笔记-大语言模型自我一致性
自我一致性需要效果和效率的平衡。自我一致性(Self-Consistency, SC)是大语言模型在复杂推理任务中,通过生成多条推理路径并聚合结果,最终输出稳定且逻辑闭环答案的能力。与传统的单路径推理方法不同,自我一致性侧重于模拟人类在解决复杂问题时,会从多个角度出发,验证不同解决方案的思路。其理论核心机制包含:自我一致性并非孤立存在,它与多种其他概念相互关联、相互影响。理解这些关系有助于更全面地
·
自我一致性需要效果和效率的平衡。
一、自我一致性理论框架
1.1 自我一致性的定义与核心机制
自我一致性(Self-Consistency, SC)是大语言模型在复杂推理任务中,通过生成多条推理路径并聚合结果,最终输出稳定且逻辑闭环答案的能力。与传统的单路径推理方法不同,自我一致性侧重于模拟人类在解决复杂问题时,会从多个角度出发,验证不同解决方案的思路。其理论核心机制包含:
- 推理路径多样性:模型需要能够生成多种不同的、潜在可行的推理路径。这些路径可以是因果链、符号推导、数学计算,也可以是常识推理等。多样性的目标在于覆盖问题空间,避免模型陷入单一认知偏差。
- 答案聚合机制:对于生成的多个推理路径,需要一种机制来整合这些路径的结果。聚合方法包括投票(选择最频繁出现的答案)、加权平均(根据路径的置信度赋予权重)或概率边缘化(将所有路径的概率分布进行合并)。最终目标是筛选出最有可能正确的解。
- 规模效应:模型参数量级与自我一致性表现通常呈现正相关关系。参数更多的模型往往具有更强的记忆能力和泛化能力,从而在生成多样化推理路径和进行准确答案聚合时表现更佳。
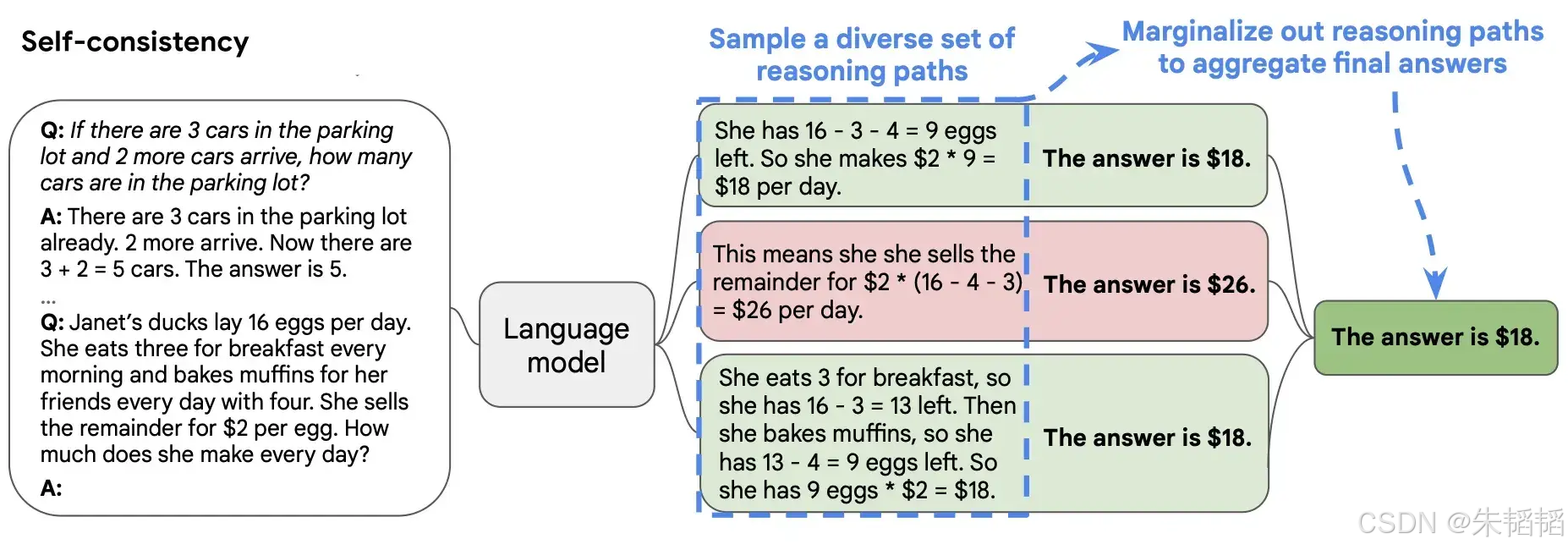
1.2 相关概念
自我一致性并非孤立存在,它与多种其他概念相互关联、相互影响。理解这些关系有助于更全面地把握自我一致性的本质及其应用场景。
| 概念 | 区别与联系 | 典型场景案例 |
|---|---|---|
| 链式推理(Chain-of-Thought, CoT) | CoT提供的是单条逐步推理的路径,而SC则将CoT扩展到多条路径,通过多条CoT路径来验证答案的正确性。SC可以看作是CoT的一种增强形式。 | 数学问题求解,模型通过多条不同的计算路径来验证最终答案的正确性。 |
| 幻觉抑制 | LLM的幻觉是指模型生成不真实或与事实相悖的内容。SC通过多条推理路径的交叉验证,可以减少模型产生幻觉的可能性,提高生成内容的可靠性。 | 医疗诊断推理,模型在给出诊断结果之前,需要通过多条医学知识推理路径来验证诊断的合理性,避免给出错误的诊断结果。 |
| 指令敏感性 | LLM的性能常常对指令(prompt)的微小变化非常敏感。SC可以通过对多个prompt的输出进行整合,从而缓解由prompt变化带来的输出波动,提高模型的鲁棒性。 | 商业报告生成,即使prompt的措辞略有不同,模型也应生成内容一致的报告。 |
1.3 自我一致性的评估指标
评估自我一致性需要设计合适的指标来量化模型在多个推理路径上的表现。
- 准确率(Accuracy):在有标准答案的任务中,可以通过计算模型输出答案与标准答案的一致程度来评估自我一致性。当模型生成多个答案时,可以选择出现频率最高的答案作为最终答案,然后计算准确率。
- 一致性比例(Consistency Ratio):对于没有标准答案的任务,可以计算模型在多个推理路径上输出相同答案的比例。一致性比例越高,说明模型的自我一致性越好。
- 信息熵(Information Entropy):可以将模型在多个推理路径上的输出结果视为一个概率分布,然后计算该分布的信息熵。信息熵越低,说明模型的输出越集中,自我一致性越好。
- 人类评估(Human Evaluation):通过人工评估模型在多个推理路径上的输出结果,从逻辑性、合理性、流畅性等方面进行综合评价。
二、实际应用中的提升策略
2.1 推理路径优化技术
(1)多路径采样与投票机制
- 代表性方法:Deng et al.(2022b)提出候选序列共识投票法,通过多轮采样生成多个候选答案,然后选择出现频率最高的答案作为最终答案。这种方法简单有效,可以显著提高模型的自我一致性。
