论文The Effectiveness of a Simplified Model Structure for Crowd Counting(FFNet)详解
当前的人群统计模型方法比较复杂,使用简单的结构构建一个高性能的人群统计模型。采用多尺度特征融合的方法主要目的是对不同尺。第二点:一个多尺度特征融合结构,这个多尺度特征。融合结构包含三个分支,并且融合的方法采用直。第一点:采用已有的分类模型。
目录
一.提出目的
当前的人群统计模型中准确率比较高的方法中模型都比较复杂,导致其很难应用起来,FFNet使用简单的convNeXt结构和多尺度特征融合构建了一个高性能的人群统计模型,并且最终的效果在四个人群计数数据集上表现在同类中都是很不错的。
虽然之前的方式也有采用比较简单的架构,比如使用MobileNet-V3作为backbone的轻量化模型以及其他的多尺度特征融合架构,这些方法虽然轻量化,由于,但是最终的检测效果却下降很快,因此为了提出更加简洁的模型架构同时性能也不错,由此诞生了FFNet。

二.提出方法
第一点:采用已有的分类模型convNeXt-tiny作为主干网络模型;
第二点:一个多尺度特征融合结构,这个多尺度特征融合结构包含三个分支,并且融合的方法采用直接按照通道拼接。采用多尺度特征融合的方法主要目的是对不同尺度的人群进行检测。
注:convNeXt-tiny :https://arxiv.org/pdf/2201.03545v2.pdf
三.当前存在的问题

第一点:图像或者视频中的不同人群密度和尺度都不一样,导致密集尺度小的人群很难被检测到;
第二点:在密集的人群场景中,重叠是非常常见的,导致使用传统的或者当前的目标检测算法很难检测密集的人群,因此采用密度图的方法,但是密度图的方法还是不能完全解决这些问题;
第三点:不同光照和背景变化对应人群检测具有很大的挑战,特别是在光照暗的地方,人群不容易被检测到。
四.不同多尺度方法比较
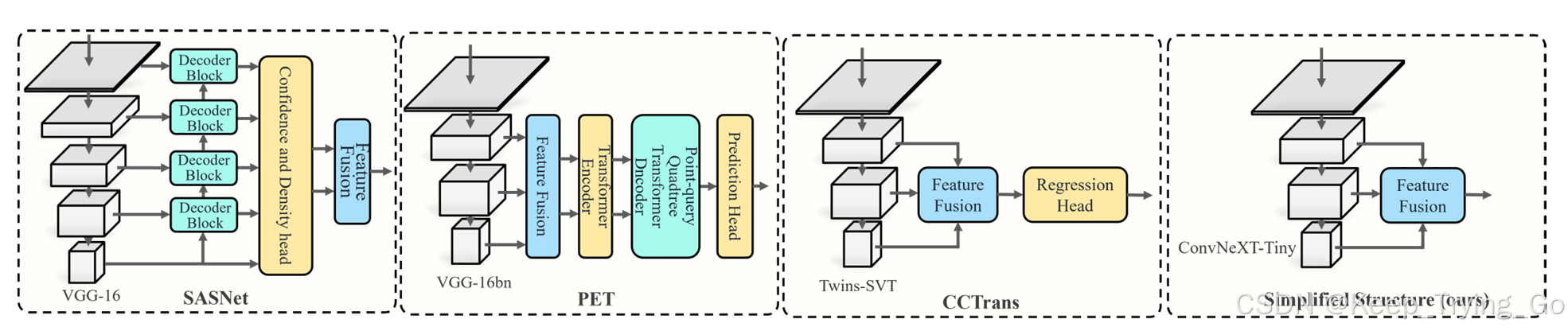
SASNet网络模型:提出采用尺度自适应网络模型,自动学习尺度和特征层中间对应关系。为了缓解离散特征层和连续尺度变化的差距,通过多个层加权平均输出方式代替了直接使用最后作为输出的方式。
PET:提出采用四叉树结构来解决人群计数的挑战,并且联合了基于Transformer的编码器-解码器,增加了模型的复杂性(这篇论文难理解)。
