一文带你精通大模型agent,收藏这篇就够了
定义 Agent 要调用的工具,一个用于获取句子中不同汉字的数量的函数,同时将工具函数绑定到模型上12345678910defsentence):"""用于计算句子中不同汉字的数量"""set()forcharinsentence:if'\u4e00'<= char <='\u9fff'returnlen# 将工具函数绑定到模型上定义一个 Agent,用于处理用户输入、大模型输出及对输出内容解析:
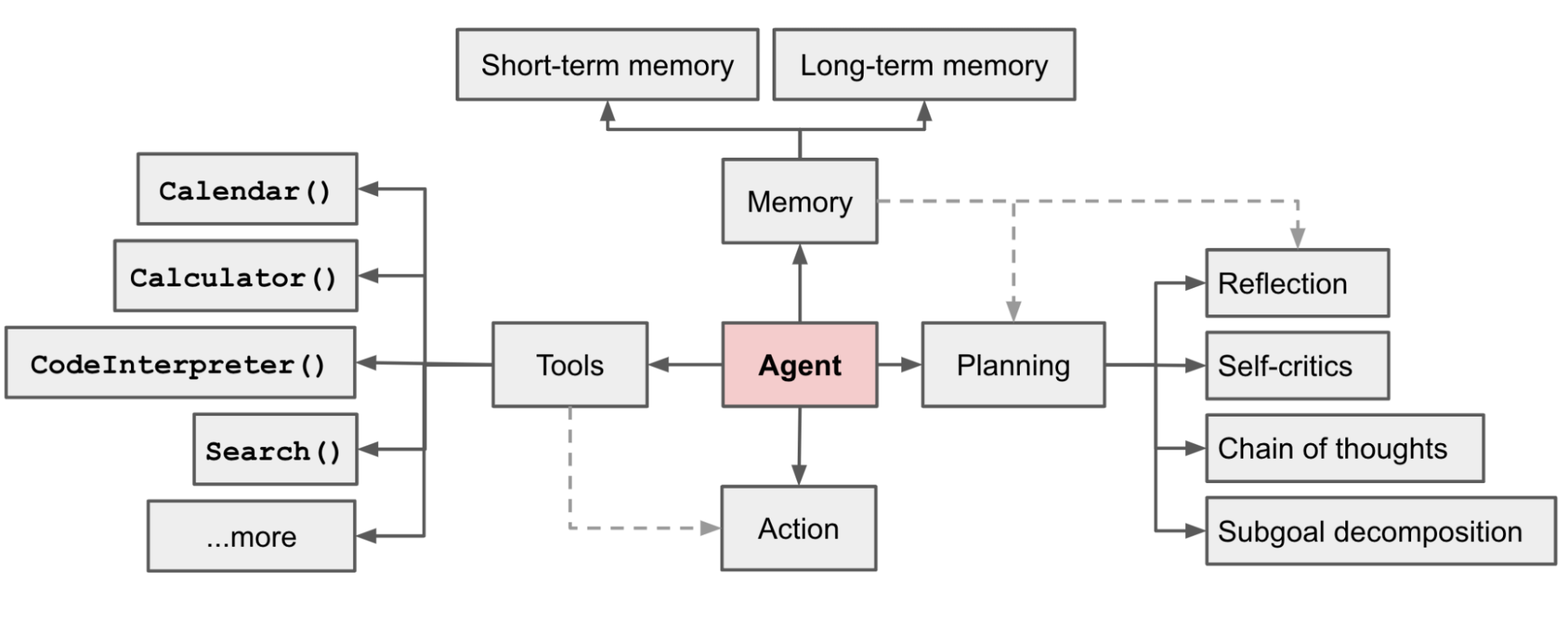
在 OpenAI AI 应用研究主管 Lilian Weng 的博客《大语言模型(LLM)支持的自主式代理》中,将规划能力视为关键的组件之一,用于将任务拆解为更小可管理的子任务,这对有效可控的处理好更复杂的任务效果显著。
人是如何做事的?
