
Shap解释Stacking多分类模型(全套代码分享)
Shap解释Stacking多分类模型
用MLP、lightgbm、xgboost、catboost、adaboost、KNN6个模型组成Stacking模型,预测多分类任务,源数据从NHANES公开数据库下载,结果表明scacking模型的准确率和auc值最高,用bootstrap方法计算acc、auc等的置信区间,最后对模型进行shap分析,得到变量重要性排序
Stacking模型有两种shap分析的思路
第一种思路是把Stacking看成一个整体去分析,第二种思路是把stacking模型拆成两部分,分别分析一级学习器和二级学习器。这两种思路在代码里都实现了,具体看下文
数据说明:
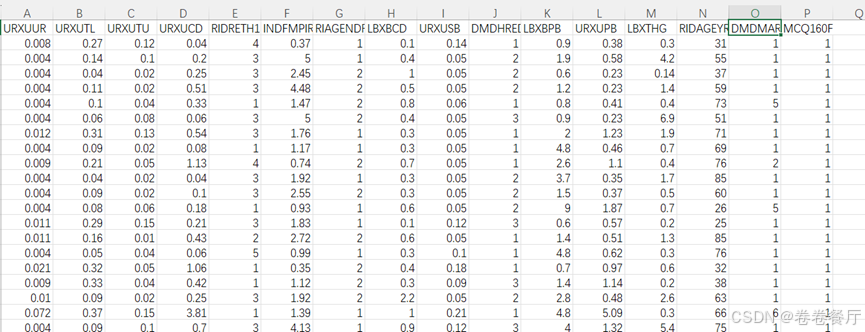
源数据在“mydata.xlsx“文件中,如下所示,A列到O列是自变量(共15个自变量),第一行是变量名称,数据是从nhanes数据库中下载的,不知道含义的可以在网站中搜索(NHANES Variables (clinicalscientists.cn))。P列是结局变量,0、1、2,三分类。
源代码使用说明:
代码文件是“shap解释stacking模型.py“,建议用pycharm打开,运行结束后可以看到所有的图片和变量。建模流程说明如下:
第一步 导入python第三方库
首先保证你安装了下图中的库,如果运行报错,可以查看各个库的版本是否太低,大于等于我用的版本就可以
Python版本:3.10.0
Pycharm版本:2024.1
Shap库版本:0.46.0
Pandas版本:2.2.3
Numpy版本:1.26.4
Sickit-learn版本:1.5.2
Xgboost版本:2.1.1
Lightbgm版本:4.5.0
Catboost版本:1.2.7
Matplotlib版本:3.9.2
第二步 读取数据
必须要自行修改的变量是path,替换成自己电脑中的文件路径即可
随后将数据拆分为训练集和测试集
print("开始读取数据")
input_size = 15 #自变量的数量
path = r"D:/PY文件/机器学习模型/shap解释stacking模型/"#定义文件路径