CCTrans: 将金字塔视觉Transformer应用到人群计数中,通过联合低层和高层特征,用于捕获全局人群信息,因此提出了采用多尺度空洞卷积作为预测head。
FFNet:提出“集中转换模块”对不同尺度的特征生成更加丰富的相关人群语义信息,最后将转换之后不同尺度特征按照通道进行拼接得到最终密度图。
五.整体模型架构
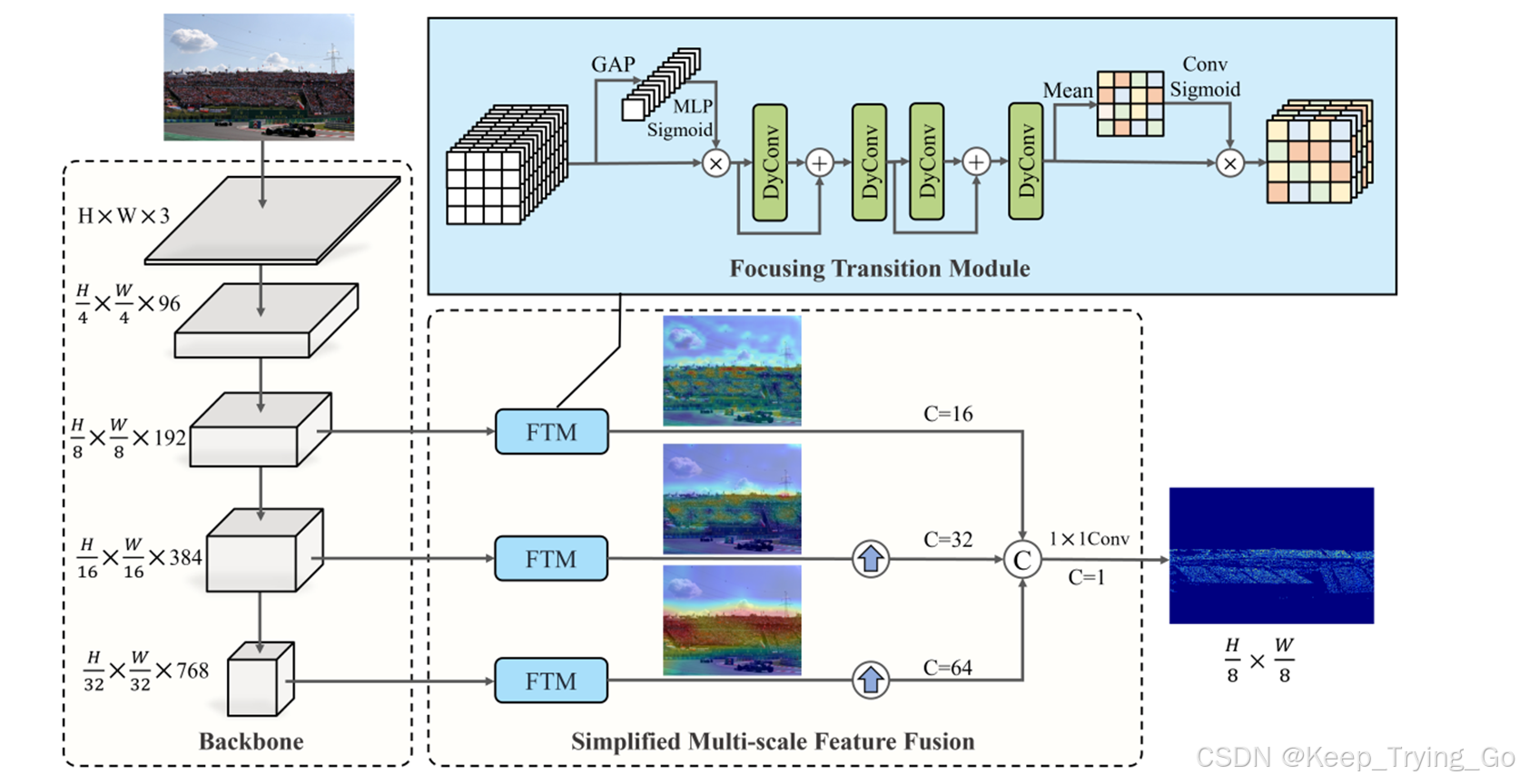
backbone:主要是采用convNeXt-tiny作为主干网络模型提取特征,其中convNeXt纯卷积和 Swin Transformer架构进行了对比设计,发现convNeXt比Swin Transformer具有更快的推理速度和更高的准确率。
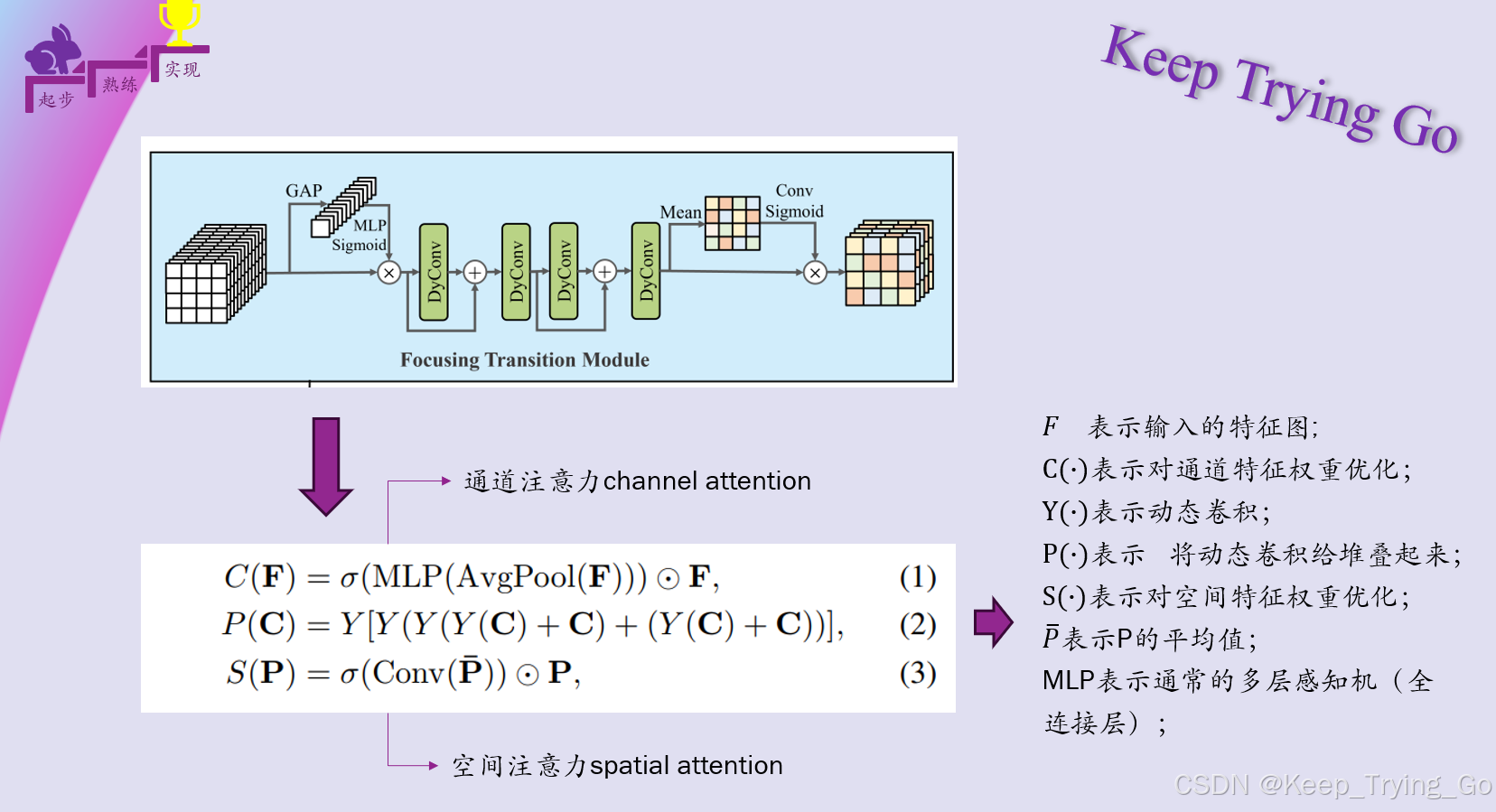
“集中转换模块”-FTM(本文重点):如果直接融合来自主干网络三个分支的特征的话容易导致特征图中包含冗余的信息,从而降低学习的效率,因此进一步提出采用“集中转换模块”可以有效的集中在动态和静态特征,支持有效的降维和特征提取,以促进转换,主要是使用了动态卷积机制。

