小白也能看懂的大模型微调知识点
AIpaca 格式具有简单的结构,特别适用于文本生成、翻译、总结等任务,尤其是单轮任务导向的指令微调。以下是其主要组成部分的详细解释:📍instruction: 任务指令,类似于用户的输入(必填项),明确告诉模型要做什么。input: 任务所需的输入内容。通常在任务开放式或不需要明确输入时,可以为空字符串。output: 给定指令和输入的情况下,模型需要生成的期望输出,即参考答案(必填项)。sy
大模型微调全流程
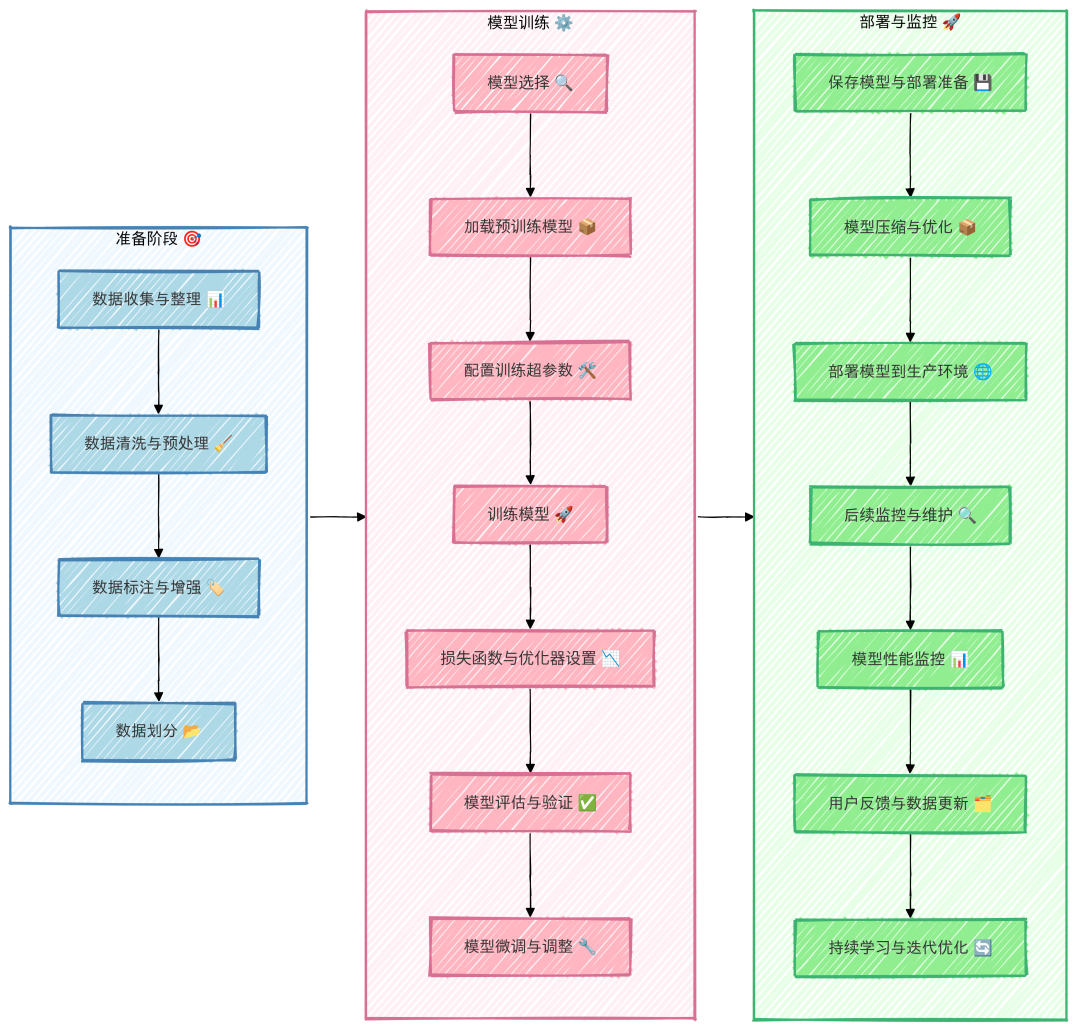
💡建议在微调过程中严格按照以上流程执行,避免跳步,否则可能导致无效劳动。比如,如果没有充分构建数据集,最终发现微调模型效果不佳是数据集质量的问题,那么前期的努力将付诸东流,事倍功半。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
数据集收集与整理
根据数据集的可获得性,数据集可以分为两种类型:公开已有的数据集和难以获取的数据集。
如何获取公开已有的数据集?