- 效果验证:在Spider文本转SQL任务中,基于GPT-4的DIN-SQL模型通过此方法将准确率提升至89.5%,超越传统微调模型15%。这表明多路径采样与投票机制可以有效提高模型在复杂任务中的表现。
(2)符号推理与程序执行结合
- 创新案例:Liu et al.(2023e)开发Python交互框架,允许模型调用pandas执行数据操作并验证中间结果,在金融数据分析任务中错误率降低37%。这种方法将符号推理与程序执行相结合,可以有效提高模型在处理结构化数据时的准确性和可靠性。
- 实现原理:该方法通过允许LLM与外部环境进行交互,从而验证和修正自身的推理过程。例如,在处理表格数据时,LLM可以生成Python代码来执行数据查询、计算和分析,并将结果反馈给LLM自身,从而提高推理的准确性。
2.2 提示工程设计
提示工程(Prompt Engineering)是一种通过设计有效的prompt来引导LLM生成期望结果的技术。在提升自我一致性方面,prompt的设计至关重要。
| 策略类型 | 典型方法 | 应用场景 | 效果提升 |
|---|---|---|---|
| 自增强提示 | 两阶段知识生成(Sui et al., 2023b),首先让LLM生成与问题相关的知识,然后将生成的知识作为prompt的一部分,再次输入LLM以生成最终答案。 | 法律条款解析 | F1值提高22% |
| 动态路径选择 | 基于问题复杂度自适应CoT/SC(Chen, 2023),对于简单问题,使用CoT即可;对于复杂问题,则使用SC。 | 临床决策支持系统 | 诊断准确率提升18% |
| 语义采样 | 检索相似问题最优提示模板(Zhao et al., 2023d),通过检索与当前问题语义最相似的问题,并使用该问题对应的最优prompt模板来生成答案。 | 教育自动评分 | 评分一致性κ值达0.81 |
| 多提示融合 | 使用多个不同的prompt来生成答案,然后将多个答案进行融合。Weber et al.(2023)的研究表明,使用多个prompt可以提高LLM的鲁棒性和泛化能力。 | 文本摘要、机器翻译等任务。 | 提高生成结果的质量和一致性。 |
2.3 数据驱动增强
数据驱动增强是指通过使用高质量的训练数据来提高LLM的自我一致性。
- 表格数据建模:通过树形结构序列化将关系型数据转化为文本描述,使PaLM-2在Spider基准上EM值提升至72.3%。
- 反馈循环优化:在教育场景中,GPT-3.5生成的结构化反馈使学生修订质量(d=0.19)与积极情绪(d=0.34)显著提升。这种反馈循环可以帮助模型更好地理解任务的要求,从而提高生成结果的一致性。
三、当前挑战与未来方向
3.1 现存问题
- 计算成本:多路径采样使推理耗时增加3-5倍(Akhtar et al., 2023)。
- 领域适应性:医疗领域SC策略在金融场景迁移时性能下降41%(Horbach et al., 2023)。
- 评估标准缺失:仅5/10任务存在可靠的一致性度量指标(Weber et al., 2023)。这表明当前对于自我一致性的评估方法还不够完善,需要进一步研究。
- 幻觉问题:LLM仍然存在生成幻觉的问题,这会影响其自我一致性。Akhtar et al.(2023)的研究表明,幻觉会导致LLM在推理任务中性能下降。
- 缺乏可解释性:LLM的决策过程通常是黑盒的,缺乏可解释性。这使得我们难以理解LLM为何会产生不一致的输出,也难以针对性地进行改进。
3.2 前沿探索方向
- 轻量化的SC框架:开发路径剪枝算法(如Top-k置信度筛选)降低计算开销。
- 跨模态的一致性:融合视觉-文本多模态验证(如医学影像报告生成)。
- 自监督改进:构建基于对抗样本的一致性强化学习机制。
四、总结
当前研究已证实,通过推理路径优化、提示工程创新与数据增强的协同作用,可显著提升LLM在实际应用中的自我一致性,进而提升LLM表现。然而,如何平衡计算效率与一致性增益、建立跨领域通用框架,仍需学术界与工业界持续突破。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)