36k Star的开源大模型应用开发平台,Dify真的太强了!
Dify是一款开源的大语言模型(LLM)应用开发平台,它帮助开发者和非技术人员,快速构建生产级别的生成式AI应用。
引言
Dify是一款开源的大语言模型(LLM)应用开发平台,它帮助开发者和非技术人员,快速构建生产级别的生成式AI应用。
该项目设立于2023 年 3 月,开源协议是基于 Apache License 2.0 有限商业许可,后端技术Python/Flask/PostgreSQL,前端技术Next.js。
它提供了构建LLM应用所需的关键技术组件,如模型支持、Prompt编排、RAG引擎、Agent框架和流程编排,同时还具备直观的界面和API。
Dify的主要功能包括:
加速AI应用开发:帮助创业者快速将创意变为现实,已助力多个团队构建MVP并获得投资。
**集成LLM至现有业务:**通过RESTful API将LLM能力嵌入现有应用,实现Prompt与业务逻辑的解耦,便于跟踪数据、成本和用量,持续优化应用效果。
**企业级LLM基础设施:**作为企业内部的LLM网关,加速GenAI技术在企业中的应用,实现中心化监管。
**探索LLM边界:**即使是技术爱好者,也可通过Dify实践Prompt工程和Agent技术,探索LLM的能力极限。
Dify还提供了完整的云服务,无需安装即可使用。
截止发稿前在 Github 上已获得 36.3k Star!
附上Github地址:github.com/langgenius/…
模型设置
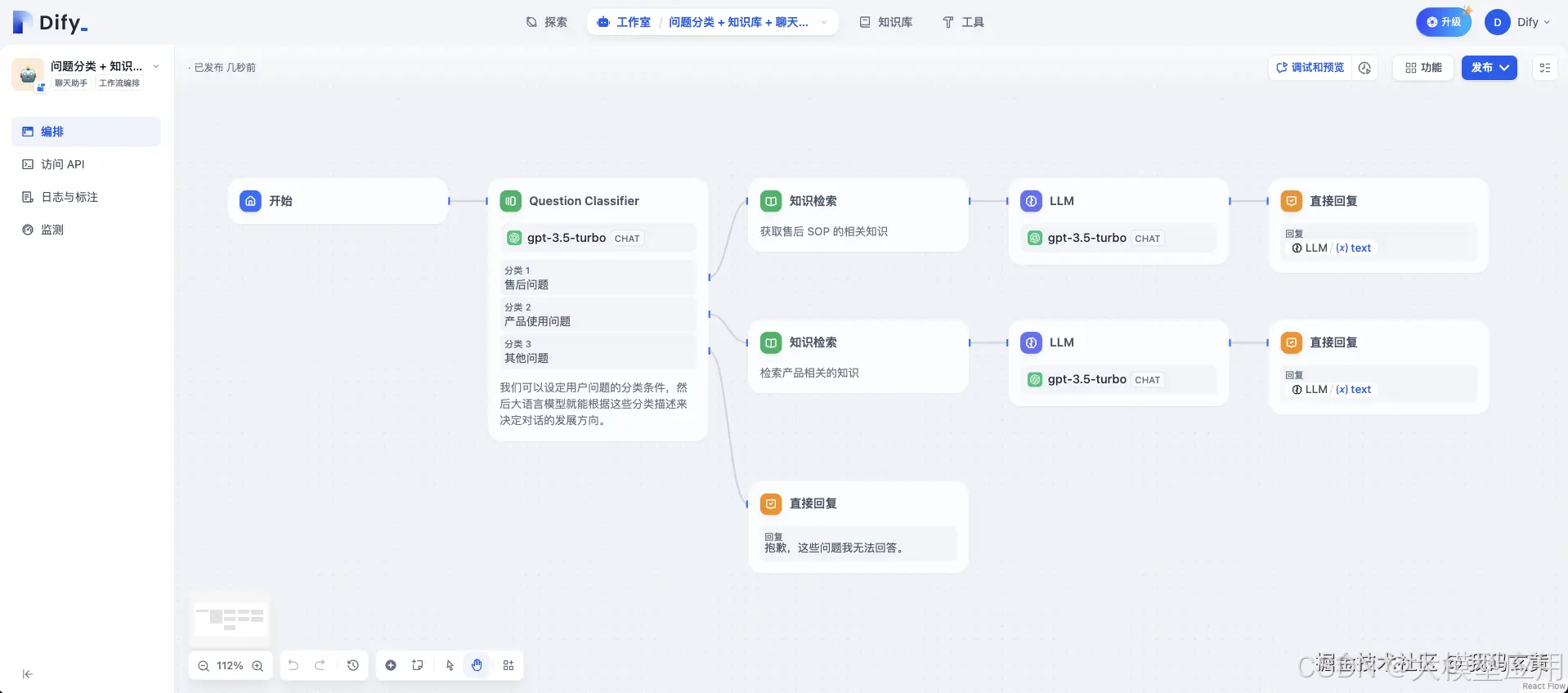
Dify 目前已支持主流的模型供应商,并将模型按场景分为4个类:
1、系统推理模型:
在创建的应用中,用的是该类型的模型。智聊、对话名称生成、下一步问题建议用的也是推理模型。
已支持的系统推理模型供应商:
OpenAI、Azure OpenAI Service、Anthropic、Hugging Face Hub、Replicate、Xinference、OpenLLM、讯飞星火、文心一言、通义千问、Minimax、ZHIPU(ChatGLM)
2、Embedding 模型:
在数据集中,将分段过的文档做 Embedding 用的是该类型的模型。在使用了数据集的应用中,将用户的提问做 Embedding 处理也是用的该类型的模型。
