Qwen2.5-Omni 技术报告
2025年3月26日Qwen2.5-Omni 技术报告Qwen 团队魔搭社区摘要本报告介绍了 Qwen2.5-Omni,这是一个端到端的多模态模型,能够感知多种模态(包括文本、图像、音频和视频),并以流式方式同时生成文本和自然语音响应。为了实现多模态信息输入的流式处理,音频和视觉编码器均采用块处理方法。这种策略有效地将多模态数据长序列的处理解耦,将感知任务分配给多模态编码器,而将长序列建模任务交给
摘要
2025年3月26日
Qwen2.5-Omni 技术报告
Qwen 团队
https://huggingface.co/Qwen
https://github.com/QwenLM/Qwen2.5-Omni
摘要
本报告介绍了 Qwen2.5-Omni,这是一个端到端的多模态模型,能够感知多种模态(包括文本、图像、音频和视频),并以流式方式同时生成文本和自然语音响应。为了实现多模态信息输入的流式处理,音频和视觉编码器均采用块处理方法。这种策略有效地将多模态数据长序列的处理解耦,将感知任务分配给多模态编码器,而将长序列建模任务交给大型语言模型。这种分工通过共享注意力机制增强了不同模态的融合。为了同步视频输入的时间戳与音频,我们按顺序组织音频和视频,并提出了一种新颖的位置嵌入方法,称为 TMRoPE(时间对齐多模态 RoPE)。为了同时生成文本和语音并避免两种模态之间的干扰,我们提出了 Thinker-Talker 架构。在这个框架中,Thinker 作为大型语言模型,负责文本生成,而 Talker 是一个双轨自回归模型,直接利用 Thinker 的隐藏表示来生成音频标记作为输出。Thinker 和 Talker 模型均设计为端到端训练和推理。为了以流式方式解码音频标记,我们引入了滑动窗口 DiT,限制感受野,旨在减少初始包延迟。Qwen2.5-Omni 在性能上与同样大小的 Qwen2.5-VL 相当,并优于 Qwen2-Audio。此外,Qwen2.5-Omni 在多模态基准测试(如 Omni-Bench)中达到了最新水平。值得注意的是,Qwen2.5-Omni 在端到端语音指令跟随方面的表现与文本输入能力相当,这在 MMLU 和 GSM8K 等基准测试中得到了证明。在语音生成方面,Qwen2.5-Omni 的流式 Talker 在鲁棒性和自然度方面优于大多数现有的流式和非流式替代方案。
1. 引言
在日常生活中,人类能够同时感知周围的视觉和听觉信息。经过大脑处理后,他们通过书写、发声或使用工具(以及身体动作)来表达反馈,从而与世界上的各种生物进行信息交流并表现出智能。近年来,由于大型语言模型(LLMs)的发展,通用人工智能越来越受到关注(Brown 等人,2020;OpenAI,2023;2024;Gemini 团队,2024;Anthropic,2023a;b;2024;Bai 等人,2023a;Yang 等人,2024a;Touvron 等人,2023a;b;Dubey 等人,2024a)。这些模型在大量文本数据上进行训练,代表人类创建的高级离散表示,展现出解决复杂问题和快速学习的能力。此外,在理解领域,语言-音频-语言模型(LALMs)(OpenAI,2024;Tang 等人,2024;Chu 等人,2023b;2024b)和语言-视觉-语言模型(LVLMs)(Li 等人,2023;Liu 等人,2023b;Dai 等人,2023;Zhu 等人,2023;Huang 等人,2023;Bai 等人,2023b;Liu 等人,2023a;Wang 等人,2023b;OpenAI,2023;Gemini 团队,2024)帮助 LLMs 以端到端的方式进一步扩展听觉和视觉能力。然而,高效地以端到端的方式统一所有这些不同的理解模态,利用尽可能多的数据,并以文本和语音流的形式提供类似人类交流的响应,仍然是一个重大挑战。
