《DINO: 基于改进去噪锚框的端到端目标检测模型》学习笔记
我们提出了DINO(DETR with Improved deNoising anchOr boxes),这是一种最先进的端到端目标检测器。(1)对比学习方法的去噪训练;通过对比学习的方式降低训练过程中的噪声干扰,提升了模型的鲁棒性和准确性。去噪训练可能涉及到对负样本的区分和增强。(2)用于锚点初始化的混合查询选择方法;为锚点(Anchor Boxes)的初始化设计了一种混合策略,可能结合了动态和
paper:https://arxiv.org/pdf/2203.03605
Github:https://github.com/IDEA-Research/DINO
目录
3、CDN 对比去噪训练(Contrastive DeNoising Training )
4、混合查询选择 (Mixed Query Selection)
摘要
我们提出了DINO(DETR with Improved deNoising anchOr boxes),这是一种最先进的端到端目标检测器。DINO通过以下技术在性能和效率上超越了以往的DETR类模型:
(1)对比学习方法的去噪训练;
通过对比学习的方式降低训练过程中的噪声干扰,提升了模型的鲁棒性和准确性。去噪训练可能涉及到对负样本的区分和增强。
(2)用于锚点初始化的混合查询选择方法;
为锚点(Anchor Boxes)的初始化设计了一种混合策略,可能结合了动态和静态查询机制以优化检测精度。
(3)用于框预测的两次前瞻(look forward twice)策略。
在预测边界框时,进行了两次前瞻计算,提高了预测框的准确性。
在使用ResNet-50主干网络和多尺度特征时,DINO在COCO数据集上实现了12个训练轮次下49.4 AP(准确率)和24个训练轮次下51.3 AP,分别比之前最佳的DETR类模型DN-DETR显著提升了+6.0 AP和+2.7 AP。DINO在模型规模和数据规模上具有良好的扩展性。在不使用任何附加优化技巧的情况下,DINO在使用SwinL主干网络并在Objects365数据集上预训练后,在COCO val2017上达到了63.2 AP,在test-dev上达到了63.3 AP,取得了最好的结果。与排行榜上的其他模型相比,DINO在显著减少模型规模和预训练数据规模的同时,取得了更好的结果。