已支持的 Embedding 模型供应商:
OpenAI、ZHIPU(ChatGLM)、JinaAI
3、Rerank 模型:
Rerank 模型用于增强检索能力,改善 LLM 的搜索结果。
已支持的 Rerank 模型供应商:
Cohere、JinaAI
4、语音转文字模型:
将对话型应用中,将语音转文字用的是该类型的模型。
已支持的语音转文字模型供应商:OpenAI
应用&工作流
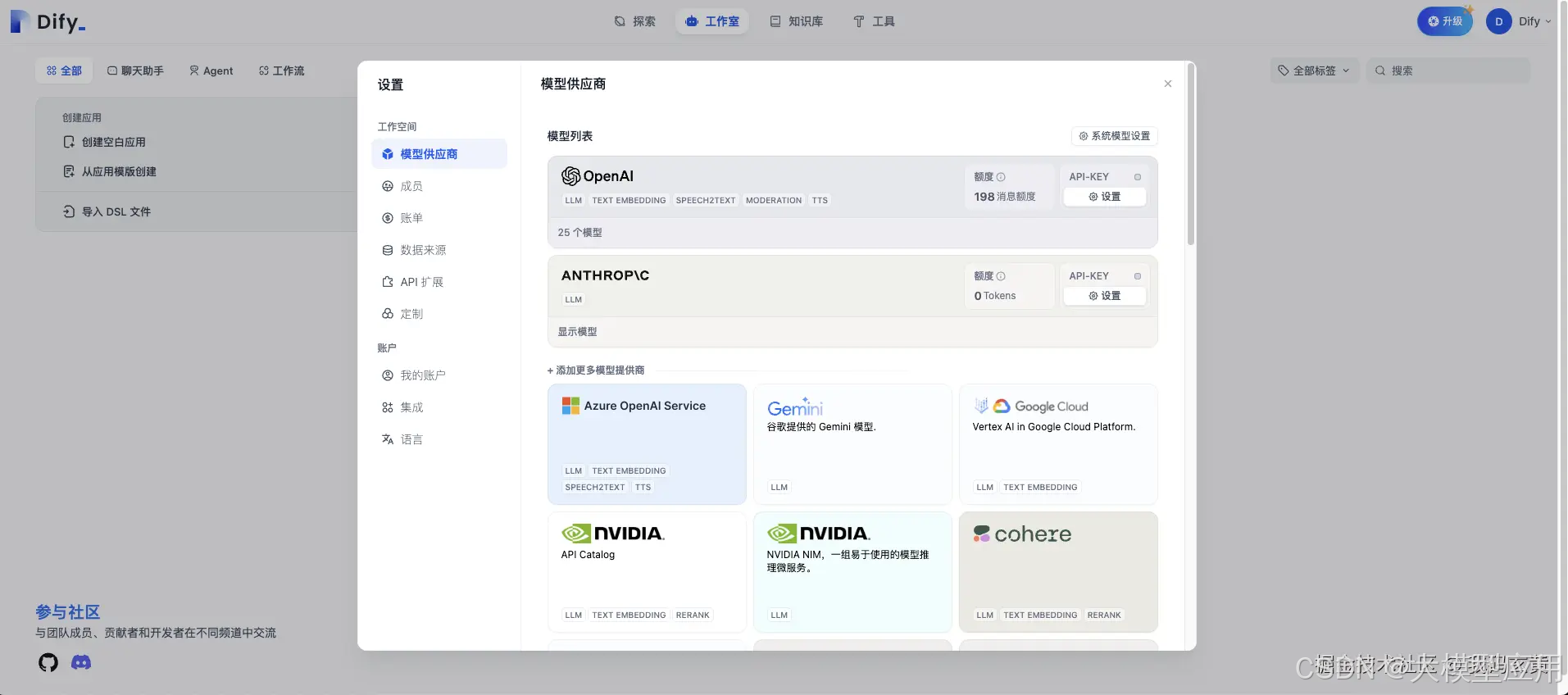
在 Dify 中应用都是基于 GPT 等大预言模型构建的,并且包含了完整的API、Token鉴权、WebApp来帮助使用者快速开发。它还提供了四种应用类型:
聊天助手: 基于 LLM 构建对话式交互的助手
文本生成: 构建面向文本生成类任务的助手,例如撰写故事、文本分类、翻译等
Agent: 能够分解任务、推理思考、调用工具的对话式智能助手
工作流: 基于流程编排的方式定义更加灵活的 LLM 工作流
知识库
