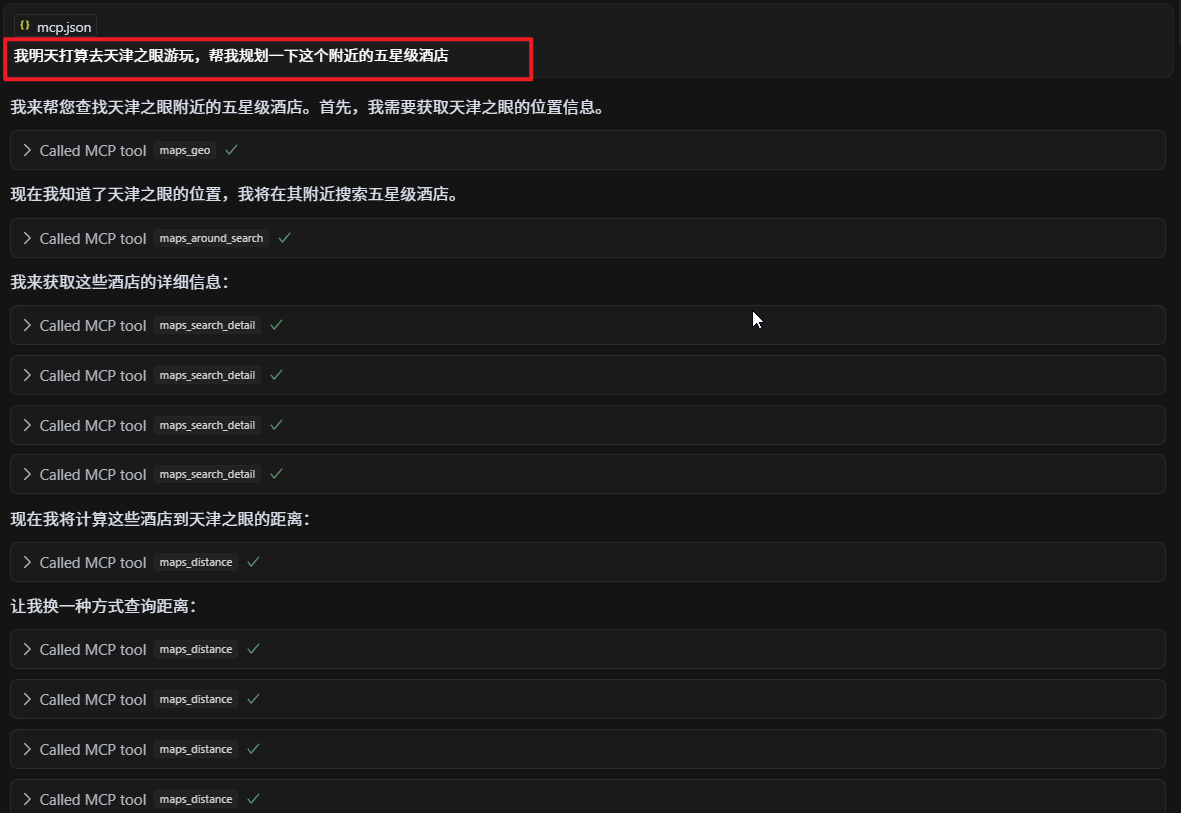
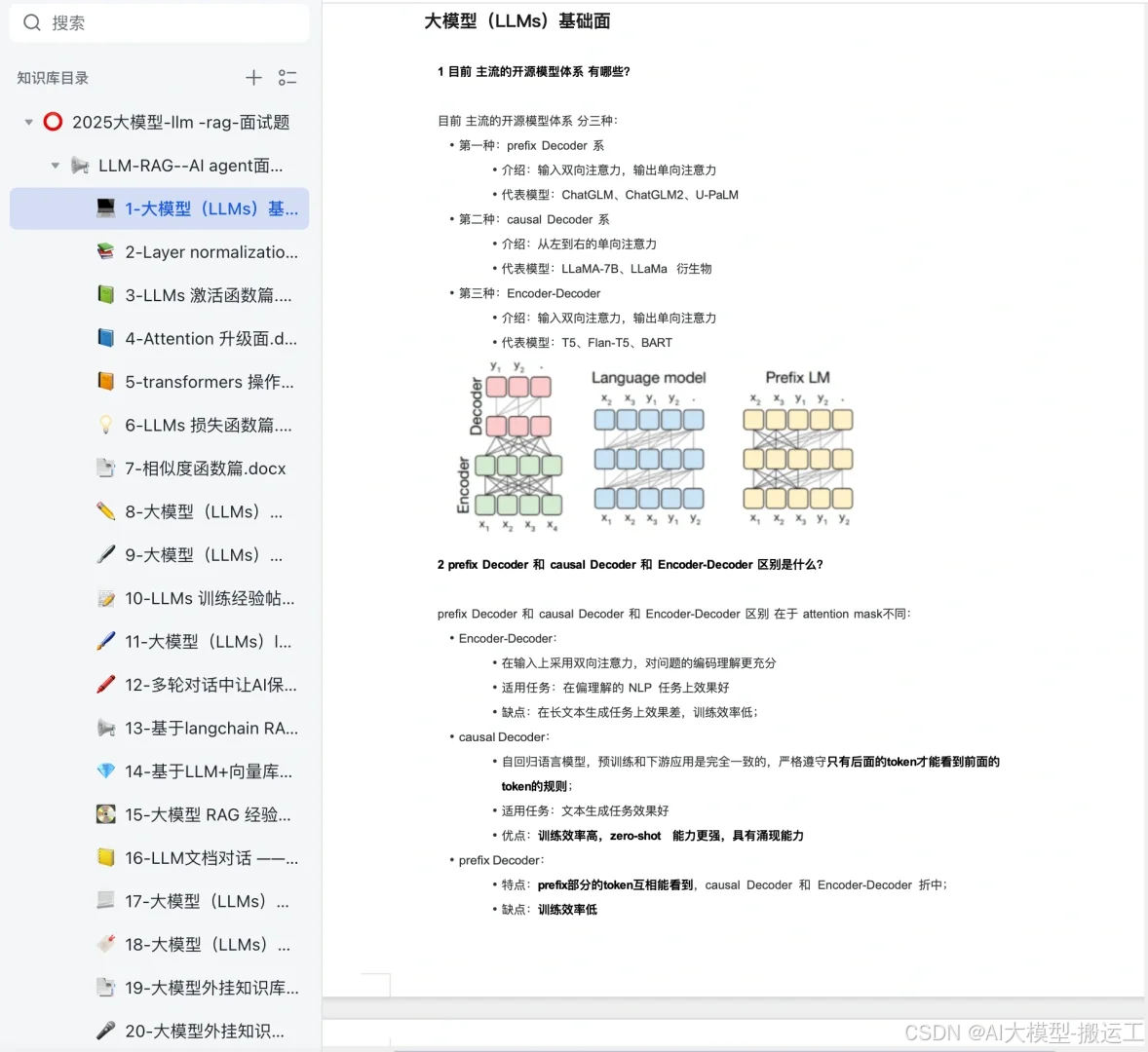
PyTorch 模型转换为 ONNX 模型的方法及应用
本文以 MNIST 图片数据集的数字识别为例,介绍 PyTorch 框架训练 CNN 模型的基本过程、 PyTorch 模型转换为 ONNX 模型的方法,以及ONNX 模型的运行。
本文以 MNIST 图片数据集的数字识别为例,介绍 PyTorch 框架训练 CNN 模型的基本过程、 PyTorch 模型转换为 ONNX 模型的方法,以及ONNX 模型的运行。
MNIST 数据集的导入
MNIST 数据集网址:
MNIST dataset
导入数据集的代码如下:
import torch
import torch.utils.data as data
import torchvision
import matplotlib.pyplot as plt
DOWNLOAD_MNIST = False # if need to download data, set True at first time
# read train data
train_data = torchvision.datasets.MNIST(
root='./data', train=True, download=DOWNLOAD_MNIST, transform=torchvision.transforms.ToTensor())
print()
print("size of train_data.train_data: {}".format(train_data.train_data.size())) # train_data.train_data is a Tensor
print("size of train_data.train_labels: {}".format(train_data.train_labels.size()), '\n')
# plot one example
plt.imshow(train_data.train_data[50].numpy(), cmap='Greys')
plt.title('{}'.format(train_data.train_labels[50]))
plt.show()
# data loader
# combines a dataset and a sampler, and provides an iterable over the given dataset
train_loader = data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# read test data
test_data = torchvision.datasets.MNIST(root='./data', train=False)
num_test, num_test_over = 2000, 1000
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(
torch.FloatTensor)[: num_test] / 255. # unsqueeze because of 1 channel; value in range (0, 1)
test_y = test_data.test_labels[: num_test]
test_over_x = torch.unsqueeze(
test_data.test_data, dim=1).type(torch.FloatTensor)[-num_test_over:] / 255. # test data after training
test_over_y = test_data.test_labels[-num_test_over:]
注意事项:
