使用AI生成金融时间序列数据,解决A股市场数据稀缺问题
金融行业面临数据稀缺和低信噪比的挑战,限制了深度学习在股市分析中的应用。本文提出了两种基于生成模型的创新方法来合成中国A股市场的股票数据:**行业基础合成方法:**通过分类不同板块股票特征,利用近似非局部总变差算法平滑数据,傅里叶变换带通滤波去噪,和去噪扩散隐式模型加速采样。**基于模式识别的递归合成方法:**针对上市时间短和可比公司少的股票,利用模式识别和马尔可夫模型生成可变长度股票序列,并引入
“GENERATIVE MODELS FOR FINANCIAL TIME SERIES DATA: ENHANCING SIGNAL-TO-NOISE RATIO AND ADDRESSING DATA SCARCITY IN A-SHARE MARKET”

金融财务数据稀缺且质量低,限制了深度学习技术在金融行业的应用。数据隐私法规的实施使金融行业在数据获取和共享上面临困难,导致信息不对称和“数据孤岛”现象。
本研究提出两种合成股票数据的新方法,旨在提高信噪比并解决数据稀缺问题,特别是针对上市时间短和可比公司有限的股票。

论文地址:https://arxiv.org/pdf/2501.00063
摘要
金融行业面临数据稀缺和低信噪比的挑战,限制了深度学习在股市分析中的应用。本文提出了两种基于生成模型的创新方法来合成中国A股市场的股票数据:
-
**行业基础合成方法:**通过分类不同板块股票特征,利用近似非局部总变差算法平滑数据,傅里叶变换带通滤波去噪,和去噪扩散隐式模型加速采样。
-
**基于模式识别的递归合成方法:**针对上市时间短和可比公司少的股票,利用模式识别和马尔可夫模型生成可变长度股票序列,并引入子时间级别数据增强方法缓解数据稀缺问题。
在多个数据集(如主板、科创板、创业板、北京证券交易所、NASDAQ、NYSE、AMEX)上进行验证,结果显示合成数据提升了预测模型性能和个股信号的信噪比子时间级别数据显著提高了合成数据质量,尤其在可比公司有限和上市时间短的情况下。
本研究为金融数据合成领域提供了新工具和技术,支持金融分析和高频交易,深入理解A股市场的复杂动态。
简介
金融市场的价格和收益预测面临数据质量和数量的挑战,尤其是股票市场的信噪比低和数据同质性问题。数据隐私法规加剧了金融行业在数据获取和共享方面的困难,导致信息不对称和数据孤岛现象。
