
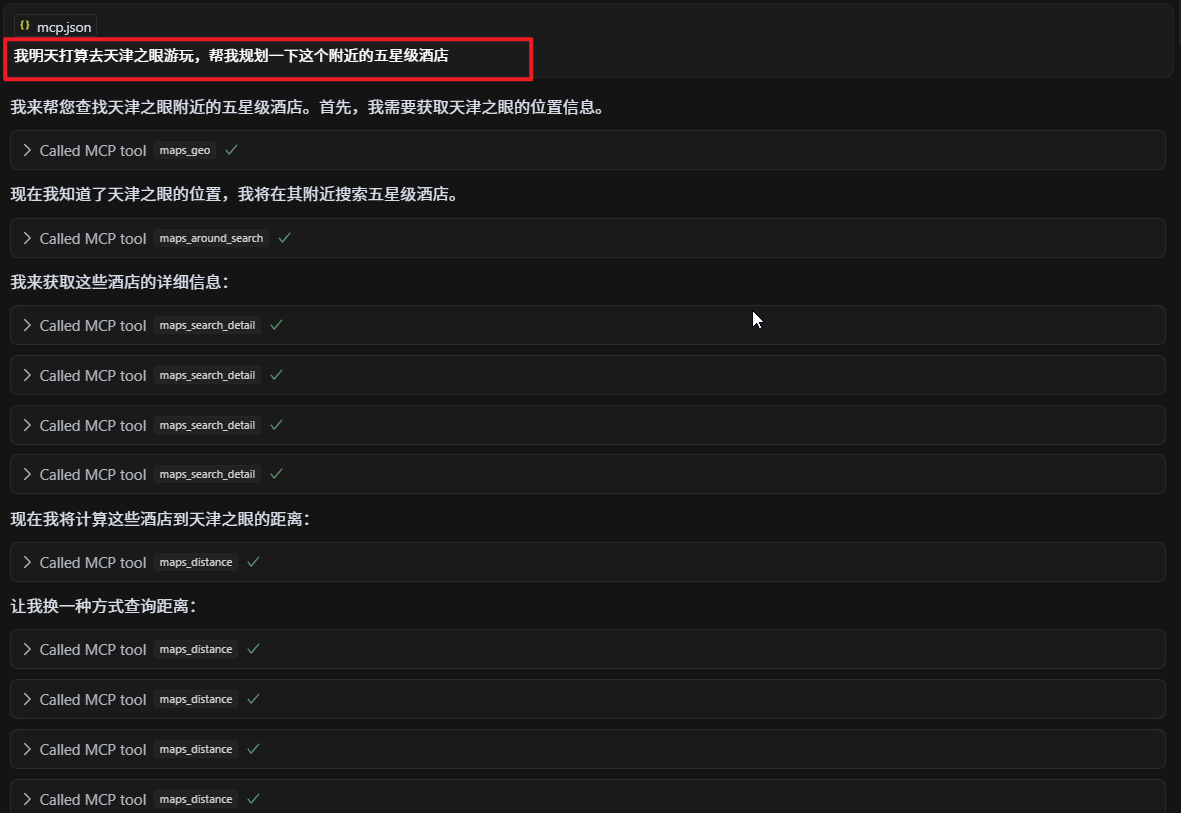
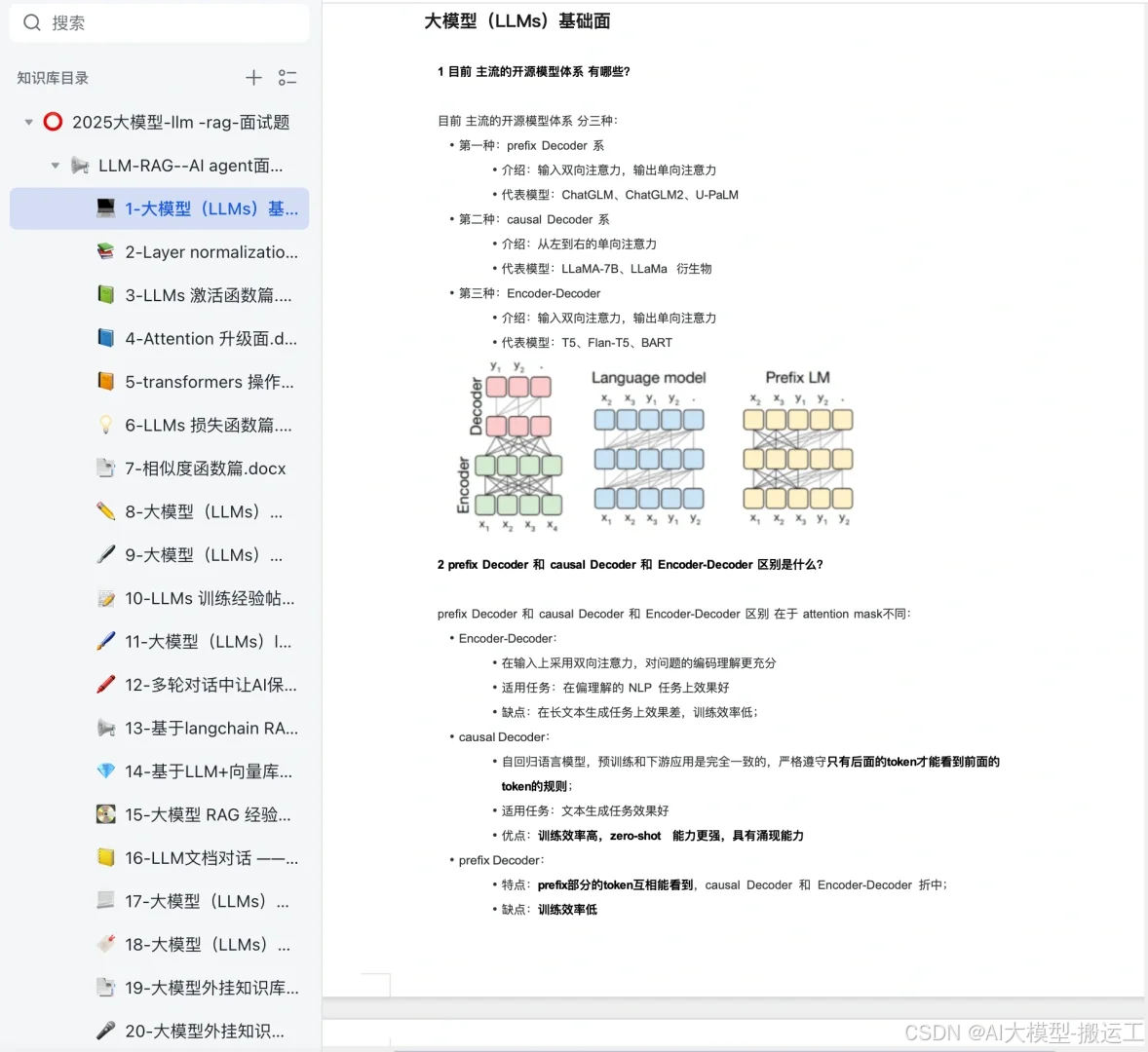
机器学习_集成学习之Voting/Averaging(集成基模型的预测结果)
机器学习_集成学习之Voting/Averaging(集成基模型的预测结果)
通过 Voting 进行不同算法的集成
Voting 就是投票的意思。这种集成算法一般应用于分类问题。思路很简单。假如用6种机器学习模型来进行分类预测,就拥有6个预测结果集,那么6种模型,一种模型一票。如果是猫狗图像分类,4种模型被认为是猫,2种模型被认为是狗,那么集成的结果会是猫。当然,如果出现票数相等的情况(3票对3票),那么分类概率各为一半。
下面就用 Voting 算法集成之前所做的客户流失数据集,看一看Voting的结果能否带来F1分数的进一步提升。截止目前,针对这个问题我们发现的最好算法是随机森林和 GBDT,随后的次优算法是极端随机森林、树的聚合和XGBoost,而SVM和AdaBoost 对于这个问题来说稍微弱一些,但还是比逻辑回归强很多(从这里也可以看出“集成学习算法家族”的整体实力是非常强的)。
把上述这些比较好的算法放在一起进行Voting—这也可以算是集成的集成
import numpy as np # 基础线性代数扩展包
import pandas as pd # 数据处理工具箱
df_bank = pd.read_csv("../数据集/BankCustomer.csv") # 读取文件
# 构建特征和标签集合
y = df_bank['Exited']
X = df_bank.drop(['Name', 'Exited', 'City'], axis=1)
from sklearn.model_selection import train_test_split # 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=0)
# 对多棵决策树进行Bagging,即树的聚合
from sklearn.ensemble import BaggingClassifier # 导入Bagging分类器
from sklearn.tree import DecisionTreeClassifier # 导入决策树分类器
from sklearn.metrics import (f1_score, confusion_matrix) # 导入评估标准
dt = BaggingClassifier(DecisionTreeClassifier()) # 只使用一棵决策树
dt.fit(X_train, y_train) # 拟合模型
y_pred = dt.predict(X_test) # 进行预测
print("决策树测试准确率: {:.2f}%".format(dt.score(X_test, y_test)*100))
print("决策树测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
bdt = BaggingClassifier(DecisionTreeClassifier()) #树的Bagging
bdt.fit(X_train, y_train) # 拟合模型
y_pred = bdt.predict(X_test) # 进行预测
print("决策树Bagging测试准确率: {:.2f}%".format(bdt.score(X_test, y_test)*100))
print("决策树Bagging测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))

