毕业设计:基于YOLO模型的乒乓球检测算法研究 深度学习
乒乓球的自动检测与跟踪技术,基于深度学习和计算机视觉算法,构建一个高效的乒乓球检测系统。首先,采用YOLO(You Only Look Once)模型进行乒乓球的实时检测,通过对比赛视频数据集进行训练和测试,优化检测精度和速度。其次,结合光流法和卡尔曼滤波等技术,实现乒乓球的运动轨迹跟踪与分析。最后,通过实验验证,系统能够在不同光照条件和背景下准确检测乒乓球,并实时输出运动状态信息。研究成果为乒乓
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于YOLO模型的乒乓球检测算法研究
项目背景
随着科技的发展,计算机视觉和深度学习技术的应用逐渐渗透到体育领域,尤其是在乒乓球等快速反应的运动项目中,实现对比赛过程的实时分析和判断显得尤为重要。乒乓球检测技术不仅可以提高比赛的公平性和观赏性,还有助于教练和运动员进行数据分析与训练指导。通过准确检测乒乓球的位置、速度和轨迹,能够为运动员提供更科学的训练方案,并推动乒乓球技术和战术的发展。
数据集
图像采集可以选择自主拍摄和互联网获取两种方式。自主拍摄可以通过设置相机在乒乓球比赛中捕捉实时画面,保证数据的多样性和真实性;而互联网采集则可以利用公开的体育视频资源,截取包含乒乓球的关键帧,以丰富数据源。使用标注工具(如LabelImg)对采集的图像进行标注,为每个乒乓球的位置信息生成对应的标注文件。标注文件通常以YOLO格式存储,包含每个乒乓球的类别和边界框坐标。在标注过程中,需确保标注的准确性,以便后续模型训练时能够有效捕捉乒乓球的特征。

数据集的划分与扩展也是提升模型性能的重要环节。将数据集划分为训练集、验证集和测试集,通常按照8:1:1的比例进行划分,以确保模型在不同数据集上的泛化能力。同时,通过数据扩展技术(如旋转、翻转、调整亮度等),增加样本的多样性,从而提升模型对不同场景和条件下乒乓球的检测能力。这种综合方法为构建高质量的乒乓球检测模型奠定了坚实的基础。
设计思路
卷积神经网络的基本结构包括输入层、卷积层、池化层、全连接层和输出层:
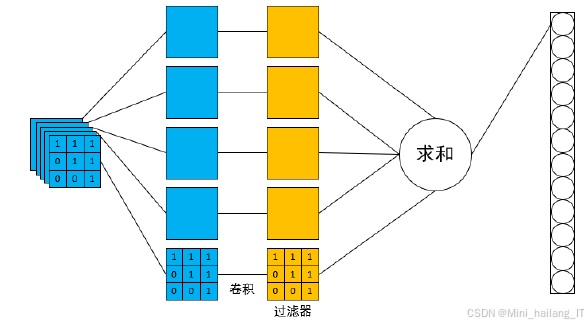
卷积层的设计涉及卷积核的步长和边缘填充。步长定义了滤波器在图像上的移动间隔,较大的步长可减小输出特征图尺寸。填充则是在输入图像边缘添加额外像素(通常为零),以调整输出特征图的大小。池化层在卷积神经网络中同样重要,其主要功能是减小特征图的空间维度,同时保留关键特征。这一层位于卷积层之后,通过滑动窗口在输入特征图上应用聚合函数,缩减特征图尺寸。常见的池化方法包括最大池化和平均池化,其中最大池化因在保持特征显著部分方面的优势而更为常用。