获取公开已有的数据集的最简单方式是通过相关开源平台进行搜索和下载。例如:GitHub、Hugging Face、Kaggle、魔搭等平台都提供了大量的开放数据集。此外,还可以尝试通过爬虫技术从一些网站获取数据,比如贴吧、知乎、行业垂直网站等。使用爬虫抓取数据通常需要一定的技术支持和遵循相关的法律法规。
如果所需数据全网没有或难以获得怎么办?
当现有的公开数据集无法满足需求时,另一个选择是自行构建数据集。但是,手动构建几百到上千条数据集往往既繁琐又耗时。那么,如何能够高效地构建数据集呢?以下介绍两种常见的快速构建数据集的思路:
1. 借助大模型平台的“数据增强”功能
目前很多大模型平台提供了数据增强的功能,这可以有效地帮助我们扩展数据集。例如,质谱开放平台、讯飞开放平台、火山开放平台等,都可以通过这些平台的增强功能,利用原始数据快速生成更多样本。具体操作是:首先,手动准备少量(如 50 条)数据,并上传到这些平台。平台会通过数据增强技术对数据进行扩充,快速实现数据集的扩大。
2. 利用大模型生成数据
另一种高效的方式是借助大模型生成数据。首先,准备少量(例如几十条)数据并作为示例输入给大模型。大模型可以根据这些示例生成相似的数据内容。为了确保生成数据的质量,建议在第一轮生成时不要一次生成过多,建议先生成 20 条数据并仔细审查,找出大模型可能犯的常见错误。然后,将这些错误示例反馈给大模型,改进生成效果。
示例Prompt:
参照以下示例,输出20个类似的“近期运气”问题。请注意,语言要生活化、不要过于夸张,避免使用诸如“在活动中”、“在比赛中”等定语或状语,语句尽量简洁,避免多余修饰。示例:
我这个季度顺利吗?
我这个季度会发财吗?
最近有哪些事情在等着我?
最近会发生什么事情?
近期我能否被幸运之神垂青?
数据清洗与微调数据集构建
原始数据集通常并不符合模型训练的要求,因此需要对其进行清理和处理,使其符合模型学习的格式。在多数情况下,微调数据集通常采用 AIpaca 格式进行构建。
AIpaca 格式简介
AIpaca 格式具有简单的结构,特别适用于文本生成、翻译、总结等任务,尤其是单轮任务导向的指令微调。以下是其主要组成部分的详细解释:
📍
-
instruction: 任务指令,类似于用户的输入(必填项),明确告诉模型要做什么。
-
input: 任务所需的输入内容。通常在任务开放式或不需要明确输入时,可以为空字符串。
-
output: 给定指令和输入的情况下,模型需要生成的期望输出,即参考答案(必填项)。
-
system: 可以视作模型的预先 Prompt,用于设置模型的行为,通常是对模型的一些初始提示(选填项)。
-
history: 历史对话信息,可以帮助模型建立上下文关系。在多轮任务中,模型会根据历史对话生成回答(选填项)。
例如,AIpaca 数据格式如下:
[
{
"instruction": "用‘梦想’、‘坚持’和‘成功’这三个词组成一个句子。",
"input": "",
"output": "只有坚持追逐梦想,才能最终取得成功。"
},
{
"instruction": "对《三国演义》做一个简短的介绍。",
"input": "",
"output": "《三国演义》是中国古典四大名著之一,描写了从东汉末年到西晋初年近百年的历史,讲述了东汉末年的群雄割据混战及魏、蜀、吴三国之间的政治和军事斗争,塑造了一批英雄人物。"
}
]
数据集构建方法
为了制作微调数据集,通常我们需要将数据转换为符合 AIpaca 格式的 JSON 文件。以下是常见的两种数据集制作方法:
-