from sklearn.model_selection import GridSearchCV # 导入网格搜索工具
# 使用网格搜索优化参数
bdt_param_grid = {
'base_estimator__max_depth' : [5,10,20,50,100],
'n_estimators' : [1, 5, 10, 50]}
bdt_gs = GridSearchCV(BaggingClassifier(DecisionTreeClassifier()),
param_grid = bdt_param_grid, scoring = 'f1',
n_jobs= 10, verbose = 1)
bdt_gs.fit(X_train, y_train) # 拟合模型
bdt_gs = bdt_gs.best_estimator_ # 最佳模型
y_pred = bdt.predict(X_test) # 进行预测
print("决策树Bagging测试准确率: {:.2f}%".format(bdt_gs.score(X_test, y_test)*100))
print("决策树Bagging测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))

from sklearn.ensemble import RandomForestClassifier # 导入随机森林分类器
rf = RandomForestClassifier() # 随机森林模型
# 使用网格搜索优化参数
rf_param_grid = {"max_depth": [None],
"max_features": [1, 3, 10],
"min_samples_split": [2, 3, 10],
"min_samples_leaf": [1, 3, 10],
"bootstrap": [True,False],
"n_estimators" :[100,300],
"criterion": ["gini"]}
rf_gs = GridSearchCV(rf,param_grid = rf_param_grid,
scoring="f1", n_jobs= 10, verbose = 1)
rf_gs.fit(X_train,y_train) # 拟合模型
rf_gs = rf_gs.best_estimator_ # 最佳模型
y_pred = rf_gs.predict(X_test) # 进行预测
print("随机森林测试准确率: {:.2f}%".format(rf_gs.score(X_test, y_test)*100))
print("随机森林测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))

from sklearn.ensemble import ExtraTreesClassifier # 导入极端随机森林模型
ext = ExtraTreesClassifier() # 极端随机森林模型
# 使用网格搜索优化参数
ext_param_grid = {"max_depth": [None],
"max_features": [1, 3, 10],
"min_samples_split": [2, 3, 10],
"min_samples_leaf": [1, 3, 10],
"bootstrap": [True,False],
"n_estimators" :[100,300],
"criterion": ["gini"]}
ext_gs = GridSearchCV(ext,param_grid = ext_param_grid, scoring="f1",
n_jobs= 4, verbose = 1)
ext_gs.fit(X_train,y_train) # 拟合模型
ext_gs = ext_gs.best_estimator_ # 最佳模型
y_pred = ext_gs.predict(X_test) # 进行预测
print("更多树测试准确率: {:.2f}%".format(ext_gs.score(X_test, y_test)*100))
print("更多树测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))

from sklearn.ensemble import AdaBoostClassifier # 导入AdaBoost模型
dt = DecisionTreeClassifier() # 选择决策树分类器作为AdaBoost的基准算法
ada = AdaBoostClassifier(dt) # AdaBoost模型
# 使用网格搜索优化参数
ada_param_grid = {"base_estimator__criterion" : ["gini", "entropy"],
"base_estimator__splitter" : ["best", "random"],
"base_estimator__random_state" : [7,9,10,12,15],
"algorithm" : ["SAMME","SAMME.R"],
"n_estimators" :[1,2,5,10],
"learning_rate": [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3,1.5]}
ada_gs = GridSearchCV(ada,param_grid = ada_param_grid,
scoring="f1", n_jobs= 10, verbose = 1)
ada_gs.fit(X_train,y_train) # 拟合模型
ada_gs = ada_gs.best_estimator_ # 最佳模型
y_pred = ada_gs.predict(X_test) # 进行预测
print("Adaboost测试准确率: {:.2f}%".format(ada_gs.score(X_test, y_test)*100))
print("Adaboost测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))