人工智能和深度学习模型为生成合成金融数据提供了创新解决方案,旨在提高数据多样性、保护隐私并增强预测准确性。金融数据分布具有尖峰厚尾、异方差性和波动聚集等特征,这些特征对理解市场动态至关重要。
本研究提出两种合成股票数据的新方法,旨在提高信噪比并解决数据稀缺问题,特别是针对上市时间短和可比公司有限的股票。
背景和相关工作
金融市场动态与数据稀缺
金融市场预测资产价格和回报至关重要,但市场的波动性和不可预测性使得准确预测具有挑战性。
财务数据稀缺且质量低,限制了深度学习技术在金融行业的应用,尤其是在股票市场中,信噪比低和数据同质性高影响模型构建。财务数据的敏感性和高价值使得数据泄露或恶意操控带来严重安全风险。
数据隐私法规的实施使金融行业在数据获取和共享上面临困难,导致信息不对称和“数据孤岛”现象。人工智能技术的探索旨在生成合成金融数据,以保持原始数据特征、增加数据多样性、保护隐私,并提升模型训练和预测准确性。
金融中的生成模型
生成模型(如VAE、GAN和扩散模型)在合成金融数据方面表现出色,能够模拟真实市场行为和客户交易模式。VAE通过概率编码和解码生成与训练数据相似的新数据实例。GAN通过生成器与判别器的竞争方法,革新了图像生成领域。扩散模型通过逐步逆转噪声注入过程,生成高质量样本。
金融数据生成中的挑战
生成模型在金融数据生成中的应用仍处于初级阶段,面临市场复杂性和动态性挑战。需要深入理解市场动态,结合深度生成模型与金融数据特征,以生成高质量的合成数据。现有模型多基于西方市场数据(如美国股市),未能充分考虑中国A股市场的独特规则和特征。不同市场的分布和监管差异可能导致合成数据不符合特定市场的规则和模式。
金融数据综合方法
各金融机构和学者提出了生成合成金融数据的框架,以在不泄露实体信息的情况下支持金融分析和研究。学术研究探索了不同的生成对抗网络(GAN)变体,以提高金融数据合成的性能,包括架构和损失函数的变体。生成模型在金融领域的研究仍在积极进行,具有开发更复杂合成数据生成方法的潜力,以增强金融模型和策略的预测能力。
基于分数的生成模型
金融市场动态与数据稀缺
Score-based Generative Models (SGMs) 是一种自监督机器学习方法,通过学习未知数据分布的得分函数来生成新样本。目标是最小化目标函数 L(θ),使用神经网络 sθ 近似得分 ∇x log p(x)。直接计算目标函数中的 tr(∇x sθ(x)) 需要大量计算资源,因此提出了去噪得分匹配(DSM)方法。