一、框架
1、预备知识
根据Conditional DETR和DAB-DETR的研究,明确了DETR中的查询由两个部分组成:位置部分和内容部分。在本文中,它们分别被称为位置查询和内容查询。DAB-DETR 明确将DETR中的每个位置查询公式化为一个四维锚框(x, y, w, h),其中x和y是锚框的中心坐标,w和h分别是锚框的宽度和高度。这种显式的锚框公式化使得可以在解码器中逐层动态优化锚框。
DN-DETR 引入了一种去噪(DN)训练方法,以加速DETR类模型的训练收敛。研究表明,DETR中的训练收敛缓慢问题源于二分图匹配的不稳定性。为了解决这一问题,DN-DETR建议将带有噪声的真实标签和边界框额外输入到Transformer解码器中,并训练模型重建这些真实值。添加的噪声(∆x, ∆y, ∆w, ∆h)受以下约束条件限制:
其中(x, y, w, h)表示一个真实边界框,λ是控制噪声尺度的超参数。由于DN-DETR遵循DAB-DETR将解码器查询视为锚框的视角,带噪声的真实框可以被视为一个特殊的锚框,其附近存在一个真实边界框(因为λ通常很小)。
除了原始的DETR查询外,DN-DETR增加了一个DN部分,该部分将带噪声的真实标签和边界框输入到解码器中以提供辅助的DN损失。DN损失有效地稳定并加速了DETR的训练过程,并且可以无缝地集成到任何DETR类模型中。
位置查询:负责锚框的位置信息,决定边界框的坐标和尺寸。
内容查询:负责对象的语义信息,确定目标的类别和特征。
DN-DETR的改进:在真实标签和边界框中添加受限噪声(∆x, ∆y, ∆w, ∆h),通过训练模型重建带噪声样本的原始值,增强模型对不确定性的鲁棒性。
Deformable DETR是另一项早期加速DETR收敛的工作。为了计算可变形注意力,它引入了参考点的概念,使可变形注意力能够关注参考点周围的一小组关键采样点。参考点的引入使得可以开发出几种进一步提升DETR性能的技术:
查询选择(query selection):直接从编码器中选择特征和参考框作为解码器的输入。
边界框迭代优化:防止后续梯度对前一层产生干扰,在两个解码器层之间设计了一个梯度分离机制,从而优化边界框。本文中,我们将这一梯度分离技术称为“单次前瞻”(look forward once)。
在DAB-DETR和DN-DETR的基础上,DINO将位置查询公式化为动态锚框(延续DAB-DETR对位置查询的锚框公式化方法。),并通过额外的去噪损失(结合DN-DETR的去噪训练方法,提升收敛速度与稳定性。)进行训练。需要注意的是,DN-DETR也借鉴了Deformable DETR的一些技术来提高性能,包括其可变形注意力机制和“单次前瞻”在层参数更新中的应用。DINO进一步采用了Deformable DETR中的查询选择方法,以更好地初始化位置查询。
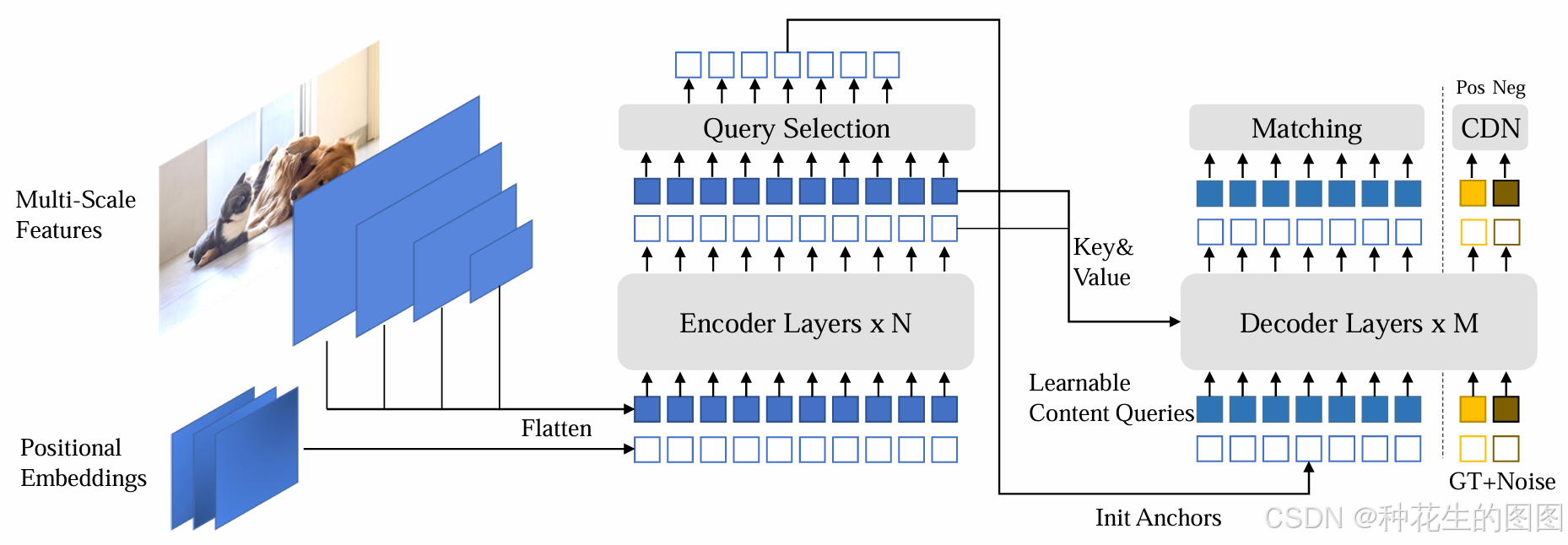
2、模型概述
如图所示,DINO是一个端到端的架构,包含一个主干网络、多层Transformer 编码器、多层Transformer解码器以及多个预测头。
1、输入
Multi-Scale Features(多尺度特征):图像首先通过主干网络(如ResNet或Swin Transformer),生成不同尺度的特征图。这些特征捕获了目标在不同空间尺度上的信息,用于更准确地检测小目标和大目标。
Positional Embeddings(位置嵌入):为多尺度特征添加位置编码,帮助模型理解目标在图像中的空间位置信息。
2、编码器
Encoder Layers × N(编码器层):由多层Transformer编码器组成,用于增强输入特征。
- 输入:多尺度特征和位置嵌入。
- 输出:增强后的特征图,包含了上下文信息和空间位置信息。
3、查询选择(Query Selection)
编码器输出特征后,DINO通过混合查询选择策略来初始化解码器的查询,需要注意的是,该策略不初始化内容查询,而是将其设置为可学习状态。
- 位置查询(Positional Queries):从编码器输出中选择锚框作为查询的初始化,用于捕获目标的位置信息。