开发统一且智能的全模态模型需要仔细考虑几个关键因素。首先,必须实施一种系统方法,用于联合训练各种模态(包括文本、图像、视频和音频),以促进它们之间的相互增强。这种对齐对于视频内容尤其重要,其中需要同步音频和视觉信号的时间方面。其次,必须管理不同模态输出之间的潜在干扰,确保文本和语音标记等输出的训练过程不会相互干扰。最后,需要探索能够实时理解多模态信息并允许高效音频输出流的架构设计,从而减少初始延迟。
在本报告中,我们介绍了 Qwen2.5-Omni,这是一个统一的单一模型,能够处理多种模态并以流式格式同时生成文本和自然语音响应。为了解决第一个挑战,我们提出了一种新颖的位置嵌入方法,称为 TMRoPE(时间对齐多模态 RoPE)。我们将音频和视频帧按交错结构组织,以按时间顺序表示视频序列。对于第二个挑战,我们提出了 Thinker-Talker 架构,其中 Thinker 负责文本生成,而 Talker 专注于生成流式语音标记。Talker 直接从 Thinker 接收高级表示。这种设计灵感来源于人类利用不同器官产生各种信号的方式,这些信号通过相同的神经网络同时协调。因此,Thinker-Talker 架构是端到端联合训练的,每个组件都致力于生成不同的信号。为了应对流式处理的挑战并支持实时理解多模态信号所需的预填充,我们对所有多模态编码器进行了修改,采用块流处理方法。为了支持流式语音生成,我们实现了一个双轨自回归模型,用于生成语音标记,以及一个 DiT 模型,将这些标记转换为波形,从而实现流式音频生成并最小化初始延迟。这种设计旨在使模型能够实时处理多模态信息并有效地进行预填充,从而实现文本和语音信号的并发生成。
Qwen2.5-Omni 在性能上与同样大小的 Qwen2.5-VL(Wang 等人,2024c)相当,并在图像和音频能力方面优于 Qwen2-Audio(Chu 等人,2024b)。此外,Qwen2.5-Omni 在多模态基准测试(如 OmniBench(Li 等人,2024b)和 AV-Odyssey Bench(Gong 等人,2024))中达到了最新水平。值得注意的是,Qwen2.5-Omni 在端到端语音指令跟随方面的表现与文本输入能力相当,这在 MMLU(Hendrycks 等人,2021a)和 GSM8K(Cobbe 等人,2021)等基准测试中得到了证明。在语音生成方面,Qwen2.5-Omni 在 seed-tts-eval(Anastassiou 等人,2024)的 test-zh、test-en 和 test-hard 测试集上分别实现了 1.42%、2.33% 和 6.54% 的 WER,优于 MaskGCT(Wang 等人,2024e)和 CosyVoice 2(Du 等人,2024)。
Qwen2.5-Omni 的关键特性可以总结如下:
-
我们介绍了 Qwen2.5-Omni,这是一个统一模型,能够感知所有模态,并以流式方式同时生成文本和自然语音响应。
-
我们提出了一种新颖的位置编码算法,称为 TMRoPE,明确结合时间信息以同步音频和视频。
-
我们提出了 Thinker-Talker 架构,以促进实时理解和语音生成。
-
