文本生成SQL实践-XiYanSQL(析言)
基于阿里实验室开源 XiYanSQL大模型,最强实践,完美实现“智能问数”业务。本文涵盖环境搭建、模型下载,Flask restful api实现的接口示例代码、文本到sql的方案流程(含流程说明),以及PostgreSQL转M-schema的工具。阿里实验室开源Xi YanSQL-QwenCoder系列模型,致力于推进文本到SQL领域的LLM开发。截至目前,Xi YanSQL-QwenCoder
基于阿里实验室开源 XiYanSQL大模型,最强实践,完美实现“智能问数”业务。本文涵盖环境搭建、模型下载,Flask restful api实现的接口示例代码、文本到sql的方案流程(含流程说明),以及PostgreSQL转M-schema的工具。
阿里实验室开源Xi YanSQL-QwenCoder系列模型,致力于推进文本到SQL领域的LLM开发。截至目前,Xi YanSQL-QwenCoder涵盖3B、7B、14B和32B参数四种主流模型大小,以满足不同开发者的需求。
- Xi YanSQL-QwenCoder机型在SQL代表现强劲,XiYanSQL-QwenCoder-32B在BIRD TEST集上取得了69.03%的EX分数,创下了单微调机型的新SOTA,该系列的其他机型也在各自的尺寸上保持领先地位。
- XiYanSQL-QwenCoder模型支持多种SQL方言,如SQLite、PostgreSQL和MySQL。
- Xi YanSQL-QwenCoder模型可以直接用于文本到SQL任务,或者作为微调SQL模型的更好起点。
模型
| 模型 | 配置 | 描述 |
|---|---|---|
| XGenerationLab/XiYanSQL-QwenCoder-32B-2412 | RTX 3090 *2 及以上 |
|
| XGenerationLab/XiYanSQL-QwenCoder-14B-2502 | RTX 3090 及以上 | |
| XGenerationLab/XiYanSQL-QwenCoder-7B-2502 | RTX 3080及以上 | |
| XGenerationLab/XiYanSQL-QwenCoder-3B-2502 | RTX 3080 及以上 | |
| XGenerationLab/DateResolver-Qwen2-7B-Instruct | 为了解决通用大模型在时间感知方面所面临的挑战,我们开发了一套解析处理文本中的时间和日期信息的流程XiYan-DateResolver,并将其转换为准确的真实时间。在覆盖的时间范围内实现了超过95%的准确率,支持包括年、月、日、周、季度、半年及时间段等在内的100多种时间表达方式 |
环境搭建
#创建xiyansql 环境
conda create create -n xiyansql python==3.10.16
#激活环境
conda activate xiyansql
#下载torch
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu124
pip install modelscope
pip install transformers==v4.49.0
pip install 'accelerate>=0.26.0'
pip install packaging模型下载
强烈建议从魔搭下载模型,国内速度快。Hugging Face可能无法访问或者下载。https://modelscope.cn/profile/XGenerationLab?tab=model
代码实现
代码结构
flask-rest-api
├── app
│ ├── __init__.py # 初始化flask应用
│ ├── api.py # 定义api
│ └── model.py # 加载模型及生成
├── requirements.txt # 项目依赖包
└── README.md # 项目readMe文件__init__.py
from flask import Flask
from .api import api_bp, add_resources
from .model import Model
def create_app():
app = Flask(__name__)
# Load the model only once
model = Model()
# Register the API blueprint
app.register_blueprint(api_bp)
# Add the SQLQuery resource with the model instance
add_resources(model)
