MapReduce工作流程
1. MapReduce的核心思想MapReduce是一种并行编程模型,是Hadoop生态系统的核心组件之一,“分而治之”是MapReduce的核心思想,它表示把一个大规模的数据集切分成很多小的单独的数据集,然后放在多个机器上同时处理。我们用一个通俗易懂的例子来体现“分而治之”的思想。2. MapReduce的核心函数MapReduce把整个并行运算过程高度抽象到两个函数上,一个是map另一个是r
1. MapReduce的核心思想
MapReduce是一种并行编程模型,是Hadoop生态系统的核心组件之一,“分而治之”是MapReduce的核心思想,它表示把一个大规模的数据集切分成很多小的单独的数据集,然后放在多个机器上同时处理。
我们用一个通俗易懂的例子来体现“分而治之”的思想。
2. MapReduce的核心函数
MapReduce把整个并行运算过程高度抽象到两个函数上,一个是map另一个是reduce。Map函数就是分而治之中的“分”,reduce函数就是分而治之中的“治”。
MapReduce把一个存储在分布式文件系统中的大规模数据集切分成许多独立的小的数据集,然后分配给多个map任务处理。然后map任务的输出结果会进一步处理成reduce任务的输入,最后由reduce任务进行汇总,然后上传到分布式文件系统中。
Map函数:map函数会将小的数据集转换为适合输入的<key,value>键值对的形式,然后处理成一系列具有相同key的<key,value>作为输出,我们可以把输出看做list(<key,value>)
Reduce函数:reduce函数会把map函数的输出作为输入,然后提取具有相同key的元素,并进行操作,最后的输出结果也是<key,value>键值对的形式,并合并成一个文件。
MapReduce的工作过程
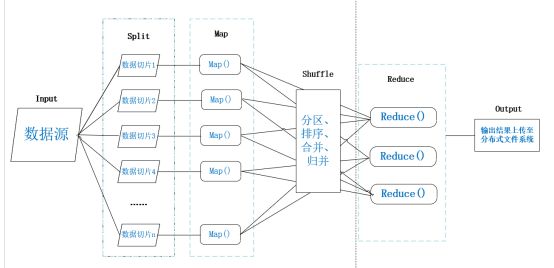
如图展示的就是MapReduce的工作过程,一共分为input、split、map、shuffle、reduce、output六个阶段。我们还是用前面介绍的做三明治的例子来演示一下MapReduce的工作流程:
√ input阶段相当于准备食材的步骤;
√ split阶段相当于分食材的步骤,数据切片1表示面包、数据切片2表示培根、数据切片3表示西红柿、数据切片4表示生菜;
√ map阶段相当于切面包、煎培根、切西红柿、洗生菜四个步骤同时进行;
√ shuffle阶段相当于把切好的食材分类,存放、汇总;
√ reduce阶段相当于整合组装成三明治;
√ output阶段相当于打包。
有了这个通俗易懂的例子加上前面map函数和reduce函数的介绍,我们再来理解MapReduce的工作过程就很轻松了。
(1) input阶段:将数据源输入到MapReduce框架中
(2) split阶段:将大规模的数据源切片成许多小的数据集,然后对数据进行预处理,处理成适合map任务输入的<key,value>形式。
(3) map阶段:对输入的<key,value>键值对进行处理,然后产生一系列的中间结果。通常一个split分片对应一个map任务,有几个split就有几个map任务。
(4) shuffle阶段:对map阶段产生的一系列<key,value>进行分区、排序、归并等操作,然后处理成适合reduce任务输入的键值对形式。
(5) reduce阶段:提取所有相同的key,并按用户的需求对value进行操作,最后也是以<key,value>的形式输出结果。
(6) output阶段:进行一系列验证后,将reduce的输出结果上传到分布式文件系统中。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)