DrivingDiffusion原文阅读
以前的工作有单视图驾驶视频生成(Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models)和本文最相关的(BEVGen:BEV布局(BEV分割掩码)生成多视角城市场景图像)基于图像合成扩散模型,把3D布局作为扩散模型的附加控制信息。包含:1)多视图单帧图像生成模型2)多摄像头共享的单视图时间模型
摘要
文章目的: 利用扩散模型生成时空一致的自动驾驶视频数据集。
挑战:
1)空间一致性:即多视角视图具有一致性
2)时间一致性:即多帧图像具有一致性
3)保证生成实例的质量:生成实例需要有意义(人/车)
解决:
1)交换相邻相机信息达到空间一致性
2)从第一帧的多视图图像中查询后续帧生成中需要注意的信息
3)引入局部提示提高生成实例质量
4)后处理步骤增加跨视图一致性+滑动窗口算法扩展视频长度
介绍
以前的工作有单视图驾驶视频生成(Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models)
和本文最相关的(BEVGen:BEV布局(BEV分割掩码)生成多视角城市场景图像)
本文:
基于图像合成扩散模型,把3D布局作为扩散模型的附加控制信息。包含:1)多视图单帧图像生成模型2)多摄像头共享的单视图时间模型3)后处理增强生成帧的一致性的多视图模型(跨视图注意模块)和扩展视频的滑动窗口处理。
方法
3.1 介绍了使用的潜在扩散模型,实际上就是把输入图像编码到隐空间,利用这个编码后的信息进行加噪和去噪,去噪后的结果解码回图像。
3.2 DrivingDiffusion
概要
图像合成的模型通常使用U-Net架构,由包含大量卷积、残差、注意块(自注意、交叉注意力和前馈网络)的模块构成,需要两轮空间下采样和上采样。
视频合成通常单帧合成再扩展到时间维度的多帧。(本文基础模型)
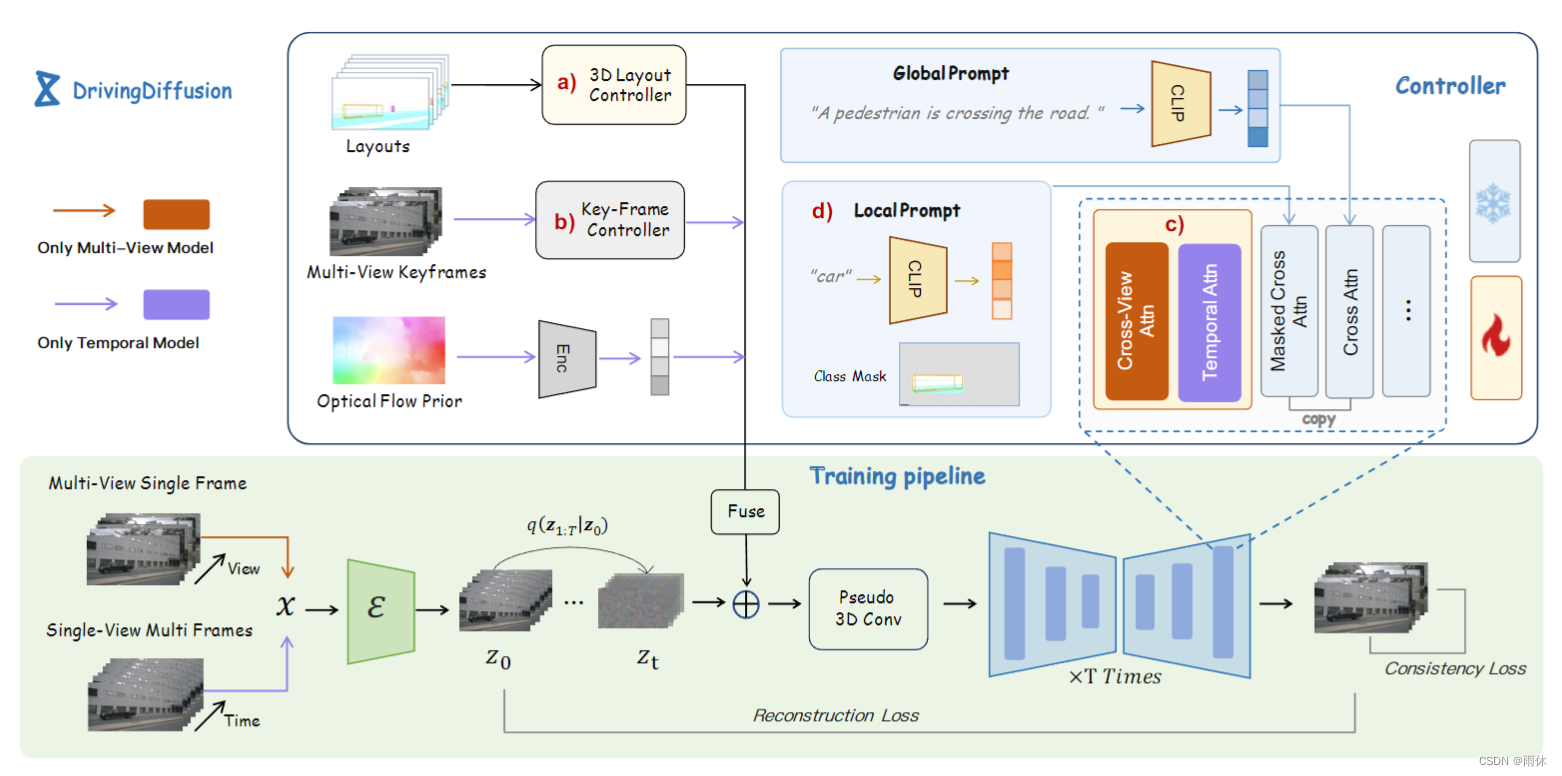
额外加入: 3D布局控制器、关键帧控制器、夸试图、跨帧一致性模块、本地提示引导模块。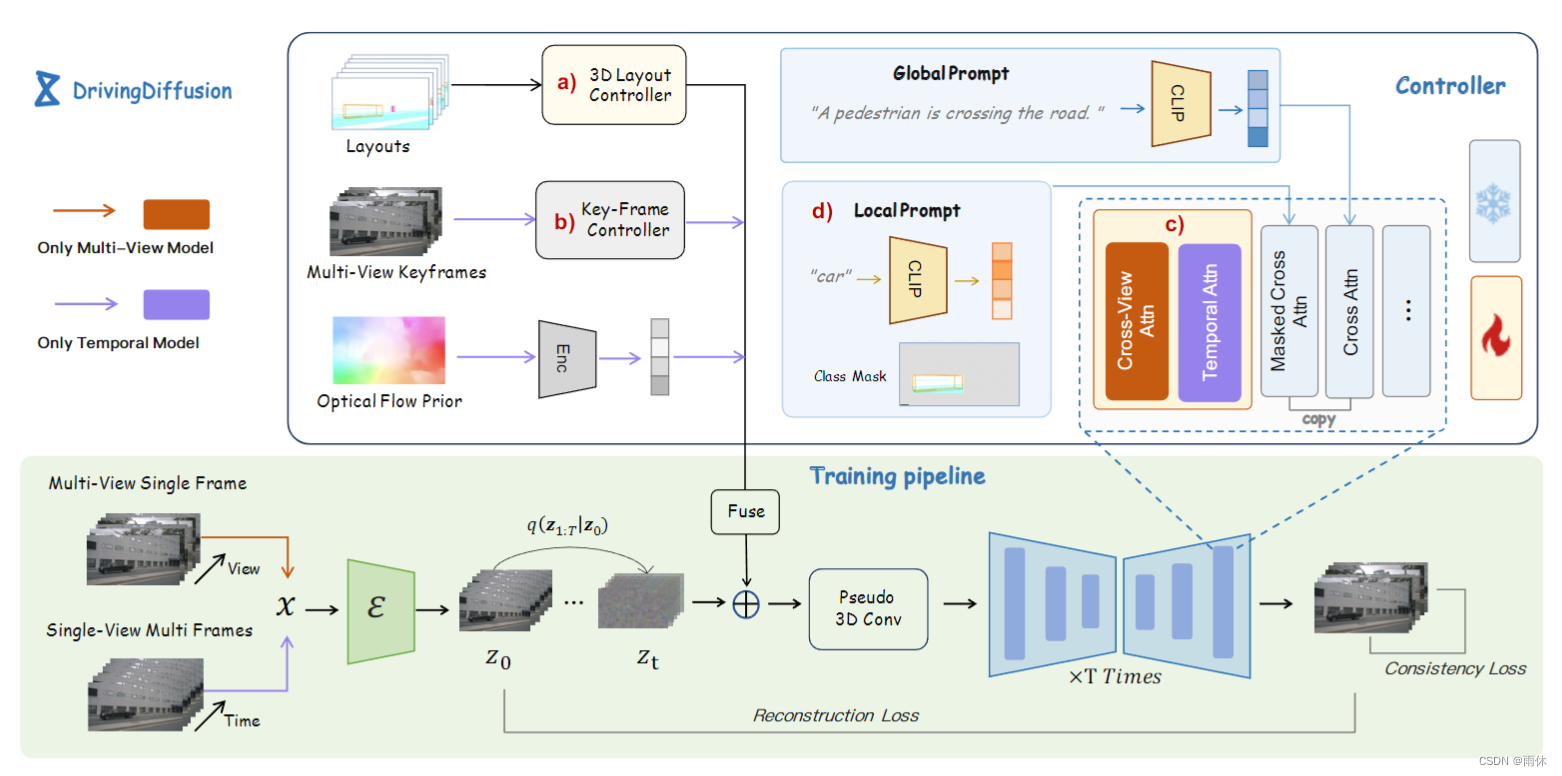
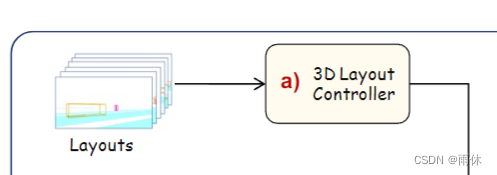
3D布局控制器
1)使用相机参数将道路结构和每个实例投影到3D布局图像上,合并每个像素对应的道路结构信息,目标类别和目标实例ID,并将该信息编码为RGB值。