- 内容查询(Content Queries):保持可学习状态,由模型在训练过程中动态调整,捕获目标的语义信息。
4、解码器
Decoder Layers × M(解码器层):由多层Transformer解码器组成,逐层更新查询。
Deformable Attention(可变形注意力):通过聚焦于关键采样点(而非全局特征),高效地结合编码器输出特征,逐层优化位置和内容查询。
在传统的 Transformer 注意力机制 中,每个查询(query)需要计算与所有特征点(key)之间的注意力权重,然后将所有特征点的加权和作为输出。这种方法有以下问题:
- 计算开销高:当输入特征图分辨率较高时,注意力计算的复杂度是
,其中
是特征点的数量。
- 冗余:很多特征点可能对目标区域的表示并无贡献(例如背景区域),却仍被计算进来。
可变形注意力 通过引入“参考点”和“采样点”的概念,有效解决了上述问题。
核心思想:
1、参考点(Reference Points)
每个查询都会生成一个参考点,这个参考点指示目标大致的位置。例如:
- 在目标检测中,参考点可以是预测边界框的中心。
- 通过参考点,模型可以专注于与目标相关的区域,而不是处理整个特征图。
2、采样点(Sampling Points)
参考点出发,在其周围采样少量关键点(例如 4 或 8 个),用于计算注意力。采样点的位置是动态生成的,可以灵活调整,具体表现为:
- 每个采样点的位置相对于参考点有一个偏移量。
- 偏移量是通过神经网络学习得到的。
3、注意力计算
- 只针对采样点计算注意力权重,而不是对整个特征图计算。
- 采样点的特征加权求和后,作为查询的输出。
输出:
- Refined Anchors(优化后的锚框):表示目标的最终位置。
- Classification Results(分类结果):目标类别的预测。
5、对比去噪训练(CDN)
结合DN-DETR的去噪训练方法,DINO通过添加噪声样本(GT + Noise)来改进目标检测性能,通过引入困难负样本的对比学习方法,增强模型的鲁棒性,避免重复预测或漏检目标。
- 正样本(Positive):带较小噪声的真实框。
- 负样本(Negative):带较大噪声的真实框。