from sklearn.ensemble import GradientBoostingClassifier # 导入梯度提升分类器
gb = GradientBoostingClassifier() # 梯度提升分类器
# 使用网格搜索优化参数
gb_param_grid = {'loss' : ["deviance"],
'n_estimators' : [100,200,300],
'learning_rate': [0.1, 0.05, 0.01],
'max_depth': [4, 8],
'min_samples_leaf': [100,150],
'max_features': [0.3, 0.1]}
gb_gs = GridSearchCV(gb,param_grid = gb_param_grid,
scoring="f1", n_jobs= 10, verbose = 1)
gb_gs.fit(X_train,y_train) # 拟合模型
gb_gs = gb_gs.best_estimator_ # 最佳模型
y_pred = gb_gs.predict(X_test) # 进行预测
print("梯度提升测试准确率: {:.2f}%".format(gb_gs.score(X_test, y_test)*100))
print("梯度提升测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))

from xgboost import XGBClassifier # 导入XGB分类器
xgb = XGBClassifier() # XGB分类器
# 使用网格搜索优化参数
xgb_param_grid = {'min_child_weight': [1, 5, 10],
'gamma': [0.5, 1, 1.5, 2, 5],
'subsample': [0.6, 0.8, 1.0],
'colsample_bytree': [0.6, 0.8, 1.0],
'max_depth': [3, 4, 5]}
xgb_gs = GridSearchCV(xgb,param_grid = xgb_param_grid,
scoring="f1", n_jobs= 10, verbose = 1)
xgb_gs.fit(X_train,y_train) # 拟合模型
xgb_gs = xgb_gs.best_estimator_ # 最佳模型
y_pred = xgb_gs.predict(X_test) # 进行预测
print("XGB测试准确率: {:.2f}%".format(xgb_gs.score(X_test, y_test)*100))
print("XGB测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))

from sklearn.ensemble import VotingClassifier # 导入Voting分类器
# 把各种模型的分类结果进行Voting,同学们还可以加入更多模型如SVM,kNN等
voting = VotingClassifier(estimators=[('rf', rf_gs),
('gb',gb_gs),
('ext', ext_gs),
('xgb', xgb_gs),
('ada', ada_gs)],
voting='soft', n_jobs=10)
voting = voting.fit(X_train, y_train) # 拟合模型
y_pred = voting.predict(X_test) # 进行预测
print("Voting测试准确率: {:.2f}%".format(voting.score(X_test, y_test)*100))
print("Voting测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))

输出结果显示,集成这几大算法的预测结果之后,准确率进一步小幅上升至86.35%,而更为重要的F1分数居然提高到60.49%。对于这个预测客户流失率的问题而言,这个F1分数已经几乎是我们目前可以取得的最佳结果。
通过Averaging 集成不同算法的结果
最后,还有一种更为简单粗暴的结果集成算法Averaging,就是完全独立地进行几种机器学习模型的训练,训练好之后生成预测结果,最后把各个预测结果集进行平均:
modell.fit(X train, y_train)
model2.fit(X_train, y_train)
model3.fit(X train, y_train)
pred_ml = model1.predict_proba(X test)
pred_m2 = mode12.predict_proba(X test)
pred_m3 = made13.predict_proba(X_test)
pred_final = (pred_ml + pred_m2 + pred_m3)/3
在取均值的时候可以给你们觉得更优秀的算法进行加权。
pred_final = (pred_m1*0.5 + pred_m2*0.3 + pred_m3*0.2)
并没有新的模型训练过程,只是读取了两个CSV的数据,然后加起来,除以2,重新生成可提交的预测结果文件
p_res[label_cols] = (p_nbsvm[label_cols] + p_1stm[label_cols])/2
p_res.to_csv('submission.csv', index=False)
与通常只用于分类问题的Voting 相比较,Averaging的优点在于既可以处理分类问题,又可以处理回归问题。分类问题是将概率值进行平均,而回归问题是将预测值进行平均,而且在平均的过程中还可以增加权重。
参考资料:零基础学机器学习

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)