【医学影像 AI】ROP 自动分期的半监督深度学习模型的开发与验证
论文 “ROP 自动分期的半监督深度学习模型的开发与验证”,本研究的贡献在于:1. 提出一种新的半监督分类模型,用于利用未标注数据进行 ROP 分期。2. 提出两种一致性损失函数,可以提高分类模型的泛化性能。3. 通过实验验证了该方法能够提升分类性能。
【医学影像 AI】ROP 自动分期的半监督深度学习模型的开发与验证
0. 论文简介
0.1 基本信息
2024 年,Wei Feng 等在 iScience发表论文 “ROP 自动分期的半监督深度学习模型的开发与验证(Development and validation of a semi-supervised deep learning model for automatic retinopathy of prematurity staging)”。
本研究的贡献在于:
-
提出一种新的半监督分类模型,用于利用未标注数据进行 ROP 分期。
本文提出了一种创新的半监督学习框架,能够有效利用大量未标注的ROP图像数据,减少对标注数据的依赖,从而降低临床场景中的标注成本。 -
提出两种一致性损失函数,从未标注数据中高效挖掘信息。
设计了两种一致性正则化策略:预测一致性损失和语义结构一致性损失。这些策略帮助模型从未标注数据中提取有用的判别信息,提升模型的泛化能力和分类性能。 -
通过实验验证了该方法能够提升分类性能。
通过在真实临床数据集上的大量实验,验证了所提出方法的有效性。实验结果表明,该方法在减少标注需求的同时,显著提高了ROP分期的分类性能。
论文下载: iScience,(https://www.sciencedirect.com/science/article/pii/S2589004223025932)
引用格式:
Wei Feng, Qiujing Huang, Tong Ma, et al., Development and validation of a semi-supervised deep learning model for automatic retinopathy of prematurity staging, iScience, 2024, 27(1), 108516, https://doi.org/10.1016/j.isci.2023.108516.

0.2 摘要
-
背景:
早产儿视网膜病变(Retinopathy of Prematurity, ROP)是目前全球范围内导致婴儿失明的主要原因之一。近年来,基于深度学习的计算机辅助诊断方法取得了显著进展。然而,深度学习通常需要大量标注数据来进行模型优化,而这在临床场景中需要经验丰富的医生花费大量时间进行标注。相比之下,大量未标注的图像相对容易获取。 -
研究内容:
在本文中,我们提出了一种新的半监督学习框架,旨在降低自动ROP分期的标注成本。我们设计了两种一致性正则化策略:预测一致性损失和语义结构一致性损失。这些策略可以帮助模型从未标注的数据中挖掘有用的判别信息,从而提高分类模型的泛化性能。 -
实验结果:
在一个真实的临床数据集上进行的大量实验表明,所提出的方法有望在临床场景中大幅减少标注需求,同时实现良好的分类性能。
关键词:
健康技术;应用计算
0.3 总结
早产儿视网膜病变(ROP)是目前全球范围内导致婴儿失明的主要原因之一。近年来,基于深度学习的计算机辅助诊断方法取得了显著进展。然而,深度学习通常需要大量标注数据来进行模型优化,而这在临床场景中需要经验丰富的医生花费大量时间进行标注。相比之下,大量未标注的图像相对容易获取。