6、梯度优化(Look Forward Twice)
为充分利用解码器后续层优化的锚框信息,DINO引入了两次前瞻(Look Forward Twice)策略,允许后续层的梯度对相邻早期层进行反馈,从而优化整个解码器的层间信息传递。
3、CDN 对比去噪训练(Contrastive DeNoising Training )
CDN 是 DINO 中提出的一种改进的对比去噪训练方法,主要解决了 DN-DETR 中对“无目标”的预测能力不足的问题。
虽然正样本和负样本都表示为可以在四维空间中表示的锚框(4D anchors),但为了简化,我们将它们示意为二维空间中同心方框上的点。如右图所示,假设方框的中心是一个真实框(GT box),那么内方框内的点被视为正样本,而内外方框之间的点被视为负样本。
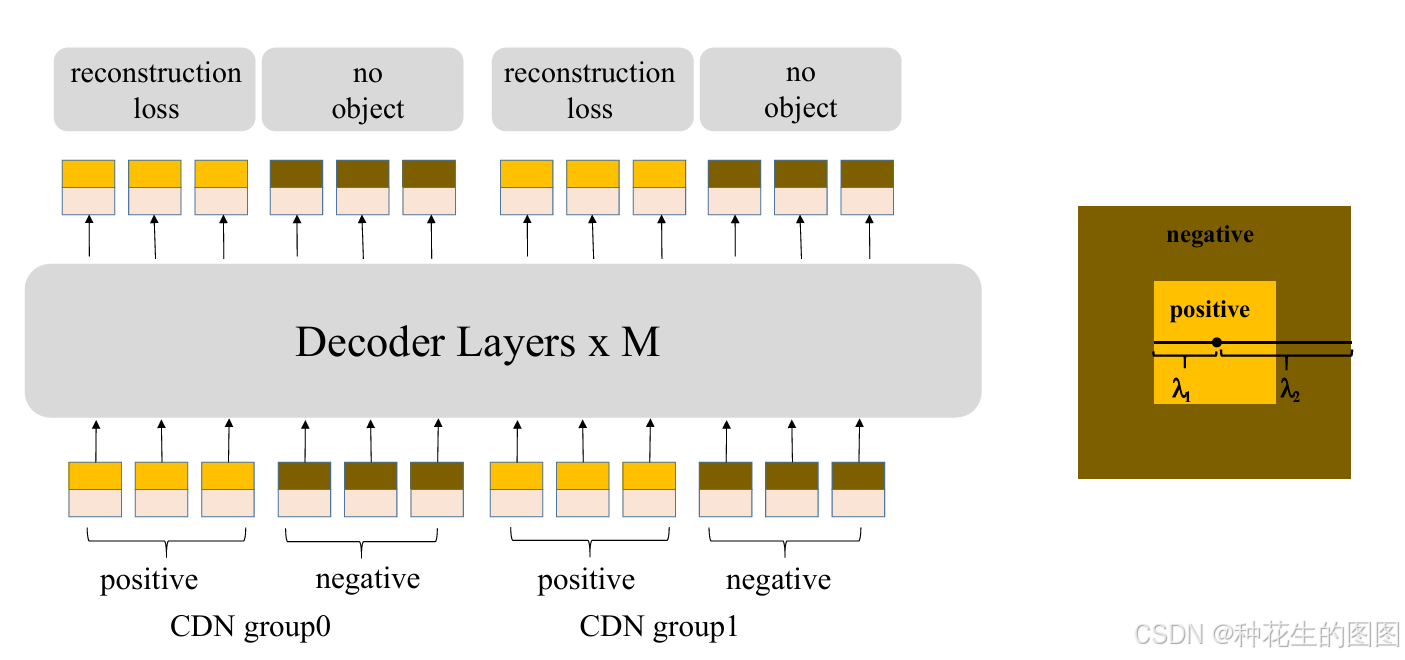
CDN 引入了两个超参数和
,并且
。
正样本查询(Positive Queries):位于内方框内的噪声尺度小于。模型的目标是重建这些查询对应的真实框。
负样本查询(Negative Queries):位于内外方框之间,噪声尺度在 和
之间。模型的目标是预测“无目标”。通常选择较小的
,因为靠近真实框的“困难负样本”对于提高性能更有帮助。
如果一张图像有个真实框,每个 CDN 组会生成
个查询(每个真实框生成一个正样本和一个负样本)。
损失函数:重建损失包括和 GIoU 损失(用于边界框回归)以及 Focal Loss(用于分类)。分类负样本为背景类别的损失也使用 Focal Loss。
CDN 的方法之所以有效,是因为它能够抑制锚点间的混淆,并选择高质量的锚点进行边界框预测。当多个锚点靠近同一个目标时,模型难以决定选择哪个锚点,这可能导致以下问题:
- 重复预测:尽管基于集合的损失和自注意力机制可以抑制重复预测,但效果有限。
- 选择错误锚点:可能选择距离目标更远的锚点。
CDN的改进:
- 通过正负样本训练,CDN 能够区分锚点间的细微差异,从而避免重复预测。
- 同时,CDN 教会模型拒绝距离真实框较远的锚点,从而进一步提升性能。
评价指标:
其中, 是真实框,