手动构建数据集:整理好所需的数据并按照 AIpaca 格式构建,可以通过编写 Python 代码手动构建数据集。这种方法适用于简单的场景和小规模数据集。
-
利用大模型自动化构建:通过调用大模型接口来自动生成数据集。这种方法适用于大规模数据集,尤其是当任务的指令和输出模式比较固定时。
完整数据集格式
完整的 AIpaca 格式如下所示,包含了任务的指令、输入、输出、系统提示词及历史对话信息:
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
该格式帮助模型学习从指令到输出的映射关系,类似于给模型提供了练习题,instruction + input = 问题,output = 答案。
底座模型选型
-
模型类型选择:根据任务需求选择基础模型,如 GPT、LLaMA、或 BERT 等。
-
规模和参数:决定模型大小(如 7B、13B 或 65B 参数规模),考虑计算资源、训练时间和推理速度。
-
开源 vs 商业模型:分析是否需要选择开源模型(如 LLaMA、Falcon)或商业闭源模型(如 OpenAI GPT 系列)。
-
用测试数据,在选择的多个模型中,做对比测试,找出最合适的。
模型参数说明

灵魂五问
一、什么是微调?
微调 (Fine-tuning) 是指在一个已经预训练好的模型基础上,使用新的数据集对其进一步训练的过程。这些预训练模型通常已经在大型数据集上学习到了丰富的特征和知识,具备一定的通用能力。微调的核心目标是将这些通用知识迁移到一个新的、更具体的任务或领域,使模型能够更好地解决特定问题。
二、为什么要微调?
1. 节省计算资源
从头开始训练一个大型模型需要大量的计算资源和时间,成本非常高。微调利用预训练模型作为起点,只需对新数据集进行较少的训练,就能取得良好效果,大大降低了计算成本和时间。
2. 提升模型性能
预训练模型虽然具有通用能力,但在特定任务上可能表现不佳。微调通过特定领域数据对模型参数进行调整,使其更加擅长处理目标任务,从而提高准确率和效率。
3. 适应新领域
通用预训练模型可能无法很好地理解特定领域的数据特征,而微调可以帮助模型适配新领域,使其更好地处理特定任务中的数据。
三、微调得到的是什么?
微调得到的是一个经过优化和调整后的模型。这个模型基于原始预训练模型的结构,但他的参数已经更新,能够更好地适应新任务或领域需求。
举例说明:
假设有一个预训练的图像分类模型,可以识别常见物体。如果需要识别特定类型的花朵,可以用包含各种花朵图片和标签的新数据集对模型进行微调。经过微调后,模型的参数会更新,从而更准确地识别这些花朵类型。
四、如何把微调好的模型进行生产使用?
1. 部署到生产环境
将模型集成到网站、移动应用或其他系统中,可以使用模型服务器或云服务进行部署,如 TensorFlow Serving、TorchServe 或 Hugging Face 提供的 API。
2. 推理任务
将微调后的模型用于推理,比如给定输入进行预测或分析结果。
3. 持续更新与优化
根据新的需求或反馈,进一步微调模型或添加更多数据进行训练,保持模型性能最佳状态。
五、微调方法怎么选?
-
LoRA:低秩适配,用于减少微调参数规模,适合资源受限环境。
-
QLoRA:基于 LoRA 的量化优化,更高效地处理大模型微调。
-
P-tuning:提示学习技术,适合小样本任务或少量标注数据。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 41
41 0
0- 0



 已为社区贡献97条内容
已为社区贡献97条内容

所有评论(0)