注:Channel attention & spatial attention: https://arxiv.org/pdf/2209.07947v1.pdf
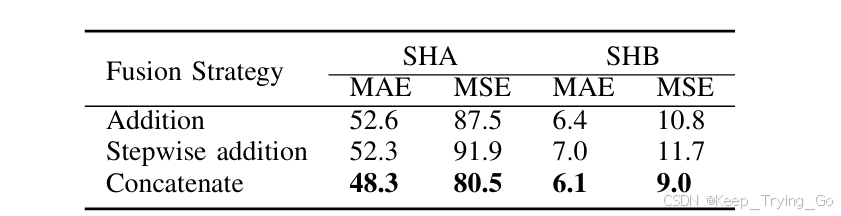
多尺度特征融合:论文分别对通道拼接,相加以及逐步相加对三种不同的尺度融合方式进行了讨论,其中根据实验结果发现,最终选择通道拼接融合方式。
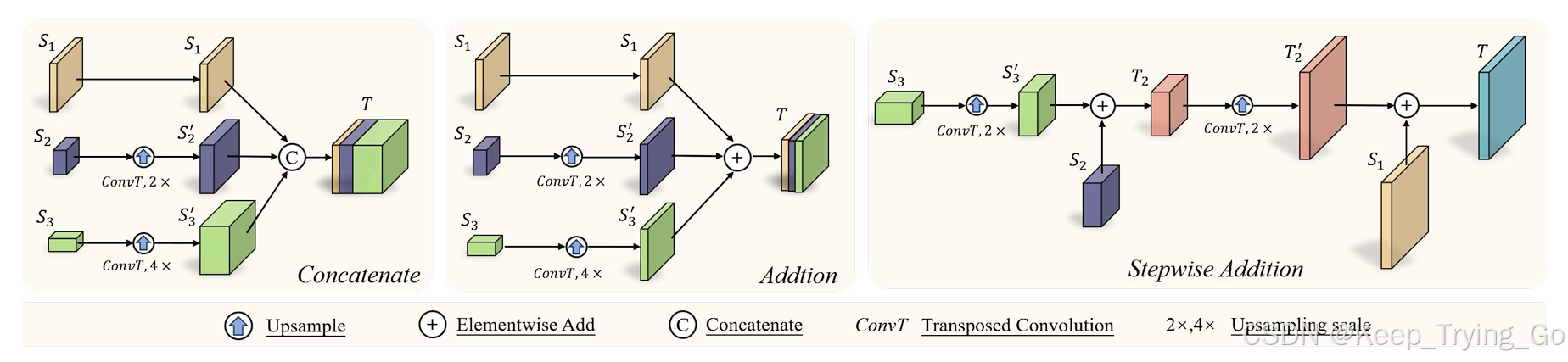
六.“集中转换模块”-FTM(重点)

七.损失函数

OT-optimal transport(难点):https://arxiv.org/pdf/1803.00567v4
https://blog.csdn.net/qq_41129489/article/details/128830589
八.评价指标
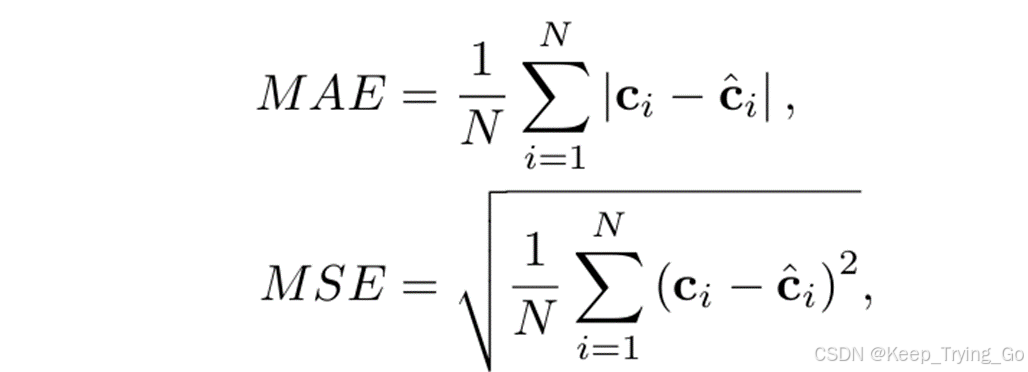
九.实验结果
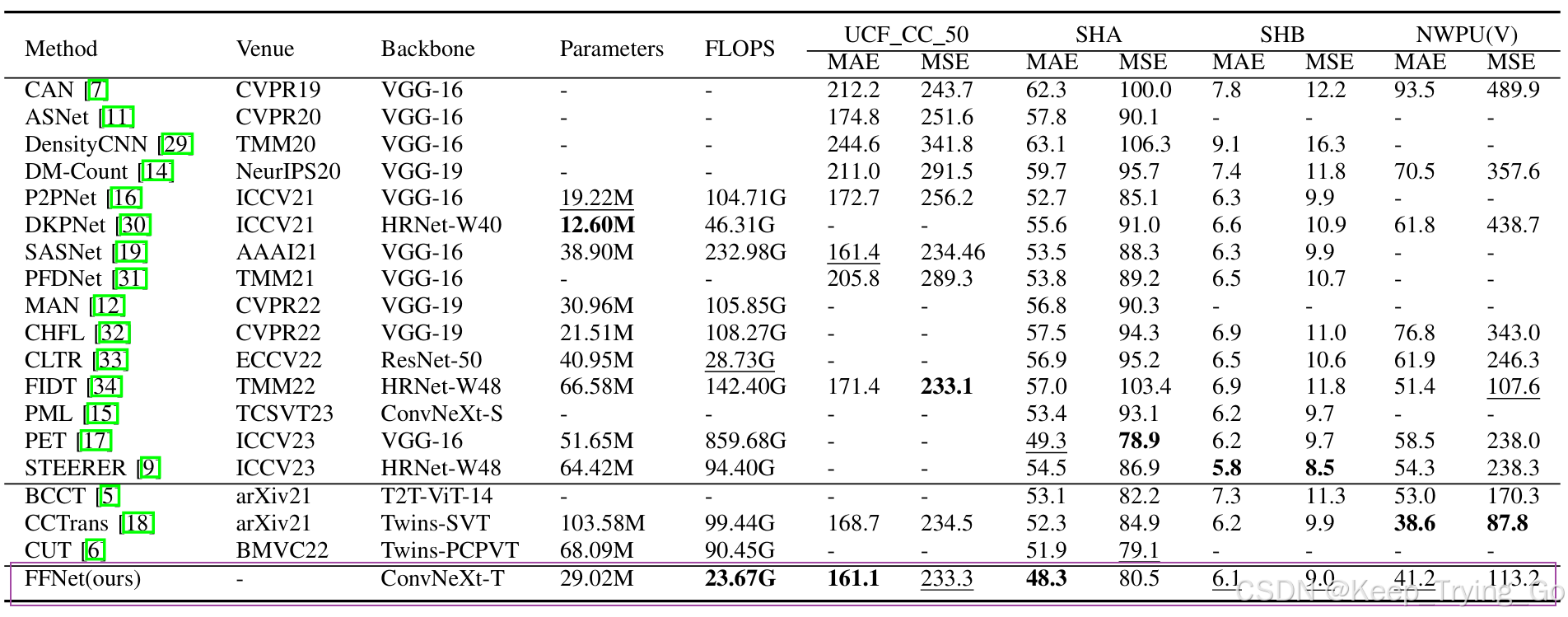
注:从所有比较的结果中可以看到,FFNet的FLOPSs是最低的,虽然在各个数据集上不是都是最优的,但是在各个数据集上的综合性能都不错。

