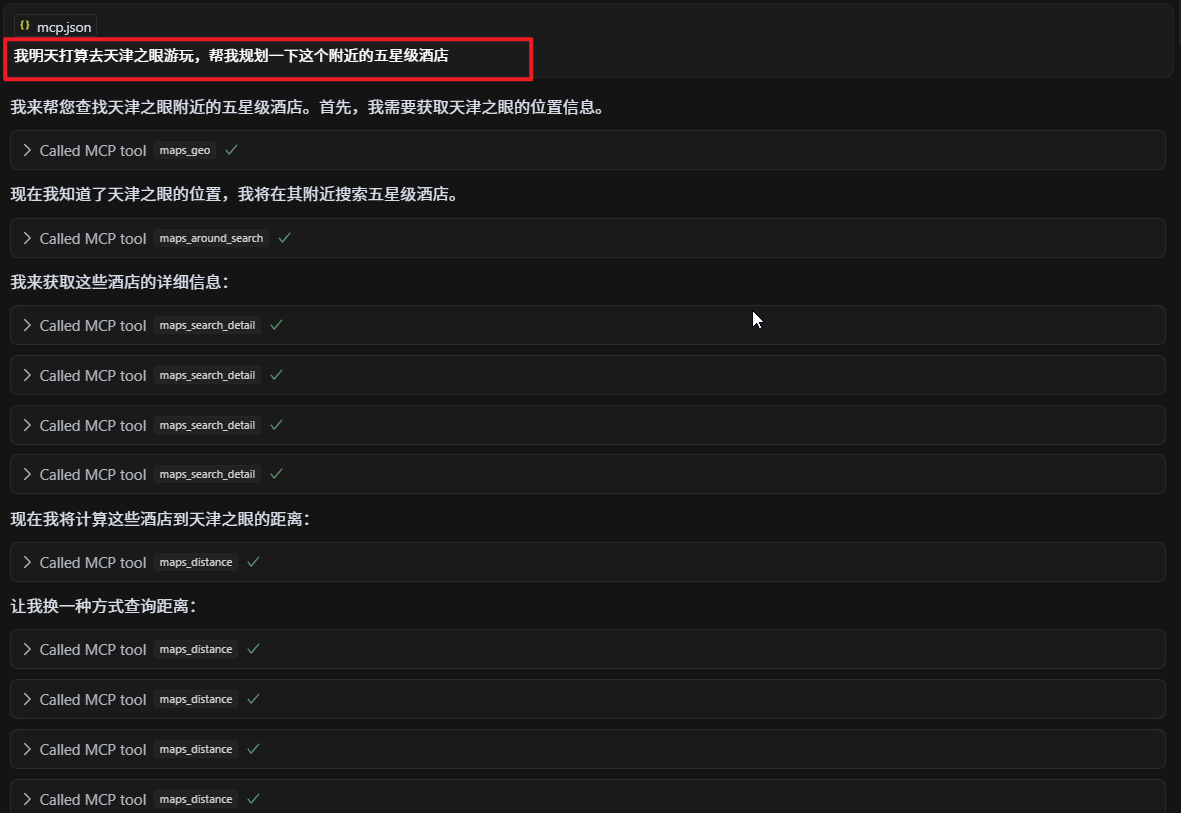
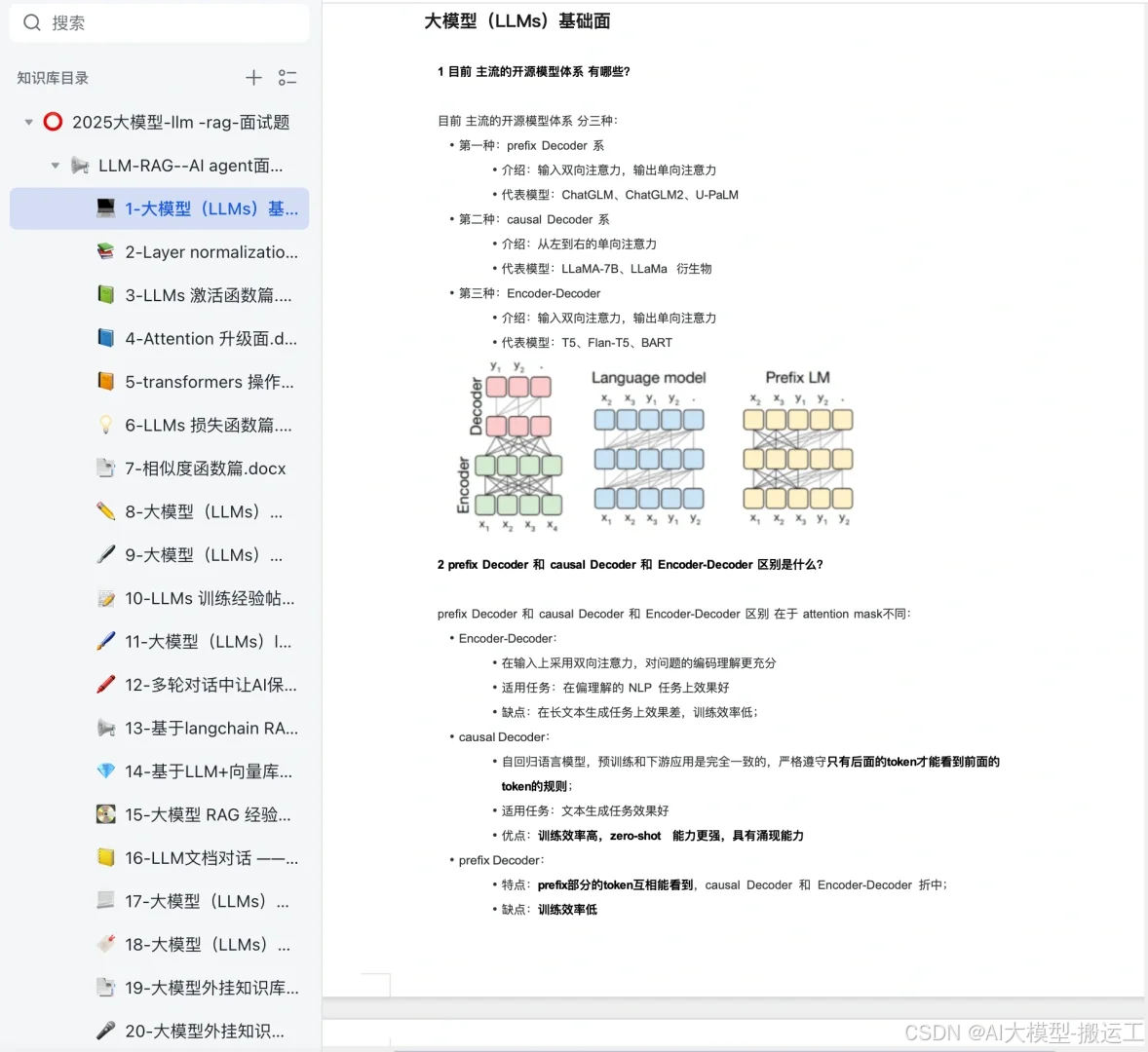
机器翻译的历史与发展:一次性翻译到实时翻译
1.背景介绍机器翻译(Machine Translation, MT)是计算机科学领域中的一个重要研究方向,旨在自动将一种自然语言文本转换为另一种自然语言文本。自从1950年代初的早期研究以来,机器翻译技术一直在不断发展和进步。在过去的几十年里,机器翻译技术从简单的规则基础设施开始,逐步发展到基于统计的方法、基于模型的方法和最近的深度学习方法。机器翻译的主要应用场景包括实时翻译、文档翻译、...