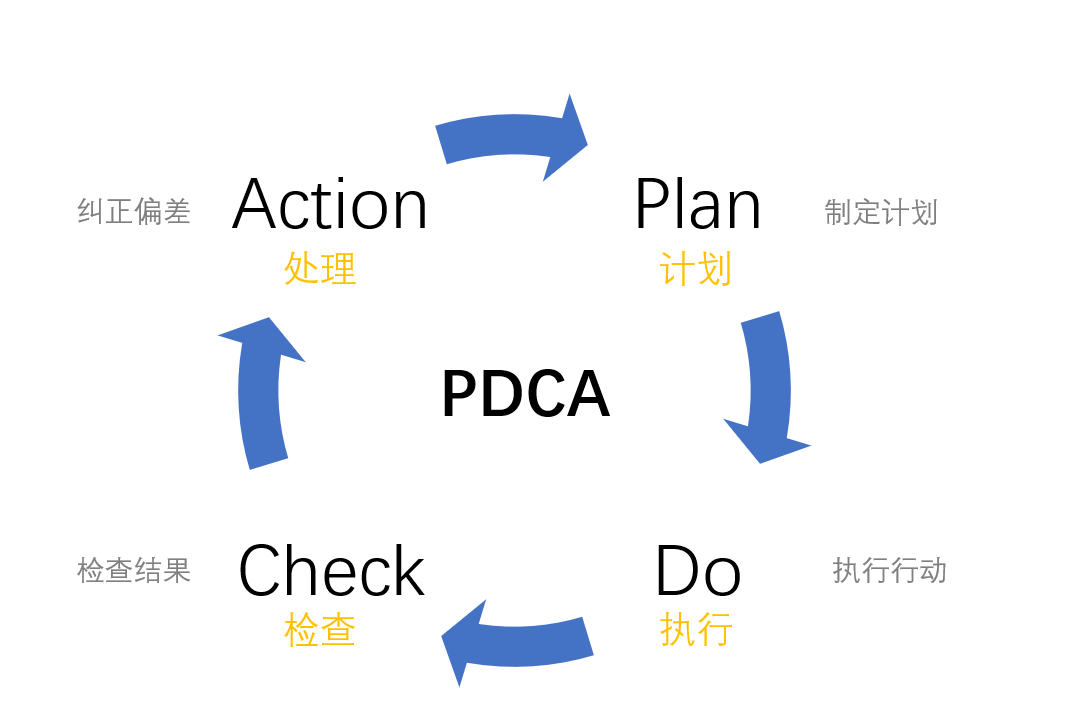
在日常工作中,我们通常将一项任务拆解成几个步骤:制定计划、执行计划、检查结果,然后将成功的作为标准,未成功的则留待下一次循环解决,这种方法已经被证明是高效完成任务的经验总结。
而这就是PDCA,是美国质量管理专家休哈特博士提出的,由戴明采纳、宣传,获得普及,所以又称戴明环。基于 PDCA 模型可以将一般项目分为四个阶段,即 Plan(计划)——Do(执行)——Check(检查)—— Act(处理)。把一件事情做出计划、然后实施计划、检查计划分析哪些出现了问题并提出解决方案、然后成功的纳入标准,不成功的进入下一个循环去解决,循环往复,从而形成一套标准化的流程。
Agent 是怎样工作的
而 Agent 的执行过程与人做事的方式类似,其中最有名的就是 ReAct 框架的思路,它来自论文《ReAct:在语言模型中协同推理与行动》,作者发现让 Agent 执行下一步行动的时候,加上大模型自己的思考过程,并将思考过程、执行的工具及参数、执行的结果放到提示词中,就能使得模型对当前和先前的任务完成度有更好的反思能力,从而提升模型的问题解决能力。
比如斯坦福 AI 小镇项目,AutoGPT等去年大火的 Agent 的项目,都可看到 ReAct 的思路,LangChain 框架中直接以 ReAct 为基础定义了几种代表性 Agent (CONVERSATIONAL_REACT_DESCRIPTION、ZERO_SHOT_REACT_DESCRIPTION 等)。
Thought: …
Action: …
Observation: …
…(重复以上过程,即表示 ReAct 的工作过程)
构建 Agent
下面通过代码构建一个最基本的 Agent,不过这里有必要提前了解几个关键概念,有助于更好地理解 Agent 的工作过程。
-
AgentAction:它主要包含两部分信息,tool表示 Agent 将要调用的工具的名称,tool_input表示传递给这个工具的具体输入。
-
AgentFinish:它有一个
return_values参数,是一个字典,该字典的output值表示要返回给用户的字符串信息。 -
intermediate_steps:表示 Agent 先前的操作及其相应的结果。它是一个列表,列表中的每个元素是一个包含
AgentAction和其执行结果的元组,这些信息对于未来的决策非常重要,因为它让 Agent 了解到目前为止已经完成了哪些工作。
定义工具
定义 Agent 要调用的工具,一个用于获取句子中不同汉字的数量的函数,同时将工具函数绑定到模型上
1 |
def count_unique_chinese_characters(sentence): |
定义 Agent
定义一个 Agent,用于处理用户输入、大模型输出及对输出内容解析:
1 |
prompt = ChatPromptTemplate.from_messages( |
Agent 执行
下面就是 Agent 的执行过程,主体实际是一个主循环,直到输出预期结果,实际情况中会对循环次数进行控制,以防止无休止执行下去,耗光资源
1 |
# 用于存储中间结果 |
一个最基本的 Agent 就构建结束了,这就是当下大家在各种文章上看到的产品层面构建 Agent(代理、智能体、智能代理、AI 代理等)的底层原理,其实很简单。
更复杂的任务
仔细观察上面的例子,很显然,只提供了一个工具,而且任务足够简单,当然可以清晰的执行,但是如果面对很复杂的任务场景,任务粒度拆解不细,导致执行步骤无法穷尽,循环就始终无法结束,这样的 Agent 也就无法完成复杂问题了。所以 Agent 要真正可用,任务拆解和规划是极为关键的一步,所以这方面也成为热门研究方向,下面将常见的思路简单介绍下:
- Zero-Shot(零样本提示,来自论文《微调后的语言模型是零样本学习者》):在提示词中简单地加入“一步一步思考”,引导模型进行逐步推理。