在本文中,我们提出了一种新的半监督学习框架,旨在降低自动ROP分期的标注成本。
我们设计了两种一致性正则化策略:预测一致性损失和语义结构一致性损失。这些策略可以帮助模型从未标注的数据中挖掘有用的判别信息,从而提高分类模型的泛化性能。
在一个真实的临床数据集上进行的大量实验表明,所提出的方法有望在临床场景中大幅减少标注需求,同时实现良好的分类性能。
1. 引言
早产儿视网膜病变(ROP, Retinopathy of prematurity)是一种早产儿视网膜发育异常的增殖性疾病[1]。它仍然是全球儿童失明的主要原因之一。RetCam 广域数字视网膜成像系统(Natus Medical Incorporated,美国加利福尼亚州圣卡洛斯)是目前用于 ROP 筛查的主要仪器之一。它具有 130° 广角镜头,在瞳孔扩张后,可以实现视网膜的多方向成像。此外,RetCam 系统不仅提供眼底摄影,还支持图像存储和传输,为远程医疗和人工智能应用奠定了基础[2]。早产儿的眼科检查需要频繁且密切的监测,导致手动图像阅读的工作量巨大[2]。然而,在临床上,ROP 1 期、2 期和 3 期的诊断存在主观性和诊断差异[3,4]。未能及时发现和治疗 ROP 会导致晚期 ROP,从而引起视力低下甚至失明。此外,经验丰富的儿科眼科医生供不应求,大多数集中在大城市或大型医疗中心。居住在偏远地区的 ROP 婴儿需要长途转诊,这会延误治疗。此外,在某些情况下,由于整体健康状况不佳,他们可能无法获得转诊机会。因此,远程医疗和计算机辅助 ROP 眼底图像阅读具有极大的实用价值。
近年来,深度学习技术在计算机视觉[5,6]、自然语言处理[7,8]和语音识别[9,10]等多个领域取得了突破性进展。在 ROP 图像分析领域,许多深度学习模型也被提出用于计算机辅助筛查和诊断。Peng 等人[11]提出了一种用于 ROP 分期的深度学习模型,利用并行特征提取、深度特征融合和序列分类器来提取更丰富的特征表示。Wang 等人[12]提出了一个两阶段深度学习模型,分别为 Id-Net 和 Gr-Net,分别用于 ROP 识别和 ROP 分期任务。Lei 等人[13]引入了通道注意力和空间注意力机制,以提高 ROP 检测的性能。然而,深度学习方法通常需要大量标注数据进行模型训练。在临床场景中,即使对于经验丰富的医生来说,标注大量数据也往往耗时且费力。对于 ROP 眼底图像的标注,临床医生通常根据 ROP 眼底图像中脊的形状和大小来确定 ROP 的分期。通过这种方式,4 期或 5 期 ROP 眼底图像很容易区分,而正常眼底图像、1 期 ROP 图像或 2 期 ROP 图像可能会被临床医生误判,因为这些图像处于疾病的早期阶段,病变特征不明显,从而增加了临床医生的负担。相比之下,我们通常可以获取大量未标注的数据,这些数据相对容易获得,并且可能对模型的分类性能有益。
半监督学习被提出以减少对标注的需求,因为数据标注耗时且费力。在给定少量标注数据的情况下,半监督学习通过利用大量未标注数据来提高模型的分类性能[14,15]。目前最先进的半监督学习策略是一致性正则化,它不依赖于数据标签,而是通过约束模型在不同数据扰动下的预测一致性来提高模型的分类性能[16,17,18]。已有一些研究将半监督学习用于医学图像分析任务[19,20,21]。例如,Zhao 等人[22]提出了一种基于半监督学习的两阶段级联网络,用于杯盘比估计。Adal 等人[23]提出了一种半监督学习方法,使用少量手动标记和大量未标注的眼底图像来自动检测微动脉瘤(MAs)。Liu 等人[24]提出了一种半监督条件生成对抗网络(GANs),用于视杯和视盘的联合分割。Liu 等人[25]提出了一种利用不同样本之间关系信息的半监督深度学习模型,提高了模型的分类性能,并在皮肤病分类和胸部疾病分类任务中取得了显著成果。然而,关于 ROP 眼底图像分类的半监督方法的研究仍然较少,而且这些方法没有考虑不同 ROP 分期之间的语义结构相关性。