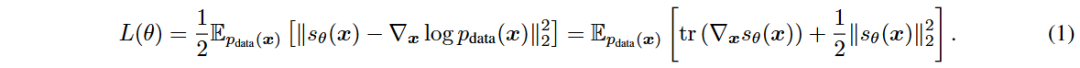
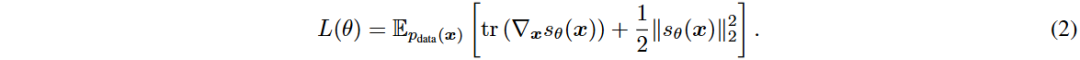
DSM 通过对数据添加噪声来估计扰动数据分布的得分,训练目标变为最小化新的目标函数。DSM 的训练目标在某些情况下等同于去噪自编码器(DAE)。
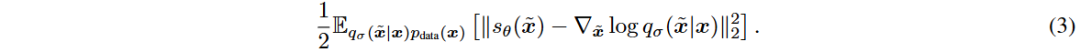
这些模型可以通过随机微分方程(SDEs)统一,提供了逐步添加和去除噪声的框架,便于设计和分析得分生成模型。
与朗格万动力学的分数匹配
SMLD过程包括两个部分:使用去噪声评分匹配估计扰动数据分布的评分,以及利用Langevin动态迭代从先验分布中采样。
Song等人提出通过多级噪声扰动数据,训练噪声条件评分网络(NCSN)来估计所有噪声水平的评分。扰动方法定义为:
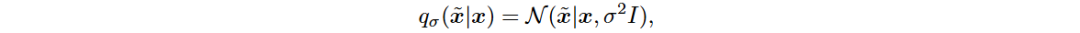
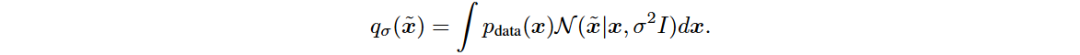
设定噪声序列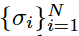 ,满足
,满足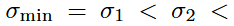
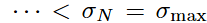 ,以使得
,以使得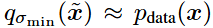 和
和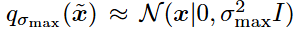 。
。
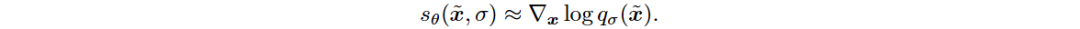
NCSN的训练目标是最小化加权去噪声评分匹配目标的损失函数。
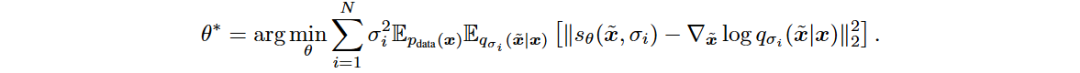
SMLD使用Langevin MCMC采样方法生成新数据样本,更新规则为:
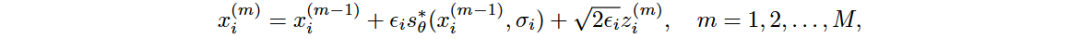
迭代从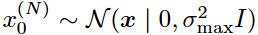 开始,最终在
开始,最终在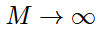 和