return appapi.py
from flask import Blueprint, request, jsonify
from flask_restful import Api, Resource
api_bp = Blueprint('api', __name__)
app = Api(api_bp)
class SQLQuery(Resource):
def __init__(self, model):
self.model = model
def post(self):
data = request.get_json()
question = data.get('question')
db_schema = data.get('db_schema')
evidence = data.get('evidence', "")
if not question or not db_schema:
return jsonify({"error": "Question and database schema are required."}), 400
sql_query = self.model.generate_sql(question=question, db_schema=db_schema, evidence=evidence)
return jsonify({"sql_query": sql_query})
# Add the SQLQuery resource to the Api instance
def add_resources(model):
app.add_resource(SQLQuery, '/text2sql', resource_class_args=(model,))
if __name__ == '__main__':
app.run(port=5010, host='0.0.0.0')model.py
from modelscope import AutoModelForCausalLM, AutoTokenizer
import torch
class Model:
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super(Model, cls).__new__(cls)
cls._instance.model_name = "../XiYanSQL-QwenCoder-3B-2502"
cls._instance.model = AutoModelForCausalLM.from_pretrained(
cls._instance.model_name,
torch_dtype=torch.bfloat16,
device_map="cuda:1"
)
cls._instance.tokenizer = AutoTokenizer.from_pretrained(cls._instance.model_name)
return cls._instance
def generate_sql(self, question, db_schema, evidence, dialect="PostgreSQL"):
nl2sqlite_template_cn = """你是一名{dialect}专家,现在需要阅读并理解下面的【数据库schema】描述,以及可能用到的【参考信息】,并运用{dialect}知识生成sql语句回答【用户问题】。
【用户问题】
{question}
【数据库schema】
{db_schema}
【参考信息】
{evidence}
【用户问题】
{question}
```sql"""
prompt = nl2sqlite_template_cn.format(dialect=dialect, db_schema=db_schema, question=question, evidence=evidence)
message = [{'role': 'user', 'content': prompt}]
text = self.tokenizer.apply_chat_template(
message,
tokenize=False,
add_generation_prompt=True
)
model_inputs = self.tokenizer([text], return_tensors="pt").to(self.model.device)
generated_ids = self.model.generate(
**model_inputs,
pad_token_id=self.tokenizer.pad_token_id,