在本文中,我们提出了一种用于 ROP 分期的半监督深度学习方法,能够利用少量标注数据和大量未标注数据来减轻医生的标注负担,并提高模型的分类性能。
具体来说,首先,受半监督学习中一致性正则化技术的启发,我们认为模型的预测不应受到数据微小扰动的影响。因此,我们提出了一种预测一致性损失,它迫使模型在不同扰动下对原始数据产生一致的预测输出,从而提高模型的泛化性能。
此外,考虑到 ROP 不同分期之间存在一定的相关性,例如,如图 1 所示,1 期 ROP 通常表现为视网膜后极部血管区和非血管区之间的白色分界线。2 期表现为分界线的进一步增宽和隆起,并伴有脊状突起。3 期时,脊状突起更加明显,并伴有新生血管形成。4 期和 5 期通常表现为进一步的视网膜脱离,需要进行眼部超声检查。ROP 不同分期之间存在一些语义结构相关性,这可能对模型的分类性能有帮助。因此,我们提出了一种语义结构一致性损失,它迫使语义结构关系在不同扰动下保持一致,从而从未标注数据中进一步提取丰富的语义信息,以增强分类性能。

图1:不同阶段的正常眼底图像和ROP眼底图像
(A) 眼底正常。
(B) ROP第1阶段。
(C) ROP阶段2。
(D) ROP阶段3。
(E) ROP阶段4。
(F) ROP阶段5。
2. 结果
2.1 构建用于 ROP 图像分类的半监督模型
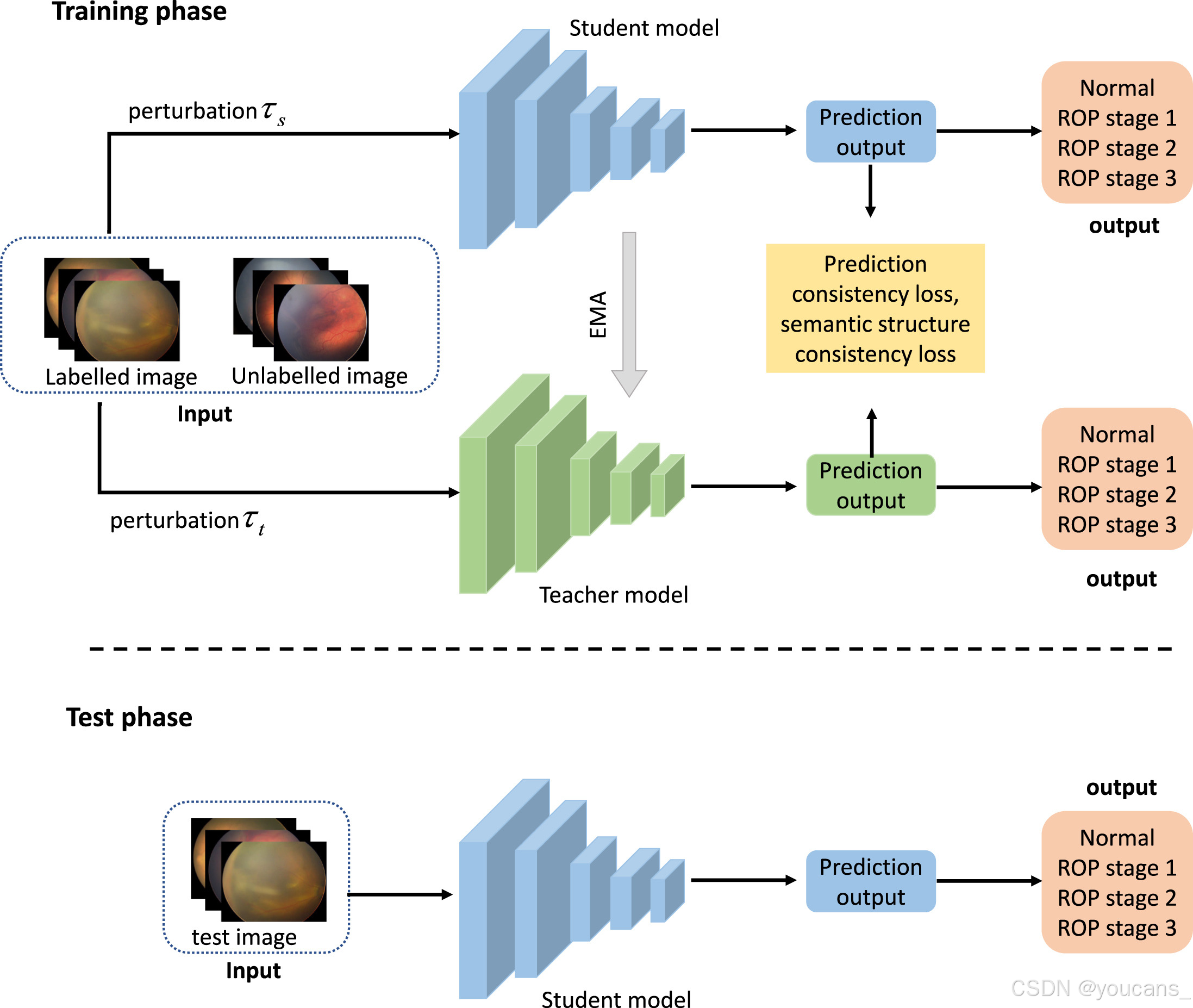
图 2 展示了我们提出的用于 ROP 眼底图像分类的半监督深度学习分类模型。
该模型结构与流行的半监督分类模型 Mean Teacher[15] 类似,包含一个学生模型和一个教师模型,两者结构相同。教师模型的参数通过学生模型参数的指数移动平均算法进行优化[15]。学生模型的参数通过在标注数据上的监督交叉熵损失和未标注数据上的一致性损失进行优化。
一致性损失根据学生模型和教师模型的输出计算得出,由预测一致性损失和语义结构一致性损失组成。预测一致性损失通过鼓励两个模型对经过不同数据增强的同一输入图像保持相同的预测输出,从而增强模型的泛化性能,并从未标注图像中挖掘信息。
此外,ROP 不同分期之间存在一定的语义相关性,这种语义相关性可能有助于提高模型的分类性能。我们使用语义结构一致性损失进一步鼓励模型在数据增强后对眼底图像保持相同的语义结构,从而从未标注图像中进一步挖掘有用信息,以帮助提高分类性能。
图2:所提出的半监督深度学习分类模型的框架说明
标记和未标记的眼底图像被输入到模型中。基于标记数据的监督损失和所有数据的预测一致性损失和语义结构一致性损失,对学生模型进行了优化。基于指数移动平均(EMA)算法对教师模型进行了优化。我们在测试阶段使用学生模型进行推理。
2.2 一致性损失的计算
预测一致性损失可以表示为:
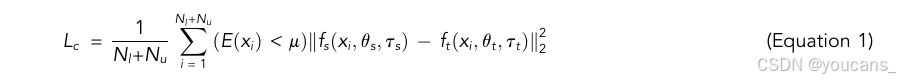
其中, τ s \tau_s τs 和 τ t \tau_t τt 表示对原始眼底图像施加的随机扰动, f s f_s fs 和 f t f_t ft 分别表示学生模型和教师模型, θ s \theta_s θs 和 θ t \theta_t θt 分别表示学生模型和教师模型的权重, N l N_l Nl 和 N u N_u Nu 分别表示标注图像和未标注图像的数量, E ( x i ) E(x_i) E(xi) 表示教师模型对样本 x i x_i xi 的预测熵, μ \mu μ 是阈值。
