自用 Java 学习(SQL)
SQL概述了解了数据模型后,接下来我们就学习SQL语句,通过SQL语句对数据库、表、数据进行增删改查操作。SQL简介英文:Structured Query Language,简称 SQL结构化查询语言,一门操作关系型数据库的编程语言定义操作所有关系型数据库的统一标准对于同一个需求,每一种数据库操作的方式可能会存在一些不一样的地方,我们称为“方言”通用语法SQL 语句可以单行或多行书写,以分号结尾。
SQL概述
了解了数据模型后,接下来我们就学习SQL语句,通过SQL语句对数据库、表、数据进行增删改查操作。
SQL简介
英文:Structured Query Language,简称 SQL
结构化查询语言,一门操作关系型数据库的编程语言
定义操作所有关系型数据库的统一标准
对于同一个需求,每一种数据库操作的方式可能会存在一些不一样的地方,我们称为“方言”
通用语法
SQL 语句可以单行或多行书写,以分号结尾。
MySQL 数据库的 SQL 语句不区分大小写,关键字建议使用大写。
同样的一条sql语句写成下图的样子,一样可以运行处结果。
注释
单行注释: -- 注释内容 或 #注释内容(MySQL 特有)
多行注释: /* 注释 */
SQL分类
DDL(Data Definition Language) : 数据定义语言,用来定义数据库对象:数据库,表,列等
DDL简单理解就是用来操作数据库,表等
DML(Data Manipulation Language) 数据操作语言,用来对数据库中表的数据进行增删改
DML简单理解就对表中数据进行增删改
DQL(Data Query Language) 数据查询语言,用来查询数据库中表的记录(数据)
DQL简单理解就是对数据进行查询操作。从数据库表中查询到我们想要的数据。
DCL(Data Control Language) 数据控制语言,用来定义数据库的访问权限和安全级别,及创建用户
DML简单理解就是对数据库进行权限控制。比如我让某一个数据库表只能让某一个用户进行操作等。
DDL:操作数据库
我们先来学习DDL来操作数据库。而操作数据库主要就是对数据库的增删查操作。
查询
查询所有的数据库
SHOW DATABASES;
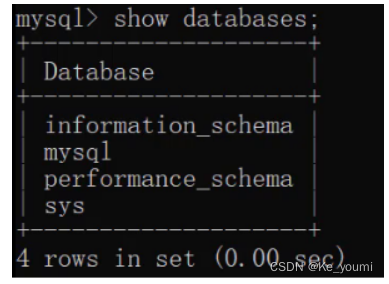
上述查询到的是的这些数据库是mysql安装好自带的数据库,我们以后不要操作这些数据库。
