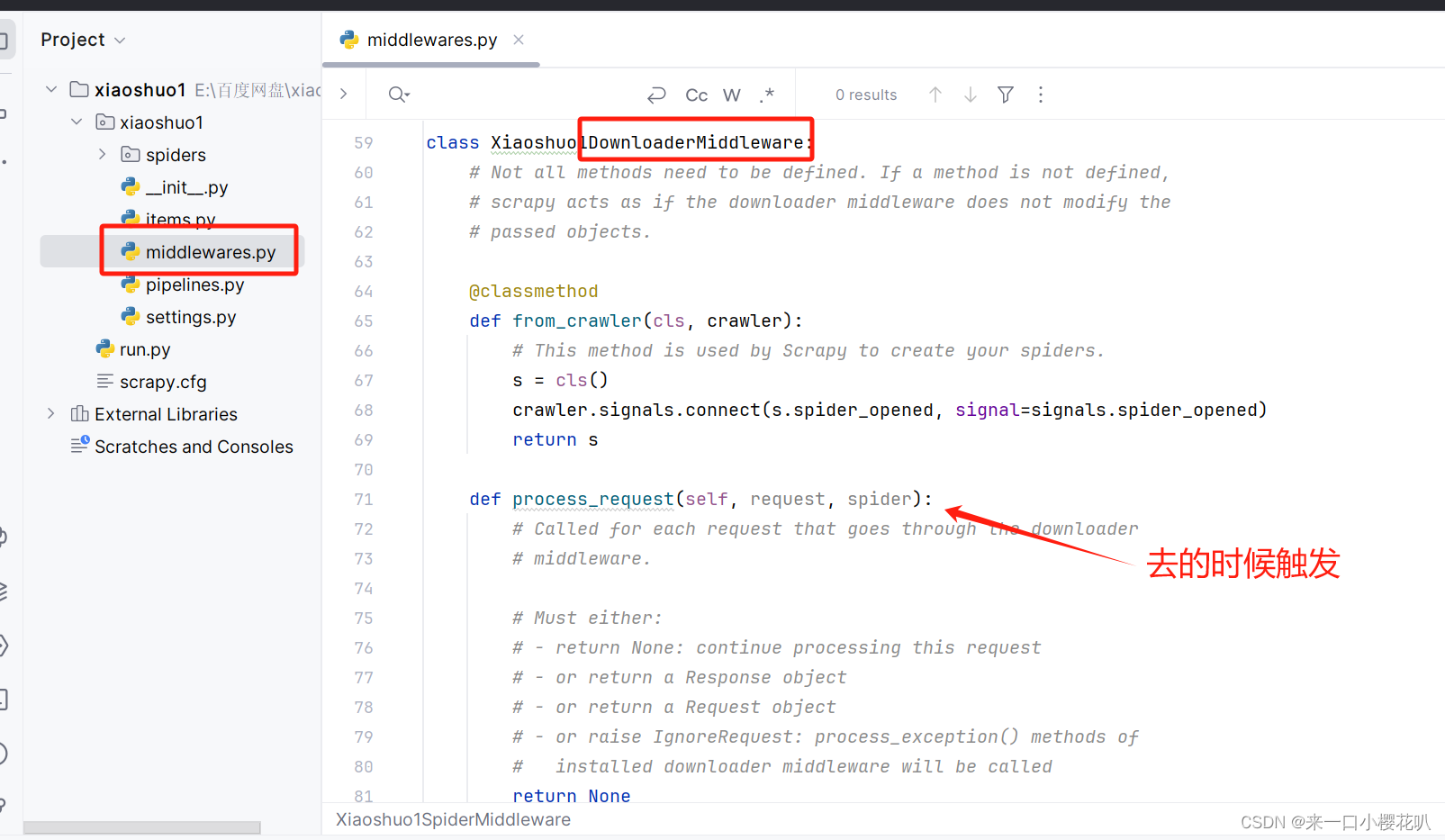

process_request(request, spider)
在 Request 从队列里调度出来到 Downloader 下载执行之前,我们都可以用process_request() 方法对 Request 进行处理。方法的返回值必须为 None、Response 对象、Request 对象之一,或者抛出 IgnoreRequest 异常。
- 当返回为 None 时,Scrapy 将继续处理该 Request,接着执行其他 Downloader Middleware 的 process_request() 方法,直到 Downloader 把 Request 执行后得到 Response 才结束。这个过程其实就是修改 Request 的过程,不同的 Downloader Middleware 按照设置的优先级顺序依次对 Request 进行修改,最后推送至 Downloader 执行。(就是没有阻拦继续往下进行,当下载中间件对request进行修改时,修改也会保留)
- 当返回为 Response 对象时,更低优先级的 Downloader Middleware 的 process_request() 和 process_exception() 方法就不会被继续调用,每个 Downloader Middleware 的process_response() 方法转而被依次调用。调用完毕之后,直接将 Response 对象发送给 Spider 来处理。(就是返回response后会停止往下进行,直接返回到核心引擎,核心引擎直接返回到爬虫处理,剩下的下载中间件就不会调用了)
- 当返回为 Request 对象时,更低优先级的 Downloader Middleware 的 process_request() 方法会停止执行。这个 Request 会重新放到调度队列里,其实它就是一个全新的 Request,等待被调度。如果被 Scheduler 调度了,那么所有的 Downloader Middleware 的 process_request() 方法会被重新按照顺序执行。(就是把请求打回去了,比如发现代理坏了要换一个代理)
- 如果 IgnoreRequest 异常抛出,则所有的 Downloader Middleware 的 process_exception() 方法会依次执行。如果没有一个方法处理这个异常,那么 Request 的 errorback() 方法就会回调。如果该异常还没有被处理,那么它便会被忽略。
process_response(request, response, spider)
Downloader 执行 Request 下载之后,会得到对应的 Response。Scrapy 引擎便会将 Response 发送给 Spider 进行解析。在发送之前,我们都可以用 process_response() 方法来对 Response 进行处理。方法的返回值必须为 Request 对象、Response 对象之一,或者抛出 IgnoreRequest 异常。
-
当返回为 Request 对象时,更低优先级的 Downloader Middleware 的 process_response() 方法不会继续调用。该 Request 对象会重新放到调度队列里等待被调度,它相当于一个全新的 Request。然后,该 Request 会被 process_request() 方法顺次处理。
-
当返回为 Response 对象时,更低优先级的 Downloader Middleware 的 process_response() 方法会继续调用,继续对该 Response 对象进行处理。
-
如果 IgnoreRequest 异常抛出,则 Request 的 errorback() 方法会回调。如果该异常还没有被处理,那么它便会被忽略。