一,torchvision.datasets.MNIST 实例化时的 download 参数,在需要下载数据集时置为 True,若数据集已下载,则置为 False 即可;
二,注意数据集的文件路径:
三,torchvision.datasets.MNIST 既可以读取训练数据,也可以读取测试数据,当读取训练数据时,其所创建对象的 train_data 即为 Tensor 数据,对象通过 torch.utils.data.DataLoader 进行批量采样操作;当读取测试数据时,实例化时的 train 参数置为 False,所创建对象的 test_data 为 Tensor 数据。
CNN 模型的训练与测试
本文使用一个比较简单的 CNN 模型训练识别 MNIST 数据集中的数字。
PyTorch 模型代码如下:
import torch.nn as nn
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=(3, 3), stride=(1, 1), padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) # for 28*28 to 14*14
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=(3, 3), stride=(1, 1), padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) # for 14*14 to 7*7
)
self.output = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = out.view(out.size(0), -1) # flatten the 32*7*7 dimension to 1568
out = self.output(out)
return out
其中,MNIST 数据均为 28 x 28 大小的图片,经过两个的卷积模块(每个模块中先后经过一个卷积层、ReLU 非线性层和一个 max pooling 层),输出一个长度为 10 的向量,即 10 个数字的权重。
模型训练部分的代码如下:
import torch.nn as nn
from model import CNN
cnn = CNN()
print("CNN model structure:\n")
print(cnn, '\n')
optimizer = torch.optim.Adam(params=cnn.parameters(), lr=LR) # optimizer: Adam
loss_func = nn.CrossEntropyLoss() # loss function: cross entropy
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader): # x, y: Tensor of input and output
output = cnn(x)
loss = loss_func(output, y)
# optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
# test at each 50 steps
if not step % 50:
test_output = cnn(test_x)
predict_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((predict_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.3f' % accuracy)
# output model file
torch.save(cnn, 'cnn.pt')
print()
print('finish training', '\n')