X = pd.read_excel(path + r'mydata.xlsx', header=None).values[1:,0:input_size] # 读取excel数据,转化为ndarray对象,去掉第一行的标签
y = pd.read_excel(path + r'mydata.xlsx', header=None).values[1:,input_size] # 对应目标变量(target),也就是类别标签,总共有3种分类
feature_name = pd.read_excel(path + r'mydata.xlsx', header=None).values[0:1,0:input_size].flatten() # 对应目标变量(target),也就是类别标签,总共有2种分类
#拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
y_test = y_test.astype(int)
y_train = y_train.astype(int)第三步 分别训练6个一级模型
6个一级模型分别为MLP、lightgbm、xgboost、catboost、adaboost、KNN,分别用网格搜索的方法找到最佳的模型参数
print("开始训练lightGBM模型")
#定义lightGBM模型
model_lgb = LGBMClassifier()
params_lgm = {
'boosting_type': ['gbdt'],
'num_class':[3],
'objective': ['multiclass'],
'max_depth': [6, 10],
#'metric': ['l2', 'auc'],
'num_leaves': [10,20],
'learning_rate': [0.05],
'verbose': [-1]
}
#定义具有多个超参数的lgb模型,对超参数进行网格搜索
lgb_cv = GridSearchCV(model_lgb, params_lgm, cv=5, scoring="accuracy")
#模型训练
lgb_cv.fit(X_train, y_train)模型训练完成之后进行评估,计算accuracy、precision、reacll、混淆矩阵、平均auc值等等