创建数据库
-
创建数据库:
CREATE DATABASE 数据库名称;
运行语句效果如下:
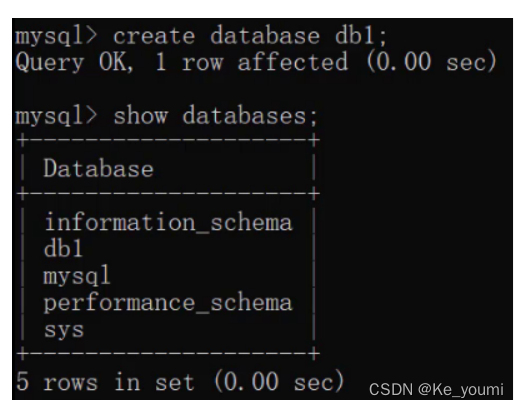
而在创建数据库的时候,我并不知道db1数据库有没有创建,直接再次创建名为db1的数据库就会出现错误。

为了避免上面的错误,在创建数据库的时候先做判断,如果不存在再创建。
-
创建数据库(判断,如果不存在则创建)
CREATE DATABASE IF NOT EXISTS 数据库名称;
运行语句效果如下:
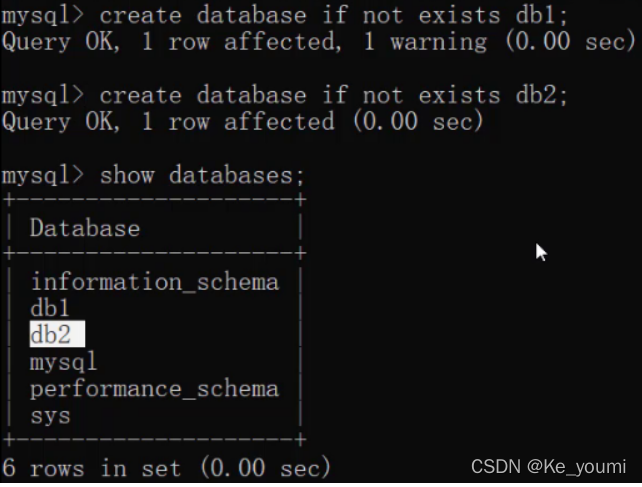
从上面的效果可以看到虽然db1数据库已经存在,再创建db1也没有报错,而创建db2数据库则创建成功。
删除数据库
-
删除数据库
DROP DATABASE 数据库名称;
-
删除数据库(判断,如果存在则删除)
DROP DATABASE IF EXISTS 数据库名称;
运行语句效果如下:

使用数据库
数据库创建好了,要在数据库中创建表,得先明确在哪儿个数据库中操作,此时就需要使用数据库。
-
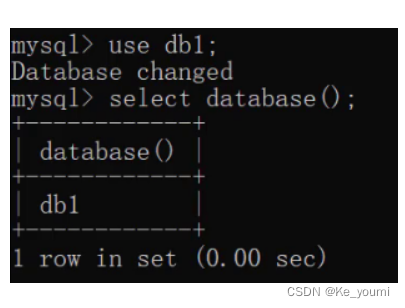
使用数据库
USE 数据库名称;
-
查看当前使用的数据库
SELECT DATABASE();
运行语句效果如下:
DDL:操作表
操作表也就是对表进行增(Create)删(Retrieve)改(Update)查(Delete)。
查询表
-
查询当前数据库下所有表名称
SHOW TABLES;
我们创建的数据库中没有任何表,因此我们进入mysql自带的mysql数据库,执行上述语句查看

-
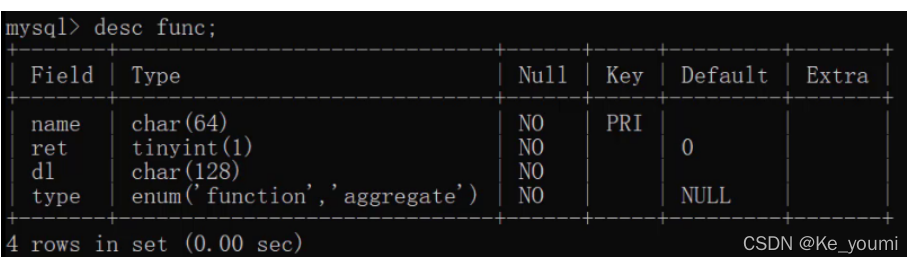
查询表结构
DESC 表名称;
查看mysql数据库中func表的结构,运行语句如下:
创建表
-
创建表
CREATE TABLE 表名 (
字段名1 数据类型1,
字段名2 数据类型2,
…
字段名n 数据类型n
);
注意:最后一行末尾,不能加逗号
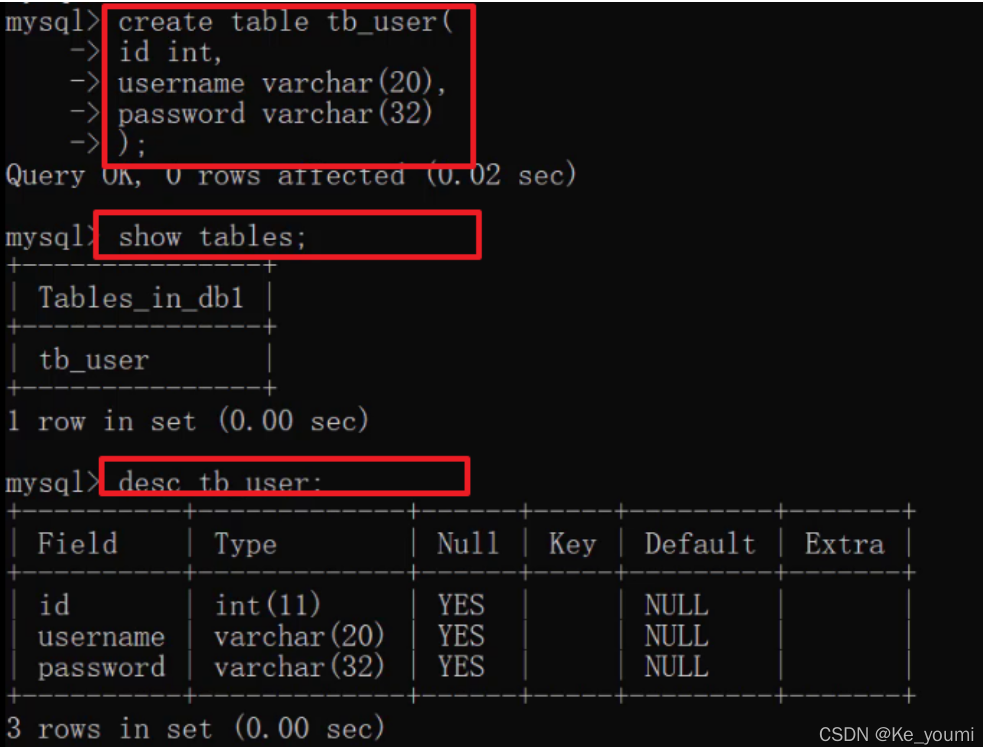
知道了创建表的语句,那么我们创建创建如下结构的表

create table tb_user (
id int,
username varchar(20),
password varchar(32)
);
运行语句如下:
数据类型