全连接层在卷积神经网络中扮演重要角色,尤其在执行分类任务时。该层关键参数包括输入特征维度、输出向量大小及是否包含偏置项。全连接层中的权重矩阵是核心元素,通过反向传播算法更新以降低损失函数值,从而提高分类准确度。
YOLOv8模型在目标检测速度和精度方面表现出色,根据规模和计算复杂度被细分为不同网络结构。YOLOv8的检测架构主要包含四个核心部分:输入层、主干网络、颈部网络和头部网络。输入层负责接收待分析图像,主干网络由多个卷积-批量归一化-激活函数组合和残差结构构成,主要用于深度特征提取。颈部层利用上采样和拼接技术,结合SPPF模块,提升特征图的尺寸适应性和特征整合能力。输出层通过不同分辨率的检测器完成目标的识别与定位。
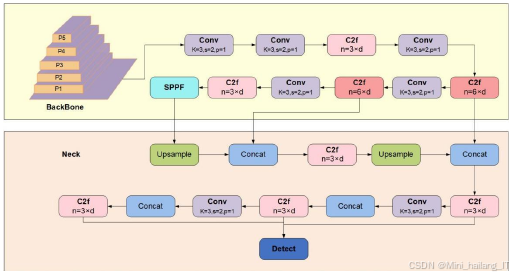
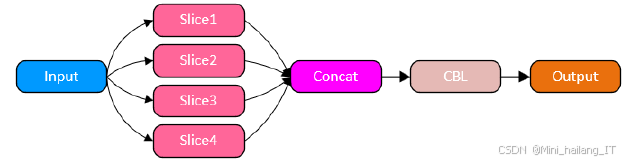
输入阶段的核心作用是接收原始图像数据并进行初步处理,智能调整图像尺寸以符合模型要求,并通过Mosaic数据增强技术提升模型的泛化性和鲁棒性。主干网络层的主要功能是特征提取,涵盖多个子模块,特别是Focus模块通过重排和下采样输入图像像素,减少计算负担并增强对细节的捕捉,提升模型对小尺寸特征的识别能力。
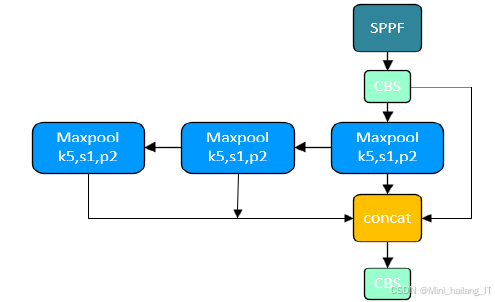
YOLOv8的架构中,C3模块被C2f模块替代,后者在C3基础上增加了跳跃连接和Split操作,丰富了模型的梯度流动,实现多层特征的轻量级融合。SPPF模块对传统SPP结构进行创新性改良,通过串联小型卷积核替代大型卷积核,显著减轻网络负担,提高检测效率。颈部结构的重要任务是整合来自不同层级的特征图,通过深层特征的语义信息和浅层特征的空间信息融合,提升模型对不同尺寸目标的检测准确度。
YOLOv8n模型主要使用3×3的卷积操作进行特征提取,导致模型参数和计算量较大。此外,YOLOv8n的主干网络为增大感受视野,主要依赖大量卷积操作扩展通道数,这需要较高的参数和计算成本,不利于实时检测乒乓球的行为。融合GhostConv对YOLOv8n的主干网络进行轻量化优化。GhostConv的核心思想是用较少的基础卷积核生成特征图,然后通过一些廉价操作产生额外的Ghost特征图,从而在不显著增加计算负担的前提下扩充模型的表达能力。
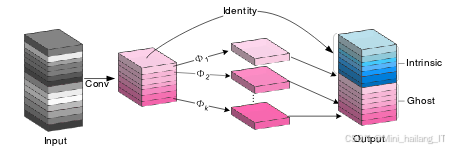
