知识图谱:动态信息处理的新突破
知识图谱在信息结构化中扮演着关键角色,但传统方法在处理动态、大规模信息时面临效率低下、适应性不足等挑战。为解决这些问题,研究者提出了创新的解决方案,如iText2KG系统,通过模块化设计和大型语言模型(LLMs)的应用,显著提升了知识图谱的构建效率和动态更新能力。基于命题的检索方法则更好地保留了上下文信息,提高了知识图谱的灵活性和信息密度,使其在复杂查询和推理任务中表现更优。持续学习成为未来知识图
标题:知识图谱:动态信息处理的新突破
文章信息摘要:
知识图谱在信息结构化中扮演着关键角色,但传统方法在处理动态、大规模信息时面临效率低下、适应性不足等挑战。为解决这些问题,研究者提出了创新的解决方案,如iText2KG系统,通过模块化设计和大型语言模型(LLMs)的应用,显著提升了知识图谱的构建效率和动态更新能力。基于命题的检索方法则更好地保留了上下文信息,提高了知识图谱的灵活性和信息密度,使其在复杂查询和推理任务中表现更优。持续学习成为未来知识图谱构建的重要趋势,系统需要具备动态更新能力,能够适应新信息并有效解决信息冲突,以确保知识图谱的时效性和准确性。这些创新方法在科学研究、商业智能、教育和医疗等多个领域具有广泛的应用前景,为不同行业提供了定制化的知识管理解决方案。
==================================================
详细分析:
核心观点:知识图谱在信息结构化中扮演着关键角色,但传统方法在处理动态、大规模信息时面临诸多挑战,如效率低下和适应性不足等问题。
详细分析:
知识图谱(Knowledge Graphs, KGs)在信息结构化中确实扮演着至关重要的角色,尤其是在当今信息爆炸的时代。它们通过将实体及其关系以结构化的方式表示,使得复杂的信息能够被机器理解和处理,从而支持高级查询、推理和知识发现。然而,传统的方法在处理动态、大规模信息时,确实面临着一系列挑战,这些挑战主要体现在以下几个方面:
1. 效率低下
传统知识图谱的构建过程通常需要大量的人工干预和复杂的规则设置。例如,实体和关系的提取往往依赖于预定义的规则或模板,这不仅耗时,而且在面对大规模数据时,效率会显著下降。此外,传统方法在处理大规模数据时,计算资源的消耗也非常大,导致构建和维护知识图谱的成本高昂。
2. 适应性不足
传统知识图谱通常依赖于预定义的架构或本体(ontologies),这些架构虽然提供了结构化和一致性,但也带来了系统僵化的问题。随着新领域和新类型信息的不断涌现,传统方法难以快速适应这些变化。例如,当面对社交媒体上的非正式文本或新兴科学领域的研究论文时,传统知识图谱的架构可能无法有效捕捉和处理这些信息。
3. 动态信息处理能力有限
在现实世界中,信息是不断变化的。新的数据不断产生,旧的数据可能被更新或失效。传统知识图谱通常是静态的,更新过程复杂且耗时。例如,当新的科学发现或市场数据出现时,传统方法需要重新处理整个数据集,这不仅效率低下,还可能导致知识图谱的过时。
4. 语义重复和实体消歧问题
在处理多源数据时,传统方法往往难以有效处理语义重复和实体消歧问题。同一个实体可能在不同的数据源中以不同的形式出现,例如“Apple Inc.”、“Apple”和“AAPL”可能都指向同一家公司。传统方法在处理这些情况时,容易导致知识图谱中的冗余和不一致性。
5. 上下文信息利用不足
传统方法在提取信息时,往往无法充分利用文本中的上下文信息。例如,句子级别的信息提取可能会丢失关键的上下文信息,导致知识图谱中的关系不够准确或完整。这种上下文信息的缺失,限制了知识图谱在复杂推理和知识发现中的应用。
6. 领域适应性差
许多传统知识图谱构建技术是针对特定领域设计的,缺乏跨领域的适应性。例如,一个为医学领域设计的知识图谱可能无法有效处理金融或科技领域的数据。这种领域依赖性限制了知识图谱的广泛应用,尤其是在需要跨领域知识融合的场景中。
7. 更新和维护困难
传统知识图谱的更新和维护通常需要大量的人工干预,尤其是在面对大规模、动态变化的数据时。例如,当新的信息需要添加到知识图谱中时,传统方法可能需要进行复杂的冲突检测和解决,这不仅耗时,还容易引入新的错误。
8. 计算资源需求高
随着知识图谱规模的扩大,传统方法所需的计算资源也呈指数级增长。例如,实体消歧、关系提取和图结构更新等操作在大规模知识图谱中变得非常复杂,导致系统性能下降,甚至无法处理。
解决方案与未来方向
为了应对这些挑战,研究者们提出了许多创新的解决方案。例如,iText2KG系统通过模块化的设计,利用大语言模型(LLMs)来处理非结构化数据,并采用增量式的方法来构建和更新知识图谱。这种方法不仅提高了效率,还增强了系统的适应性和动态更新能力。
此外,基于命题的检索(Proposition-Based Retrieval)也被提出作为一种更灵活、上下文保留的信息提取方式。通过将文本分解为自包含的命题,这种方法能够更好地捕捉信息的上下文,从而提高知识图谱的准确性和完整性。
总的来说,虽然传统知识图谱在信息结构化中发挥了重要作用,但在面对动态、大规模信息时,其局限性日益显现。未来的研究方向将集中在提高效率、增强适应性、改进动态更新能力以及更好地利用上下文信息等方面,以构建更加灵活、智能和全面的知识图谱系统。
==================================================