是对应的初始锚框。
选取
个最大的距离。选择
是因为混淆问题更可能发生在匹配较远锚点时。
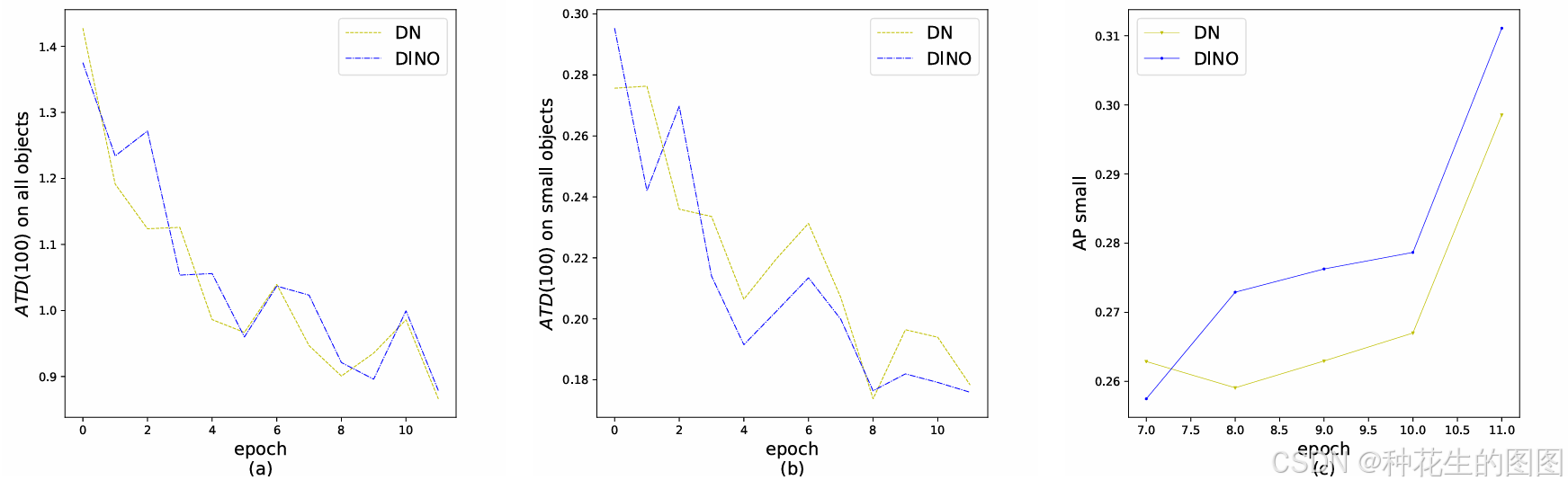
图(a)(b):分别在所有物体及小型物体上 ATD( 100 );( c ):小物体上的AP。 (CDN 方法在小目标检测上相比 DN 查询提升了 +1.3 AP)

左图为使用DN查询训练的模型的检测结果,右图为使用CDN的检测结果
在左图中,箭头所指的男孩有3个重复的边界框。
4、混合查询选择 (Mixed Query Selection)
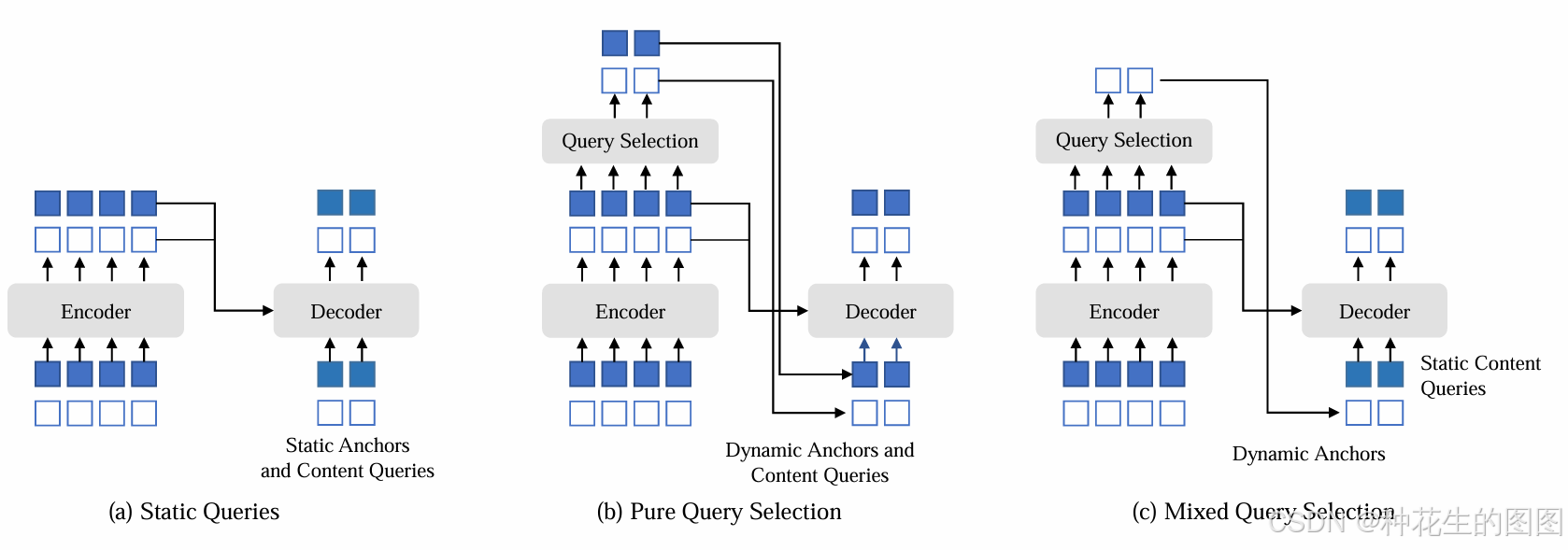
如图 (a) 所示,在 DETR和 DN-DETR中,解码器查询(decoder queries)是静态嵌入,与特定图像的编码器特征无关。它们直接从训练数据中学习锚框(在 DN-DETR 和 DAB-DETR 中)或位置查询(在 DETR 中),并将内容查询初始化为全零向量。Deformable DETR同时学习位置和内容查询,这是另一种静态查询初始化的实现。
如图(b)所示,为了进一步提升性能,Deformable DETR 提出了一个查询选择变体,从最后一层编码器中选择前 个特征作为先验,用于增强解码器查询。位置查询和内容查询都通过选定特征的线性变换生成。此外,这些选定特征被输入到一个辅助检测头,用于预测边界框,并将这些边界框用于初始化参考框。同样,Efficient DETR也根据每个编码器特征的目标性(类别)分数选择前
个特征。
如图(c)所示,DINO中混合查询选择方法查询的动态 4D 锚框公式使其与解码器的位置查询紧密相关,而位置查询可以通过查询选择得到改进。仅使用与所选前 个特征相关联的位置信息来初始化锚框,但仍将内容查询保持为静态向量(如以往一样)。
需要注意的是,Deformable DETR 使用前 个特征同时增强位置查询和内容查询。然而,由于这些选定特征只是初步内容特征,未经过进一步优化,它们可能会对解码器产生歧义和误导。例如,一个选定的特征可能同时包含多个目标或仅是一个目标的一部分。