GhostBottleneck是借助GhostConv设计的轻量化结构,主要包括步长为1和步长为2的两种形式。步长为1的GhostBottleneck结构由两个1×1的GhostConv组成,第一个GhostConv用于扩展通道数以增强网络表达能力,第二个GhostConv用于还原通道数,使输出特征图的通道数与输入一致,残差连接贯穿整个结构,有助于梯度的反向传播,保持网络的表达能力。步长为2的GhostBottleneck结构在步长为1的基础上增加了Depthwise卷积,首先通过GhostConv扩展通道数,然后进行下采样,最后与1×1卷积共同工作,恢复特征图的通道数,确保与输入一致。
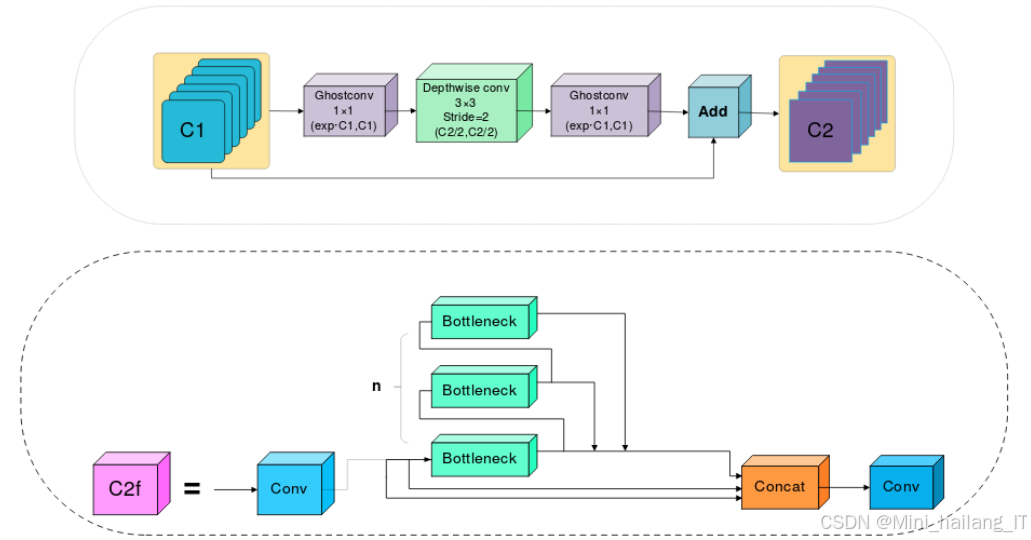
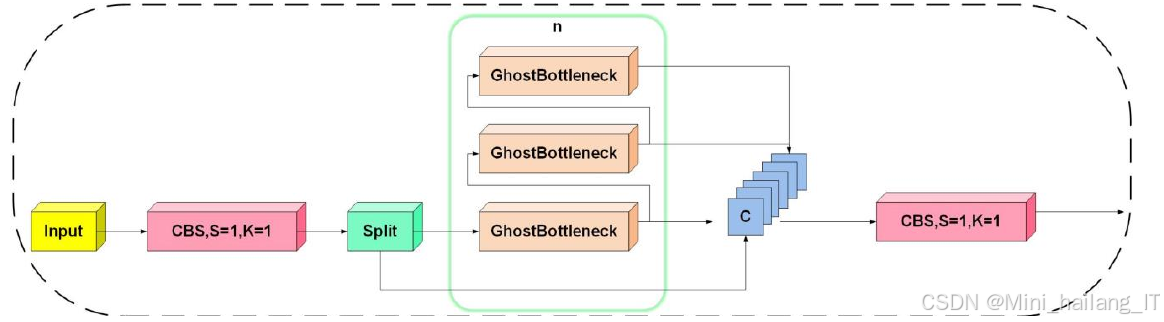
受GhostBottleneck启发,研究重新设计了GhostC2f结构,以优化主干层中的C2f结构。在新设计中,C2f结构的Bottleneck层被GhostBottleneck层替代,使网络能够在不增加实际卷积计算量的条件下获取更多特征图,降低模型的参数量和复杂性,从而提高运行效率。此外,研究采用GhostConv对YOLOv8n的主干和颈部网络的卷积层进行优化,保留原卷积层的感受野,通过轻量级的线性操作提升特征提取效率,显著减少参数量和计算复杂度。在不降维的基础上,ECA通过局部跨通道交互策略,使模型仅增加少量参数,却获得显著效果。ECA首先对输入特征图进行全局平均池化,然后使用K大小的卷积核对池化后的特征进行降维卷积操作,经过Sigmoid激活函数得到每个通道的权值信息,将获得的权重信息与输入特征图相乘,最终得到具有通道注意力的特征图。
数据准备是模型训练的第一步,涉及图像数据的收集、标注和预处理。首先,需要收集包含乒乓球的图像数据集,可以从公开的体育视频中截取图像,或利用相机拍摄实景。接下来,使用标注工具(如LabelImg)对图像中乒乓球的位置进行标注,生成对应的标注文件(如YOLO格式的txt文件),包含每个乒乓球的类别和位置信息。最后,对图像进行预处理,包括调整图像尺寸、数据增强(如旋转、翻转)和归一化,以提高模型的泛化能力。
import cv2
import os
def preprocess_images(image_folder, output_size=(640, 640)):
for img_file in os.listdir(image_folder):