和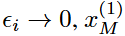 时,
时,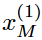 将成为
将成为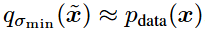 的精确样本。
的精确样本。
DDPM模型
Denoising Diffusion Probabilistic Model (DDPM)可视为一种分层马尔可夫变分自编码器。定义噪声序列 β 和 α,推导出条件分布 q(x_t | x_0) 和逆去噪过程。
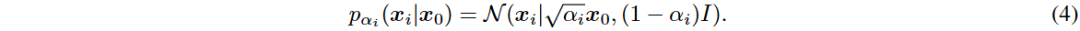
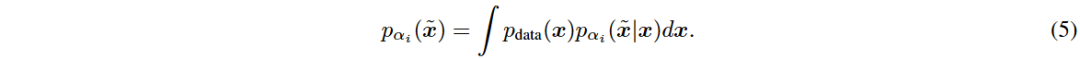
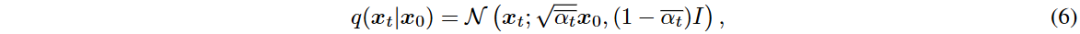
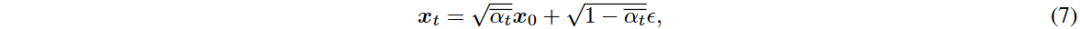
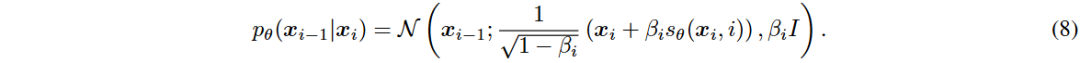
DDPM 的训练目标是最小化加权的证据下界 (ELBO) 损失函数。
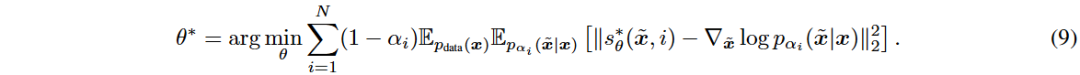
从随机微分方程的角度统一SMLD和DDPM
根据 Song 等人的研究,SMLD 和 DDPM 可以通过随机微分方程 (SDEs) 统一理解。
使用随机微分方程(SDE)描述前向扩散过程,包含漂移项f(x, t)和扩散项g(t)dw。反向过程同样用SDE表示,逐步去噪生成样本x0,接近真实数据分布p0。通过训练得分网络sθ(x, t)来估计∇x log pt(x),目标函数包含正权重函数λ和均匀分布t。
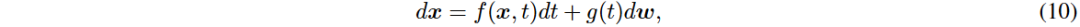
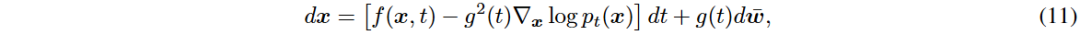
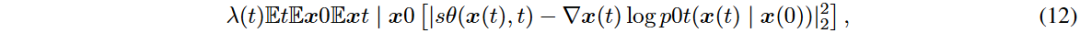
DDPM可视为连续时间SDE的离散形式,离散前向过程和连续形式分别为xi和dx。
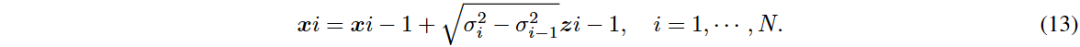
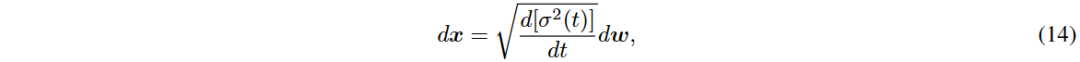
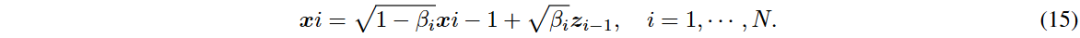
