CNN+Transformer:深度学习的创新融合,性能炸裂!
的全局上下文理解能力,这一研究趋势在图像处理和自然语言处理等多个领域展现出了巨大的潜力。它。通过这种结构的结合,研究人员能够开发出更高效、更精确的模型,以应对传统单一网络结构难以解决的复杂挑战。这一领域的研究为了帮助研究人员深入理解中该领域的论文。这些论文涵盖了最新的研究成果,并且我们提供了论文的来源链接和相关代码,以期激发新的学术灵感。
【CNN+Transformer】融合了卷积神经网络(CNN)的局部特征捕捉能力与Transformer的全局上下文理解能力,这一研究趋势在图像处理和自然语言处理等多个领域展现出了巨大的潜力。它特别适用于那些需要同时关注细节和全局信息的任务。通过这种结构的结合,研究人员能够开发出更高效、更精确的模型,以应对传统单一网络结构难以解决的复杂挑战。这一领域的研究不仅推动了深度学习技术的发展,也为实际应用提供了更多的可能性。
为了帮助研究人员深入理解 【CNN+Transformer】的方法论并探索新的研究方向,我们精心整理了过去两年中该领域的 18篇顶级会议和期刊 论文。这些论文涵盖了最新的研究成果,并且我们提供了论文的来源链接和相关代码,以期激发新的学术灵感。
三篇论文详解
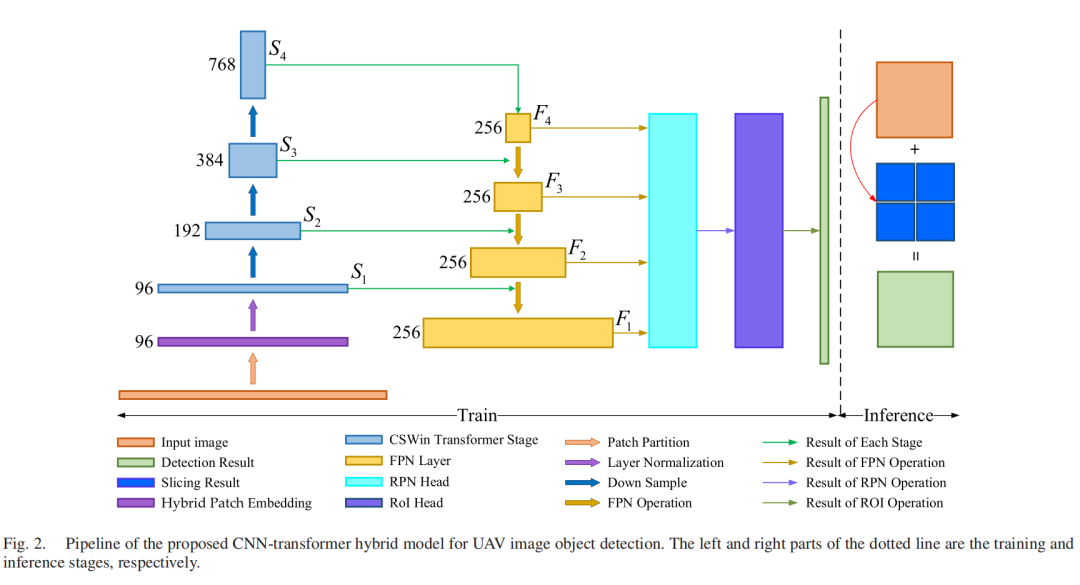
1、A CNN-Transformer Hybrid Model Based on CSWin Transformer for UAV Image Object Detection
方法
-
混合模型框架:提出了一种结合卷积神经网络(CNN)和变换器(Transformer)的混合模型,用于无人机(UAV)图像中的目标检测。
-
CSWin Transformer作为骨干网络:使用高效的CSWin Transformer作为骨干网络来提取图像特征,并将其输入到特征金字塔网络(FPN)中,实现多尺度表示,有助于多尺度目标检测。
-
混合Patch嵌入模块(HPEM):构建了一个混合Patch嵌入模块来提取和利用图像中的低级信息,如边缘和角落。
-
基于切片的推理方法(SI):提出了一种基于切片的推理方法,通过融合原始图像和切片图像的推理结果来提高小目标检测的准确性,无需修改原始网络。
创新点
-