由于模型在训练初期比较不稳定,为了使模型能够逐步从有意义且可靠的目标中学习,我们仅考虑那些具有可靠性的样本。我们计算教师模型对每个样本预测的信息熵,并过滤掉高熵(不确定性高、噪声大)的样本。
对于语义结构一致性损失的计算,我们首先将一批眼底图像输入分类模型,并获取其深度特征表示 S ∈ R B ∗ D ∗ H ∗ W S \in R^{B*D*H*W} S∈RB∗D∗H∗W ,其中:B 表示批次大小,D 表示特征通道数,H 和 W 表示深度特征的空间维度。
然后,我们将深度特征变形为 Q ∈ R B ∗ H W D Q \in R^{B*HWD} Q∈RB∗HWD ,计算批次中样本之间的逐样本 Gram 矩阵[26] G = Q ⋅ Q T G=Q \cdot Q^T G=Q⋅QT ,其中 G i , j G_{i,j} Gi,j 表示样本 i i i 和样本 j j j 之间的相似性。直观上,它可以反映当前批次中样本之间的语义结构相关性。然后,我们对语义结构相关性矩阵 G G G 的每一行进行归一化: P = [ Q 1 ∣ ∣ Q 1 ∣ ∣ 2 , . . . , Q B ∣ ∣ Q B ∣ ∣ 2 ] T P=[\frac{Q_1}{||Q_1||_2},...,\frac{Q_B}{||Q_B||_2}]^T P=[∣∣Q1∣∣2Q1,...,∣∣QB∣∣2QB]T。
我们分别计算学生模型和教师模型的语义结构相关性矩阵,语义结构一致性损失可以表示为:
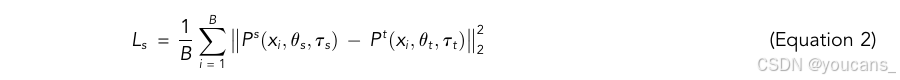
其中, P s P^s Ps 和 P t P^t Pt 分别表示学生模型和教师模型的语义结构相关性矩阵。
最后,我们可以得到所提出的半监督分类模型的总体训练损失:
其中, L c e L_{ce} Lce 表示在少量标注数据上计算的分类交叉熵损失,λ 是平衡系数,用于控制两种一致性损失的权重。
2.3 数据集描述
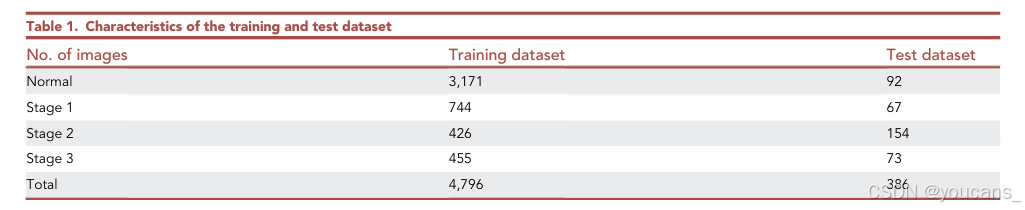
我们使用来自新华医院的 473 名婴儿的眼底图像作为训练集,性别比例为 1.2:1(男:女)。平均孕周为 29.86 ± 2.47 周,平均出生体重为 1379.95 ± 412.95 克。数据集中包含 4,796 张眼底图像,其中 3,171 张为正常图像,744 张为 1 期 ROP,426 张为 2 期 ROP,455 张为 3 期 ROP。
为了评估模型的性能,我们使用来自新华医院的 62 名婴儿的眼底图像作为测试集,性别比例为 1.4:1(男:女)。平均孕周为 29.29 ± 2.94 周,平均出生体重为 1381.77 ± 451.75 克。数据集中包含 386 张眼底图像,其中 92 张为正常图像,67 张为 1 期 ROP,154 张为 2 期 ROP,73 张为 3 期 ROP。
图像数据的收集和分析均获得新华医院伦理委员会的批准,并符合《赫尔辛基宣言》的原则。数据集的详细统计信息如表 1 所示。
2.4 实验设置与实现细节
我们将所有眼底图像调整为 224 × 224 大小作为分类模型的输入。
我们使用 ResNet50 作为网络主干,并使用 ImageNet 数据集的预训练权重进行初始化。学生模型和教师模型具有相同的结构。
我们使用受试者工作特征曲线下面积(AUC)、准确率(Accuracy)、灵敏度(Sensitivity)和特异度(Specificity)作为评估指标,以评估不同算法的性能。
我们使用 Python 和 PyTorch 进行实验,所有实验均在两块 NVIDIA 3090 Ti GPU 上运行。