MySQL 支持多种类型,可以分为三类:
-
数值
tinyint : 小整数型,占一个字节 int : 大整数类型,占四个字节 eg : age int double : 浮点类型 使用格式: 字段名 double(总长度,小数点后保留的位数) eg : score double(5,2) -
日期
date : 日期值。只包含年月日 eg :birthday date : datetime : 混合日期和时间值。包含年月日时分秒 -
字符串
char : 定长字符串。 优点:存储性能高 缺点:浪费空间 eg : name char(10) 如果存储的数据字符个数不足10个,也会占10个的空间 varchar : 变长字符串。 优点:节约空间 缺点:存储性能底 eg : name varchar(10) 如果存储的数据字符个数不足10个,那就数据字符个数是几就占几个的空间
注意:其他类型参考资料中的《MySQL数据类型].xlsx》
案例:
需求:设计一张学生表,请注重数据类型、长度的合理性
1. 编号
2. 姓名,姓名最长不超过10个汉字
3. 性别,因为取值只有两种可能,因此最多一个汉字
4. 生日,取值为年月日
5. 入学成绩,小数点后保留两位
6. 邮件地址,最大长度不超过 64
7. 家庭联系电话,不一定是手机号码,可能会出现 - 等字符
8. 学生状态(用数字表示,正常、休学、毕业...)
语句设计如下:
create table student (
id int,
name varchar(10),
gender char(1),
birthday date,
score double(5,2),
email varchar(15),
tel varchar(15),
status tinyint
);
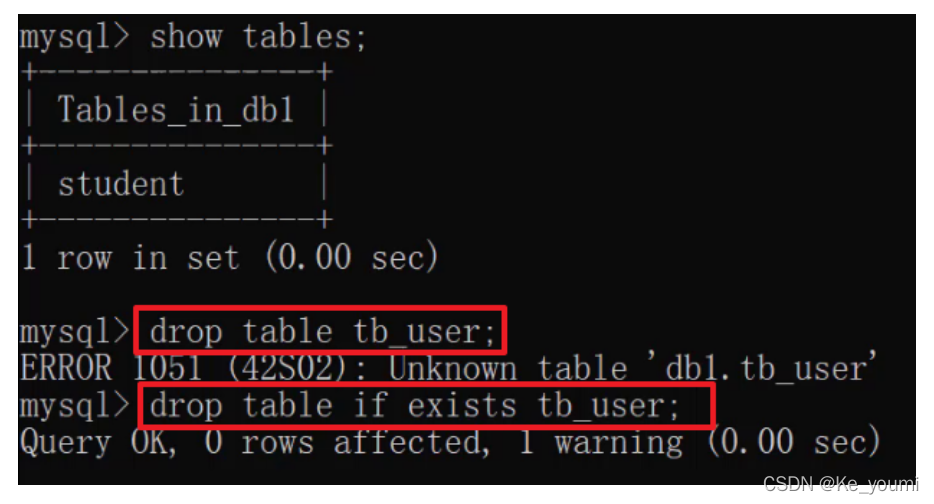
删除表
-
删除表
DROP TABLE 表名;
-
删除表时判断表是否存在
DROP TABLE IF EXISTS 表名;
运行语句效果如下:
5.5 修改表
-
修改表名
ALTER TABLE 表名 RENAME TO 新的表名; -- 将表名student修改为stu alter table student rename to stu;
-
添加一列
ALTER TABLE 表名 ADD 列名 数据类型; -- 给stu表添加一列address,该字段类型是varchar(50) alter table stu add address varchar(50);