训练结束后,可通过 torch.save 将模型存储在本地的 .pt 文件,即为 PyTorch 模型文件,后面会介绍如何将该模型文件转换为 ONNX 模型。
模型测试部分的代码如下:
# load model
print('load cnn model', '\n')
cnn_ = torch.load('cnn.pt')
# test new data
test_output = cnn_(test_over_x)
predict_y = torch.max(test_output, 1)[1].data.numpy()
print("prediction number: {}".format(predict_y))
print("real number: {}".format(test_over_y.numpy()), '\n')
accuracy = float((predict_y == test_over_y.data.numpy()).astype(int).sum()) / float(test_over_y.size(0))
print("accuracy: {}".format(accuracy), '\n')
PyTorch 模型转换为 ONNX 模型及应用
ONNX 全称为 Open Neural Network eXchange,是一种机器学习模型的开放标准形式,支持多种框架的模型转换,有很强的通用性。
此外,ONNX 模型的运行效率(inference)明显优于 PyTorch 模型。
代码如下:
import os
import numpy as np
import torch
import torchvision
import onnx
import onnxruntime as ort
from model import CNN # need model structure
PATH = os.path.dirname(__file__)
NUM_TEST = 1000
""" from pt to onnx """
# get pt model
path_pt = os.path.join(PATH, "cnn.pt")
model_pt = torch.load(f=path_pt)
# dummy input
dummy_input = torch.randn(size=(1, 1, 28, 28))
# save onnx model
path_onnx = os.path.join(PATH, "cnn.onnx")
input_names = ['actual_input'] + ['learned_%d' % i for i in range(6)]
torch.onnx.export(model=model_pt, args=dummy_input, f=path_onnx,
verbose=True, input_names=input_names) # arg verbose: True to print log
""" load onnx model """
# load onnx model
model_onnx = onnx.load(path_onnx)
# check if model well formed
onnx.checker.check_model(model_onnx)
# print a human readable representation of the graph
print(onnx.helper.printable_graph(model_onnx.graph))
# data input
test_data = torchvision.datasets.MNIST(root='./data', train=False)
test_data_x = torch.unsqueeze(input=test_data.test_data, dim=1).type(torch.FloatTensor)[: NUM_TEST] / 255.