我们使用随机梯度下降(SGD)优化器训练了 200 个 epoch,学习率设置为 1e-4,批量大小为 128,其中包含 32 个标注样本和 96 个未标注样本。
对于随机扰动,我们使用随机水平/垂直翻转、随机旋转和颜色抖动。
此外,我们在 ResNet50 网络的全局池化层之前添加了一个 dropout 层,并将 dropout 率设置为 0.2。阈值 μ 设置为 0.9,平衡系数 λ 设为 1。我们使用高斯预热函数 λ t = 1 ∗ e − 5 ( 1 − t / T ) 2 \lambda_t = 1*e^{-5(1-t/T)^2} λt=1∗e−5(1−t/T)2 来控制两种一致性损失,在前 T 个 epoch 中从 0 逐渐增加到 1,之后固定。这种方法避免了模型在训练初期被两种一致性损失主导,因为此时模型的预测不可靠,不利于一致性训练。
2.5 ROP 分期结果
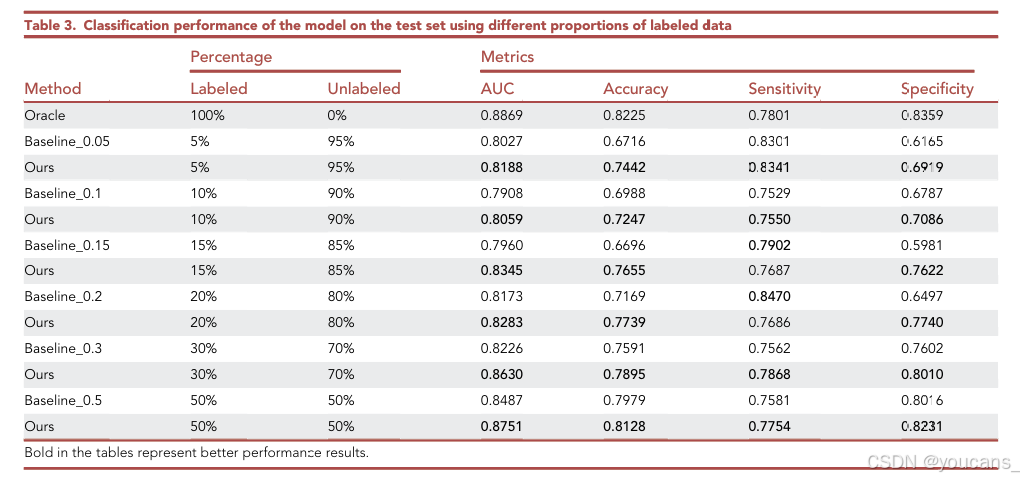
我们首先使用训练集中 30%(1,438 张)的标注眼底图像训练模型,其余 70%(3,358 张)眼底图像作为未标注数据。
我们还提供了仅使用 30%(1,438 张)标注眼底图像(不使用 70% 未标注图像)训练模型的结果作为下界(baseline_0.3)进行比较。
从表 2 可以看出,当仅使用 30% 的训练数据进行模型训练时,模型的分类性能较差,平均 AUC 为 0.8226,平均准确率为 0.7590,平均灵敏度为 0.7562,平均特异度为 0.7602。
我们的方法通过强制模型不仅在单个样本的预测上保持一致,还在样本之间的语义结构上保持一致,从而实现了更好的分类性能,平均 AUC 提高了 4.04%,平均准确率提高了 3.05%,平均灵敏度提高了 3.06%,平均特异度提高了 4.08%。
从图 3 的受试者工作特征曲线和图 4 的混淆矩阵可以看出,我们的方法在所有类别上均取得了性能提升,进一步验证了我们方法的优越性。
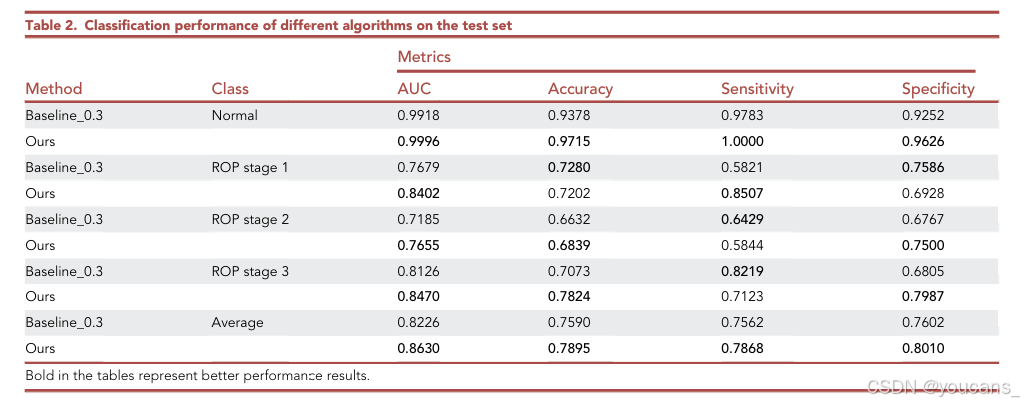
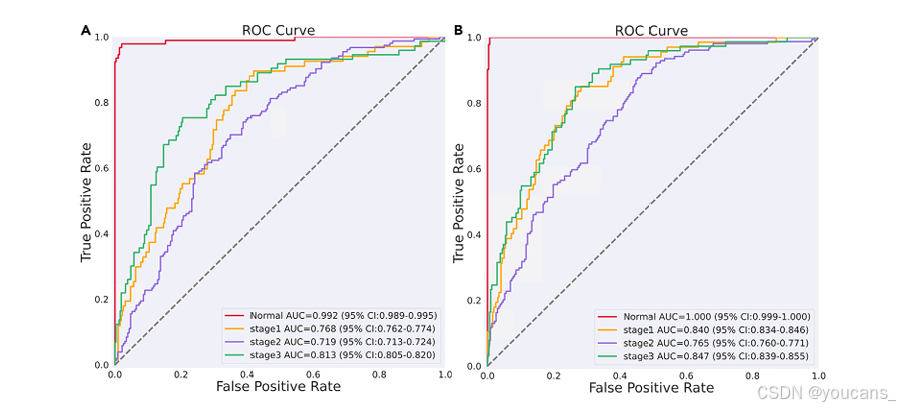
图3。不同方法的受试者工作特征曲线图
(A) 基线_0.3,(B)我们的。
图 4。不同方法的混淆矩阵。
(A) 基线_0.3,(B)我们的。
2.6 不同比例标注数据的效果
为了进一步研究我们提出的半监督深度学习分类模型在不同比例标注数据下的分类性能,我们通过改变标注样本的数量重新运行实验。
我们还报告了全监督情况下的模型性能,即使用 100%(4,796 张)标注眼底图像作为训练集,作为比较的上界(Oracle)。Baseline_0.05、Baseline_0.1、Baseline_0.15、Baseline_0.2、Baseline_0.3 和 Baseline_0.5 分别表示仅使用 5%、10%、15%、20%、30% 和 50% 的标注数据,且这些基线模型在训练过程中均未使用未标注数据。
如表 3 所示,随着标注训练数据样本的增加,模型的性能逐渐提升。此外,可以发现,当我们使用 50% 的标注数据时,所提出算法的性能已经接近全监督(使用 100% 标注数据)的性能。
这表明,所提出的方法能够充分利用未标注数据来提高模型的分类性能,并显著减轻医生的标注负担。
2.7 语义结构相关性矩阵的演化可视化
为了进一步理解所提出的语义结构一致性损失在半监督深度学习分类方法中的行为,我们可视化了不同训练 epoch 下的语义结构相关性矩阵。
