【Kubernetes】k8s的deployment【控制器】详细说明【pod副本数、HPA、升级镜像】
文章目录官方介绍Deployment可以帮我们做什么Deployment原理说明RS【副本数管理】更新策略【滚动更新】控制器模型环境准备Deployment使用常用代码查看deployment查看deploy详细内容创建deploy【yaml文件方式】yaml文件生成并解释编辑yaml文件并生成pod删除pod测试修改副本数【scale】方式1【建议】方式2方式3HPA【自动伸缩】说明查看hpa创
官方介绍
-
网址:Deployments
-
Deployment为Pod和Replica Set提供声明式更新。
-
你只需要在 Deployment 中描述您想要的目标状态是什么,Deployment controller 就会帮您将 Pod 和ReplicaSet 的实际状态改变到您的目标状态。您可以定义一个全新的 Deployment 来创建 ReplicaSet 或者删除已有的 Deployment 并创建一个新的来替换。
-
注意:您不该手动管理由 Deployment 创建的 Replica Set,否则您就篡越了 Deployment controller 的职责!下文罗列了 Deployment 对象中已经覆盖了所有的用例。如果未有覆盖您所有需要的用例,请直接在 Kubernetes 的代码库中提 issue。
Deployment可以帮我们做什么
- 定义一组Pod期望数量,Controller会维持Pod数量与期望数量一致
- 配置Pod的发布方式,controller会按照给定的策略更新Pod,保证更新过程中不可用Pod维持在限定数量范围内
- 如果发布有问题支持回滚
Deployment原理
说明
-
首先说明一下:docker容器—是不稳定的
-
在 kubernetes 的世界里,Pod 是运行应用的载体。 Pod 是由多个容器组成、是 kubernetes 的最小调度单元、Pod 共享底层资源、由 kubernetes 来管理生命周期。
-
一般情况下,我们并不直接创建 Pod,而是通过 Deployment 来创建 Pod,由 Deployment 来负责创建、更新、维护其所管理的所有 Pods。
那Deployment的具体是怎样创建、更新、维护所有的Pod呢?
RS【副本数管理】
-
这里就需要说一下
ReplicationSet(RS)和ReplicationController(RC),RS是在RC基础上发展来的,在新版的Kubernetes中,已经将RC替换为RS 了,它们两者没有本质的区别,都是用于Pod副本数量的维护与更新的,使得副本数量始终维持在用户定义范围内,即如果存在容器异常退出,此时会自动创建新的Pod进行替代;而且异常多出来的容器也会自动回收。
【简单来说,就是:如果某个pod挂掉了,deployment会重新生成一个,保证环境里有3个pod【一般设置为3个,可以自定义数量】】 -
不同点在于:RS在RC的基础上支持集合化的selector;
-
一般情况下RS也是可以单独使用的,但是一般推荐和Deployment一起使用,这样会使得的Deployment提供的一些回滚更新操作同样用于RS上,因为RS不支持回滚更新操作;
-
所以Deployment一般使用的场景都是和RS一起使用,那它们的具体原理是怎样的呢?
先看一下Deployment、RS、Pod它们三者之间的关系: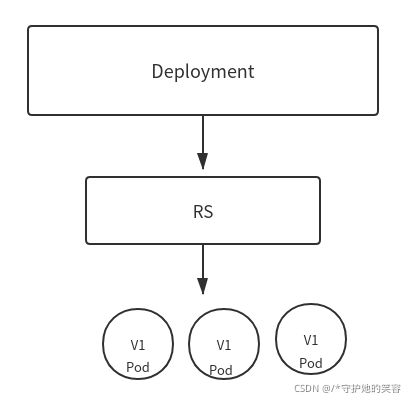
RS负责控制副本数量,由Deployment来创建具体的Pod,但是如果遇到版本更新的操作会怎样呢?