在Dify平台中,我们地运用知识库来实施RAG(Retrieval-Augmented Generation)技术,当用户提出一个问题时,系统会迅速在知识库中搜索与该问题最为契合的数据片段。
这一过程涉及复杂的语义匹配算法,确保所检索到的内容不仅相关,而且能够直接回答或辅助解答用户的问题。
一旦找到合适的信息,系统会将这些检索到的文档片段融入模型生成回复的上下文中,作为额外的背景知识,使用户获得更为满意和详尽的答案。
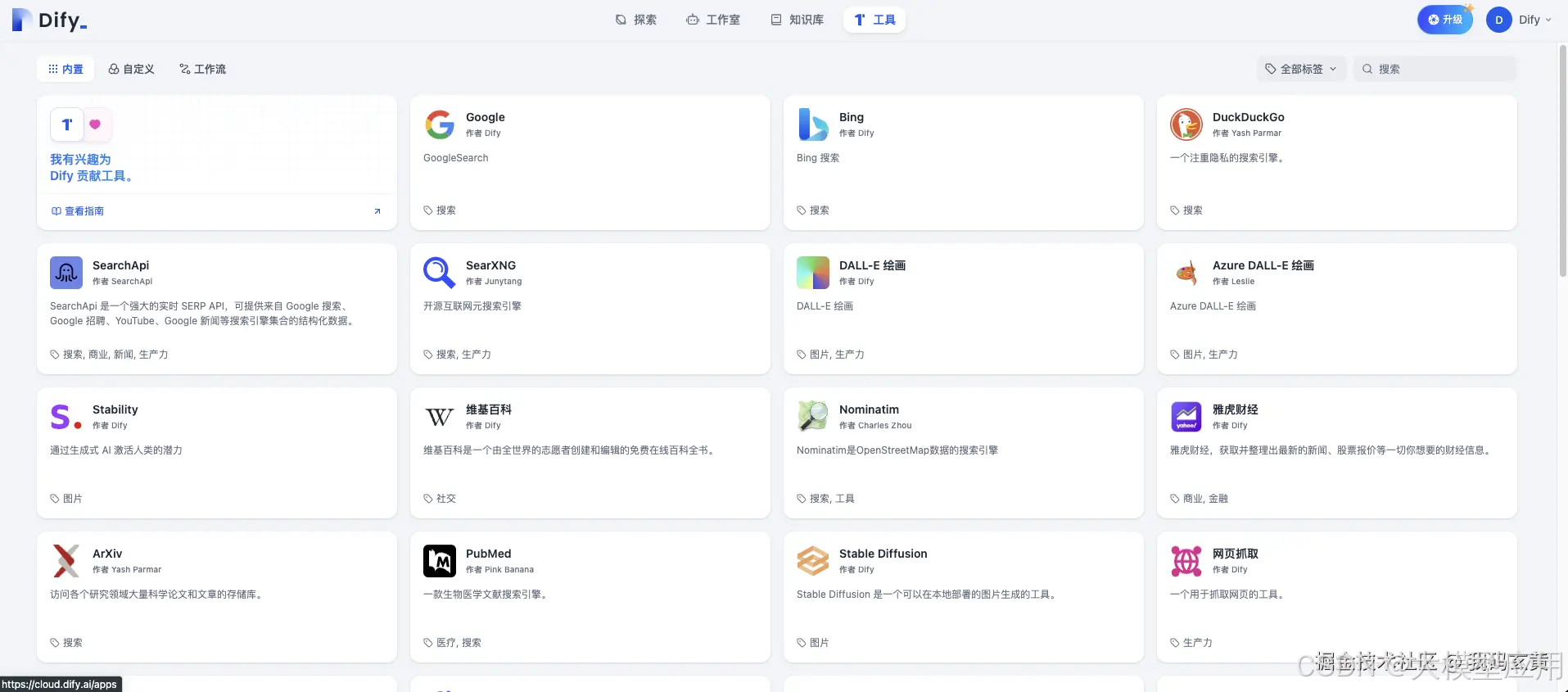
工具
工具有效地拓展了大型语言模型(LLM)的功能边界,通过集成联网搜索、科学计算、图像生成等能力,不仅丰富了LLM的技能集,还显著增强了其与外部世界互动的能力。
使得LLM能更全面地理解和响应复杂多样的现实需求。
安装
系统要求
在安装 Dify 之前,请确保您的机器满足以下最低系统要求:
- CPU >= 2 Core
- RAM >= 4GB
快速启动
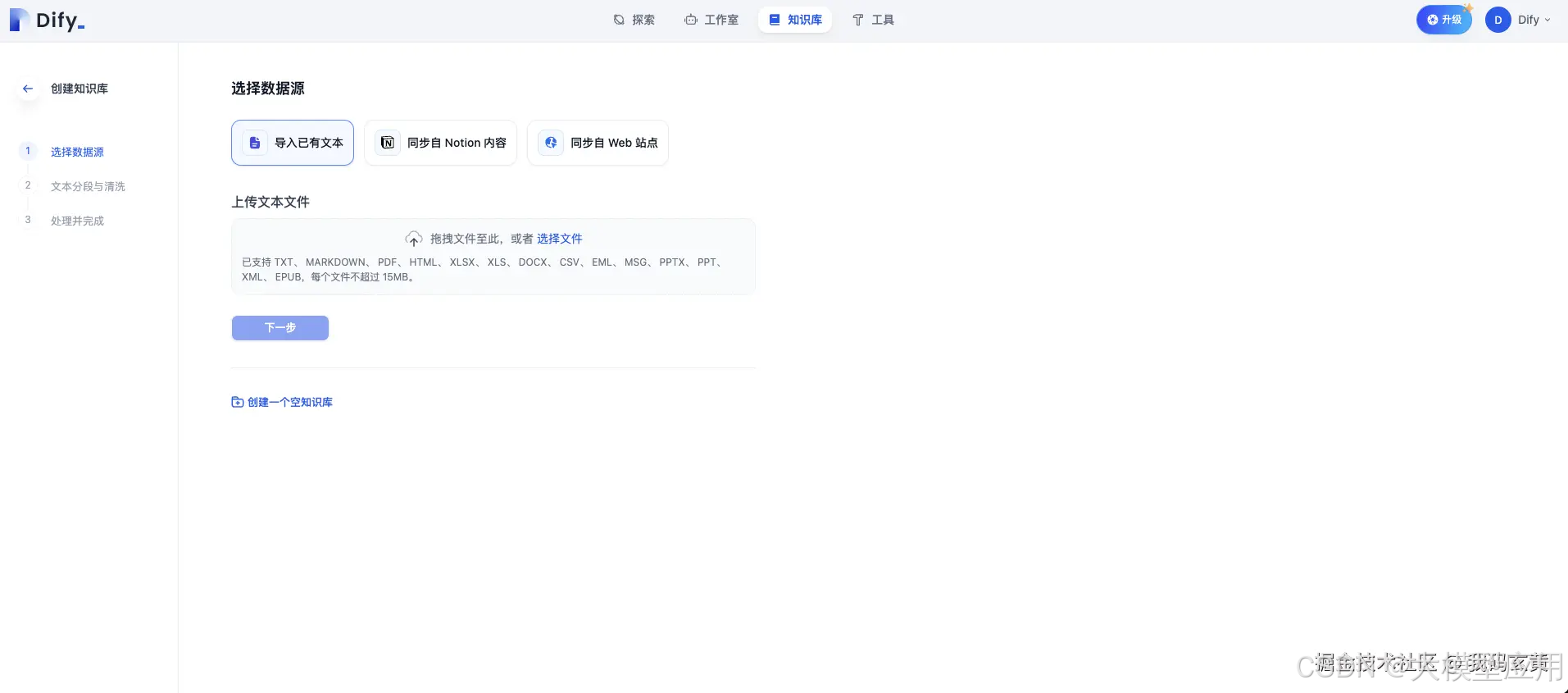
启动 Dify 服务器的最简单方法是运行 docker-compose.yml 文件。