test_data_y = test_data.test_labels[: NUM_TEST]
""" run onnx model """
# ort session initialize
ort_session = ort.InferenceSession(path_onnx)
# dummy input
outputs = ort_session.run(output_names=None,
input_feed={'actual_input': np.random.randn(1, 1, 28, 28).astype(np.float32)})
print("result of dummy input: {}".format(outputs[0]), '\n')
# test data, loop
num_correct = 0
for i in range(NUM_TEST):
test_data_x_, test_data_y_ = test_data_x[i: i + 1], test_data_y[i]
outputs = ort_session.run(output_names=None, input_feed={'actual_input': test_data_x_.numpy()})
predict_y = np.argmax(outputs[0])
if predict_y == test_data_y_:
num_correct += 1
else:
print("predict result {}, correct answer {}".format(predict_y, test_data_y_), '\n')
accuracy = round(num_correct / NUM_TEST, 3)
print("model accuracy: {}".format(accuracy), '\n')
注意事项:
一,ONNX 的模型转换,需要原模型的模型结构;
二,前面代码所示的模型运行过程,是把每个测试数据通过循环的方式反复调用模型来实现的,其实可以通过批量输入的方式实现。
首先将构建 ONNX 模型所用的 dummy input 的 size 第一维设置为批量大小:
dummy_input = torch.randn(size=(NUM_TEST, 1, 28, 28)) # batch mode
然后对应设置 ONNX 模型输入数据的长度即可:
# test data, batch mode
test_data_x_, test_data_y_ = test_data_x[: NUM_TEST], test_data_y[: NUM_TEST]
outputs = ort_session.run(output_names=None, input_feed={'actual_input': test_data_x_.numpy()})
output = outputs[0]
num_correct = 0
for i in range(len(output)):
predict_y = np.argmax(output[i])
if predict_y == test_data_y_[i]:
num_correct += 1
else:
print("predict result {}, correct answer {}".format(predict_y, test_data_y_[i]), '\n')
accuracy = round(num_correct / NUM_TEST, 3)
print("model accuracy: {}".format(accuracy), '\n')
模型输入为多个参数的情况
在实际应用的机器学习模型中,输入参数可能不止一个,为了验证多输入的情况,本文将原 CNN 模型的模型结构复制一份,形成两个并行的网络,最后对两个网络的输出取平均值。
模型结构如下:
import torch.nn as nn
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv11 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=(3, 3), stride=(1, 1), padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) # for 28*28 to 14*14
)
self.conv12 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=(3, 3), stride=(1, 1), padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) # for 14*14 to 7*7
)
self.output1 = nn.Linear(32 * 7 * 7, 10)
self.conv21 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=(3, 3), stride=(1, 1), padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) # for 28*28 to 14*14
)
self.conv22 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=(3, 3), stride=(1, 1), padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) # for 14*14 to 7*7
)
self.output2 = nn.Linear(32 * 7 * 7, 10)
def forward(self, x1, x2):
out1 = self.conv11(x1)
out1 = self.conv12(out1)
out1 = out1.view(out1.size(0), -1) # flatten the 32*7*7 dimension to 1568
out1 = self.output1(out1)
out2 = self.conv21(x2)
out2 = self.conv22(out2)
out2 = out2.view(out2.size(0), -1) # flatten the 32*7*7 dimension to 1568
out2 = self.output1(out2)
out = (out1 + out2) / 2
return out
模型训练与测试的代码如下:
import torch
import torch.nn as nn
import torch.utils.data as data
import torchvision
import matplotlib.pyplot as plt
from model_2 import CNN
# global variables
EPOCH = 5
BATCH_SIZE = 50
LR = 0.001 # learning rate
DOWNLOAD_MNIST = False # if need to download data, set True at first time
""" data process """
# read train data
train_data = torchvision.datasets.MNIST(
root='./data', train=True, download=DOWNLOAD_MNIST, transform=torchvision.transforms.ToTensor())
print()
print("size of train_data.train_data: {}".format(train_data.train_data.size())) # train_data.train_data is a Tensor
print("size of train_data.train_labels: {}".format(train_data.train_labels.size()), '\n')
plt.imshow(train_data.train_data[50].numpy(), cmap='Greys') # plot one example
plt.title('{}'.format(train_data.train_labels[50]))
# plt.show()
# data loader
# combines a dataset and a sampler, and provides an iterable over the given dataset
train_loader = data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# read test data