-
修改数据类型
ALTER TABLE 表名 MODIFY 列名 新数据类型; -- 将stu表中的address字段的类型改为 char(50) alter table stu modify address char(50);
-
修改列名和数据类型
ALTER TABLE 表名 CHANGE 列名 新列名 新数据类型; -- 将stu表中的address字段名改为 addr,类型改为varchar(50) alter table stu change address addr varchar(50);
-
删除列
ALTER TABLE 表名 DROP 列名; -- 将stu表中的addr字段 删除 alter table stu drop addr;
添加数据
-
给指定列添加数据
INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…);
-
给全部列添加数据
INSERT INTO 表名 VALUES(值1,值2,…);
-
批量添加数据
INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…)…; INSERT INTO 表名 VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…)…;
7.2 修改数据
-
修改表数据
UPDATE 表名 SET 列名1=值1,列名2=值2,… [WHERE 条件] ;
注意:
修改语句中如果不加条件,则将所有数据都修改!
像上面的语句中的中括号,表示在写sql语句中可以省略这部分
7.3 删除数据
-
删除数据
DELETE FROM 表名 [WHERE 条件] ;
DQL
我们先介绍查询的完整语法:
SELECT 字段列表 FROM 表名列表 WHERE 条件列表 GROUP BY 分组字段 HAVING 分组后条件 ORDER BY 排序字段 LIMIT 分页限定
8.1 基础查询
8.1.1 语法
-
查询多个字段
SELECT 字段列表 FROM 表名; SELECT * FROM 表名; -- 查询所有数据
-
去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;
-
起别名
