对于纽约黄色出租车车费和行程时间预测
本项目旨在利用纽约市出租车行程数据,预测出租车的车费和行程时间。通过对TLC Trip Record Data数据集的深入分析,我们采用了随机森林模型和神经网络模型,对出租车车费进行了预测,并使用神经网络模型对行程时间进行了预测。本报告将详细介绍数据处理流程、使用的模型以及预测结果。本文所利用的数据集是在,获取的2024年一月份黄色出租车行程记录,根据给定的接送地点,预测纽约市出租车的车费和行程时
一、项目概述
本项目旨在利用纽约市出租车行程数据,预测出租车的车费和行程时间。通过对TLC Trip Record Data数据集的深入分析,我们采用了随机森林模型和神经网络模型,对出租车车费进行了预测,并使用神经网络模型对行程时间进行了预测。本报告将详细介绍数据处理流程、使用的模型以及预测结果。
二、数据集介绍
本文所利用的数据集是在TLC Trip Record Data - TLC (nyc.gov),获取的2024年一月份黄色出租车行程记录,根据给定的接送地点,预测纽约市出租车的车费和行程时间。 提供的数据集字段主要有:
VendorID:供应商ID,表示提供此次出租车服务的公司或供应商。
tpep_pickup_datetime:乘客上车的时间戳,表示出租车行程的起始时间。
tpep_dropoff_datetime:乘客下车的时间戳,表示出租车行程的结束时间。
passenger_count:乘客数量,表示乘坐此次出租车行程的乘客人数。
trip_distance:行程距离,表示出租车从起点到终点的行驶距离(通常以英里为单位)。
RatecodeID:费率代码ID,表示此次行程的费率类型,例如高峰时段、夜间费率等。
store_and_fwd_flag:存储和转发标志,用于指示该记录是否是因为设备故障而稍后转发到系统的。
PULocationID:上车点ID,表示乘客上车的具体位置(通常是基于一个预定义的地理区域或位置代码)。
DOLocationID:下车点ID,表示乘客下车的具体位置(同样是基于一个预定义的地理区域或位置代码)。
payment_type:支付方式,表示乘客如何支付出租车费用,例如现金、信用卡等。
fare_amount:基础车费,表示此次行程的基础费用(不包括其他费用如附加费、税费等)。
extra:附加费,表示额外的费用,例如行李费、夜间服务费等。
mta_tax:MTA税,表示纽约市运输局(MTA)征收的税费。
tip_amount:小费金额,表示乘客给司机的小费。
tolls_amount:过路费金额,表示行程中可能产生的过路费(如桥梁或隧道的费用)。
improvement_surcharge:改进费或附加费,表示特定的附加费用,可能是针对特定服务或时间的。
total_amount:总金额,表示乘客需要支付的总费用(包括基础车费、附加费、税费、小费等)。
congestion_surcharge:拥堵费,表示在高峰时段或拥堵区域行驶时可能产生的额外费用。
Airport_fee:机场费,如果行程的起点或终点是机场,可能产生的额外费用。
此本文利用所得的数据集进行缺失值处理、特征提取和选择、建模等步骤,最后利用测试集来预测票价。
三、模型的使用
1车费预测模型
使用随机森林模型对车费进行预测,通过调整参数优化模型性能。
同时,构建神经网络模型进行对比实验,评估不同模型的预测效果。
2行程时间预测模型
使用神经网络模型对行程时间进行预测,通过调整网络结构和参数优化模型性能。
四、程序设计,流程图
1.数据处理
(1)数据清洁
获取到的文件为yellow_tripdata.parquet,首先我先将该文件转为test_yellow_tripdata.csv文件,再将test_yellow_tripdata.csv中的数据划分为训练集、验证集和测试集。训练集占总数据的百分之70,验证集和测试集各占总数据的百分之15。
