
部署DeepSeek的最优解,昇腾率先给出了答案
不到一个月,DeepSeek这一现象级应用在全球大模型市场持续风靡,入局玩家持续增长。百度、OpenAI、谷歌等主流大模型厂商密集官宣旗下闭源AI模型纷纷转向开源,主流AI产品也计划免费向用户开源。另一方面,DeepSeek的崛起不仅让全球大模型厂商吃到了红利,也让更多开发者涌入了DeepSeek。“服务器繁忙,请稍后再试”的提示词频现,也暴露出大模型工具对于稳定可靠的算力底座的依赖。CSDN了解
不到一个月,DeepSeek这一现象级应用在全球大模型市场持续风靡,入局玩家持续增长。百度、OpenAI、谷歌等主流大模型厂商密集官宣旗下闭源AI模型纷纷转向开源,主流AI产品也计划免费向用户开源。
另一方面,DeepSeek的崛起不仅让全球大模型厂商吃到了红利,也让更多开发者涌入了DeepSeek。“服务器繁忙,请稍后再试”的提示词频现,也暴露出大模型工具对于稳定可靠的算力底座的依赖。
CSDN了解到,DeepSeek 目前每天的调用量已经达到 3000 多万次,且这一数字还在不断攀升。如此庞大的调用量,意味着大量的计算任务需要处理,对算力的需求自然水涨船高。
此外,从模型的参数规模来看,DeepSeek所需的参数规模对算力的要求极高。DeepSeek-R1 模型的参数规模从1.5B 到671B 不等,以训练一个 671B 参数的模型为例,传统的训练方式可能需要数千张高性能GPU 卡才能在合理的时间内完成训练。从这一点来看,稳定可靠的算力底座依旧是模型创新的关键。而从算力需求来看,DeepSeek的出现并没有让算力的重要性降低,反而提升了对高效、稳定算力的需求。
放眼国内大模型产业,大模型算力主要依靠海外算力,尤其是训练环节。强大的算力是优化模型参数、提升模型性能的关键。当前主流的大模型动辄拥有数百亿、上千亿个参数,如此巨量的参数空间意味着海量的计算工作量。也就是说只有拥有超大规模的算力集群,才能支撑起如此复杂的训练任务。
而对于拥有成熟算力集群部署经验的昇腾来说,这显然不是一件难事。
DeepSeek带来的算力挑战
为什么是昇腾?
要回答这个问题,我们首先需要了解DeepSeek为什么需要大量算力支撑?
首先,在模型结构上,DeepSeek采用了MOE架构,将大量的小专家模型组合在一起,实现了模型性能的大幅提升。这种架构的创新使得 DeepSeek 在处理复杂任务时能够更加高效,同时也对算力提出了更高的要求。