Qwen2.5-Omni 在所有模态的性能上均表现出色,与同样大小的单模态模型相比。它显著增强了语音指令跟随能力,达到了与纯文本输入相当的性能水平。对于涉及多种模态集成的任务(如在 OmniBench(Li 等人,2024b)中评估的任务),Qwen2.5-Omni 达到了最新水平。值得注意的是,Qwen2.5-Omni 在 seed-tts-eval(Anastassiou 等人,2024)上表现出色,证明了其强大的语音生成能力。
2. 架构
2.1 概述
如图 2 所示,Qwen2.5-Omni 采用 Thinker-Talker 架构。Thinker 像大脑一样,负责处理和理解文本、音频和视频模态的输入,生成高级表示和对应的文本。Talker 则像人类的嘴巴一样,以流式方式接收 Thinker 生成的高级表示和文本,并输出连续的语音标记。Thinker 是一个 Transformer 解码器,配备了用于提取信息的音频和图像编码器。相比之下,Talker 被设计为一个双轨自回归 Transformer 解码器架构,受到 Mini-Omni(Xie & Wu,2024)的启发。在训练和推理过程中,Talker 直接从 Thinker 接收高维表示,并共享 Thinker 的所有历史上下文信息。因此,整个架构作为一个统一的单一模型运行,支持端到端训练和推理。
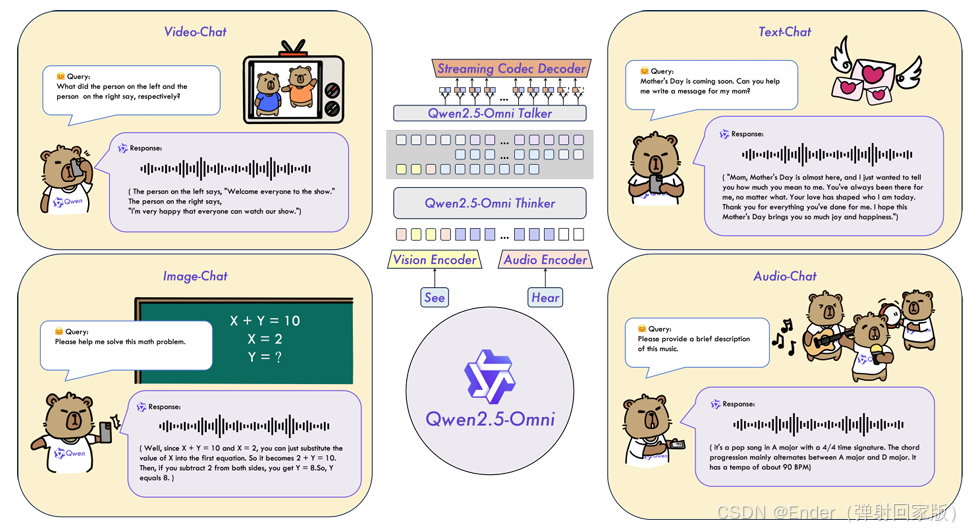
2.2 感知
文本、音频、图像和视频(无音频)。 Thinker 通过将文本、音频、图像和视频(无音频轨道)转换为一系列隐藏表示来处理这些输入。对于文本分词,我们使用 Qwen 的分词器(Yang 等人,2024a),它应用基于字节的字节对编码,词汇表包含 151,643 个常规标记。对于音频输入以及视频中的音频,我们将音频重新采样到 16kHz 的频率,并将原始波形转换为 128 通道的 mel-spectrogram,窗口大小为 25ms,步长为 10ms。我们采用 Qwen2-Audio(Chu 等人,2024b)中的音频编码器,使每个音频帧的表示大致对应原始音频信号的 40ms 片段。此外,我们使用 Qwen2.5-VL(Bai 等人,2025)中的视觉编码器,该编码器基于约 6.75 亿参数的 Vision Transformer(ViT)模型,能够有效处理图像和视频输入。视觉编码器采用混合训练方案,结合图像和视频数据,确保在图像理解和视频理解方面的熟练性。为了尽可能保留视频信息,同时适应音频采样率,我们使用动态帧率对视频进行采样。此外,为了保持一致性,每张图像被视为两个相同的帧。
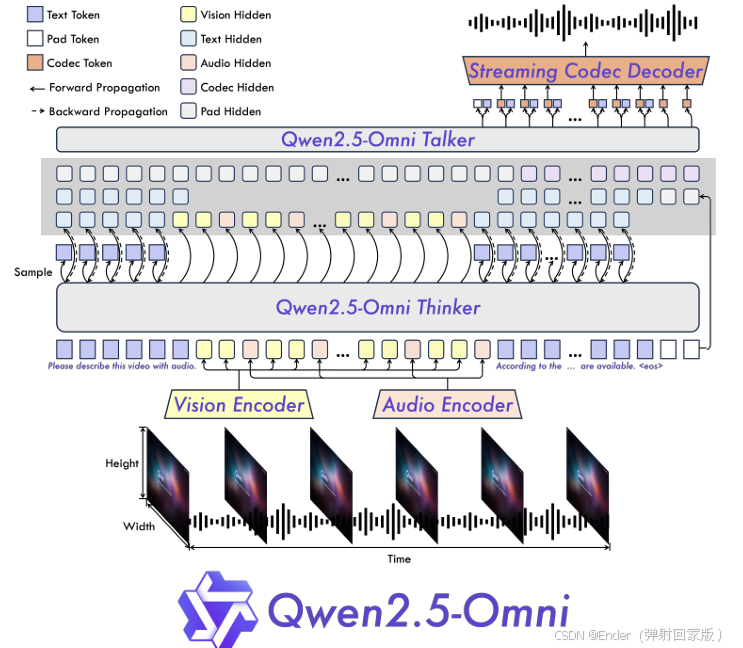
视频和 TMRoPE。 我们提出了一种音频和视频的时间交错算法,以及一种新颖的位置编码方法。如图 3 所示,TMRoPE 对多模态输入的 3D 位置信息进行编码,即多模态旋转位置嵌入(M-RoPE)(Bai 等人,2023b),带有绝对时间位置。这是通过将原始旋转嵌入分解为三个部分实现的:时间、高度和宽度。对于文本输入,这些部分使用相同的位置 ID,使 M-RoPE 在功能上等同于 1D-RoPE。同样,对于音频输入,我们也使用相同的位置 ID,并引入绝对时间位置编码,每个时间 ID 对应 40ms。在处理图像时,每个视觉标记的时间 ID 保持不变,而高度和宽度部分的位置 ID 根据标记在图像中的位置分别分配。当输入是带有音频的视频时,音频仍然使用每个 40ms 帧的相同位置 ID 进行编码,而视频被视为一系列图像,每个帧的时间 ID 递增,而高度和宽度部分的位置 ID 分配模式与图像相同。由于视频的帧率不固定,我们根据每个帧的实际时间动态调整时间 ID 之间的间隔,以确保一个时间 ID 对应 40ms。在模型输入包含多种模态的情况下,每种模态的位置编号通过将前一种模态的最大位置 ID 加一来初始化。TMRoPE 增强了位置信息建模,最大限度地整合了各种模态,使 Qwen2.5-Omni 能够同时理解和分析来自多种模态的信息。