核心观点:iText2KG系统通过模块化设计和大型语言模型(LLMs)的应用,提供了一种更灵活、可扩展的知识图谱构建方法,能够高效处理大规模数据,并通过增量式处理、实体消歧和关系提取等技术提升构建效率。
详细分析:
iText2KG系统确实代表了知识图谱构建领域的一次重要突破,其模块化设计和大型语言模型(LLMs)的应用为处理大规模数据提供了全新的解决方案。让我们深入探讨这一系统的核心优势和技术细节。
首先,模块化设计是iText2KG系统的基石。它将知识图谱构建过程分解为四个关键模块:文档蒸馏器、增量实体提取器、增量关系提取器和图谱集成器。这种设计不仅提高了系统的灵活性,还使得每个模块可以独立优化和更新,从而适应不同领域和数据类型的需求。
文档蒸馏器作为系统的第一道关卡,利用LLMs将原始文档转化为语义块。这一步骤不仅提高了信息的信噪比,还为后续的实体和关系提取提供了清晰的指导。例如,在处理科学论文时,文档蒸馏器能够将内容结构化,提取出标题、作者、摘要等关键信息,为后续处理奠定基础。
增量实体提取器则负责从语义块中识别和提取实体。其增量处理方式使得系统能够高效处理大规模数据,同时通过实体消歧技术确保语义一致性。例如,在处理多个关于科技公司的文档时,该模块能够识别“Apple Inc.”、“Apple”和“AAPL”为同一实体,确保知识图谱中的一致性。
增量关系提取器进一步挖掘实体之间的关系。通过结合局部和全局上下文,该模块能够捕捉复杂的关联,如“is_CEO_of”或“competes_with”等关系。这种精细化的关系提取不仅丰富了知识图谱的内容,还提高了其查询和推理能力。
最后,图谱集成器将提取的实体和关系整合成一个连贯的知识图谱。这一模块不仅确保了图谱的结构一致性,还支持可视化和复杂查询,为各种下游应用提供了坚实的基础。
LLMs的应用是iText2KG系统的另一大亮点。这些模型能够理解和处理自然语言,使得系统能够适应各种领域和类型的信息,而无需大量的领域特定训练或规则设置。例如,LLMs能够识别文本中的隐含关系和上下文信息,从而更准确地提取实体和关系。
增量式处理是iText2KG系统的另一大优势。通过逐步处理数据,系统能够高效地更新知识图谱,而无需重新构建整个图谱。这种处理方式不仅提高了系统的响应速度,还降低了计算资源的消耗。
实体消歧和关系提取技术的结合进一步提升了系统的构建效率。通过识别和解决实体和关系中的歧义,系统能够生成更准确和一致的知识图谱。例如,在处理多个来源的数据时,系统能够识别并合并相同实体的不同表述,避免冗余和不一致。
总的来说,iText2KG系统通过模块化设计和LLMs的应用,提供了一种更灵活、可扩展的知识图谱构建方法。其增量式处理、实体消歧和关系提取技术不仅提高了构建效率,还为处理大规模数据提供了有效的解决方案。这种创新方法有望在科学研究、商业智能、教育和医疗等领域带来深远的影响。
==================================================
核心观点:该系统具有跨领域的广泛适应性,能够在科学研究、商业智能、教育和医疗等多个领域产生深远影响,为不同行业提供定制化的知识管理解决方案。
详细分析:
The Universal Continuous Knowledge Graph Builder’s cross-domain adaptability is truly remarkable, offering transformative potential across various industries. Let’s explore how this system could revolutionize different fields:
Scientific Research:
Imagine a world where researchers can instantly access interconnected knowledge across disciplines. This system could:
- Automatically link related studies, even across different scientific fields
- Identify potential research gaps by analyzing patterns in the knowledge graph
- Suggest novel interdisciplinary collaborations based on unexpected connections
- Track the evolution of scientific concepts over time
Business Intelligence:
In the fast-paced world of commerce, this system could provide:
- Real-time market trend analysis by continuously updating business knowledge
- Competitor intelligence by tracking and connecting various data points