img_path = os.path.join(image_folder, img_file)
image = cv2.imread(img_path)
image_resized = cv2.resize(image, output_size)
cv2.imwrite(img_path, image_resized)
preprocess_images('path/to/your/images')选择合适的YOLO模型是关键步骤。YOLOv8系列提供多种配置(如YOLOv8n、YOLOv8s等),根据任务需求和计算资源选择合适的模型。接下来,配置模型的超参数,包括学习率、batch size、训练轮数等,并设置模型的输入尺寸,以适应预处理后的图像。可以参考YOLOv8的官方文档进行配置。模型训练是整个流程的核心部分。在训练过程中,使用准备好的数据集和配置文件,通过反向传播算法不断优化模型的参数,以降低损失函数值。训练过程中,可以监控训练和验证集上的损失和准确度,以确保模型的收敛性。利用深度学习框架(如PyTorch或TensorFlow)进行训练,编写训练循环。
# config.yaml
model: 'YOLOv8n'
input_size: [640, 640]
learning_rate: 0.001
batch_size: 16
epochs: 50训练完成后,需要对模型进行评估,以验证其在测试集上的性能。使用常见的评估指标,如mAP、Precision、Recall等,评估模型的检测准确性和鲁棒性。将测试图像输入模型,获取检测结果,并与真实标注进行对比。据评估结果,对模型进行优化。可以通过调整超参数、增加数据增强、采用更轻量化的结构等方式来提升模型性能。可视化模型在不同数据集上的表现,以便更好地理解模型的优缺点,并进行针对性的改进。
from metrics import evaluate
test_loader = load_data('path/to/your/test_dataset')
results = []
for images, targets in test_loader:
outputs = model(images)
results.append(outputs)
mAP = evaluate(results, targets)
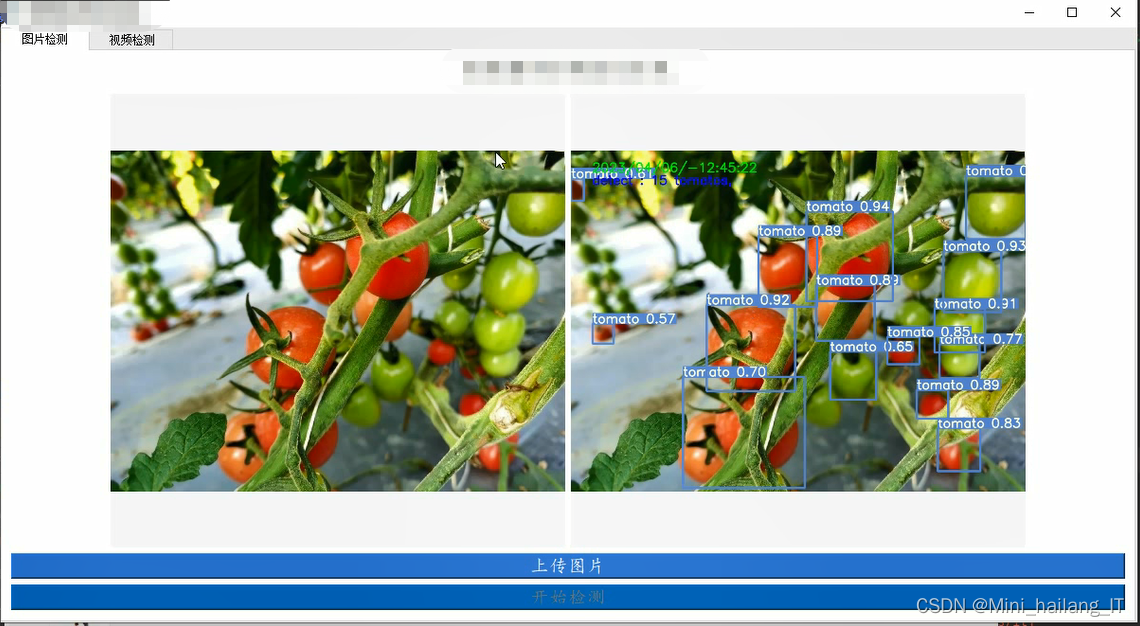
print(f'mAP: {mAP}')海浪学长项目示例:



更多帮助

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)