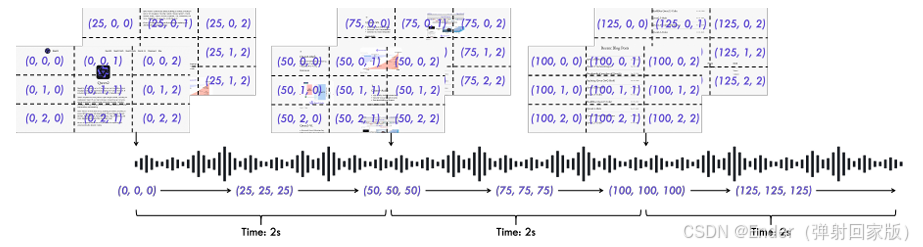
在将位置信息纳入每种模态后,我们将表示按顺序排列。为了使模型能够同时接收视觉和听觉信息,如图 3 所示,我们为带有音频的视频设计了一种特殊的时间交错方法,该方法根据实际时间将带有音频的视频的表示每 2 秒分割成块。然后,我们在 2 秒内将视觉表示放在前面,音频表示放在后面,交错带有音频的视频的表示。
2.3 生成
文本。 文本由 Thinker 直接生成。文本生成的逻辑与广泛使用的 LLMs 所采用的逻辑基本相同,即通过基于词汇表的概率分布进行自回归采样来生成文本。生成过程可能会采用诸如重复惩罚和 top-p 采样等技术来增强其多样性。
语音。 Talker 接收 Thinker 采样的文本标记的嵌入以及高级表示。在这种情况下,高维表示和离散采样标记的整合至关重要。作为一种流式算法,语音生成必须在完整文本生成之前预测内容的语调和态度。Thinker 提供的高维表示隐式地传达了这些信息,从而实现更自然的流式生成过程。此外,Thinker 的表示主要在表示空间中表达语义相似性,而不是语音相似性。因此,即使语音不同的单词也可能具有非常相似的高级表示,这需要输入采样的离散标记以消除这种不确定性。
我们设计了一种高效的语音编解码器,名为 qwen-tts-tokenizer。qwen-tts-tokenizer 能够高效地表示语音的关键信息,并且可以通过因果音频解码器流式解码为语音流。在接收信息后,Talker 开始自回归地生成音频标记和文本标记。语音的生成不需要与文本的逐词和时间戳级别的对齐。这大大简化了训练数据的要求和推理过程。
2.4 流式设计
在流式音频和视频交互的背景下,初始数据包延迟是衡量系统流式性能的关键指标。这种延迟受到几个因素的影响:1)多模态信息输入处理的延迟;2)从接收第一个文本输入到输出第一个语音标记的延迟;3)将第一段语音转换为音频的延迟;4)架构本身的固有延迟,这与模型大小、计算 FLOPs 等因素有关。本文将在后续部分讨论为减少这四个维度的延迟而进行的算法和架构改进。
支持预填充。块预填充是现代推理框架中广泛使用的一种机制。为了在模态交互中支持它,我们修改了音频和视觉编码器,以支持沿时间维度的块注意力。具体来说,音频编码器从对整个音频的全注意力改为每 2 秒执行一次块注意力。视觉编码器使用闪存注意力进行高效训练和推理,并使用一个简单的 MLP 层,将相邻的 2×2 个标记合并为一个标记。设置的补丁大小为 14,这允许不同分辨率的图像被打包成一个序列。
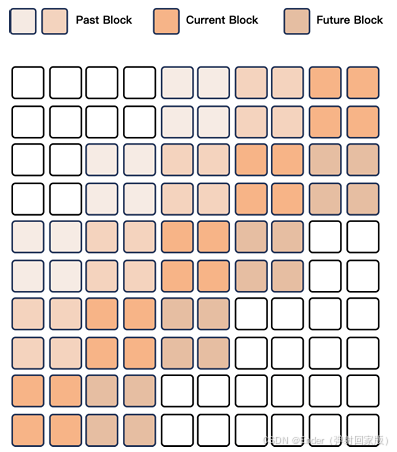
流式编解码器生成。为了便于音频的流式传输,特别是对于较长的序列,我们提出了一种滑动窗口块注意力机制,限制当前标记对有限上下文的访问。具体来说,我们使用 Flow-Matching(Lipman 等人)DiT 模型。使用 Flow-Matching 将输入代码转换为 mel-spectrogram,然后使用修改后的 BigVGAN(Lee 等人)将生成的 mel-spectrogram 重建为波形。