注:通过该表的实验结果可以看到,FFNet之所以会选择ConvNeXt-Tiny,不仅仅是最终的评价误差最低,同时参数量也相对最小。
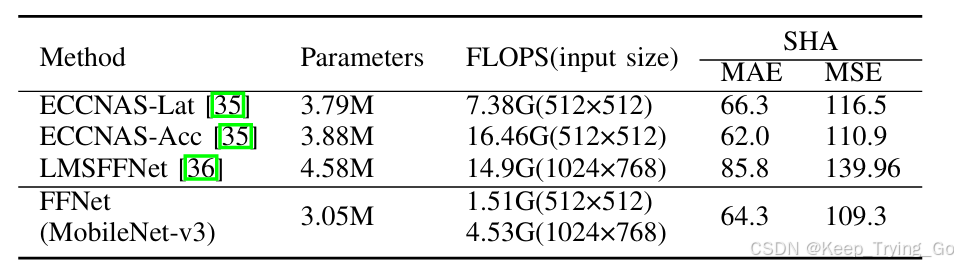
注:有一点不明白的是,既然FFNet以ConvNeXt-Tiny作为backbone,为什么在和其他模型比较的时候使用的MobileNet-v3作为backbone呢?
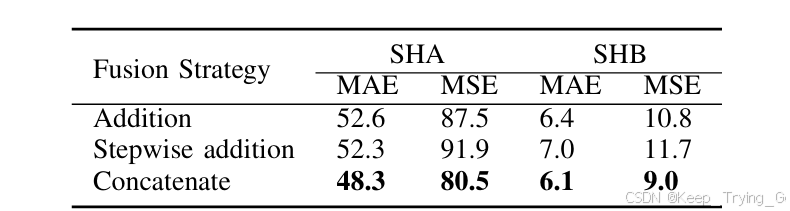
注:比较不同尺度特征图的融合方式,通道拼接的效果是最好的。
最后总结
- 本文提出了采用已有的轻量化分类模型和本文提出的采用多尺度特征融合,并且在多尺度特征融合的过程中采用动态卷积的方法进一步提升模型的性能;
- 采用已有的损失函数 = 人群数统计损失 + 概率分布最优化传输损失 + 变化损失提升了最终算法的性能;
- 从目前来讲的话,该篇论文提出的方法还是比较好理解,并且最终算法的性能在同类中也达到了最好的结果。
- 虽然在同类算法中达到了比较好结果,其实在其他领域该算法的性能会降低很多。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)