其次,DeepSeek 在底层计算和通信方面进行了深度优化。通过对硬件的底层通信优化,DeepSeek 能够更好地利用硬件资源,提高计算效率。此外,DeepSeek 还在后训练和强化学习方面进行了创新,升级了 GRPO 算法和推理能力,实现了单次推理生成多个字符token的能力。这些技术突破使得DeepSeek 在性能上有了显著提升,但同时也对算力平台提出了更高的挑战。
可以看到,无论是在训练环节还是推理环节,DeepSeek均需要超强的算力作为支撑。
DeepSeek需要昇腾
作为DeepSeek的算力供应商,昇腾是业界唯一一个能够全面支持DeepSeek从预训练到微调全流程的AI训练平台,不仅成本可控,支持本地部署,并且拥有与DeepSeek相似的技术路线,可谓具备天然的优势。
比如,在训练能力上,昇腾是业界首个适配完成 DeepSeek 核心算法的平台,支持 DeepSeek 全系模型预训练及微调。它支持 DualPipe、跨节点 All2All 等 DeepSeek 核心优化技术,超大带宽通信域更适合 DeepSeek 的流水线并行算法及冗余专家等能力。同时,提供 “行业强化微调解决方案”,支持 GRPO 算法,实现计算能力升级(算子性能提升 10% +)、通信算法升级(效率提升 100%)以及调度和并行能力升级(任务自动寻找最优资源)。
推理能力方面,针对 DeepSeek 小专家创新架构带来的通信耗时及专家负载不均挑战,昇腾采用双机并行推理 + 专家负载均衡技术,助力 DeepSeek 模型推理吞吐性能提升 30% +。通过高效跨机互联 + MoE 专家通信优化降低通信时延 30%,通信优化 + 访存优化(伪 EP 混合并行算法使通信优化性能提升 30% +,稀疏路由稠密化算法使访存性能提升 20% +),有效降低专家不均衡度,提升推理吞吐性能。
此外,昇思 MindSpore AI 框架也为 DeepSeek供了有力支持。它支持DeepSeek - V3 预训练、微调、推理全流程开箱即用,实现天级复现。同时,MindSpore助力DeepSeek快速基于超大集群拉起分布式训练,提供丰富的分布式并行算法,支持DS极致性能优化,集群仿真和自动调优,大模型调优不占用算力资源,静态图支持动态shape,保证更稳定高效的 MoE 计算。此外,MindSpore 亲和昇腾硬件,通过多维混合并行技术等,优化模型在集群训练上的计算、存储、通信协同效率,实现模型训练性能加速。
除了技术路线上的天然适配外,昇腾在模型本地部署方面也积累了一些经验。