eos_token_id=self.tokenizer.eos_token_id,
max_new_tokens=1024,
temperature=0.1,
top_p=0.8,
do_sample=True,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = self.tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
运行
python -m flask run --host=0.0.0.0 --port=5010提升模型准确度及执行效率,强烈建议将DDL转M-schema,转换工具(PostgreSQL 转 M-schema)
import re
def convert_postgres_to_mschema(sql):
# 提取模式名称和表名
table_match = re.search(r'CREATE TABLE "([^"]+)"\."([^"]+)"', sql)
schema_name = table_match.group(1) if table_match else ''
table_name = table_match.group(2) if table_match else ''
# 提取表注释
table_comment_match = re.search(r'COMMENT ON TABLE [^\']+\'([^\']+)\'', sql)
table_comment = table_comment_match.group(1) if table_comment_match else ''
# 提取字段定义部分
field_matches = re.findall(r'"(\w+)"\s+([a-zA-Z]+)[^,]*,', sql)
# 提取字段注释
comment_matches = re.findall(
r'COMMENT ON COLUMN "[\w_]+"\."[\w_]+"\."(\w+)" IS \'([^\']+)\'',
sql
)
comments = {name: desc for name, desc in comment_matches}
# 提取主键字段
primary_key_match = re.search(r'PRIMARY KEY \("(.*?)"\)', sql)
primary_keys = primary_key_match.group(1).split(', ') if primary_key_match else []
# 类型映射字典
type_mapping = {
'varchar': 'VARCHAR',
'numeric': 'NUMERIC',
'timestamp': 'TIMESTAMP'
}
# 生成输出
output = []
# 添加模式名称和表名
output.append(f'【DB_ID】{schema_name}')
output.append('【Schema】')
output.append(f'#Table:{schema_name}.{table_name},{table_comment}')
output.append('[')
# 生成字段定义
for field, pg_type in field_matches:
field_type = type_mapping.get(pg_type.lower(), pg_type.upper())
comment = comments.get(field, '')
pk_flag = ',Primary Key' if field in primary_keys else ''
output.append(f'({field}:{field_type},{comment}{pk_flag}),')
output.append(']')
return '\n'.join(output)
# 示例使用
postgres_sql = '''
CREATE TABLE "bi"."bi_bc_org_statistics" (
"id" varchar(32) COLLATE "pg_catalog"."default" NOT NULL DEFAULT nextval('"bi".bi_bc_org_statistics_id_seq'::regclass),
"tenant_id" varchar(32) COLLATE "pg_catalog"."default",
"statistics_time" timestamp(6),
"province_code" varchar(32) COLLATE "pg_catalog"."default",