首先检查训练集、验证集和测试集的大小。检查训练集、验证集和测试集的缺失值。我认为乘客数量缺失代表此行数据无用,并且我考虑到出租车的载客数量,所以我将出租车的载客人数最大值限制到6,在训练集中检查大于6的数据发现有16行,验证集中检查大于6的数据发现只有4行,测试集中检查大于6的数据发现只有3行,我在各集合中将大于6的数据删除。然后我处理RatecodeID 费率,我用他的众数1对缺失值进行补充。再处理congestion_surcharge和Airport_fee,我使用众数填充。接着我对组成总费用的这些费用字段进行处理fare_amount,extra,mta_tax,tip_amount,tolls_amount,improvement_surcharge,congestion_surcharge,Airport_fee,我统一识别这些字段的异常值,即费用不能是负数,对于异常值处理,我选择用0替换负值。对于总车费字段total_amount,我检查费用小于0的部分将小于0的部分数据删除。行程距离trip_distance的处理,我将行程距离小于0或者大于100的数据删除。然后更改tpep_pickup_datetime和tpep_dropoff_datetime的数据类型,将object的数据类型更改为datetime64类型。再确定 dataset DataFrame 中 'tpep_pickup_datetime' 和'tpep_dropoff_datetime'列的第一个元素的类型。统计并删除距离为0,票价为0的数据 全部为0 对模型来说没有用处。统计并删除距离为0,票价不为0的数据 。原因1:司机等待乘客很长时间,乘客最终取消了订单,乘客依然支付了等待的费用;原因2:车辆的经纬度没有被准确录入或缺失;再创建新的字段用于车费预测使用:每公里车费即根据距离、车费,计算每公里的车费,添加新列fare_per_km来计算每公里车费,注意:我们需要处理trip_distance为0的情况,以避免除以零的错误。
创建新字段:行程时长:从tpep_dropoff_datetime和tpep_pickup_datetime计算出实际的行程时间,以分钟为单位。
(2)特征提取和选择
然后选取特征列 (X_train)和选取目标列 (y_train),验证集也是相同操作,需注意的是验证集所选的要与训练集一样,test集知选取特征列也与训练集相同,而test集的目标列就是我们要预测的值所以不用选取。
2.模型构建与训练
缩放特征列数据,然后构建LSTM模型,接着编译模型,使用Adam优化器,使用均方误差作为损失函数,添加其他评估指标,如平均绝对误差。然后进行模型训练,使用训练集训练完后再添加验证集。
接着提取MSE和MAE,计算RMSE,预测验证集,计算r平方。然后使用验证集对模型进行评估,
再缩放test集的特征列数据,然后进行预测,使用model.evaluate评估模型并获取损失值(默认为MSE),最后将预测结果保存为trip_duration_predictions.csv文件和total_amount_predictions2.csv文件。
3流程图:

五、实验结果,模型优缺点
1.实验结果
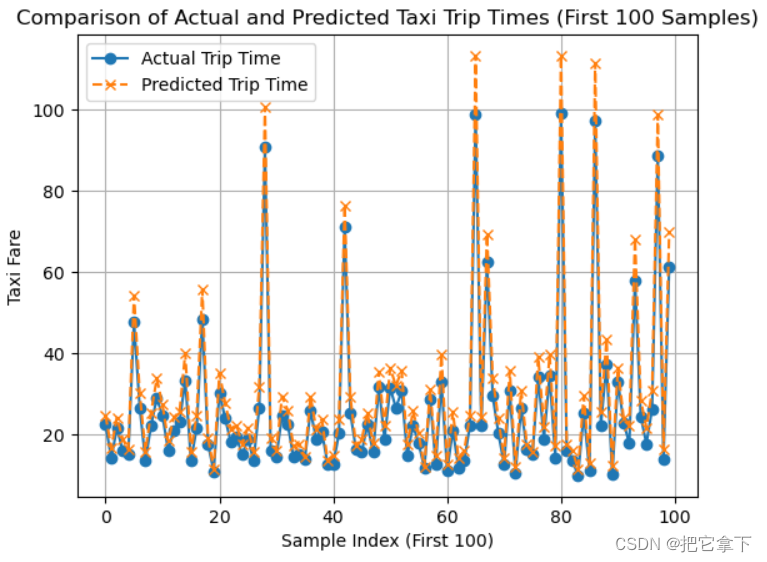
下图为我们得出的实际车费(蓝色线)与预测车费(黄色线)的对比图,选择100个数据是为了让图看着比较直观,数据太多图会显得很杂乱,看不出效果
下图为我们得出的实际行程时间(蓝色线)与预测行程时间(黄色线)的对比图,选择100个数据是为了让图看着比较直观,数据太多图会显得很杂乱,看不出效果
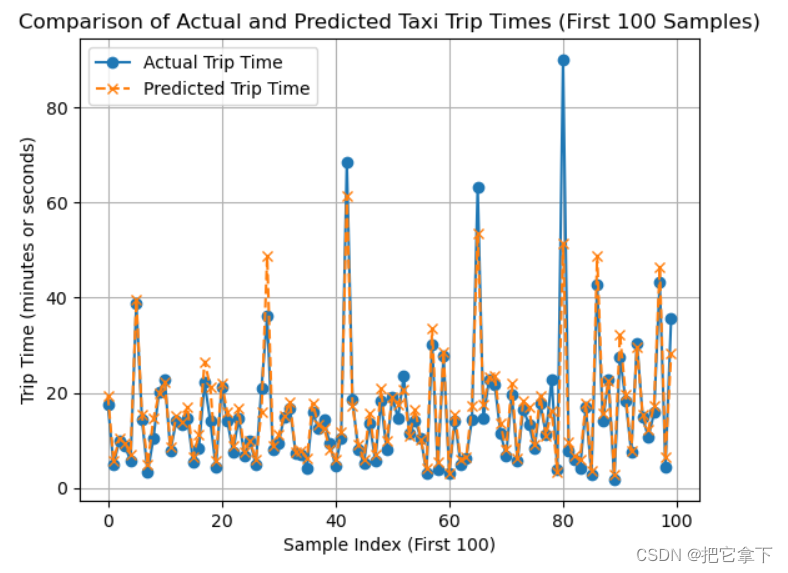
两个预测我都采用的是LSTM模型
2.模型优缺点:
(1)车费预测:
随机森林模型
优点:
强大的泛化能力:由于随机森林集成了多棵决策树,因此它通常具有比单棵决策树更好的泛化能力,能够处理复杂的非线性关系。
对异常值和噪声的鲁棒性:由于每棵树都使用部分数据和部分特征进行训练,因此随机森林对异常值和噪声的敏感度较低。
易于理解和解释:虽然随机森林是一个集成模型,但其基础是决策树,这使得它相对容易理解和解释。