如图 5 所示,在训练初期,样本之间的相关性未能很好地呈现,因为模型尚未收敛,且学生模型和教师模型在不同扰动下的语义结构相关性矩阵存在较大差异。随着训练的进行,样本之间的语义相关性变得更加清晰,且由于语义结构一致性损失的约束,学生模型和教师模型的语义结构相关性矩阵之间的差异逐渐减小,从而使模型能够学习到更鲁棒和更具判别性的特征表示,这解释了所提出方法性能提升的原因。
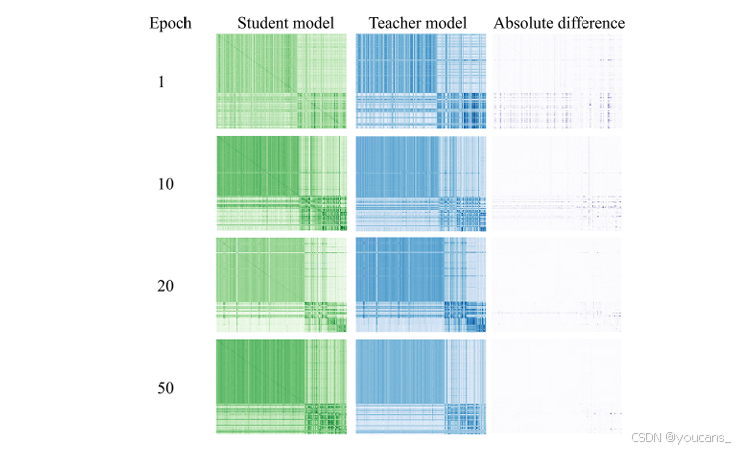
图5。语义结构相关矩阵的演化。
2.8 热图可视化
为了更直观地展示我们的方法使用图像的哪些区域进行预测,我们使用类激活映射(Class Activation Mapping, CAM)技术对热图进行可视化。
如图 6 所示,可以看出我们的方法主要利用 ROP 图像中脊区域的特征来确定图像属于哪一阶段的 ROP,这与医生在判断 ROP 图像所属阶段时的临床经验一致。
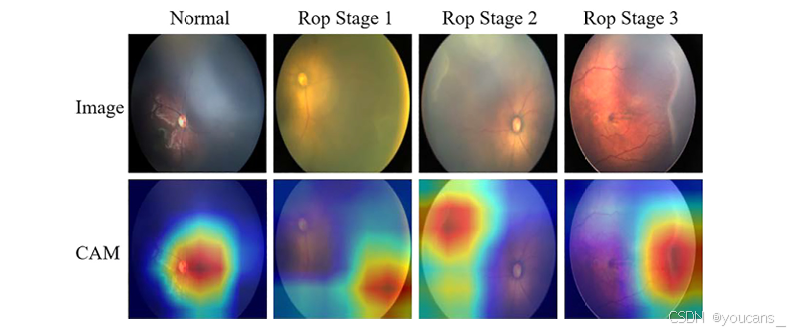
图6。CAM热图可视化。
3. 讨论
早产儿视网膜病变(ROP)是一种影响早产新生儿的视网膜疾病,在全球范围内可导致失明。
自动化的ROP筛查和诊断有助于医生及时、适当地制定治疗方案。为了实现ROP的自动检测,许多深度学习算法已被提出,并取得了显著进展。例如,Tong等人[27]利用深度学习技术自动评估ROP严重程度并检测附加病变的存在,其ROP严重程度分类的准确率为0.903。Mulay等人[28]使用基于深度卷积神经网络的Mask区域卷积神经网络(R-CNN)[29]模型检测ROP图像中的重要病变标志“脊线”,从而有助于早期ROP的诊断和筛查,其模型的检测准确率达到了0.88。
然而,在实际应用中,获取大量标注数据进行自动ROP分期往往非常困难,这限制了深度学习模型的应用。这主要是由于以下原因:首先,ROP的病变特征在初期并不明显,且ROP图像通常对比度较低,导致医生标注需要耗费大量时间和精力;其次,相比其他常见疾病,ROP患者数量较少,因此难以收集大量ROP图像数据。
本文提出了一种新的半监督深度学习框架,旨在利用少量标注数据和大量未标注数据提高模型对ROP分期的分类性能。我们的方法基于一致性正则化策略,该策略鼓励模型在不同扰动后的数据预测中保持一致,以充分利用大量未标注数据。
此外,我们还考虑到不同ROP分期之间的疾病演变关系可能有助于分类性能,因此进一步提出了语义结构相关性一致性损失,以鼓励跨样本的语义结构一致性。我们的方法能够显著减轻医生的标注负担。
从表3可以看出,我们的方法仅使用50%的数据就达到了接近全监督性能的效果,验证了所提方法的有效性。此外,从混淆矩阵和受试者工作特征曲线可以看出,我们的方法在所有类别上表现更优。热图还表明,我们的方法确实基于ROP相关病变特征“脊线”的形状和大小进行判断。该方法不仅可用于ROP分期,还可用于其他计算机辅助医学图像分析任务,因此具有重要的临床应用价值。
我们的工作存在一些局限性。受数据来源的限制,我们的模型尚未在来自广泛医疗机构的 ROP 眼底图像数据集上进行性能测试。此外,我们的数据集质量控制由经验丰富的专业人员完成,但在大规模筛查场景中,可能存在一些质量较差的 ROP 图像,这可能会影响模型的性能。
4. 结论
在本文中,我们提出了一种用于 ROP 分期的半监督深度学习分类模型。我们提出了两种一致性损失,以高效利用未标注数据,从而显著减轻医生的标注负担,仅需标注部分数据即可达到接近全监督的性能。
我们通过实验验证了所提出算法的有效性。
未来的工作需要在更大的医学临床数据集上验证所提出算法的性能。
5. 方法
本文的在线版本提供了详细的方法,包括以下内容:
5.1 方法细节
患者队列
训练数据集包含来自新华医院的 473 名婴儿的眼底图像,性别比例为 1.2:1(男:女)。平均孕周为(29.86 ± 2.47)周,平均出生体重为(1379.95 ± 412.95)克。数据集中包含 4,796 张眼底图像,其中 3,171 张为正常图像,744 张为 1 期 ROP,426 张为 2 期 ROP,455 张为 3 期 ROP。为了评估模型的性能,我们使用来自新华医院的 62 名婴儿的眼底图像作为测试集,性别比例为 1.4:1(男:女),平均孕周为(29.29 ± 2.94)周,平均出生体重为(1381.77 ± 451.75)克。测试集包含 386 张眼底图像,其中 92 张为正常图像,67 张为 1 期 ROP,154 张为 2 期 ROP,73 张为 3 期 ROP。
半监督深度学习分类模型
在医学影像领域,标注医学图像是一项耗时且费力的任务。医学病症、结构和异常的复杂性需要细致的标注,通常需要专业人员的丰富经验。这一标注过程的繁琐性带来了巨大挑战,因为它需要投入大量的时间和人力资源。此外,医学图像分析的深度学习模型的开发和训练严重依赖于大量精心标注的数据。在追求构建鲁棒且准确的模型过程中,对标注数据的需求是巨大的。标注医学图像的稀缺性,加上医学现象的复杂性,进一步加剧了获取有效模型训练所需标注数据的挑战。
为了减少标注需求并提高 ROP 分类性能,我们提出了一种基于半监督学习的分类框架。
我们提出的半监督深度学习分类模型与著名的半监督分类模型 Mean Teacher 类似,包含一个学生模型和一个教师模型,两者结构相同。
教师模型的参数通过学生模型参数的指数移动平均算法进行优化。
为了优化学生模型的参数,我们在标注数据上使用监督交叉熵损失,在未标注数据上使用一致性损失。
一致性损失根据学生模型和教师模型的输出计算,包括预测一致性损失和语义结构一致性损失。预测一致性损失通过确保两个模型对经过不同数据增强的同一输入图像产生相同的预测,从而增强模型的泛化能力,并从未标注图像中提取信息。
我们采用多种技术引入随机扰动,包括随机水平/垂直翻转、随机旋转和颜色抖动。
此外,在 ResNet50 网络的全局池化层之前添加了一个 dropout 率为 0.2 的 dropout 层。
此外,考虑到 ROP 不同分期之间的语义相关性,我们利用语义结构一致性损失来鼓励模型在数据增强后对眼底图像保持一致的语义结构。这进一步从未标注图像中提取有价值的信息,从而提高分类性能。
我们计算样本之间的逐样本 Gram 矩阵,以反映不同样本之间的语义结构关系。
为了标准化输入,所有眼底图像均调整为 224 × 224 大小作为分类模型的输入。
我们使用 ResNet50 作为网络主干,并使用 ImageNet 数据集的预训练权重进行初始化。
学生模型和教师模型共享相同的 ResNet50 结构。
实验使用 Python(v3.8)、PyTorch(v1.11.0)和 scikit-learn(v0.23.2)进行,所有实验均在两块 Nvidia 3090 Ti GPU 上运行。
量化与统计分析
我们在新华医院的测试集数据上评估了所提出的半监督分类框架的性能。我们使用 AUC(曲线下面积)、准确率(Accuracy)、灵敏度(Sensitivity)和特异度(Specificity)作为评估指标,以评估不同算法的性能。为了进行热图可视化,我们使用类激活映射(CAM)技术,这有助于我们理解模型基于图像的哪些特征进行预测。
5.2 相关资源
主要联系人
如需更多信息和资源请求,请联系首席联系人黄秋静(电子邮件:hqj1010@126.com).