多尺度特征融合:通过结合CNN和Transformer的优势,实现了对不同尺度目标的有效检测。
-
CSWin Transformer的应用:将CSWin Transformer用于UAV图像的目标检测任务,有效地捕捉长距离依赖关系。
-
HPEM模块:提出了一种新的HPEM模块,用于提取图像中的低级特征,增强了模型对边缘和角落等细节信息的捕捉能力。
-
基于切片的推理方法:创新性地提出了一种基于切片的推理方法,通过在推理阶段对图像进行切片和放大处理,提高了对小目标的检测精度。
-
无需修改原始模型:提出的SI方法可以在不修改原始模型结构的情况下,通过后处理步骤提升检测性能。
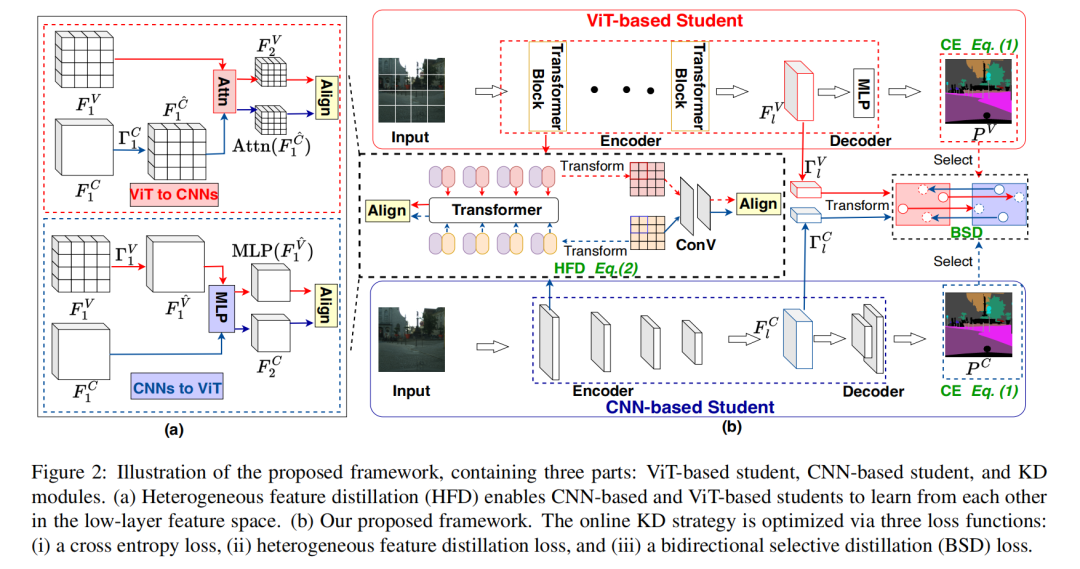
2、A Good Student is Cooperative and Reliable: CNN-Transformer Collaborative Learning for Semantic Segmentation
方法
-
在线知识蒸馏(KD)框架:提出了一个在线KD框架,用于同时学习紧凑且有效的基于CNN和基于ViT的模型,以进行语义分割任务。
-
异构特征蒸馏(HFD):通过模仿CNN和ViT之间的异构特征,提高学生模型在低层特征空间的一致性。
-
双向选择性蒸馏(BSD):提出BSD模块,通过动态转移区域和像素级的可靠知识,促进两个学生模型相互学习。
-
区域-wise BSD:通过确定特征空间中相应区域的知识转移方向,动态地转移区域间的可靠知识。
-
像素-wise BSD:在logit空间中判断哪些预测知识需要被转移。
-
优化目标:结合交叉熵损失、HFD损失和BSD损失,优化两个学生模型的学习过程。
创新点
-
首次在线KD策略:首次提出在线KD策略,用于语义分割中CNN和ViT模型的协作学习。
-
异构特征蒸馏(HFD):创新性地提出HFD,使CNN和ViT学生模型能够互相学习,以补偿各自的局限性。
-
双向选择性蒸馏(BSD):首次提出BSD,通过区域和像素级的双向知识选择性转移,提高了模型间的协作学习能力。
-
跨模型知识选择与交换:通过选择和交换可靠的知识,模型能够在特征和预测空间中互补学习,提高了语义分割的性能。
-
无额外计算成本:所提出的方法在推理过程中不增加额外的计算成本,因为教师模型仅在训练中参与。