2)将图像输入3D布局控制器中(类似ResNet),以对应于不同级别的特征的不同分辨率(即 64 × 64、32 × 32、16 × 16、8 × 8)对 U-Net 模型进行编码。
3)通过残差连接将不同分辨率的附加控制信息注入到U-Net模型的每一层中
这部分应该对应的是图中的Layouts和a)部分
多视角模型
对于多视图单帧模型,我们使用所有视图的 3D 布局作为输入,以及场景的文本描述,以生成高度对齐的多视图图像。在这个阶段,我们只使用了一个 3D 布局控制器。
这部分是整体管道中除了紫色其他部分,文章中的训练一共分成了两阶段,第一阶段就是通过多视角图像以及Layouts和文本提示生成图像

时间模型
在时间维度其实是生成单视角的模型。
输入: 所有视频帧的单视角3D布局和 视频序列的第一帧图像以及 相机对应的光流。
输出: 单个视点在时间上一致的视频
使用第一帧作为视频生成的控制条件。
为了避免需要为每个相机训练一个单独的视频生成模型,每个相机视图的统计光流趋势,固定值作为先验,编码为标记,以与时间嵌入相同的方式输入到模型中。
后处理
为了处理长序列视频,在跨视图和时间模型之后训练微调模型以增强后续帧的一致性。