高效的处理能力:在训练过程中,随机森林可以并行处理多个决策树,因此具有较高的计算效率。
缺点:
对参数敏感:随机森林的性能受到多个参数(如树的数量、树的深度、最大特征数等)的影响,需要仔细调整。
过拟合风险:如果树的数量过多或树的深度过大,随机森林可能会过拟合训练数据,导致在测试数据上性能下降。
神经网络模型
优点:
强大的非线性映射能力:神经网络能够学习和逼近复杂的非线性映射关系,对车费这种可能受多种因素影响的变量具有较好的预测能力。
自适应性:神经网络能够自动学习并更新模型参数,以适应不同数据集和任务的需求。
高灵活性:通过调整网络结构、激活函数和优化算法等,可以构建出各种复杂的神经网络模型,以满足不同的预测需求。
缺点:
计算量大:神经网络的训练通常需要大量的计算资源和时间,尤其是在处理大规模数据集时。
容易过拟合:如果网络结构过于复杂或训练数据不足,神经网络容易过拟合训练数据,导致在测试数据上性能下降。
可解释性差:与随机森林相比,神经网络的决策过程较为复杂,难以直观地解释其预测结果。
(2)行程时间预测
神经网络模型
优点:
能够处理时间序列数据:行程时间通常与时间、日期等因素有关,神经网络能够捕捉这些时间相关的特征,从而更准确地预测行程时间。
自适应性:神经网络能够根据训练数据自动学习并更新模型参数,以适应不同交通状况和路线的需求。
高灵活性:通过调整网络结构、激活函数和优化算法等,可以构建出各种复杂的神经网络模型,以满足不同的预测需求。
缺点:
计算量大:与车费预测模型类似,神经网络的训练需要大量的计算资源和时间。
容易过拟合:如果网络结构过于复杂或训练数据不足,神经网络容易过拟合训练数据,导致在测试数据上性能下降。
对初始参数敏感:神经网络的性能受到初始参数(如权重和偏置)的影响,需要仔细调整。
六、总结与展望
本项目基于纽约市出租车行程数据的深入分析,成功开发了两个核心预测模型:出租车车费预测模型和行程时间预测模型。这两个模型不仅展现了强大的预测能力,而且为乘客和出租车司机提供了实用的决策支持工具,有助于提升城市出行效率和服务质量。
在车费预测方面,我们选择了随机森林模型,并通过精细的参数调整和优化,实现了对出租车车费的准确预测。随机森林模型以其优秀的泛化能力和对噪声的鲁棒性,在复杂的数据集中展现出了强大的适应能力。此外,该模型还提供了较高的可解释性,使得预测结果更加直观易懂。
在行程时间预测方面,我们采用了神经网络模型,并针对性地设计了网络结构和优化算法。神经网络模型凭借其强大的非线性映射能力和自适应性,能够捕捉数据中隐藏的复杂关系,从而实现对行程时间的精确预测。尽管神经网络模型的计算量较大且容易过拟合,但通过适当的网络设计和参数调整,我们成功地克服了这些挑战,并取得了令人满意的预测效果。
展望未来,我们将继续致力于优化这两个预测模型的性能。首先,我们将探索更多的特征工程技术,以进一步提升模型的预测精度。例如,我们可以考虑将天气、交通状况等外部因素纳入模型输入,以更全面地反映实际出行环境。其次,我们将尝试引入更先进的机器学习算法和深度学习框架,如集成学习、深度神经网络等,以挖掘数据中更多的潜在信息。此外,我们还将关注模型的实时性和可扩展性,以满足城市交通管理的实时需求和大规模数据处理能力。
除了优化模型性能外,我们还计划将这两个预测模型应用于更多的实际场景中。例如,我们可以将车费预测模型与打车软件结合使用,为乘客提供实时、准确的打车费用估算服务;将行程时间预测模型应用于城市交通规划和管理中,为交通拥堵预测和疏导提供有力支持。此外,我们还将探索与其他领域的交叉融合应用,如智能交通系统、无人驾驶技术等,为城市交通出行提供更加智能、便捷的解决方案。
总之,本项目所构建的出租车车费和行程时间预测模型为城市交通出行提供了重要的技术支撑。未来,我们将不断优化模型性能、拓展应用场景,为城市交通出行的发展贡献更多的智慧和力量。
初学者自己做的,做的不好多多包涵,想要源码的话可以联系我。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)