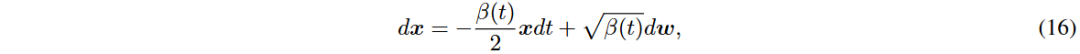
VE-SDE中f(x, t)=0,g(t)=q d[σ²(t)] dt。VP-SDE中f(x, t)=-β(t)²x,g(t)=pβ(t)。通过替换f(x, t)和g(t)可获得SMLD或DDPM的反向过程SDE形式。
方法
本研究提出CS-Diffusion方法,利用扩散模型合成A股数据,增加数据点。该方法旨在缓解数据稀缺,提升股票潜在回报率预测的准确性。
基于A股市场板块类型的训练方法
问题定义
输入时间序列x和条件c均为特定长度,经过模型处理后得到去噪时间序列xˆ。
训练阶段
在训练阶段,采用随机噪声水平(t ∼ U(0, T))对输入数据进行前向扩散处理,最大噪声水平由T控制,T=1为最大噪声。训练条件扩散模型时,使用无分类器引导方法,结合条件模型和无条件模型,避免额外分类器的训练。引入两种正交条件数据:股票对应的申万二级行业和板块信息,以增强模型的条件生成能力,解决中国股市波动规则未考虑的问题。申万二级行业有124个类别,A股市场分为5个板块,使用嵌入层和独热编码生成条件向量c。
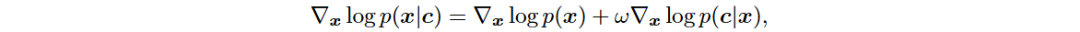
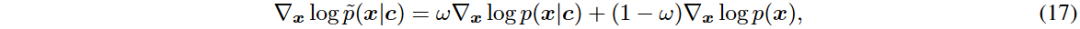

现有抽样方法的改进
去噪过程
在去噪过程中,从x_t中减去噪声以恢复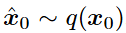 。使用神经网络参数化
。使用神经网络参数化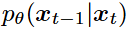 来估计
来估计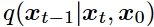 。
。
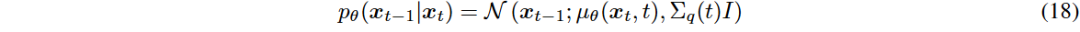
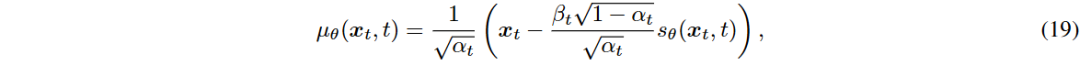
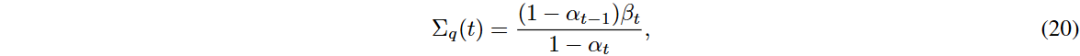
是用于预测扩散过程中的噪声的可训练项。
加速抽样
传统扩散概率模型生成高质量样本,但采样速度慢,通常需要数千个时间步。DDIM提出加速采样的新方法,通过隐式建模条件分布实现更高效的去噪。DDIM结合确定性和随机性,减少所需的扩散步骤T,同时保持样本质量。