如图 4 所示,为了从代码生成波形,我们将相邻的代码分组为块,并使用这些块进行我们的注意力掩码。我们将 DiT 的感受野限制为 4 个块,包括向后看 2 个块和向前看 1 个块。在解码过程中,我们使用 Flow Matching 以块为单位生成 mel-spectrum,确保每个代码块都能访问必要的上下文块。这种方法通过保持上下文信息来提高流式输出的质量。我们还使用这种方法为 BigVGAN 的固定感受野进行块状处理,以便进行流式波形生成。
3. 预训练
Qwen2.5-Omni 的预训练分为三个阶段。在第一阶段,我们锁定 LLM 参数,专注于训练视觉编码器和音频编码器,利用大量的音频-文本和图像-文本对来增强 LLM 中的语义理解。在第二阶段,我们解冻所有参数,并使用更广泛的多模态数据进行训练,以实现更全面的学习。在最后阶段,我们使用 32k 序列长度的数据来增强模型对复杂长序列数据的理解能力。
该模型在预训练时使用了多种类型的数据集,包括图像-文本、视频-文本、视频-音频、音频-文本和纯文本语料库。我们按照 Qwen2-Audio(Chu 等人,2024a)中的方法,将层次化标签替换为自然语言提示,这可以提高模型的泛化能力和指令遵循能力。
在初始预训练阶段,Qwen2.5-Omni 的 LLM 组件使用 Qwen2.5(Yang 等人,2024b)的参数进行初始化,视觉编码器与 Qwen2.5-VL 相同,音频编码器使用 Whisper-large-v3(Radford 等人,2023)进行初始化。两个编码器在固定的 LLM 上分别进行训练,最初都专注于训练各自的适配器,然后再训练编码器。这种基础训练对于使模型具备对视觉-文本和音频-文本核心关联和对齐的稳健理解至关重要。
第二阶段预训练标志着一个重大进展,通过引入额外的 8000 亿个图像和视频相关标记、3000 亿个音频相关标记以及 1000 亿个视频与音频相关标记。这一阶段引入了更大规模的混合多模态数据和更广泛的任务,从而增强了听觉、视觉和文本信息之间的互动,并加深了对它们的理解。包含多模态、多任务数据集对于开发模型同时处理多种任务和模态的能力至关重要,这对于处理复杂的现实世界数据集来说是一个关键能力。此外,纯文本数据在维持和提高语言熟练度方面发挥着重要作用。
为了提高训练效率,我们在前几个阶段将最大标记长度限制为 8192 个标记。然后,我们将长音频和长视频数据纳入其中,并将原始文本、音频、图像和视频数据扩展到 32,768 个标记进行训练。实验结果表明,我们的数据在支持长序列数据方面表现出显著的改进。
4. 后训练
4.1 数据格式

4.2 Thinker
在后训练阶段,我们使用 ChatML(OpenAI,2022)格式的指令遵循数据进行指令微调。我们的数据集包括纯文本对话数据、视觉模态对话数据、音频模态对话数据以及混合模态对话数据。
4.3 Talker
我们为 Talker 引入了一个三阶段训练过程,使 Qwen2.5-Omni 能够同时生成文本和语音响应。在第一阶段,我们训练 Talker 学习上下文延续。第二阶段利用 DPO(Rafailov 等人,2023)来增强语音生成的稳定性。在第三阶段,我们应用多说话人指令微调来提高语音响应的自然性和可控性。
在上下文学习(ICL)训练阶段,除了使用与 Thinker 类似的文本监督外,我们还通过下一个标记预测,通过一个包含多模态上下文和口语回应的广泛对话数据集,执行语音延续任务。Talker 学会从语义表示到语音建立单调映射,同时获得在不同上下文中表达具有不同属性的语音的能力,例如语调、情感和口音。此外,我们还实施了音色解耦技术,以防止模型将特定语音与不常见的文本模式联系起来。