在运行安装命令之前,请确保您的机器上安装了 Docker 和 Docker Compose:
cd docker cp .env.example .env docker compose up -d
运行后,可以在浏览器上访问 http://localhost/install 进入 Dify 控制台并开始初始化安装操作。
自定义配置
如果您需要自定义配置,请参考 .env.example 文件中的注释,并更新 .env 文件中对应的值。
此外,可能需要根据您的具体部署环境和需求对 docker-compose.yaml 文件本身进行调整,例如更改镜像版本、端口映射或卷挂载。
完成任何更改后,请重新运行 docker-compose up -d。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

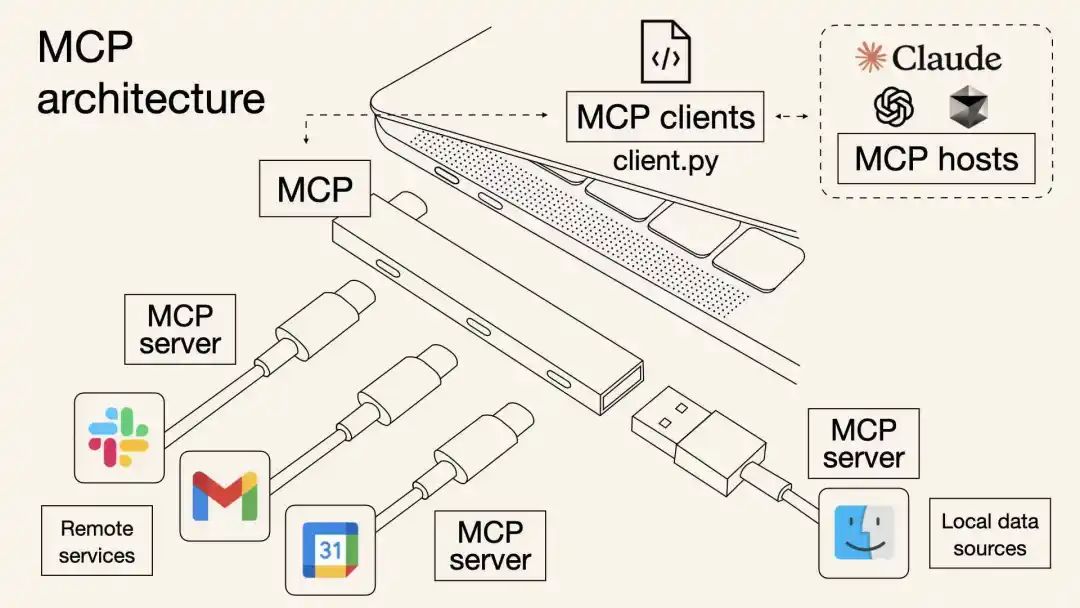
欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)