与此形成对比的是,DINO的混合查询选择方法仅利用前 个选定特征增强位置查询,而保持内容查询的可学习性。这种方法帮助模型使用更好的位置信息,从编码器中提取更全面的内容特征。
| 方法 | 查询类型 | 查询增强方式 | 潜在问题 | DINO 改进点 |
|---|---|---|---|---|
| DETR / DN-DETR | 静态嵌入 | 无 | 查询与具体图像无关 | 引入动态锚框 |
| Deformable DETR | 动态嵌入 | 前 |
内容特征未经优化可能产生歧义 | 仅用前 |
| DINO | 动态锚框 | 前 |
无 | 更精确的查询选择 |
5、双次前瞻(Look Forward Twice)
本节中提出了一种新的边界框预测方法。Deformable DETR中的边界框迭代优化通过阻断梯度反向传播来稳定训练过程。我们将这种方法称为“单次前瞻(look forward once)”,因为如图(a)所示,第 层的参数仅基于该层辅助损失(即边界框
的损失)进行更新。
然而,我们推测后续层优化得到的边界框信息可能对其相邻的早期层更有帮助。因此,我们提出了另一种方法,称为“双次前瞻(look forward twice)”,用于边界框的更新。在这种方法中,第 层的参数同时受到第
层和第
层损失的影响,如图(b)所示。对于每个预测的偏移量
,它将被用来更新两次边界框,一次是更新
,另一次是生成
。因此,我们将这种方法命名为“双次前瞻”。
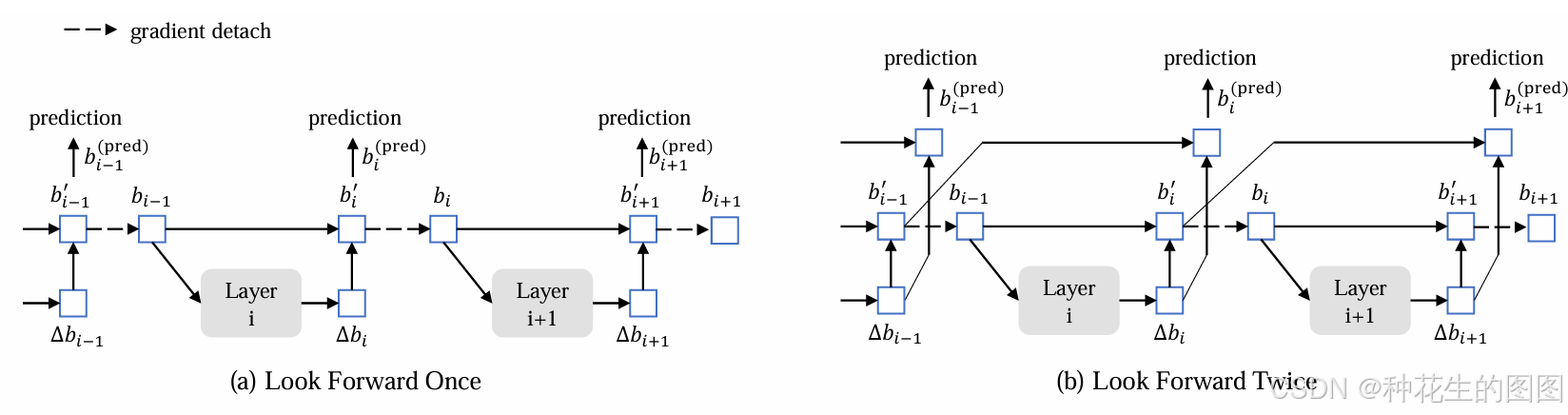
边界框预测的最终精度由两个因素决定:
- 初始框
的质量。
- 预测偏移量
的质量。
单次前瞻方法仅优化后者,因为梯度信息从第层到第
层是断开的。
而在双次前瞻中,同时优化初始框和预测框偏移量
。一种简单的改进初始框质量的方法是使用下一层输出的
来监督第
层的最终框
。因此,我们将
和
的和作为第
层的预测框。
对于输入框到第
层,最终预测框
的生成过程如下:
其中, 是未断开梯度版本的
,
是一个根据预测偏移量
优化边界框
的函数。
二、参考博客

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)