-
显著的性能提升:在三个基准数据集上进行的广泛实验表明,所提出的方法大幅超越了现有的在线KD方法,并在各种教师-学生组合中实现了一致且显著的性能提升。
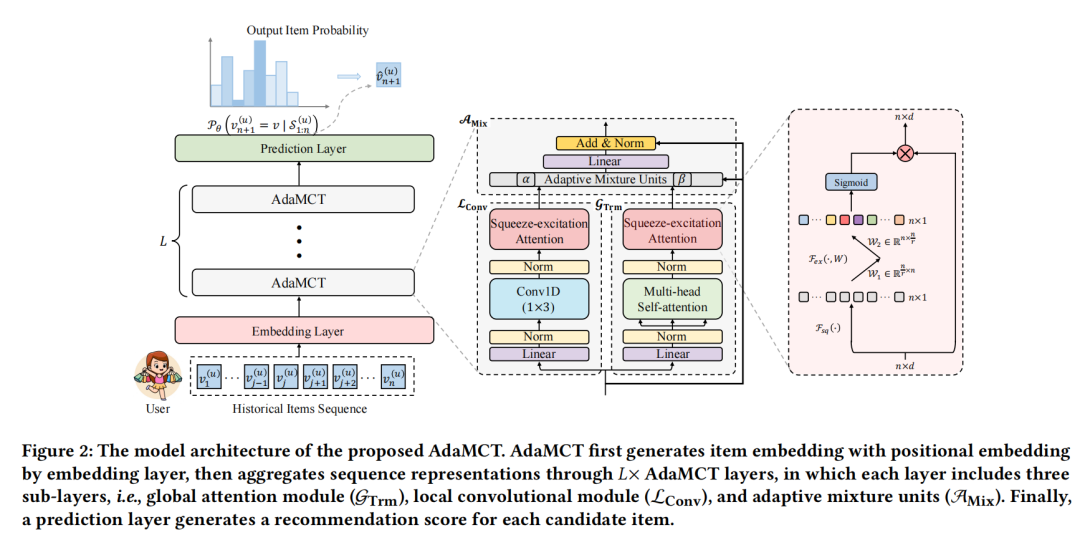
3、AdaMCT: Adaptive Mixture of CNN-Transformer for Sequential Recommendation
方法
AdaMCT是一种用于序列推荐的新型模型,它通过以下几个关键方法来捕获用户的长期和短期偏好:
-
混合局部和全局注意力机制:AdaMCT结合了局部卷积滤波器(CNN)和全局Transformer注意力机制,以利用局部性和全局交互性的感应偏差。
-
自适应混合单元:通过层感知的自适应混合单元(AMix),模型可以根据每个用户的个性化需求调整局部和全局依赖模块的混合重要性。
-
挤压激活注意力(Squeeze-Excitation Attention, SEAtt):提出了SEAtt来替代传统的softmax注意力机制,允许同时激活多个与用户偏好相关的项目,从而提高模型的表达能力。
-
多层架构:AdaMCT采用多层架构,每一层都包括上述的局部卷积模块(LConv)、全局注意力模块(GTrm)和自适应混合单元(AMix),以增强模型对用户行为序列的理解和表示。
创新点
-
CNN与Transformer的结合:首次尝试将CNN的局部感知能力和Transformer的全局注意力机制结合起来,以同时捕获用户的长期和短期偏好。
-
自适应混合机制:提出了一种新的自适应混合单元,能够在不同层次上根据用户的个性化需求调整局部和全局信息的融合,提高了模型的适应性和表达能力。
-
Squeeze-Excitation Attention:引入了SEAtt机制来解决传统注意力机制中的单一模态激活问题,允许模型同时考虑多个与用户偏好相关的项目。
-
模型效率:尽管增加了模型复杂性,AdaMCT在参数数量和计算效率方面仍然具有优势,这使得它在资源受限的设备上也具有实际应用的潜力。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 23
23 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)