材料可用性
这项研究没有产生新的独特试剂。
数据和代码可用性
- 本文中报告的所有数据将由首席联系人根据要求共享。
- 本文不报告原始代码。
- 如有需要,可向主要联系人索取重新分析本文报告的数据所需的任何其他信息。
伦理声明
作者对工作的各个方面负责,确保与工作任何部分的准确性或完整性相关的问题得到适当的调查和解决。图像数据是在NCH的批准下收集和分析的,并符合《赫尔辛基宣言》的原则。
6. 参考文献
-
K. Gupta, J.P. Campbell, S. Taylor, et al. A quantitative severity scale for retinopathy of prematurity using deep learning to monitor disease regression after treatment, JAMA Ophthalmol., 137 (2019), pp. 1029-1036
-
S. Taylor, J.M. Brown, K. Gupta, et al. Monitoring disease progression with a quantitative severity scale for retinopathy of prematurity using deep learning, JAMA Ophthalmol., 137 (2019), pp. 1022-1028
-
T.K. Redd, J.P. Campbell, J.M. Brown, et al. Evaluation of a deep learning image assessment system for detecting severe retinopathy of prematurity, Br. J. Ophthalmol., 103 (2019), pp. 580-584
-
D.S. Ting, W.-C. Wu, C. Toth, Deep Learning for Retinopathy of Prematurity Screening, (2019)
-
T.H. Chan, K. Jia, S. Gao, et al. PCANet: A Simple Deep Learning Baseline for Image Classification? IEEE Trans. Image Process., 24 (2015), pp. 5017-5032
-
X. Yang, Y. Ye, X. Li, et al. Hyperspectral image classification with deep learning models
IEEE Trans. Geosci. Remote Sens., 56 (2018), pp. 5408-5423 -
T. Young, D. Hazarika, S. Poria, et al. Recent trends in deep learning based natural language processing, IEEE Comput. Intell. Mag., 13 (2018), pp. 55-75
-
S. Wu, K. Roberts, S. Datta et al. Deep learning in clinical natural language processing: a methodical review, J. Am. Med. Inform. Assoc., 27 (2020), pp. 457-470
-
Z. Zhang, J. Geiger, J. Pohjalainen, et al. Deep learning for environmentally robust speech recognition: An overview of recent developments, ACM Trans. Intell. Syst. Technol., 9 (2018), pp. 1-28
-
J. Huang, B. Kingsbury, Audio-visual deep learning for noise robust speech recognition, 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, IEEE (2013), pp. 7596-7599
-
Y. Peng, W. Zhu, Z. Chen, et al. Automatic staging for retinopathy of prematurity with deep feature fusion and ordinal classification strategy IEEE Trans. Med. Imaging, 40 (2021), pp. 1750-1762
-
J. Wang, R. Ju, Y. Chen, et al. Automated retinopathy of prematurity screening using deep neural networks, EBioMedicine, 35 (2018), pp. 361-368
-
B. Lei, X. Zeng, S. Huang, et al. Automated detection of retinopathy of prematurity by deep attention network, Multimed. Tools Appl., 80 (2021), pp. 36341-36360
-
S. Laine, T. Aila, Temporal ensembling for semi-supervised learning, Preprint at arXiv (2016), 10.48550/arXiv.1610.02242
-
A. Tarvainen, H. Valpola, Mean teachers are better role models: Weight- averaged consistency targets improve semi-supervised deep learning results, Adv. Neural Inf. Process. Syst., 30 (2017)
-
V. Cheplygina, M. de Bruijne, J.P.W. Pluim, Not-so-supervised: a survey of semi-supervised, multi-instance, and transfer learning in medical image analysis, Med. Image Anal., 54 (2019), pp. 280-296
-
D. Wang, Y. Zhang, K. Zhang, et al. Focalmix: Semi-supervised learning for 3d medical image detection, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2020), pp. 3951-3960
-
S. Chen, G. Bortsova, A. Garc’ıa-Uceda Jua’rez, et al. Multi-task attention-based semi-supervised learning for medical image segmentation, International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer (2019), pp. 457-465
-
H. Shang, Z. Sun, W. Yang, et al. Leveraging other datasets for medical imaging classification: evaluation of transfer, multi-task and semi-supervised learning, International conference on medical image computing and computer-assisted intervention, Springer (2019), pp. 431-439
-
G. Bortsova, F. Dubost, L. Hogeweg, et al. Semi-supervised medical image segmentation via learning consistency under transformations, International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer (2019), pp. 810-818
-
W. Zhang, L. Zhu, J. Hallinan, et al. Boostmis: Boosting medical image semi-supervised learning with adaptive pseudo labeling and informative active annotation, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022), pp. 20666-20676
-
R. Zhao, X. Chen, X. Liu, et al. Direct cup-to-disc ratio estimation for glaucoma screening via semi-supervised learning, IEEE J. Biomed. Health Inform., 24 (2020), pp. 1104-1113
-
K.M. Adal, D. Sidibé, S. Ali, et al. Automated detection of microaneurysms using scale- adapted blob analysis and semi-supervised learning, Comput. Methods Programs Biomed., 114 (2014), pp. 1-10
-
S. Liu, J. Hong, X. Lu, et al. Joint optic disc and cup segmentation using semi-supervised conditional gans, Comput. Biol. Med., 115 (2019), Article 103485
-
Q. Liu, L. Yu, L. Luo, et al. Semi-supervised medical image classification with relation-driven self-ensembling model, IEEE Trans. Med. Imaging, 39 (2020), pp. 3429-3440
-
L.A. Gatys, A.S. Ecker, M. Bethge, A neural algorithm of artistic style, Preprint at arXiv (2015), 10.48550/arXiv.1508.06576
-
Y. Tong, W. Lu, Q.-q. Deng, et al. Automated identification of retinopathy of prematurity by image-based deep learning, Eye Vis., 7 (2020), p. 40
-
S. Mulay, K. Ram, M. Sivaprakasam, et al. Early detection of retinopathy of prematurity stage using deep learning approach, Medical Imaging 2019: Computer-Aided Diagnosis, 10950, SPIE (2019), pp. 758-764
-
K. He, G. Gkioxari, P. Doll’ar, et al. Mask r-cnn, Proceedings of the IEEE international conference on computer vision (2017), pp. 2961-2969
-
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, Proceedings of the IEEE conference on computer vision and pattern recognition (2016), pp. 770-778
版权说明:
本文由 youcans@xidian 对论文 Development and validation of a semi-supervised deep learning model for automatic retinopathy of prematurity staging 进行摘编和翻译。该论文版权属于原文期刊和作者,本译文只供研究学习使用。
youcans@xidian 作品,转载必须标注原文链接:
【医学影像 AI】ROP 自动分期的半监督深度学习模型的开发与验证(https://youcans.blog.csdn.net/article/details/146348551)
Crated:2025-03

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)