Attention机制在问答系统中的应用:QA-CNN,QA-biLSTM,AP-CNN和AP-biLSTM 参考论文Attentive Pooling Networks
文章目录摘要代码(Pytorch)经典问答系统模型简述基于attention机制的问答系统简述实验参数设定与实验结果摘要本文复现和整理了关于问答系统的4个经典模型:QA-CNN,QA-biLSTM,AP-CNN和AP-biLSTM。其中AP-CNN和AP-biLSTM是对前两种模型的改进,即引入了attention机制。主要参考论文《Attentive Pooling Networks》Co-at
文章目录
摘要
本文复现和整理了关于问答系统的4个经典模型:QA-CNN,QA-biLSTM,AP-CNN和AP-biLSTM。其中AP-CNN和AP-biLSTM是对前两种模型的改进,即引入了attention机制。主要参考论文《Attentive Pooling Networks》
Co-attention机制是近年来新出现的处理序列信息匹配的机制。
本文末尾给出了模型代码和实验结果。
经典问答系统模型
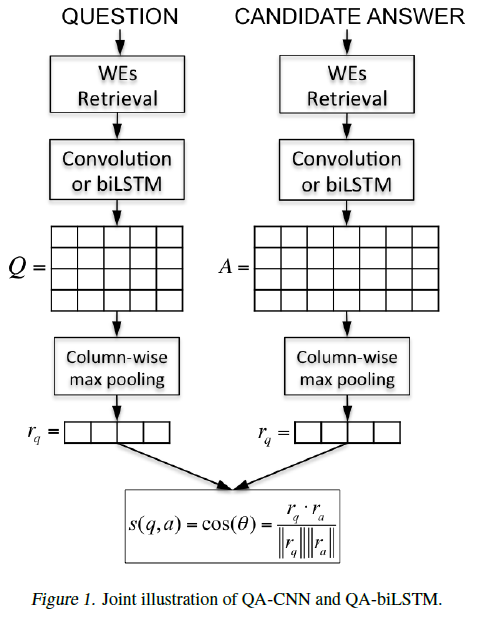
问题文本和答案文本分别喂入两个同样的CNN或LSTM网络。若编码层采用卷积网络CNN处理,称模型为QA-CNN;若编码层采用双向循环神经网络biLSTM处理,称模型为QA-biLSTM。
问题文本经过embedding、编码层、池化层后,得到一个向量表达 r q r_q rq;答案文本同理得到向量表达 r a r_a ra。然后用 r q r_q rq和 r a r_a ra的cosine距离来衡量该问题和该答案的匹配程度(也就是该答案能否回答该问题)。cosine距离越接近1,则匹配程度越高,越接近-1,则匹配程度越低(即答非所问)。
特别注意,编码层是共享的!即图中Convolution or biLSTM在模型中是同一个编码器。同样embedding层也是共享的,即WEs Retrieval。
基于attention机制的问答系统
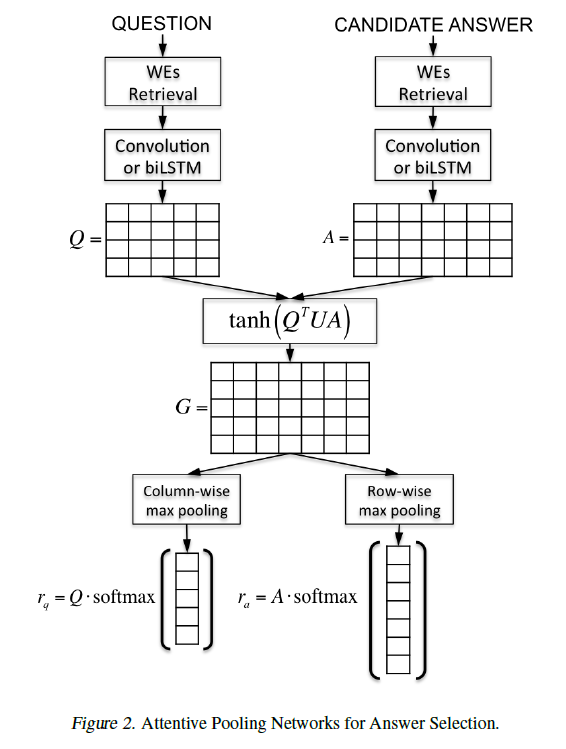
对编码层的输出Q和A做attention处理:
G = tanh ( Q T U A ) G=\tanh(Q^TUA) G=tanh(QTUA)
其中 U U U是可学习参数。这样做的目的是让Q和A的每两个单词间计算一下匹配分值。 G i j G_{ij} Gij表示问题第 i i i个单词与答案第 j j j个单词的匹配分值(也就是相关程度)。然后通过对 G G G求列最大池化(即每行最大值组成的列向量)得到问题的每个单词的重要程度得分,同理求行最大池化得到答案的每个单词的重要程度。再用这个重要程度向量作为概率分布(Attention),去抽取Q(或A)中的编码,重要程度高的单词的编码将以较大的比重累加给 r q r_q rq。
实验
pytorch实现模型:https://github.com/winter1997/Attentive-Pooling-Networks
实验设定与实验结果:https://github.com/winter1997/Attentive-Pooling-Networks#experiment

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)