用bootstrap方法计算评估参数的置信区间,并进行输出
# 评估性能
acc_lgb, pre_lgb, rec_lgb, c_lgb, fpr_lgb, tpr_lgb, auc_lgb = Model_Evaluation(lgb_cv, X_test, y_test)
print("LGB模型的正确率", acc_lgb)
#计算模型评估参数的置信区间
y_pred_proba_lgb = lgb_cv.predict_proba(X_test)
auc_lgb_boot,acc_lgb_boot,spe_lgb_boot,sen_lgb_boot = Get_CI(y_test,y_pred_proba_lgb)#计算lgb模型auc、recall、precision等的置信区间
第四步 训练stacking模型
定义一级学习器和二级学习器(也就是元学习器,这里定义为随机森林模型)
print("开始训练Stacking模型")
# 定义一级学习器
base_learners = [
("MLP", model_mlp),
("XGB", xgb_cv),
("LGBM", lgb_cv),
("KNN", knn_cv),
("AdaBoost", ada_cv),
("CatBoost", cat_cv)
]
# 定义二级学习器
meta_model = RandomForestClassifier()
# 创建Stacking回归器
stacking_Classifier = StackingClassifier(estimators=base_learners, final_estimator=meta_model, cv=5)
# 用训练数据进行训练
stacking_Classifier.fit(X_train, y_train)训练完成后进行模型评估以及计算置信区间,与一级学习器相同
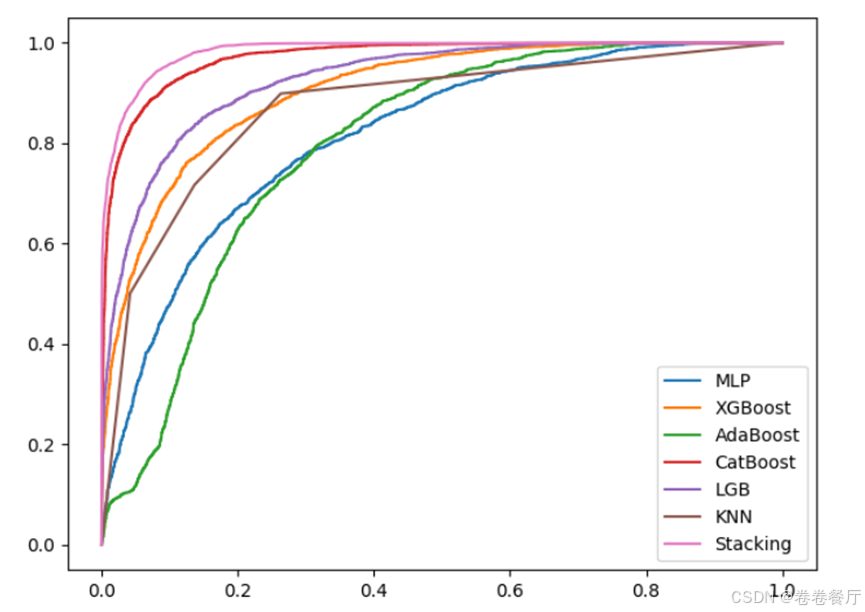
最后绘制6个单独的模型以及stacking模型的roc曲线,可以看到stacking模型的roc值最高
第五步 shap解释
一共有两种思路去解释scacking模型
第一种是把整个stacking模型看成一个完整的模型去分析,直接分析根据输入和输出去shap分析,这里只分析测试集的前100个样本,样本数量可以自行设置,数量越多相应的运行速度会越慢