为了扩大说话人和场景的覆盖范围,预训练数据不可避免地包含标签噪声和发音错误,导致模型出现幻觉。为了缓解这一问题,我们引入了一个强化学习阶段,以提高语音生成的稳定性。具体来说,对于每个带有参考语音的请求和响应文本,我们构建了一个包含三元组数据(x, yw, yl)的数据集 D,其中 x 是带有输入文本的输入序列,yw 和 yl 分别是好的和坏的生成语音序列。我们根据与词错误率(WER)和标点停顿错误率相关的奖励分数对这些样本进行排名。
最后,我们在上述基础模型上进行了说话人微调,使 Talker 能够采用特定的声音并提高其自然性。
5. 评估
我们对 Qwen2.5-Omni 进行了全面评估。该模型主要分为两大类:理解(X→Text)和语音生成(X→Speech)。
5.1 X→Text 的评估
在本节中,我们评估 Qwen2.5-Omni 对各种多模态输入(文本、音频、图像和视频)的理解能力,并生成文本响应。
5.1.1 文本→文本
我们对 Qwen2.5-Omni 在文本→文本方面的评估主要集中在一般评估、数学与科学能力以及编码能力上。具体来说,我们使用了以下基准测试:
-
一般评估:MMLU-Pro(Wang 等人,2024f)、MMLU-redux(Gemma 等人,2024)和 Livebench0803(White 等人,2024)。
-
数学与科学:GPQA(Rein 等人,2023)、GSM8K(Cobbe 等人,2021)和 MATH(Hendrycks 等人,2021b)。
-
编码能力:HumanEval(Chen 等人,2021)、MBPP(Austin 等人,2021)、MultiPL-E(Cassano 等人,2023)和 LiveCodeBench 2305-2409(Jain 等人,2024)。
5.1.2 音频→文本
我们对 Qwen2.5-Omni 在多种音频理解、音频推理和语音聊天基准测试中的性能进行了比较。如表 2 和表 3 所示,Qwen2.5-Omni 在音频理解方面与其他最新方法相比表现更好或相当。例如,在 Fleurs_zh、CommonVoice_en、CommonVoice_zh、CoVoST2_en-de 和 CoVoST2_zh-en 测试集上,它在自动语音识别(ASR)和语音到文本翻译(S2TT)方面优于之前的最新模型,如 Whisper-large-v3、Qwen2-Audio、MinMo 和其他 Omni 模型。Qwen2.5-Omni 在音乐和 VSC 等一般音频理解任务上也达到了最新水平。此外,Qwen2.5-Omni 在音频推理方面表现出色,在 MMAU 基准测试的声音、音乐和语音子集上取得了优异的成绩。这些结果证明了 Qwen2.5-Omni 在一般音频理解和推理方面的强大能力。
此外,在 VoiceBench 上,Qwen2.5-Omni 的平均得分达到了 74.12,超过了其他类似大小的音频语言模型和 Omni 模型。这展示了我们模型在语音交互方面的强大能力。为了进一步探索多样化语音交互的性能,我们将几个纯文本基准测试中的文本指令转换为语音,并对 Qwen2.5-Omni、Qwen2-Audio 和 Qwen2-7B 进行评估。大约使用了 90% 的文本指令。我们对 Qwen2.5-Omni 和 Qwen2-Audio 使用语音指令,对 Qwen2-7B 使用文本指令。如表 4 所示,与 Qwen2-Audio 相比,Qwen2.5-Omni 显著缩小了与使用文本指令的 Qwen2-7B 之间的差距。这反映了我们模型在多样化端到端语音交互方面的显著进步。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)