- Predictive analytics for consumer behavior and emerging markets
- Automated generation of comprehensive industry reports
Education:
The potential for personalized learning is immense:
- Create adaptive learning paths based on individual student progress
- Visualize complex concepts through interactive knowledge graphs
- Identify knowledge gaps in curriculum design
- Facilitate cross-disciplinary learning by showing connections between subjects
Healthcare:
In the medical field, this could lead to:
- Faster diagnosis by connecting symptoms, conditions, and treatments
- Identification of potential drug interactions across vast medical literature
- Tracking of disease patterns and emerging health threats
- Personalized treatment plans based on comprehensive patient data
Additional Applications:
- Legal Sector: Tracking case law precedents and legal interpretations
- Journalism: Fact-checking and source verification in real-time
- Government: Policy analysis and impact assessment across sectors
- Technology: Tracking innovation trends and patent landscapes
The system’s adaptability stems from its ability to:
- Process diverse data types (text, numbers, images, etc.)
- Understand context across different domains
- Continuously learn and update its knowledge base
- Customize output based on specific industry needs
This flexibility allows for truly tailored solutions in each field, while maintaining the ability to draw connections across domains. The potential for cross-pollination of ideas and innovations is particularly exciting, as it could lead to breakthroughs that might otherwise remain undiscovered.
However, the implementation of such a system also raises important considerations:
- Data privacy and security, especially in sensitive fields like healthcare
- Ethical use of information across different industries
- Maintaining accuracy and reliability in rapidly changing fields
- Balancing domain-specific needs with universal applicability
As we move forward, the development of this technology will likely lead to new, unforeseen applications, further expanding its impact across various sectors of society. The key will be in developing robust frameworks that can harness this power while addressing the unique challenges of each field.