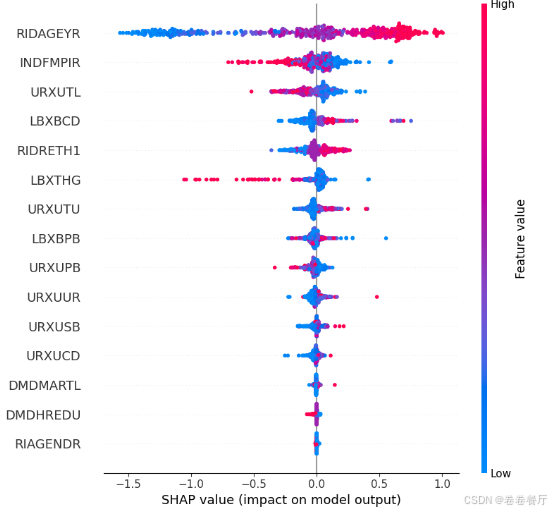
除了可以画自变量重要性散点图,还可以画变量依赖图
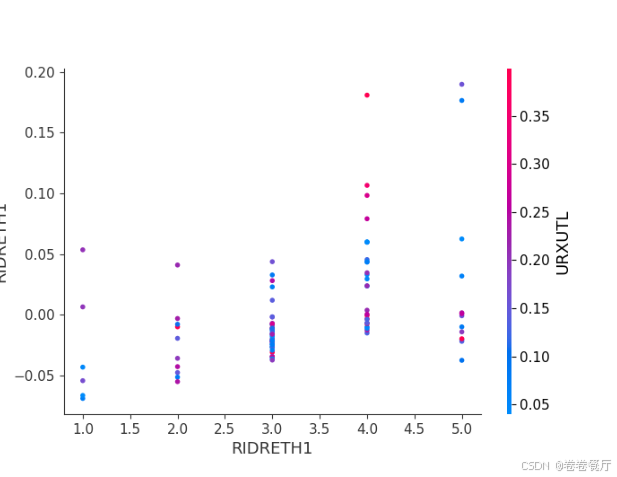
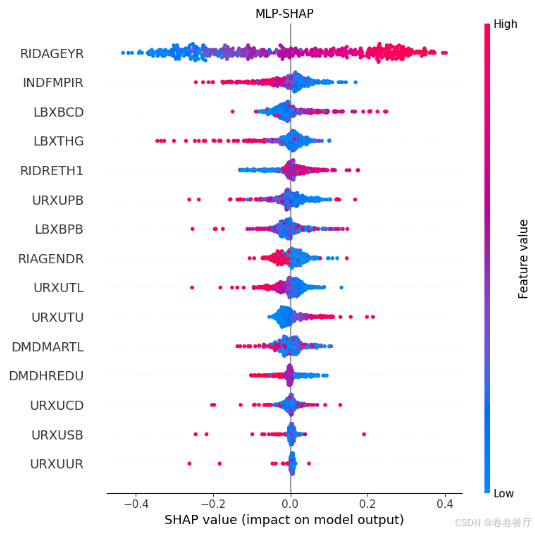
第二种思路是根据stacking模型的特性,shap分析每一个一级学习器的输出(这里只展示了其中一个模型的分析)
print("开始解释MLP模型")
#解释MLP模型,分析前500个样本,速度会快一点
mlp_ = stacking_Classifier.named_estimators_['MLP']
e_mlp = shap.Explainer(mlp_.predict_proba, X_test[:500,:].astype(float))
shap_values_mlp = e_mlp.shap_values(X_test[:500,:].astype(float))
#画第一类的变量重要性汇总图
shap.summary_plot(shap_values_mlp[:,:,0], X_test[:500,:], feature_names=feature_name)
#画第一类的变量重要性散点图
shap.summary_plot(shap_values_mlp[:,:,0], X_test[:500,:], plot_type="bar", feature_names=feature_name)
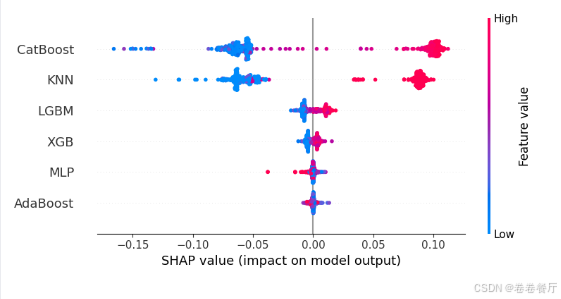
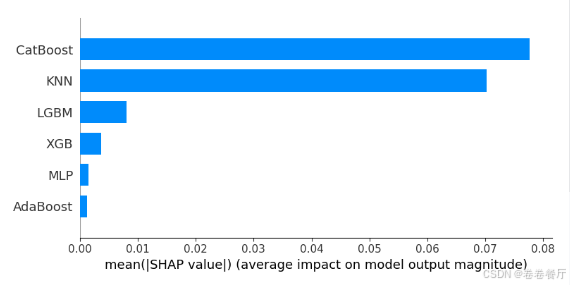
之后再分析二级学习器(元学习器)的输出,得到每个模型对输出的贡献度
代码纯手写,shap解释部分替大家踩了很多坑,终于整理出了可用的模板,谢谢理解~
【闲鱼链接】:闲鱼宝贝详情
包括数据集、源代码、运行结果图、说明文档
如链接失效,闲鱼或小红书搜索卷卷餐厅就可以看到啦

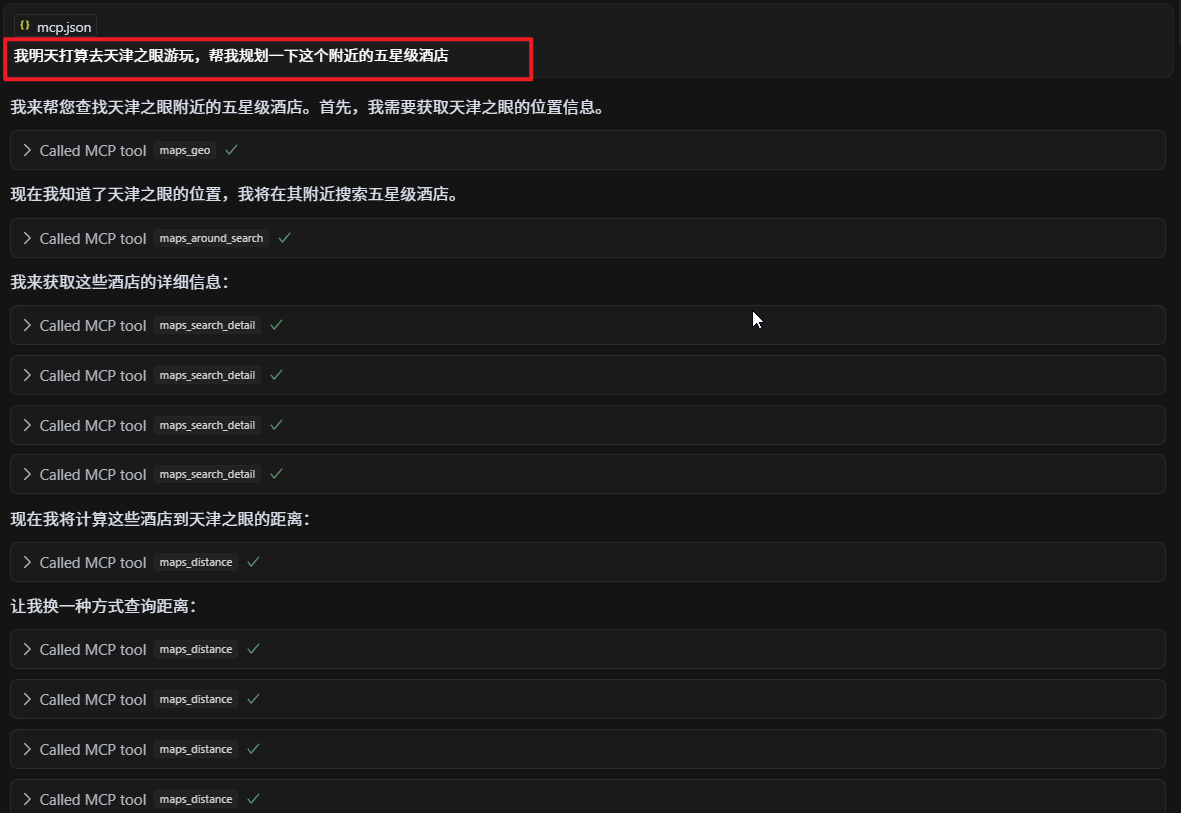
欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)