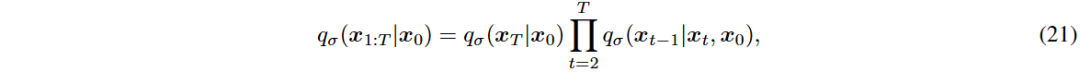
DDIM修改前向过程为非马尔可夫过程,加速采样,σ参数控制随机过程的幅度。当σ_t=0时,去噪过程变为确定性,沿确定路径加速。DDIM采样可在T’≪T的步骤内完成去噪。
近似非局部总变差损失
在时间序列数据生成中,控制生成序列的方差同时保持整体趋势和特征是一大挑战。传统的局部方法(如全变差TV正则化)可能导致不自然的块效应或过度平滑。提出了一种基于Liu等人非局部全变差(NTV)方法的近似非局部全变差(ANTV)损失,旨在捕捉时间序列的全局结构。

ANTV方法通过考虑局部窗口内的数据点的非局部依赖关系,降低计算复杂度。ANTV损失函数中,α为正则化参数,x为时间序列数据,w(i)为局部窗口,ω(i, j)为测量相似性的权重函数,采用高斯核表示。算法步骤包括在每次去噪后计算非局部梯度并更新x_i,以减少方差并保持序列一致性,特别适用于A股市场的生成序列。
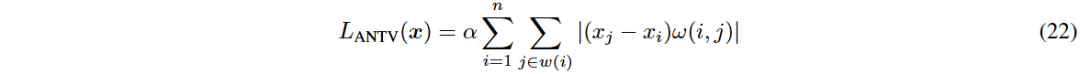
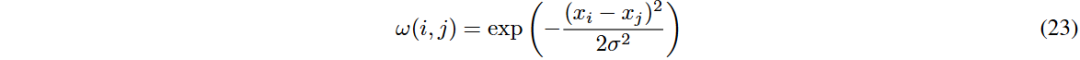
傅里叶变换滤波的应用场景
北京证券交易所(BSE)因历史数据有限,面临模型训练挑战。可采用迁移学习方法,利用成熟市场(如上海、深圳证券交易所)的数据进行预训练。通过逐步添加噪声和应用带通滤波损失(Bandpass Filter Loss)生成合成数据。带通滤波损失旨在使信号的频域特征与目标一致,保留特定频率范围内的有用信息。
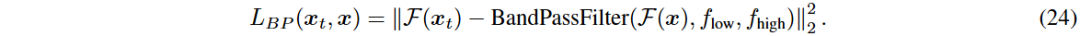
采样算法总结
使用条件扩散模型的采样过程结合DDIM采样和损失函数优化生成高质量数据。初始化生成数据数量m、采样步数T’和条件向量c,准备空列表存储结果。随机从高斯分布N(0, I)中采样初始噪声x T’,从t=T’逐步更新x t−1至t=0。在每个时间步应用近似非局部全变差损失和带通滤波损失,增强时间序列数据的结构一致性和频率特征。
完成采样后,将最终生成的x 0添加至结果列表,达到m后计算均值作为最终输出x ˆ。该算法高效生成高质量时间序列数据,并通过条件向量c适应目标领域特征。
实验
实验设置
通过实验验证以下问题:
-
验证基于扩散模型合成的股票时间序列数据是否提高信噪比。
-