==================================================
核心观点:基于命题的检索方法能够更好地保留上下文信息,显著提高知识图谱的灵活性和信息密度,使其在复杂查询和推理任务中表现更优。
详细分析:
基于命题的检索方法(Proposition-Based Retrieval)在知识图谱构建和信息检索中展现出了显著的优势,尤其是在上下文保留、灵活性和信息密度方面。这种方法通过将文本分解为独立的命题(propositions),每个命题都包含一个完整的事实或信息单元,从而在复杂查询和推理任务中表现更优。以下是对这一方法的深入探讨:
1. 上下文保留
传统的检索方法(如基于段落或句子的检索)往往在提取信息时丢失了重要的上下文。例如,一个句子可能包含多个事实,但如果没有足够的上下文,这些事实可能会被误解或无法准确关联。基于命题的检索方法通过将每个命题设计为自包含的单元,确保所有必要的上下文信息都被保留。例如,句子“The Eiffel Tower, built in 1889, is 324 meters tall and located in Paris, France.”可以被分解为三个独立的命题,每个命题都包含了完整的事实和上下文。这种自包含性使得在知识图谱中存储和检索信息时,上下文信息不会丢失,从而提高了信息的准确性和可用性。
2. 灵活性
基于命题的检索方法在信息提取和表示上具有更高的灵活性。与固定长度的检索单元(如段落或句子)不同,命题可以根据需要调整其长度和复杂性。这种灵活性使得系统能够更自然地表示知识,尤其是在处理复杂或多样化的信息时。例如,一个命题可以是一个简单的事实(如“The Eiffel Tower is located in Paris”),也可以是一个更复杂的陈述(如“The Eiffel Tower, built in 1889, is a major tourist attraction in France”)。这种灵活性使得知识图谱能够更好地适应不同领域和类型的信息需求。
3. 信息密度
由于命题专注于提取独立的事实或信息单元,它们通常具有更高的信息密度。相比之下,段落或句子可能包含冗余或无关的信息,降低了检索效率。基于命题的检索方法通过提取最相关的信息单元,减少了冗余,提高了知识图谱的信息密度。例如,在处理科学文献时,命题可以提取出关键的研究发现、方法和结论,而忽略掉无关的背景信息。这种高信息密度使得知识图谱在存储和检索大规模信息时更加高效。
4. 复杂查询和推理