这部分总结下来就是为了生成长视频,在每次时间模型生成视频后根据groundtruth进行微调。
整体过程:
1)根据空间模型生成多视角单帧图像
2)根据生成的单帧图像作为条件输入时间模型生成短时间视频帧
3)根据生成的大量时间后续帧和数据集中的原始图像(真值)微调
4)根据微调后的某一时刻作为新的关键帧,再次输入时间模型。此时实现类似滑动窗口的长视频生成。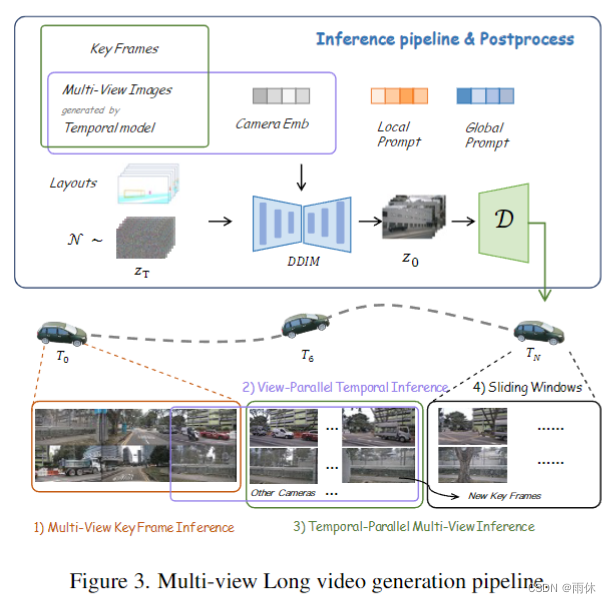
3.3 跨视频和跨帧一致性
提出有效的注意力机制,强调跨视图和跨帧交互,并引入几何约束来监督生成结果。
图 4 的右侧部分显示了一致性模块生效的范围:(1)多视图中的相邻视图,(2)多帧中的当前帧和前/前一帧。
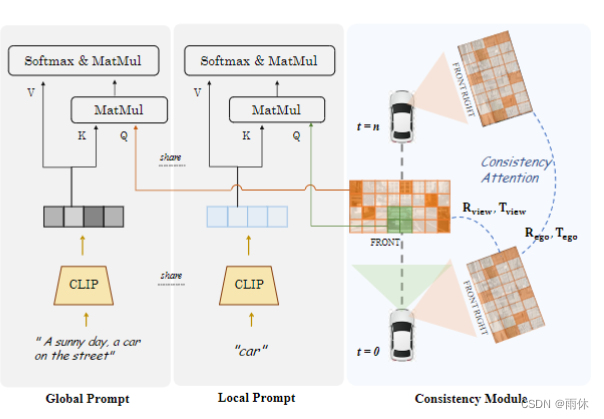
一致性注意力机制
相同帧只关注左右相邻视角
相同视角只关注关键帧以及前一帧
一致性关联损失
实验相关
我们使用预训练的网络 F 来监督生成结果的一致性,该网络可以执行图像匹配和回归相对姿势。在训练过程中,我们固定F的参数并使用实际的相对位姿作为ground truth。对于跨视图模型,我们监督相邻帧之间的姿势,对于时间模型,我们按时间顺序监督相邻帧。