检验基于扩散模型合成的股票时间序列数据在交易中的盈利能力。
-
评估提出的基于行业的股票数据合成方法是否能缓解数据稀缺问题。
数据集
数据来源于RiceQuant,涵盖2014年1月1日至2024年6月1日的A股日频数据,包含主板、创业板、科创板和北京证券交易所的公司。股票分类依据:30开头为创业板,002为中小板,60为上海主板,000为深圳主板,688为科创板,83/87/88为北京证券交易所。使用Wind终端的申万二级行业分类,确保行业属性的准确性。
采用60天滑动窗口,步长20,数据集按4:1比例分为训练集和测试集。对于停牌股票,短期停牌用线性插值填补,长期停牌用前向填充,频繁停牌的股票数据将被移除。新上市股票初期因价格波动大不纳入数据,避免异常波动影响模型。
对所有股票进行前向权利处理,消除股息和配股对价格的影响,确保历史价格的可比性。行业变更时,统一使用最新的申万行业信息,反映最新业务情况。
通过以上预处理步骤,确保数据的完整性和一致性,提高模型的训练效果和预测准确性。
评估指标
回报率(RR):股票预测的主要目标是实现显著利润。
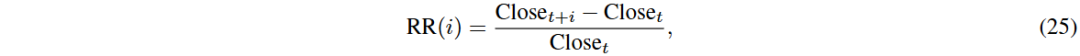
对数收益率(LR):金融数据分析中的常用指标,反映价格变化的比例,具有可加性和近似正态分布的特性。
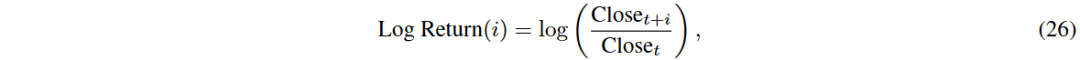
信息系数(IC):用于评估预测值与真实标签之间的线性相关性。
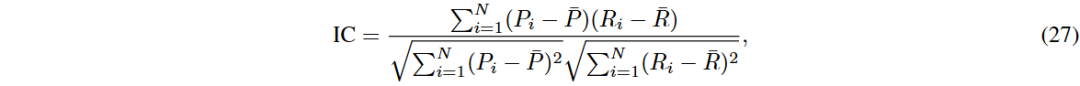
排名信息系数(Rank IC):用于评估预测值与真实标签之间的排名相关性。
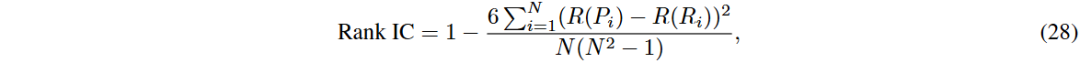
实现细节
使用Gao等人提出的DiffsFormer,基于Transformer的神经网络sθ(x, t, c)估计噪声。输入为时间序列x,条件信息c和正弦嵌入时间t。条件嵌入网络为3层MLP,隐藏层维度128,激活函数为SiLU。扩散模型网络为Transformer架构,卷积层输出通道64,8个注意力头,4个残差块,激活函数为ReLU。去噪步骤总数设为400。近似非局部总变差系数λANTV设为0.03,傅里叶变换过滤系数λBP设为0.03,分类器无关引导尺度ω设为7.5。
基线
-
MLP:2层256单元的多层感知器,用于股票价格预测。
-