目前,国内 70% 客户、伙伴基于昇腾快速上线,截至 2 月 12 日,已有80 +客户/伙伴基于昇腾已上线 DeepSeek,20 + 适配测试中。昇腾联合伙伴/客户,推出形态丰富的产品和解决方案,涵盖一体机、云服务、硬件+开源社区等多种形式,帮助企业快速部署,已覆盖互联网、金融、运营商、政务、教育等多个行业。
此外,据昇腾方透露,春节前,硅基流动与昇腾达成深度合作,在开发者社区方面,DeepSeek 系列模型配套版本上线魔乐社区,用户数超 1.6w,日均访问量超过 3000,下载量超 1w。
可以看到,从硬件使能、AI框架到应用使能,昇腾的每一个环节几乎都为DeepSeek提供了可能。
DeepSeek起而万物生
另外,从生态层面来看,无论是DeepSeek宣布开源还是昇腾开发者生态的构建,都体现了双方在AI技术普及上的坚定承诺。
一方面,DeepSeek 通过开源共享,确保技术的透明度和可访问性,降低了AI技术的入门门槛,提升了普惠优质AI的可获得性,各行各业能够获得更加优质的模型,激发出更多的行业、产业去进行AI创新。
另一方面,作为一个开放的AI基础软硬件平台,昇腾平台打造了Atlas系列硬件、异构计算架构CANN、全场景AI框架昇思MindSpore、昇腾应用使能以及一站式开发平台ModelArts等全栈产品体系,并形成了规模庞大的产业生态。
据悉,截至2024年12月31日,昇腾已发展超过60硬件合作伙伴,330万多开发者,2500多家行业合作伙伴,并共同孵化了150多个昇腾原生硬件产品,超过5800个解决方案。
此外,据公开信息统计,目前昇腾正在助力20+省、25城市公共算力服务平台启动部署DeepSeek系列模型,全国超70%区域可获取本地支持。
这些事实都说明,如果没有普惠算力的持续接入,那么资源限制与访问繁忙,会快速消耗掉大众和企业使用AI、探索AI的热情。而没有千行百业的AI创新,AI的突破也只能止步于开发者社区,无法进入从研发到商用的良性循环。
从这个层面上来看,不仅仅是DeepSeek需要昇腾,昇腾更需要DeepSeek。

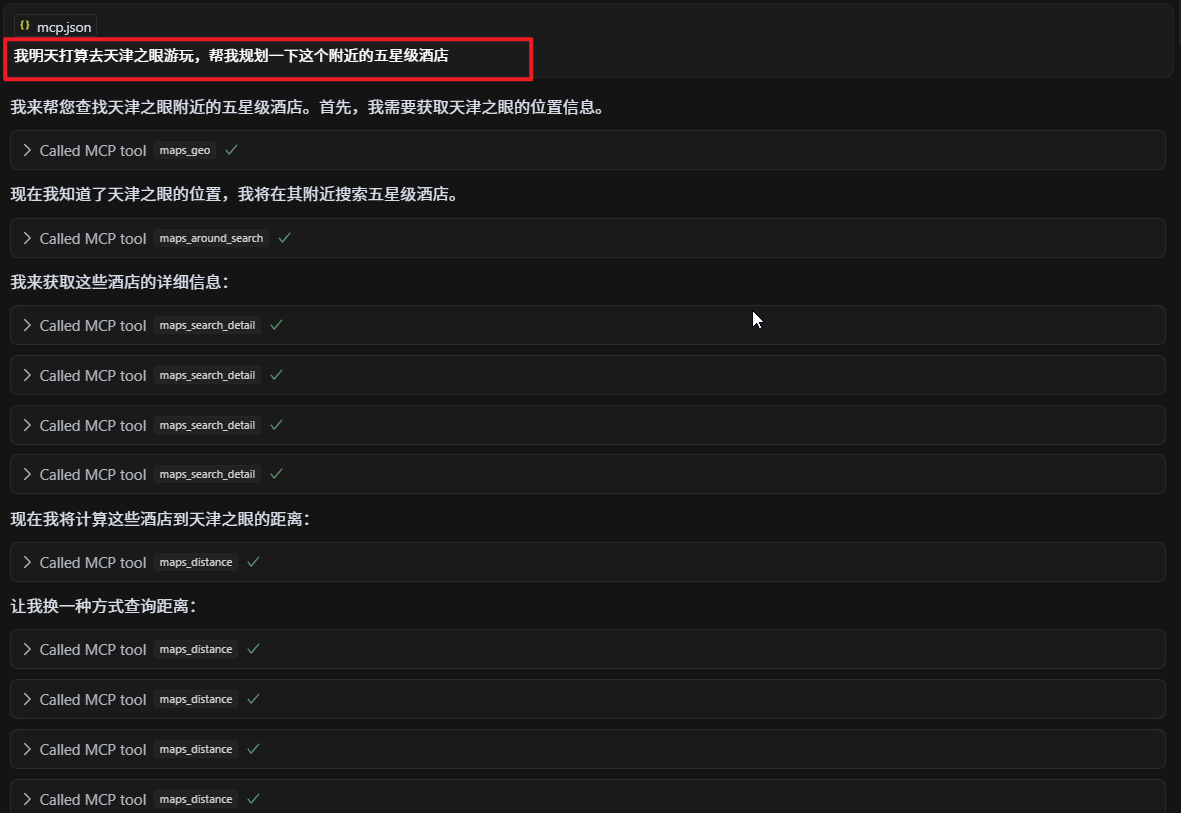
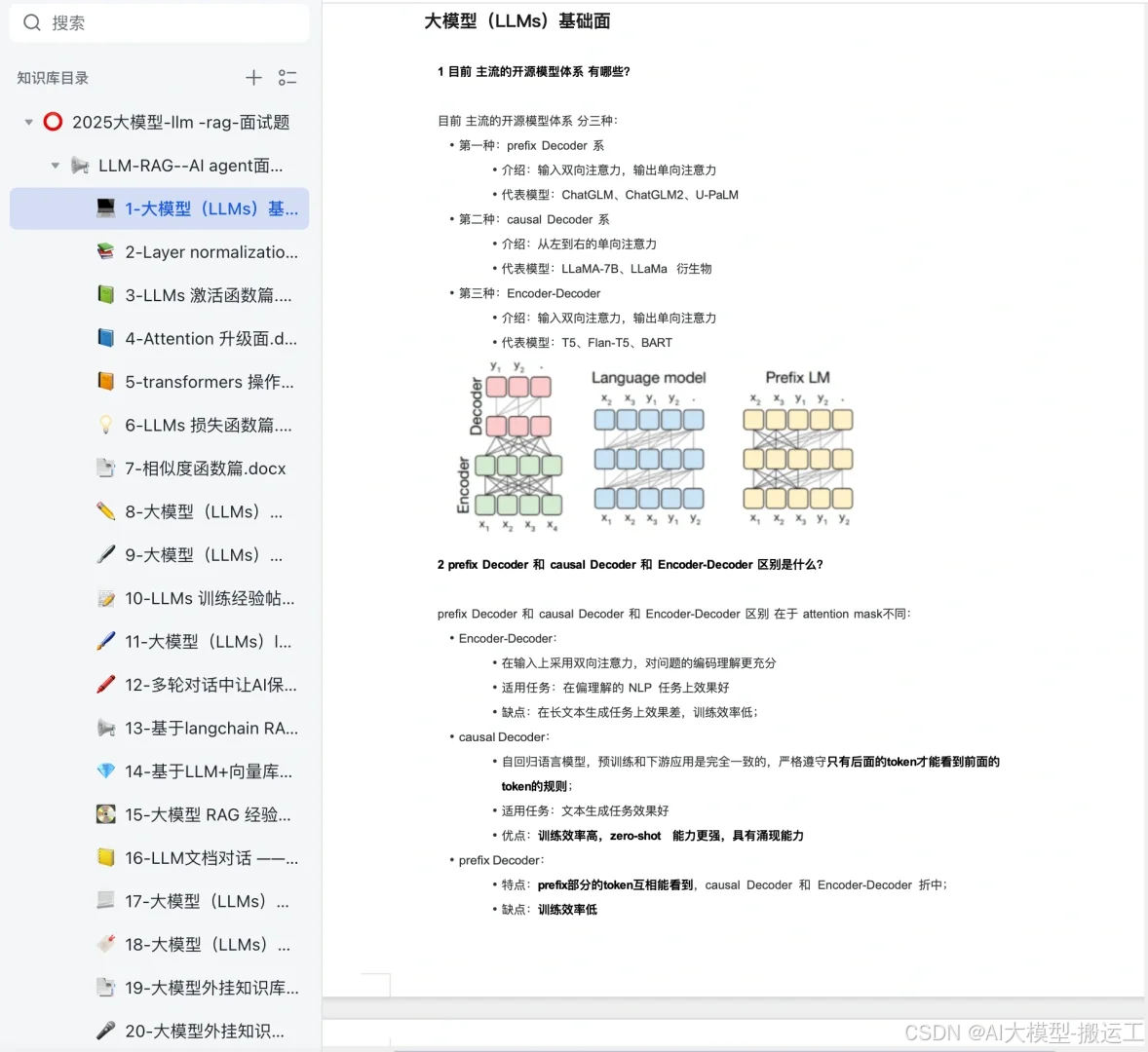
欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 18
18 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)