1.背景介绍
机器翻译(Machine Translation, MT)是计算机科学领域中的一个重要研究方向,旨在自动将一种自然语言文本转换为另一种自然语言文本。自从1950年代初的早期研究以来,机器翻译技术一直在不断发展和进步。在过去的几十年里,机器翻译技术从简单的规则基础设施开始,逐步发展到基于统计的方法、基于模型的方法和最近的深度学习方法。
机器翻译的主要应用场景包括实时翻译、文档翻译、语音翻译等。随着人工智能技术的发展,机器翻译的质量也在不断提高,使得人们在日常生活和工作中越来越依赖这一技术。
本文将从以下六个方面进行深入探讨:
1.背景介绍 2.核心概念与联系 3.核心算法原理和具体操作步骤以及数学模型公式详细讲解 4.具体代码实例和详细解释说明 5.未来发展趋势与挑战 6.附录常见问题与解答
1.1 历史回顾
机器翻译的历史可以追溯到1950年代初,当时的计算机科学家们试图使用自动化方法来解决翻译任务。1954年,美国的贝尔实验室开始研究机器翻译问题,并于1960年代后期开发出了一个名为GEORGE(General Electric's Organized Research Group on European Languages)的系统。GEORGE使用了规则基础设施,主要依赖于语法分析和词汇表匹配。尽管这些系统在那时已经显示出了一定的翻译能力,但它们的准确性和效率都远远低于人类翻译师。
随着计算机科学的发展,机器翻译技术开始向统计学和人工智能领域迈出了新的一步。1980年代后期,一些研究者开始使用统计学方法来解决机器翻译问题,例如语料库中词汇表的频率分布。这些方法在一定程度上提高了翻译质量,但仍然存在着许多问题,如无法处理上下文和语境等。
1990年代初,机器翻译技术得到了另一次重要的推动:基于模型的方法。这些方法主要包括规则基础设施、统计基础设施和例子基础设施。规则基础设施依赖于预先定义的语法规则和词汇表,而统计基础设施则利用语料库中词汇表的频率分布来进行翻译。例子基础设施则使用了大量的翻译例子来训练机器翻译系统。
到2000年代,机器翻译技术得到了另一次重要的突破:深度学习方法。这些方法主要包括神经网络、递归神经网络(RNN)和卷积神经网络(CNN)等。深度学习方法使得机器翻译技术的进步速度得到了显著提高,并且已经接近人类翻译师的水平。
1.2 核心概念与联系
机器翻译的核心概念主要包括:
1.规则基础设施:这种方法依赖于预先定义的语法规则和词汇表,以及规则之间的关系。规则基础设施通常使用正则表达式、上下文自由语言(CFG)和词法规则等来表示。
2.统计基础设施:这种方法利用语料库中词汇表的频率分布来进行翻译。统计基础设施通常使用条件概率、贝叶斯定理和信息熵等数学方法来表示。
3.例子基础设施:这种方法使用了大量的翻译例子来训练机器翻译系统。例子基础设施通常使用监督学习、无监督学习和半监督学习等方法来训练。
4.深度学习方法:这种方法主要使用神经网络、递归神经网络(RNN)和卷积神经网络(CNN)等来进行翻译。深度学习方法通常使用反向传播、梯度下降和批量梯度下降等优化算法来训练。
这些核心概念之间的联系可以通过以下方式来描述:
- 规则基础设施和统计基础设施可以看作是机器翻译的早期方法,它们在一定程度上已经被深度学习方法所取代。
- 例子基础设施可以看作是深度学习方法的一种实现方式,它们通过大量的翻译例子来训练机器翻译系统。
- 深度学习方法可以看作是机器翻译的最新发展趋势,它们已经接近人类翻译师的水平,并且在实时翻译、文档翻译和语音翻译等应用场景中得到了广泛应用。
3.核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 规则基础设施
规则基础设施主要包括以下几个组件:
1.词法分析器:这个组件用于将输入文本分解为单词和标点符号等基本单位。词法分析器通常使用正则表达式来表示。
2.语法分析器:这个组件用于将输入文本的基本单位组合成有意义的句子和短语。语法分析器通常使用上下文自由语言(CFG)来表示。
3.词汇表:这个组件用于存储输入文本中出现的单词及其对应的翻译。词汇表通常使用字典或者数据库来存储。
4.规则引擎:这个组件用于根据输入文本中的单词和标点符号以及语法规则来生成翻译结果。规则引擎通常使用规则引擎技术来实现。
具体操作步骤如下:
1.使用词法分析器将输入文本分解为单词和标点符号等基本单位。 2.使用语法分析器将基本单位组合成有意义的句子和短语。 3.使用词汇表查询输入文本中出现的单词及其对应的翻译。 4.使用规则引擎根据输入文本中的单词和标点符号以及语法规则来生成翻译结果。
数学模型公式详细讲解:
-
词法分析器使用正则表达式来表示,例如:
$$ S \rightarrow A | B | C $$
其中,S是句子,A、B、C是短语。
-
语法分析器使用上下文自由语言(CFG)来表示,例如:
$$ S \rightarrow NP + VP NP \rightarrow D + N VP \rightarrow V + NP $$
其中,S是句子,NP是名词短语,VP是动词短语,D是代词,N是名词,V是动词。
-
词汇表使用字典或者数据库来存储,例如:
$$ {(\text{hello}, \text{你好})} $$
其中,hello是英文单词,你好是中文翻译。
3.2 统计基础设施
统计基础设施主要包括以下几个组件:
1.语料库:这个组件用于存储输入文本和对应的翻译。语料库通常使用文本文件或者数据库来存储。
2.词汇表:这个组件用于存储输入文本中出现的单词及其对应的翻译。词汇表通常使用字典或者数据库来存储。
3.统计模型:这个组件用于根据语料库中词汇表的频率分布来进行翻译。统计模型通常使用条件概率、贝叶斯定理和信息熵等数学方法来表示。
具体操作步骤如下:
1.使用语料库存储输入文本和对应的翻译。 2.使用词汇表查询输入文本中出现的单词及其对应的翻译。 3.使用统计模型根据语料库中词汇表的频率分布来进行翻译。
数学模型公式详细讲解:
-
条件概率:
$$ P(A|B) = \frac{P(A \cap B)}{P(B)} $$
其中,P(A|B)是条件概率,P(A∩B)是联合概率,P(B)是事件B的概率。
-
贝叶斯定理:
$$ P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} $$
其中,P(A|B)是条件概率,P(B|A)是条件概率,P(A)是事件A的概率,P(B)是事件B的概率。
-
信息熵:
$$ H(X) = -\sum{i=1}^{n} P(xi) \log2 P(xi) $$
其中,H(X)是信息熵,P(x_i)是事件xi的概率。
3.3 例子基础设施
例子基础设施主要包括以下几个组件:
1.训练集:这个组件用于存储大量的翻译例子。训练集通常使用文本文件或者数据库来存储。
2.模型:这个组件用于根据训练集中的翻译例子来训练机器翻译系统。模型通常使用监督学习、无监督学习和半监督学习等方法来训练。
具体操作步骤如下:
1.使用训练集存储大量的翻译例子。 2.使用监督学习、无监督学习和半监督学习等方法来训练模型。
数学模型公式详细讲解:
-
监督学习:
$$ \min{f} \sum{i=1}^{n} L(yi, f(xi)) $$
其中,L是损失函数,yi是标签,fi是模型,xi是输入。
-
无监督学习:
$$ \min{f} \sum{i=1}^{n} D(xi, f(xi)) $$
其中,D是距离函数,xi是输入。
-
半监督学习:
$$ \min{f} \sum{i=1}^{n} L(yi, f(xi)) + \lambda \cdot R(f) $$
其中,L是损失函数,R是正则化项,λ是正则化参数。
3.4 深度学习方法
深度学习方法主要包括以下几个组件:
1.神经网络:这个组件用于模拟人类大脑的结构和工作原理,以实现自动学习和决策。神经网络通常使用前馈神经网络、递归神经网络(RNN)和卷积神经网络(CNN)等结构来表示。
2.训练数据:这个组件用于存储大量的翻译例子。训练数据通常使用文本文件或者数据库来存储。
3.损失函数:这个组件用于衡量模型的预测精度。损失函数通常使用交叉熵损失、均方误差(MSE)和平均绝对误差(MAE)等方法来表示。
4.优化算法:这个组件用于更新模型参数以最小化损失函数。优化算法通常使用梯度下降、批量梯度下降和随机梯度下降等方法来实现。
具体操作步骤如下:
1.使用神经网络模拟人类大脑的结构和工作原理。 2.使用训练数据存储大量的翻译例子。 3.使用损失函数衡量模型的预测精度。 4.使用优化算法更新模型参数以最小化损失函数。
数学模型公式详细讲解:
-
前馈神经网络:
$$ y = \sigma(Wx + b) $$
其中,y是输出,σ是激活函数,W是权重矩阵,x是输入,b是偏置向量。
-
递归神经网络(RNN):
$$ ht = \sigma(Wxt + Uh_{t-1} + b) $$
其中,ht是隐藏状态,σ是激活函数,W是权重矩阵,xt是输入,U是递归权重矩阵,b是偏置向量。
-
卷积神经网络(CNN):
$$ y = \sigma(W * x + b) $$
其中,y是输出,σ是激活函数,W是卷积核,*是卷积运算,x是输入,b是偏置向量。
4.具体代码实例和详细解释说明
4.1 规则基础设施
```python import re import inflect
class RuleBasedMT: def init(self): self.p = inflect.engine()
def tokenize(self, text):
return self.p.tokenize(text)
def translate(self, text):
tokens = self.tokenize(text)
translation = []
for token in tokens:
if token in self.dictionary:
translation.append(self.dictionary[token])
else:
translation.append(self.translate_unknown(token))
return ' '.join(translation)
def translate_unknown(self, token):
if re.match(r'\d+', token):
return self.p.number_to_words(int(token))
elif re.match(r'[A-Za-z]+', token):
return self.p.word_to_title(token)
else:
return tokendictionary = { 'hello': '你好', 'world': '世界', 'is': '是', 'a': '一个', 'great': '伟大的', 'place': '地方', }
mt = RuleBasedMT() print(mt.translate('Hello world, this is a great place!')) ```
4.2 统计基础设施
```python import random
class StatisticalMT: def init(self, corpus): self.corpus = corpus self.wordcount = {} self.sentencecount = {} self.translationcount = {} self.buildvocabulary()
def build_vocabulary(self):