基于命题的检索方法在复杂查询和推理任务中表现尤为出色。由于每个命题都是一个独立的信息单元,知识图谱可以更轻松地进行复杂的查询和推理。例如,在回答“Which cities have landmarks built in the 19th century?”这样的查询时,系统可以快速检索出所有与“19th century”和“landmarks”相关的命题,而不需要遍历整个段落或句子。此外,命题的结构与知识图谱中的三元组(subject-predicate-object)非常相似,这使得从文本到知识图谱的转换更加直接和高效。
5. 与知识图谱的兼容性
基于命题的检索方法与知识图谱的结构高度兼容。知识图谱通常以三元组的形式表示信息,而命题本质上也是三元组的形式(如“The Eiffel Tower - is located in - Paris”)。这种兼容性使得从文本中提取的命题可以更容易地集成到知识图谱中,减少了信息转换的复杂性。例如,iText2KG系统中的“Document Distiller”模块可以通过提取命题来生成更细粒度的信息单元,从而为后续的实体和关系提取提供更准确的输入。
6. 实际应用中的优势
在实际应用中,基于命题的检索方法已经在多个领域展示了其优势。例如,在科学研究中,命题可以帮助研究人员快速提取和整合跨学科的研究发现;在商业智能中,命题可以提供更精确的市场洞察;在医疗领域,命题可以帮助医生快速检索和关联症状、诊断和治疗方法。这些应用场景都得益于命题方法在上下文保留、灵活性和信息密度方面的优势。
总结
基于命题的检索方法通过将文本分解为自包含的信息单元,显著提高了知识图谱的上下文保留能力、灵活性和信息密度。这种方法在复杂查询和推理任务中表现尤为出色,能够更高效地处理大规模、多样化的信息。随着知识图谱技术的不断发展,基于命题的检索方法有望成为构建更智能、更灵活的知识管理系统的重要工具。
==================================================
核心观点:持续学习是未来知识图谱构建的重要趋势,系统需要具备动态更新能力,能够适应新信息并有效解决信息冲突,以确保知识图谱的时效性和准确性。
详细分析:
持续学习确实是未来知识图谱构建的重要趋势,尤其是在信息爆炸的时代,知识图谱需要具备动态更新能力,以保持其时效性和准确性。以下是对这一趋势的深入探讨:
1. 动态更新能力
知识图谱不再是一个静态的结构,而是一个不断进化的系统。随着新信息的不断涌现,系统需要能够实时或近实时地更新知识图谱。这种动态更新能力包括:
- 增量更新:系统应能够在不重建整个图谱的情况下,逐步添加新信息。例如,当新的科学论文发布时,系统可以自动提取其中的关键信息并整合到现有图谱中。