LSTM:基于长短期记忆网络,适合处理时间序列的长期依赖。
-
GRU:门控循环单元,简化版LSTM,结构更简单,参数更少。
-
SFM:状态频率记忆网络,分解记忆单元的隐藏状态以建模交易模式。
-
ALSTM:改进的LSTM,加入时间注意力聚合层,增强对不同时间信息的关注。
-
Transformer:基于Transformer架构,利用自注意力机制捕捉长距离依赖,适合复杂时间序列。
-
HIST:图基框架,挖掘预定义和隐含概念的共享信息,实现更全面的特征表示。
实验结果
基于板块类型的股票数据合成方法在A股数据上训练,针对主板、科创板、创业板和北京证券交易所进行数据增强,采用“top20drop20”策略进行模拟交易。
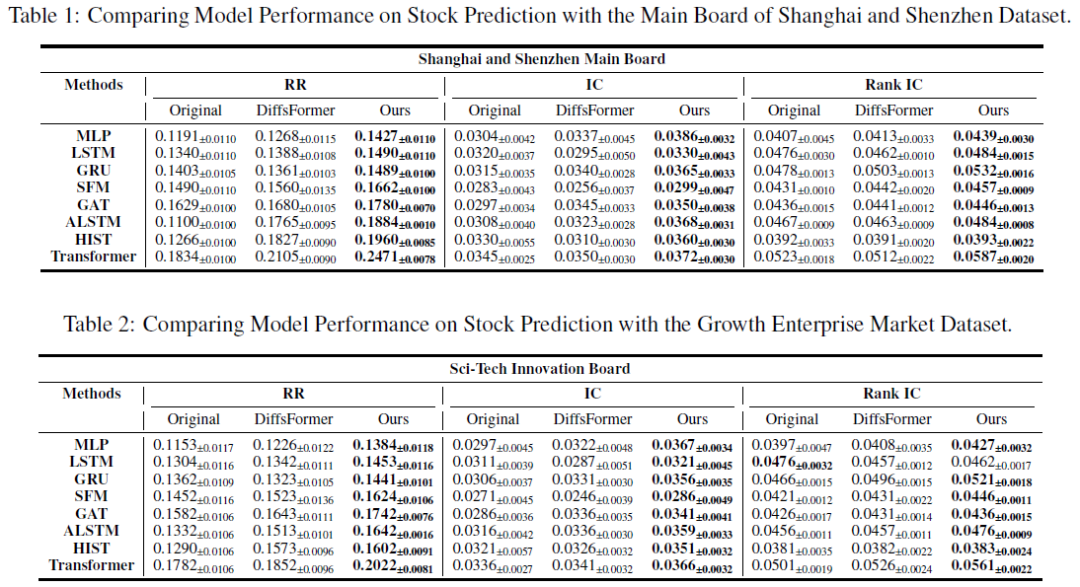
实验结果显示,所提方法在RR、IC和Rank IC指标上显著优于Original和DiffsFormer,表明预测准确性和稳定性提升。在低信噪比环境下,ALSTM和HIST等模型的预测性能显著改善,说明该方法增强了原始股票数据的信噪比。
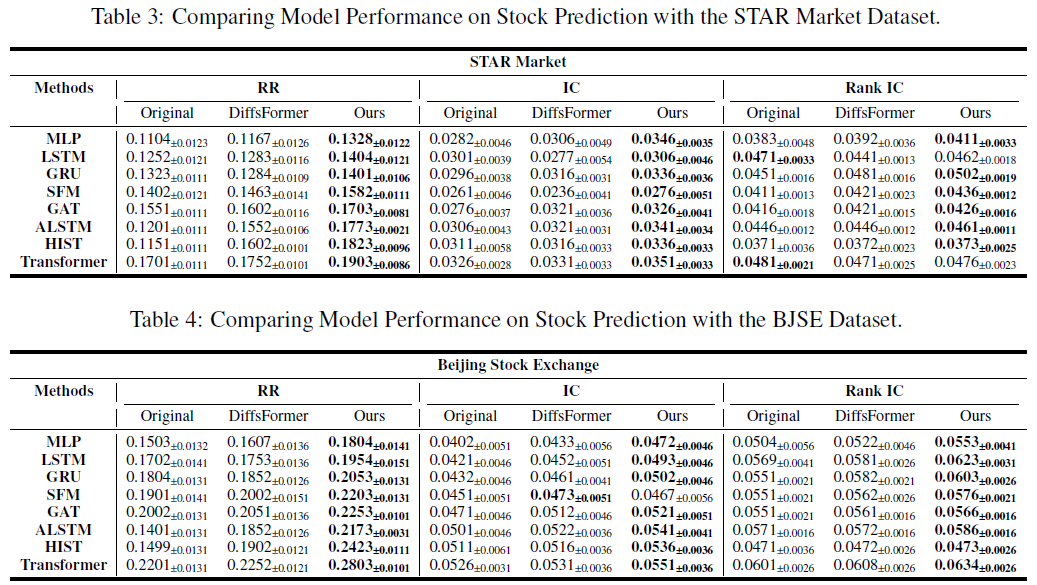
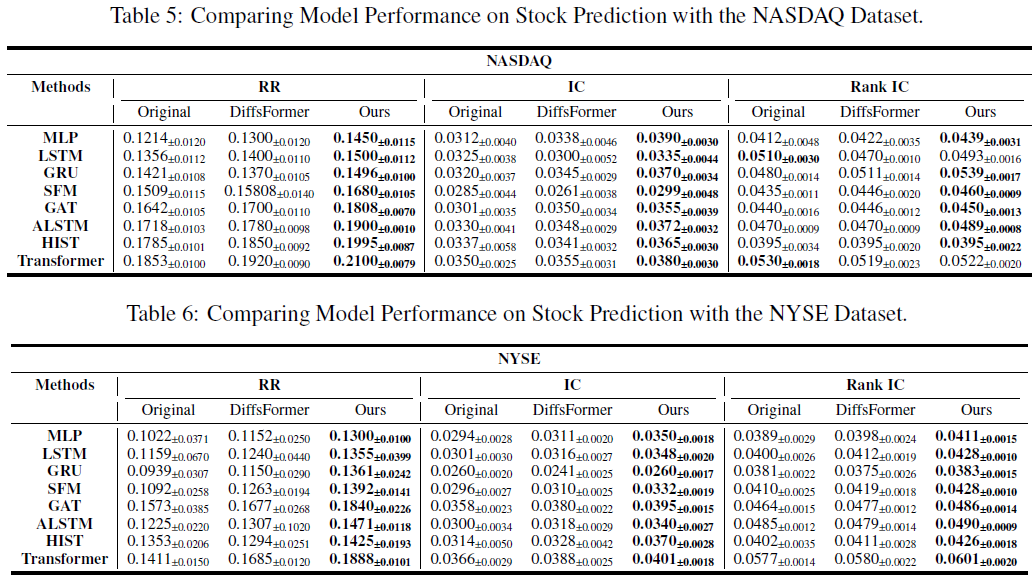
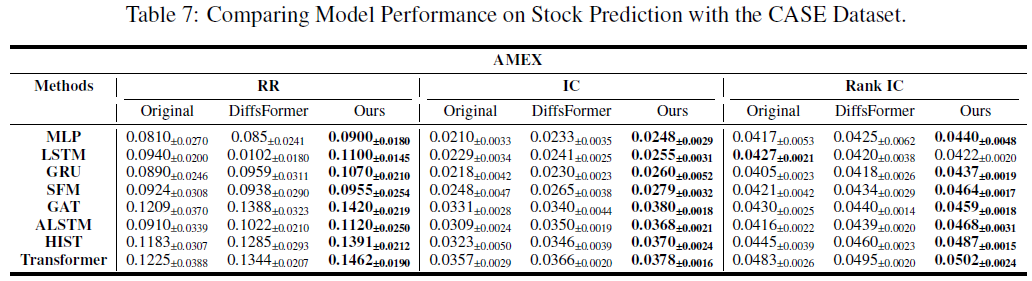
在美国股市(NYSE、NASDAQ、AMEX)上进行相同实验,结果显示方法同样有效,提升了8.34。中国A股市场短线机制有限,主要由机构投资者参与,而美国市场则允许零售投资者灵活做空。实验设计假设所有市场参与者均可顺利做空,以消除不同市场短线机制对结果的影响。
总结
本文提出的基于板块类型的股票数据合成方法在多个市场(主板、创业板、科创板、北京证券交易所)上表现优于现有算法,提升了预测准确性和稳定性。方法显著改善了股票数据的信噪比,增强了ALSTM和HIST模型在低信噪比环境下的表现。方法在美国股市(NYSE、NASDAQ、AMEX)同样有效,显示出广泛的适用性和鲁棒性。未来将进一步优化模型并探索其在其他金融市场的应用。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 14
14 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)