AS: AS 也可以省略
8.2 条件查询
8.2.1 语法
SELECT 字段列表 FROM 表名 WHERE 条件列表;
-
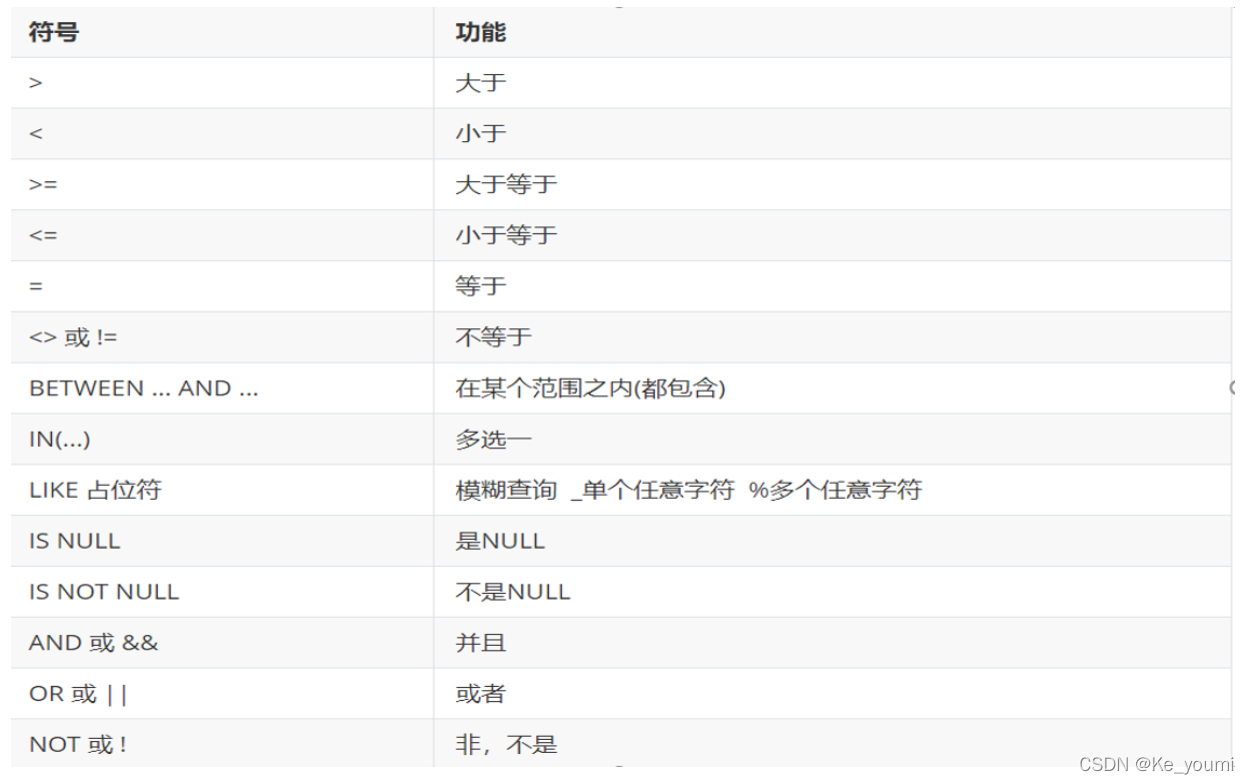
条件
条件列表可以使用以下运算符
8.3 排序查询
8.3.1 语法
SELECT 字段列表 FROM 表名 ORDER BY 排序字段名1 [排序方式1],排序字段名2 [排序方式2] …;
上述语句中的排序方式有两种,分别是:
-
ASC : 升序排列 (默认值)
-
DESC : 降序排列
注意:如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序
8.4 聚合函数
8.4.1 概念
==将一列数据作为一个整体,进行纵向计算。==
如何理解呢?假设有如下表
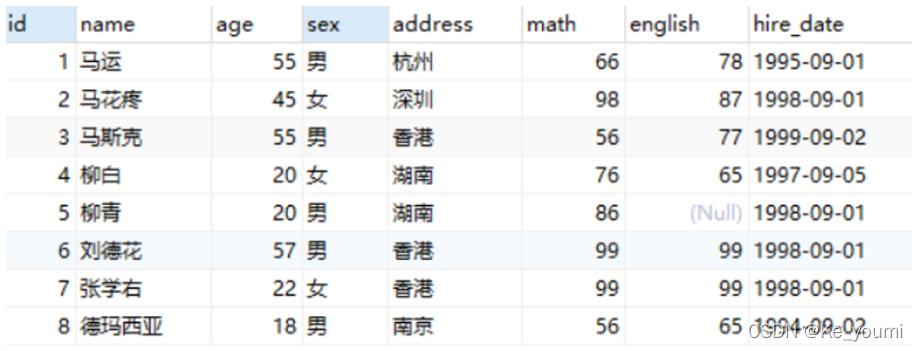
现有一需求让我们求表中所有数据的数学成绩的总和。这就是对math字段进行纵向求和。
8.4.2 聚合函数分类
| 函数名 | 功能 |
|---|---|
| count(列名) | 统计数量(一般选用不为null的列) |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| sum(列名) | 求和 |
| avg(列名) | 平均值 |
8.4.3 聚合函数语法
SELECT 聚合函数名(列名) FROM 表;
注意:null 值不参与所有聚合函数运算
8.5 分组查询
8.5.1 语法
SELECT 字段列表 FROM 表名 [WHERE 分组前条件限定] GROUP BY 分组字段名 [HAVING 分组后条件过滤];
注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
where 和 having 区别:
-
执行时机不一样:where 是分组之前进行限定,不满足where条件,则不参与分组,而having是分组之后对结果进行过滤。
-
可判断的条件不一样:where 不能对聚合函数进行判断,having 可以。
分页查询
语法
SELECT 字段列表 FROM 表名 LIMIT 起始索引 , 查询条目数;
注意: 上述语句中的起始索引是从0开始

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)