test_data = torchvision.datasets.MNIST(root='./data', train=False)
num_test, num_test_over = 2000, 1000
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(
torch.FloatTensor)[: num_test] / 255. # unsqueeze because of 1 channel; value in range (0, 1)
test_y = test_data.test_labels[: num_test]
test_over_x = torch.unsqueeze(
test_data.test_data, dim=1).type(torch.FloatTensor)[-num_test_over:] / 255. # test data after training
test_over_y = test_data.test_labels[-num_test_over:]
""" train """
cnn = CNN()
print("CNN model structure:\n")
print(cnn, '\n')
optimizer = torch.optim.Adam(params=cnn.parameters(), lr=LR) # optimizer: Adam
loss_func = nn.CrossEntropyLoss() # loss function: cross entropy
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader): # x, y: Tensor of input and output
output = cnn(x, x)
loss = loss_func(output, y)
# optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
# test at each 50 steps
if not step % 50:
test_output = cnn(test_x, test_x)
predict_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((predict_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.3f' % accuracy)
# output model file
torch.save(cnn, 'cnn2.pt')
print()
print('finish training', '\n')
""" test """
# load model
print('load cnn model', '\n')
cnn_ = torch.load('cnn2.pt')
# test new data
test_output = cnn_(test_over_x, test_over_x)
predict_y = torch.max(test_output, 1)[1].data.numpy()
print("prediction number: {}".format(predict_y))
print("real number: {}".format(test_over_y.numpy()), '\n')
accuracy = float((predict_y == test_over_y.data.numpy()).astype(int).sum()) / float(test_over_y.size(0))
print("accuracy: {}".format(accuracy), '\n')
ONNX 模型转换与运行:
(此处为批量运行模式,注意多个输入的 input name 设置)
import os
import numpy as np
import torch
import torchvision
import onnx
import onnxruntime as ort
from model_2 import CNN # need model structure
PATH = os.path.dirname(__file__)
NUM_TEST = 1000
""" from pt to onnx """
# get pt model
path_pt = os.path.join(PATH, "cnn2.pt")
model_pt = torch.load(f=path_pt)
# dummy input
dummy_input = torch.randn(size=(NUM_TEST, 1, 28, 28)) # batch mode
# save onnx model
path_onnx = os.path.join(PATH, "cnn2.onnx")
input_names = ['actual_input_{}'.format(i) for i in range(2)] + ['learned_%d' % i for i in range(8)] # 2 inputs
torch.onnx.export(model=model_pt, args=(dummy_input, dummy_input), f=path_onnx,
verbose=True, input_names=input_names) # arg verbose: True to print log
""" check onnx model """
# load onnx model
model_onnx = onnx.load(path_onnx)
# check if model well formed
onnx.checker.check_model(model_onnx)
# print a human readable representation of the graph
print(onnx.helper.printable_graph(model_onnx.graph))
# data input
test_data = torchvision.datasets.MNIST(root='./data', train=False)
test_data_x = torch.unsqueeze(input=test_data.test_data, dim=1).type(torch.FloatTensor)[: NUM_TEST] / 255.
test_data_y = test_data.test_labels[: NUM_TEST]
""" run onnx model """
# ort session initialize
ort_session = ort.InferenceSession(path_onnx)
# test data, batch mode
test_data_x_, test_data_y_ = test_data_x[: NUM_TEST], test_data_y[: NUM_TEST]
outputs = ort_session.run(output_names=None, input_feed={'actual_input_0': test_data_x_.numpy(),
'actual_input_1': test_data_x_.numpy()})
output = outputs[0]
num_correct = 0
for i in range(len(output)):
predict_y = np.argmax(output[i])
if predict_y == test_data_y_[i]:
num_correct += 1
else:
print("predict result {}, correct answer {}".format(predict_y, test_data_y_[i]), '\n')
accuracy = round(num_correct / NUM_TEST, 3)
print("model accuracy: {}".format(accuracy), '\n')
PyTorch 模型与 ONNX 模型的对比
如前所述,经验表明,ONNX 模型的运行效率明显优于原 PyTorch 模型,这似乎是源于 ONNX 模型生成过程中的优化,这也导致了模型的生成过程比较耗时,但整体效率依旧可观。
此外,根据对 ONNX 模型和 PyTorch 模型运行结果的统计分析(误差的均值和标准差),可以看出 ONNX 模型的运行结果误差很小、基本可靠。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)