process_exception(request, exception, spider)
当 Downloader 或 process_request() 方法抛出异常时,例如抛出 IgnoreRequest 异常,process_exception() 方法就会被调用。方法的返回值必须为 None、Response 对象、Request 对象之一。
-
当返回为 None 时,更低优先级的 Downloader Middleware 的 process_exception() 会被继续顺次调用,直到所有的方法都被调度完毕。
-
当返回为 Response 对象时,更低优先级的 Downloader Middleware 的 process_exception() 方法不再被继续调用,每个 Downloader Middleware 的 process_response() 方法转而被依次调用。
-
当返回为 Request 对象时,更低优先级的 Downloader Middleware 的 process_exception() 也不再被继续调用,该 Request 对象会重新放到调度队列里面等待被调度,它相当于一个全新的 Request。然后,该 Request 又会被 process_request() 方法顺次处理。
案例
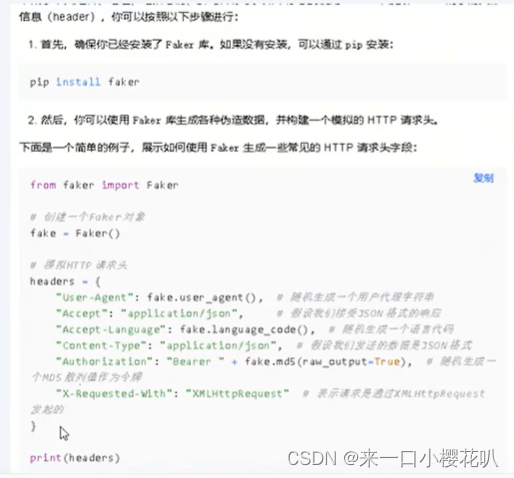
定义header头的三种方法
新建了一个 Scrapy 项目,名为 scrapydownloadertest。进入项目,新建一个 Spider,名为 httpbin:
scrapy startproject scrapydownloadertest
scrapy genspider httpbin httpbin.orghttpbin,源代码:
import scrapy
class HttpbinSpider(scrapy.Spider):
name = 'httpbin'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/']
def parse(self, response):
pass修改 start_urls 为:[‘httpbin.org’]。随后将 parse() 方法添加一行日志输出,将 response 变量的 text 属性输出,这样我们便可以看到 Scrapy 发送的 Request 信息了。 修改 Spider 内容如下所示:
import scrapy
class HttpbinSpider(scrapy.Spider):
name = 'httpbin'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/get']
def parse(self, response):
self.logger.debug(response.text)运行后,显示发送的 Request 信息
{"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip,deflate,br",
"Accept-Language": "en",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "Scrapy/1.4.0 (+http://scrapy.org)"
},
"origin": "60.207.237.85",
"url": "http://httpbin.org/get"
}
Scrapy 发送的 Request 使用的 User-Agent 是 Scrapy/1.4.0(+http://scrapy.org),这其实是由 Scrapy 内置的 UserAgentMiddleware 设置的