"city_code" varchar(32) COLLATE "pg_catalog"."default",
"county_code" varchar(32) COLLATE "pg_catalog"."default",
"town_code" varchar(32) COLLATE "pg_catalog"."default",
"village_code" varchar(32) COLLATE "pg_catalog"."default",
"statistics_year" varchar(4) COLLATE "pg_catalog"."default",
"org_count" int4 DEFAULT nextval('"bi".bi_bc_org_statistics_id_seq'::regclass),
CONSTRAINT "bi_pb_org_statistics_copy1_pkey" PRIMARY KEY ("id")
)
;
ALTER TABLE "bi"."bi_bc_org_statistics"
OWNER TO "topeak_dev";
COMMENT ON COLUMN "bi"."bi_bc_org_statistics"."id" IS '主键';
COMMENT ON COLUMN "bi"."bi_bc_org_statistics"."tenant_id" IS '租户id';
COMMENT ON COLUMN "bi"."bi_bc_org_statistics"."statistics_time" IS '统计时间';
COMMENT ON COLUMN "bi"."bi_bc_org_statistics"."province_code" IS '省编码';
COMMENT ON COLUMN "bi"."bi_bc_org_statistics"."city_code" IS '市编码';
COMMENT ON COLUMN "bi"."bi_bc_org_statistics"."county_code" IS '县编码';
COMMENT ON COLUMN "bi"."bi_bc_org_statistics"."town_code" IS '镇编码';
COMMENT ON COLUMN "bi"."bi_bc_org_statistics"."village_code" IS '村编码';
COMMENT ON COLUMN "bi"."bi_bc_org_statistics"."statistics_year" IS '统计年份';
COMMENT ON COLUMN "bi"."bi_bc_org_statistics"."org_count" IS '行政组织数量';
COMMENT ON TABLE "bi"."bi_bc_org_statistics" IS '行政组织统计';
'''
print(convert_postgres_to_mschema(postgres_sql))api调用
restapi接口
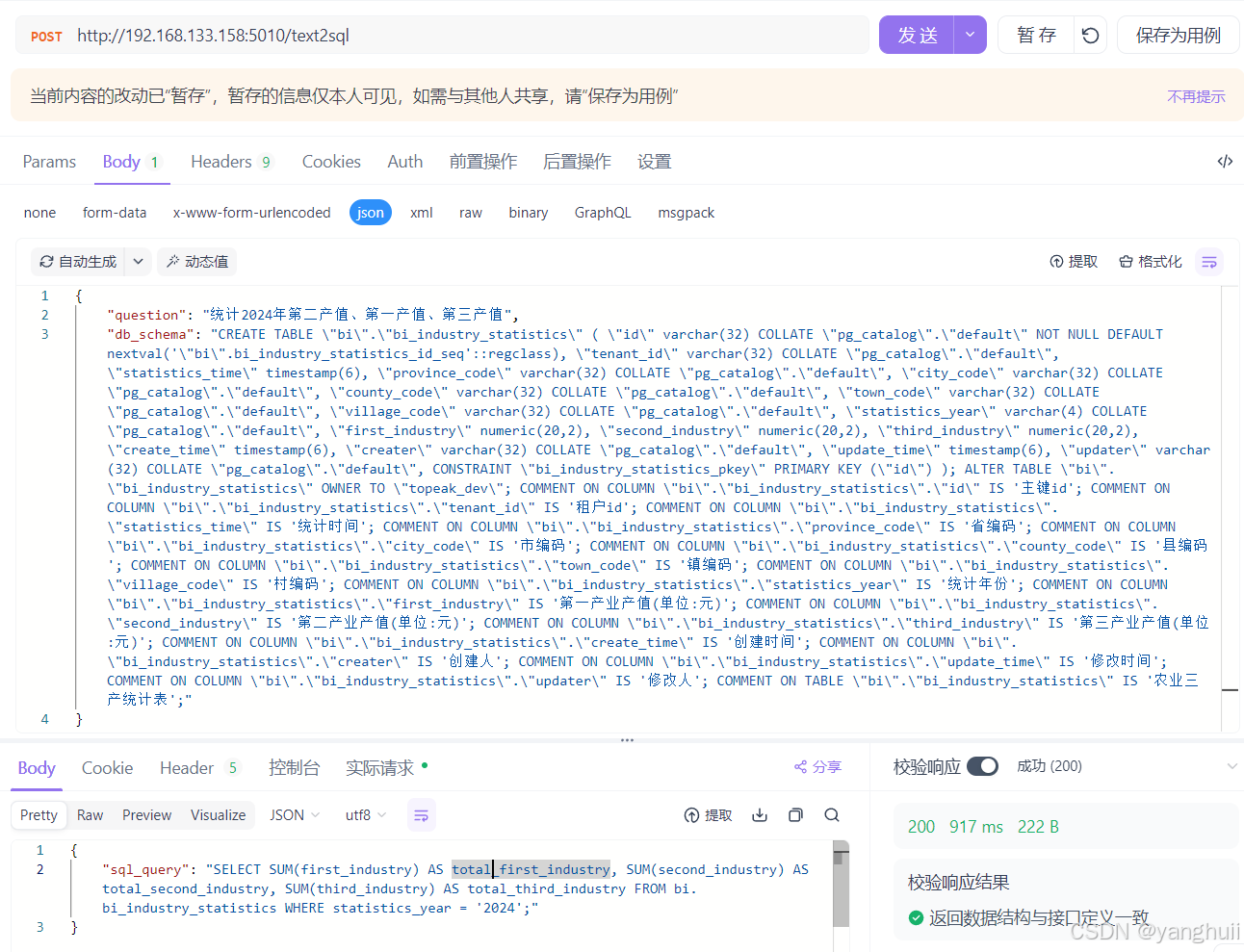
| 接口:/text2sql | ||
|---|---|---|
| 参数 | 是否必填 | 描述 |
|
db_schema |
是 | 表定义:例如 create table.... |
| question | 是 | 问题 |
| 响应 | ||
|
sql_query |
是 | 返回sql语句 |
Apifox 调用示例
方案实现流程
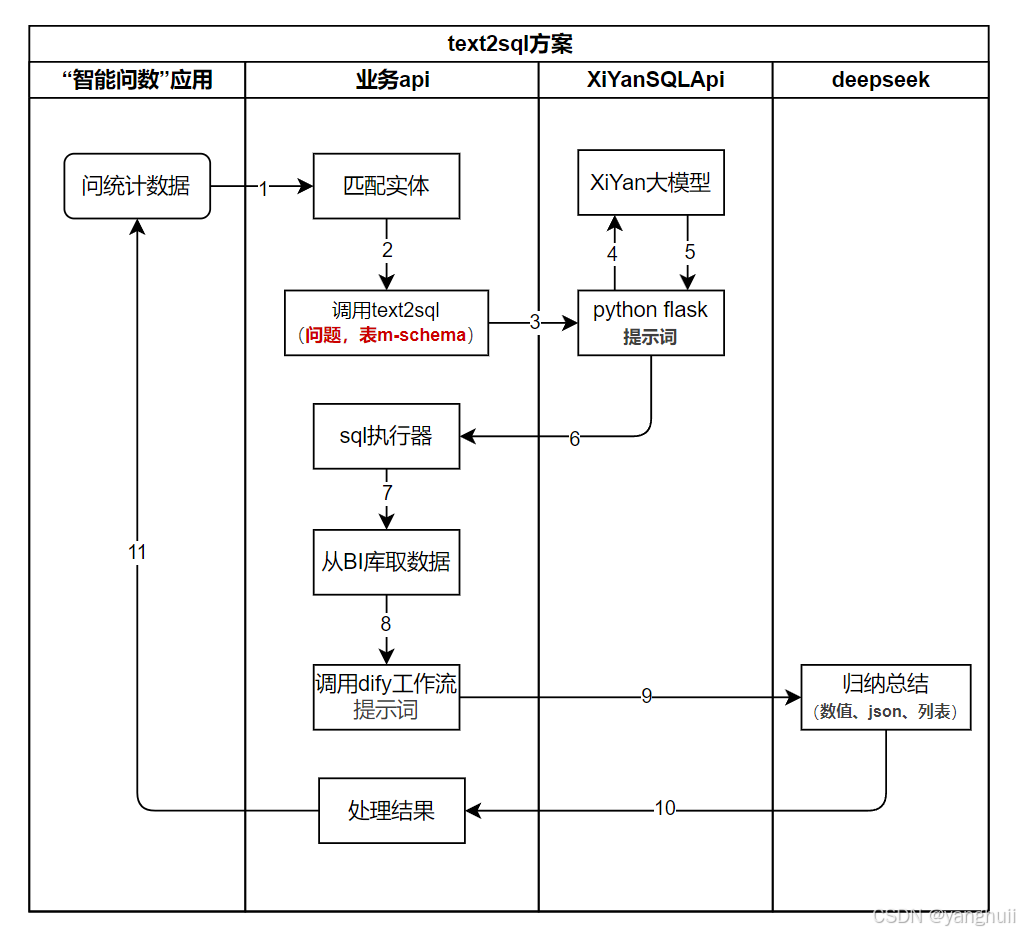
步骤说明:
1、前端应用获取用户输入的问题(语音/文本)
2、业务api调用向量库匹配问题,找到实体表。提交用户问题及表m-schema到XiYanSQLApi。
3、调用XiYan api服务,
4、5 加载本地模型(XiYanSQL-3B),根据提示词模板进行推理。
6、推理结果返回给业务层api。
7、业务api执行大模型返回sql语句,从BI库中获取数据
8、调用dify工作流,将sql执行的结果,拼接提示词
9、dify调用deepseek(或者其他大语言模型),大模型对提交的内容进行归纳总结。例如:结果转为echarts格式数据、统计的数据分析等。
10、大模型返回推理结果。
11、回传给应用层,应用层根据数据格式进行解析。例如:针对图表数据,echarts组件展示;列表数据--列表组件展示;统计结果类:文本展示。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)