3.4 局部提示
1)预先存储类别k和对英语类别名称的文本Tk,使用CLIP编码器对类别进行编码。
2)将3D布局的最小周围矩形区域作为每个类别的掩码Mk。
3)然后使用潜在表示计算 z 和类别文本编码 Ek 以与全局提示相同的方式计算交叉注意力,使用 Mk 作为注意力的掩码。
如图所示,在图像token和全局的文字描述提示的交叉注意力机制基础上,作者对某类别进行local prompt设计并使用该类别mask区域的图像token对local prompt进行查询。该过程最大程度地利用了原模型参数中在open domain的文本引导图像生成的概念。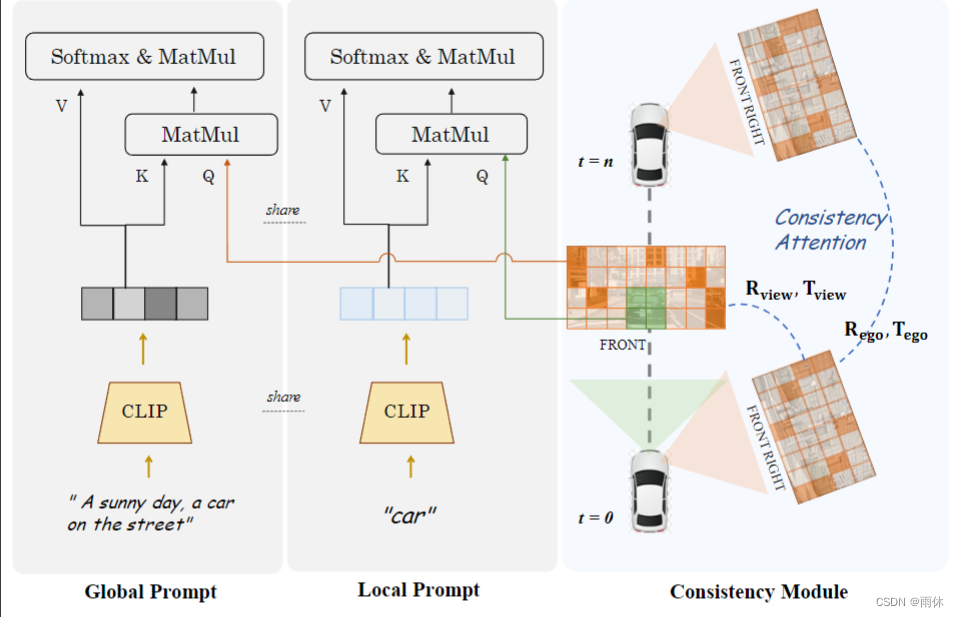
实验
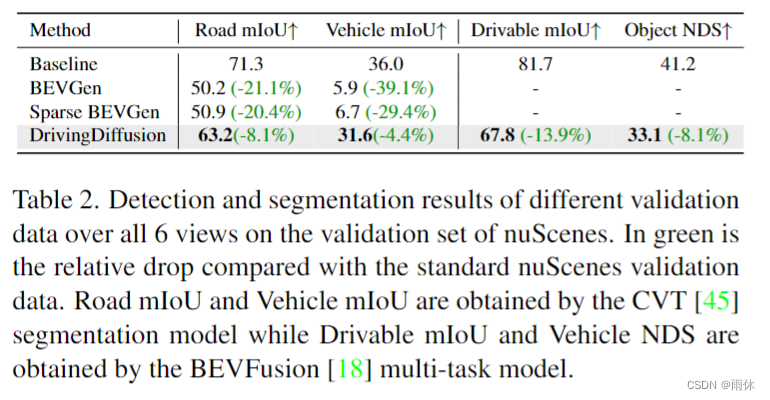
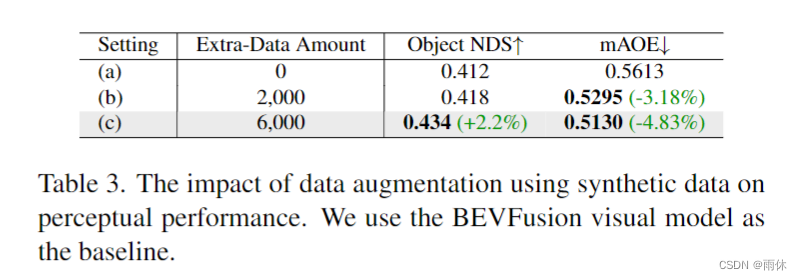
定量: 图像比较其他多视图单帧方法,视频比较单视图视频方法,指标:FID、FVD。
定性: 可视化


欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)