- Few- Shot(小样本提示,来自论文《语言模型是小样本学习者》):给模型展示解题过程和答案,作为样例(如果只提供一个样例,又叫 One-Shot),以便于解答新问题。
- COT(思维链,来自论文《链式思维提示在大型语言模型中引发推理》),思维链提示即将一个复杂的多步骤推理问题细化为多个中间步骤,然后将这些中间答案组合起来共同解决问题。其有效性已在这篇论文(揭示思维链背后的奥秘:一个理论视角)中得到验证。
- Auto CoT(来自论文《大型语言模型中的自动思维链提示》):大模型在解题前自动从数据集中查询相似问题进行自我学习,但需要专门的数据集支持。
- Meta CoT(来自论文《Meta-CoT:在大型语言模型中使用通用链式思考提示应对混合任务场景》):在 Auto CoT 的基础上,先对问题进行场景识别,进一步优化自动学习过程。
- **Least-to-Most ** (来自论文从简到难的提示使大型语言模型能够进行复杂推理):该策略的核心是把复杂问题划分成若干简易子问题,并依次解决,在处理每个子问题时,前一个子问题的解答有助于下一步。比如提示词中加入“针对每个问题,首先判断是否需分解子问题。若不需,则直接回答;若需,则拆分问题后,整合子问题解答,以得出最优、最全面及最确切的答案。”,启用大模型的思维模式,细化问题,从而获得更佳的结果。
- Self-Consistency CoT(来自论文自洽性可以提高语言模型中思维链的推理能力):在多次输出中选择投票最高的答案。自洽性利用了一个复杂推理问题通常有多种不同的思路,但最终可以得到唯一正确答案的本质,自洽性提升了思维链在一系列常见的算术和常识推理基准测试中的性能,比如在提示词中加入”对于每个问题,你将思考 5 种不同的想法,然后将它们结合起来,输出措辞最佳,最全面和最准确的答案。”
- TOT (全称 Tree of Thoughts,思维树,来自论文《思维树:利用大型语言模型进行深思熟虑的解决问题》):构建一个树状结构来存储各步推理过程中产生的多个可能结果作为末梢节点。在进行状态评估以排除无效结果之后,基于这些末梢节点继续进行推理,从而发展出一棵树。接着,利用深度优先搜索(DFS)或广度优先搜索(BFS)算法连接这些节点,形成多条推理链。最终,将这些推理链提交至一个大模型以评估哪个结果最为合适。
- GOT (全称 Graph of Thoughts,思维图谱,来自论文《思维图谱:用大型语言模型解决复杂问题》):思维图谱是将大型语言模型的输出抽象成一个灵活的图结构,其中思考单元作为节点,节点间的连线代表依赖关系。这种方式模拟人类解决问题的思维组合,它能合并多条推理链,自然回溯到有效的推理链,并行地探索独立的推理链,更贴近人类思维方式,从而增强了推理能力。
- Multi-Persona Self-Collaboration(来自论文《释放大型语言模型中的认知协同:通过多重人格自我协作的任务解决代理》):模拟多个角色协作解决问题。
在这些技巧中,Zero-Shot、Few-Shot、Self-Consistency 和 Least-to-Most 在提示词层面易于应用且效果显著。
上述论文中的思路已经在很多开源或商业 Agent 产品中采用了,就像我在这篇文章提到的, 当下的 AI 产品经理必须主动的去读论文。
读者福利:倘若大家对大模型抱有兴趣,那么这套大模型学习资料肯定会对你大有助益。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
学习路上没有捷径,只有坚持。但通过学习大模型,你可以不断提升自己的技术能力,开拓视野,甚至可能发现一些自己真正热爱的事业。
最后,送给你一句话,希望能激励你在学习大模型的道路上不断前行:
If not now, when? If not me, who?
如果不是为了自己奋斗,又是为谁;如果不是现在奋斗,什么时候开始呢?

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 27
27 0
0- 0



 已为社区贡献95条内容
已为社区贡献95条内容

所有评论(0)