使用python划分训练数据集
划分数据集在实现机器学习的过程中,训练集是用来训练模型的,给模型输入和对应的输出,让模型学习它们之间的关系。验证集是用来估计模型的训练水平,比如分类器的分类精确度,预测的误差等,我们可以根据验证集的表现来选择最好的模型。划分数据集功能描述:将一个大数据集按比例划分为训练集和验证集(如下图)代码:#split_data.py# 划分数据集flower_data,数据集划分到flower_datas中
·
划分数据集
在实现机器学习的过程中,训练集是用来训练模型的,给模型输入和对应的输出,让模型学习它们之间的关系。
验证集是用来估计模型的训练水平,比如分类器的分类精确度,预测的误差等,我们可以根据验证集的表现来选择最好的模型。
划分数据集功能描述:将一个大数据集按比例划分为训练集和验证集(如下图)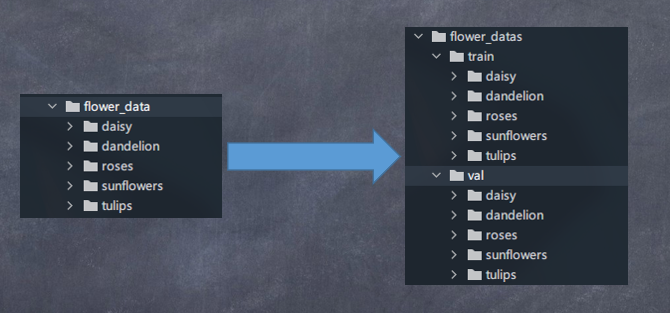
代码:
#split_data.py
# 划分数据集flower_data,数据集划分到flower_datas中,训练验证比例为8:2
import os
from shutil import copy
import random
def mkfile(file):
if not os.path.exists(file):
os.makedirs(file)
# 获取data文件夹下所有文件夹名(即需要分类的类名)
#划分数据集flower_data,数据集划分到flower_datas中
file_path = 'F:/gao/data/flower_data'
new_file_path = 'F:/gao/data/flower_datas'
# 划分比例,训练集 : 验证集 = 8 : 2
split_rate = 0.2
data_class = [cla for cla in os.listdir(file_path)]
train_path = new_file_path + '/train/'
val_path = new_file_path + '/val/'
# 创建 训练集train 文件夹,并由类名在其目录下创建子目录
mkfile(new_file_path)
for cla in data_class:
mkfile(train_path + cla)
# 创建 验证集val 文件夹,并由类名在其目录下创建子目录
mkfile(new_file_path)
for cla in data_class:
mkfile(val_path + cla)
# 遍历所有类别的全部图像并按比例分成训练集和验证集
for cla in data_class:
cla_path = file_path + '/' + cla + '/' # 某一类别的子目录
images = os.listdir(cla_path) # iamges 列表存储了该目录下所有图像的名称
num = len(images)
eval_index = random.sample(images, k=int(num * split_rate)) # 从images列表中随机抽取 k 个图像名称
for index, image in enumerate(images):
# eval_index 中保存验证集val的图像名称
if image in eval_index:
image_path = cla_path + image
new_path = val_path + cla
copy(image_path, new_path) # 将选中的图像复制到新路径
# 其余的图像保存在训练集train中
else:
image_path = cla_path + image
new_path = train_path + cla
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="") # processing bar
print()
print("processing done!")
注意:
只需要修改file_path(源文件夹)和new_file_path(新生成的文件夹)
其次是修改split_rate(split_rate=0.2就是训练集:验证集=8:2)
)和new_file_path(新生成的文件夹)
其次是修改split_rate(split_rate=0.2就是训练集:验证集=8:2)

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)