- 信息删除与修正:过时或错误的信息需要被及时识别和修正。例如,如果某个事实被新的研究推翻,系统应能够自动更新相关节点和关系。
2. 适应新信息
知识图谱需要具备高度的适应性,能够处理来自不同领域和来源的多样化信息。这种适应性体现在:
- 多源数据整合:系统应能够从文本、数据库、API、传感器等多种来源获取信息,并将其整合到一个统一的知识图谱中。
- 跨领域知识融合:知识图谱应能够跨越学科界限,将不同领域的知识连接起来,从而促进跨学科的创新和发现。
3. 信息冲突解决
在动态更新的过程中,信息冲突是不可避免的。系统需要具备有效的冲突解决机制,以确保知识图谱的一致性和准确性。这包括:
- 冲突检测:系统应能够自动识别新信息与现有知识之间的冲突。例如,当两个不同的来源对同一事实给出不同的描述时,系统应能够检测到这种不一致。
- 冲突解决策略:系统可以采用多种策略来解决冲突,如基于来源可信度的加权、时间戳的优先级、或通过人工审核进行最终裁决。
4. 时效性与准确性
持续学习的最终目标是确保知识图谱的时效性和准确性。这需要系统具备以下能力:
- 实时更新:系统应能够实时或近实时地更新知识图谱,以反映最新的信息。
- 质量保证:系统应具备自动化的质量检查机制,确保新信息的准确性和可靠性。例如,通过验证信息的来源、上下文一致性等。
5. 应用场景
持续学习的知识图谱在多个领域具有广泛的应用前景:
- 科学研究:帮助研究人员快速获取最新的研究成果,促进跨学科的合作与创新。
- 商业智能:为企业提供实时的市场洞察,支持决策制定和战略规划。
- 教育:根据学生的学习进度和兴趣,动态调整教学内容,提供个性化的学习体验。
- 医疗:整合最新的医学研究成果,辅助医生进行诊断和治疗决策。
6. 技术挑战
尽管持续学习的知识图谱具有巨大的潜力,但其实现也面临诸多技术挑战:
- 计算资源:处理大规模、动态更新的知识图谱需要强大的计算资源。
- 算法优化:需要开发高效的算法来处理增量更新、冲突解决和质量保证。
- 隐私与安全:在整合多源数据时,需要确保数据的隐私和安全,防止信息泄露和滥用。
总之,持续学习是未来知识图谱构建的核心趋势,它将使知识图谱成为一个动态、自适应、不断进化的系统,能够更好地服务于各个领域的需求。
==================================================
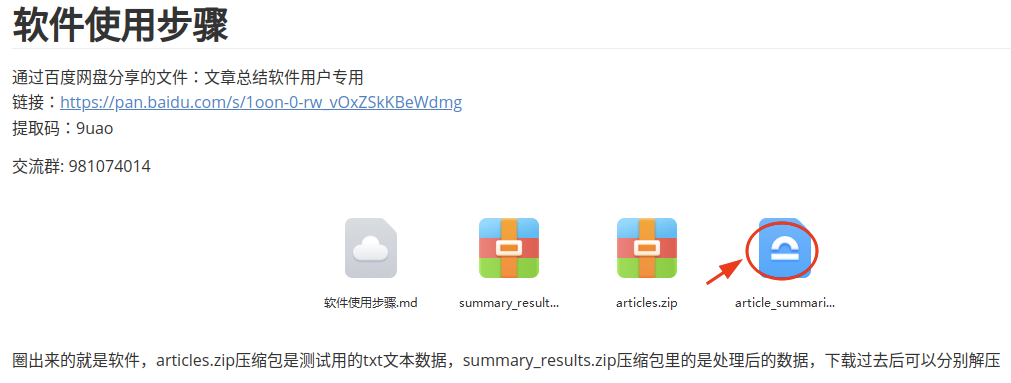
利用GPT提高信息处理效率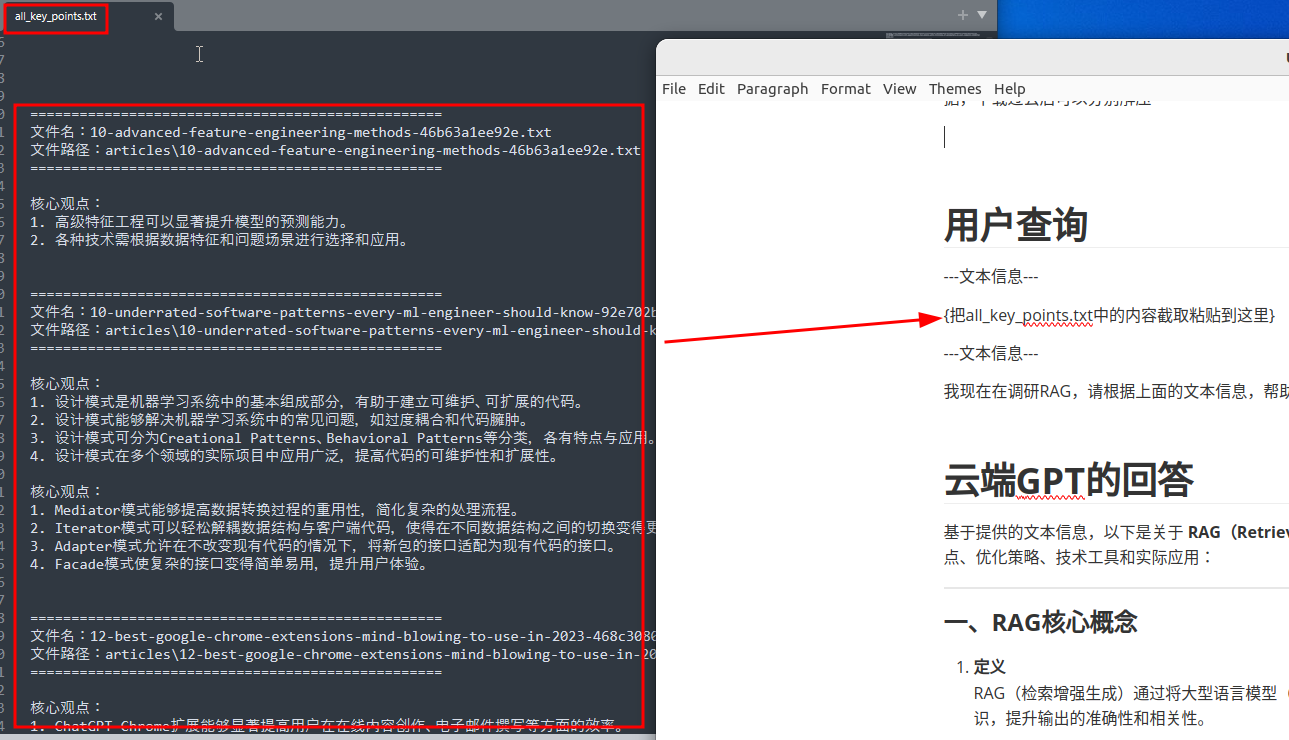

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)