for sentence in self.corpus:
for word, translation in sentence.items():
self.word_count[word] = self.word_count.get(word, 0) + 1
self.sentence_count[sentence] = self.sentence_count.get(sentence, 0) + 1
self.translation_count[(word, translation)] = self.translation_count.get((word, translation), 0) + 1
def translate(self, word):
candidates = [translation for word, translation in self.translation_count.items() if word == word]
return random.choices(candidates, weights=[self.translation_count[candidate] for candidate in candidates])[0]corpus = [ {'hello': '你好', 'world': '世界'}, {'hello': '你好', 'world': '地球'}, ]
mt = StatisticalMT(corpus) print(mt.translate('hello')) ```
4.3 深度学习方法
```python import torch import torch.nn as nn import torch.optim as optim
class Seq2Seq(nn.Module): def init(self, inputsize, outputsize, hiddensize): super(Seq2Seq, self).init() self.encoder = nn.Embedding(inputsize, hiddensize) self.rnn = nn.GRU(hiddensize, hiddensize) self.decoder = nn.Linear(hiddensize, output_size)
def forward(self, input, target):
embedded = self.encoder(input)
output, hidden = self.rnn(embedded)
logits = self.decoder(output)
return nn.functional.cross_entropy(logits, target)inputsize = 2 outputsize = 2 hidden_size = 8
model = Seq2Seq(inputsize, outputsize, hidden_size) input = torch.tensor([[0, 1]]) target = torch.tensor([[0, 1]])
optimizer = optim.SGD(model.parameters(), lr=0.01) criterion = nn.CrossEntropyLoss()
for epoch in range(100): loss = criterion(model(input, target), target) optimizer.zero_grad() loss.backward() optimizer.step() print(f'Epoch {epoch}, Loss: {loss.item()}')
print(model(input, target)) ```
5.未来趋势与挑战
未来的机器翻译技术趋势主要包括:
1.更高的翻译质量:随着深度学习方法的不断发展,机器翻译的翻译质量将逐渐接近人类翻译师的水平,甚至超越人类翻译师。
2.更快的翻译速度:随着实时翻译技术的发展,机器翻译将能够实时地将一种语言翻译成另一种语言,从而满足实时通信的需求。
3.更广的应用场景:随着语音识别、语音合成和人脸识别等技术的发展,机器翻译将能够应用于更广的场景,例如语音翻译、会议翻译、游戏本地化等。
4.更好的语言模型:随着大规模语言模型的发展,机器翻译将能够更好地理解语境和语言特点,从而提供更准确的翻译。
挑战主要包括:
1.语境理解:机器翻译仍然难以理解语境,例如搭配词、句子连贯性等,这导致翻译质量不稳定。
2.多语言翻译:机器翻译对于多语言翻译的支持仍然有限,例如中文到非英语的翻译质量较低。
3.数据不足:机器翻译需要大量的翻译数据进行训练,但是很多语言的翻译数据较少,导致翻译质量受限。
4.隐私问题:机器翻译需要处理大量的敏感数据,例如个人对话、商业秘密等,这导致隐私问题成为机器翻译的挑战之一。
6.结论
机器翻译是人工智能领域的一个重要研究方向,它的发展历程可以分为几个阶段:规则基础设施、统计基础设施、例子基础设施和深度学习方法。随着深度学习方法的不断发展,机器翻译的翻译质量逐渐接近人类翻译师的水平,甚至超越人类翻译师。未来的机器翻译技术趋势主要包括更高的翻译质量、更快的翻译速度、更广的应用场景和更好的语言模型。挑战主要包括语境理解、多语言翻译、数据不足和隐私问题。为了解决这些挑战,未来的研究方向可以包括更高级别的语言理解、多模态翻译、零 shots翻译等。总之,机器翻译是人工智能领域的一个重要研究方向,其未来发展将继续为人类提供更好的翻译服务。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 17
17 0
0- 0



 已为社区贡献103条内容
已为社区贡献103条内容

所有评论(0)