修改请求时的 User-Agent 可以有两种方式:一是修改 settings 里面的 USER_AGENT 变量;二是通过 Downloader Middleware 的 process_request() 方法来修改。
第一种方法非常简单,我们只需要在 setting.py 里面加一行 USER_AGENT 的定义即可:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'第二种方法更灵活,可以设置随机的 User-Agent ,在 middlewares.py 里面添加一个 RandomUserAgentMiddleware 的类:
import random
class RandomUserAgentMiddleware():
def __init__(self):
self.user_agents = ['Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2',
'Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1'
]
def process_request(self, request, spider):
request.headers['User-Agent'] = random.choice(self.user_agents)要使其生效,需要在 settings.py 中,将 DOWNLOADER_MIDDLEWARES 取消注释,并设置成如下内容
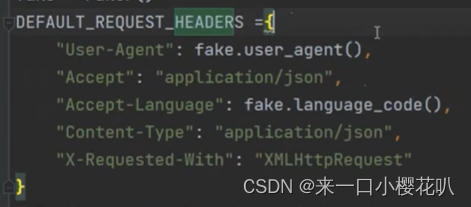
DOWNLOADER_MIDDLEWARES = {'scrapydownloadertest.middlewares.RandomUserAgentMiddleware': 543,}全局修改header头,在setting里直接修改
针对特殊请求进行单个修改:
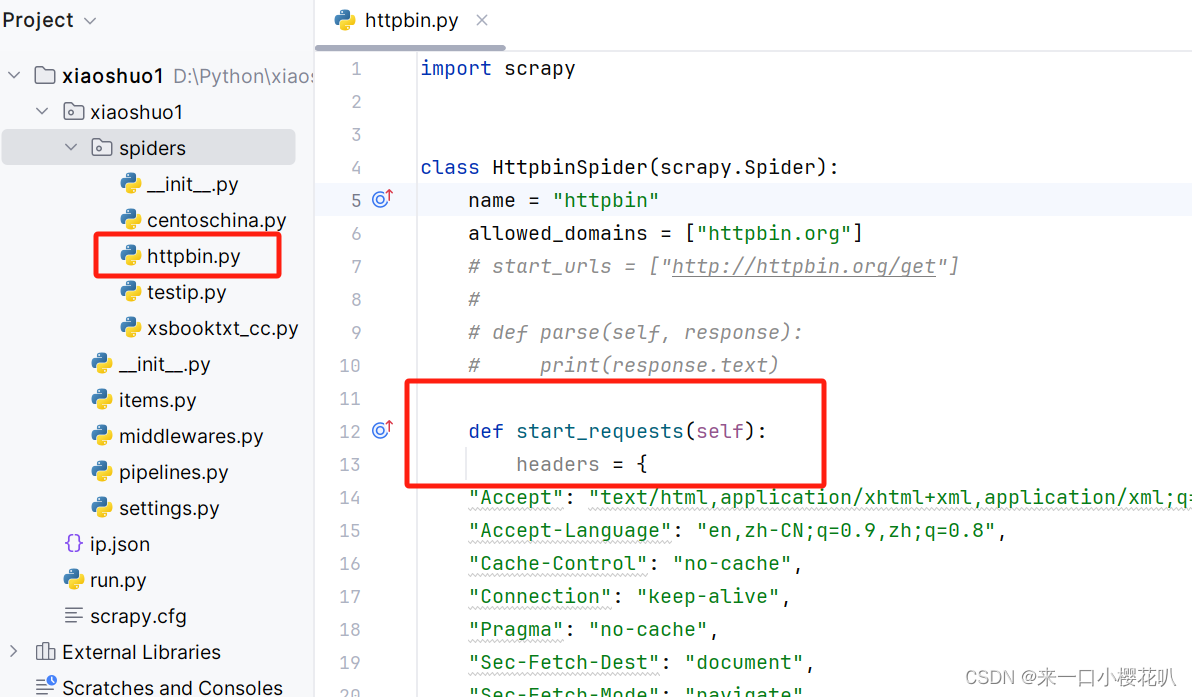
import scrapy
class HttpbinSpider(scrapy.Spider):
name = "httpbin"
allowed_domains = ["httpbin.org"]
# start_urls = ["http://httpbin.org/get"]
#
# def parse(self, response):
# print(response.text)
def start_requests(self):
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en,zh-CN;q=0.9,zh;q=0.8",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Pragma": "no-cache",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"sec-ch-ua": "\"Google Chrome\";v=\"123\", \"Not:A-Brand\";v=\"8\", \"Chromium\";v=\"123\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\""
}
yield scrapy.Request('http://httpbin.org/get',self.demo)
def demo(self,response):
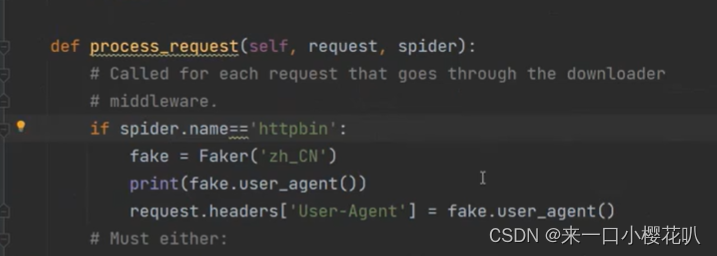
print(response.text)或者使用 middlewares进行修改

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)