更新策略【滚动更新】
-
Deployment控制器支持两种更新策略:滚动更新(rolling update)和重新创建(recreate),默认为滚动更新。
-
滚动升级是默认的更新策略,它在删除一部分旧版本Pod资源的同时,补充创建一部分新版本的Pod对象进行应用升级,其优势是升级期间,容器中应用提供的服务不会中断,但要求应用程序能够应对新旧版本同时工作的情形,例如新旧版本兼容同一个数据库方案等。不过,更新操作期间,不同客户端得到的响应内容可能会来自不同版本的应用。
Deployment控制器的滚动更新操作并非在同一个ReplicaSet控制器对象下删除并创建Pod资源,而是将它们分置于两个不同的控制器之下:旧控制器的Pod对象数量不断减少的同时,新控制器的Pod对象数量不断增加,直到旧控制器不再拥有Pod对象,而新控制器的副本数量变得完全符合期望值为止,如图所示: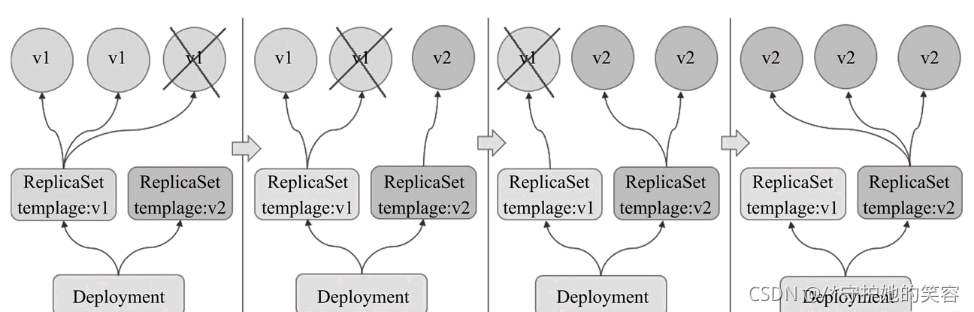
-
滚动更新时,应用升级期间还要确保可用的Pod对象数量不低于某阈值以确保可以持续处理客户端的服务请求,变动的方式和Pod对象的数量范围将通过
spec.strategy.rollingUpdate.maxSurge和spec.strategy.rollingUpdate.maxUnavailable两个属性协同进行定义,它们的功用如图所示: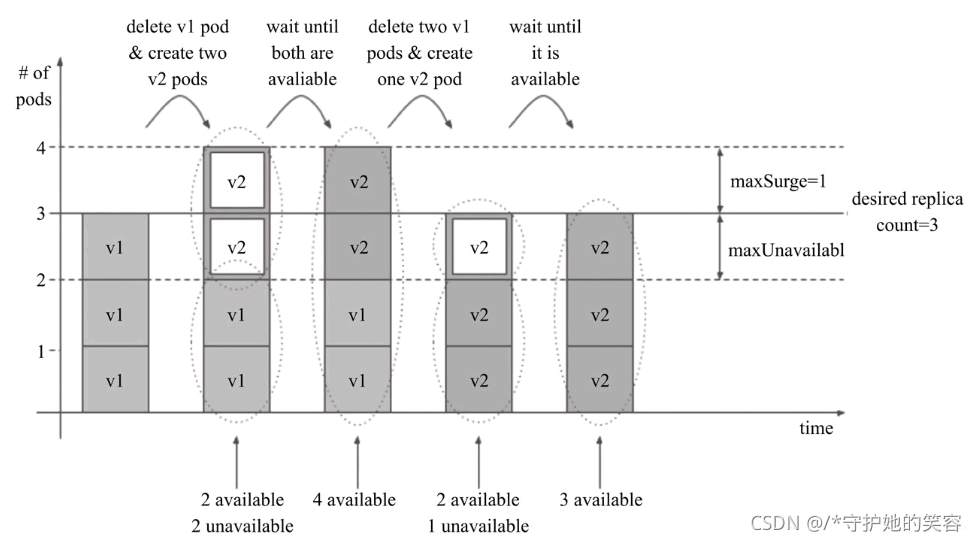
maxSurge:指定升级期间存在的总Pod对象数量最多可超出期望值的个数,其值可以是0或正整数,也可以是一个期望值的百分比;例如,如果期望值为3,当前的属性值为1,则表示Pod对象的总数不能超过4个maxUnavailable:升级期间正常可用的Pod副本数(包括新旧版本)最多不能低于期望数值的个数,其值可以是0或正整数,也可以是一个期望值的百分比;默认值为1,该值意味着如果期望值是3,则升级期间至少要有两个Pod对象处于正常提供服务的状态。- maxSurge和maxUnavailable属性的值不可同时为0,否则Pod对象的副本数量在符合用户期望的数量后无法做出合理变动以进行滚动更新操作。
-
Deployment控制器也支持用户保留其滚动更新历史中的旧ReplicaSet对象版本,这赋予了控制器进行应用回滚的能力:用户可按需回滚到指定的历史版本。控制器可保存的历史版本数量由“
spec.revisionHistoryLimit”属性进行定义。当然,也只有保存于revision历史中的ReplicaSet版本可用于回滚,因此,用户要习惯性地在更新操作时指定保留旧版本。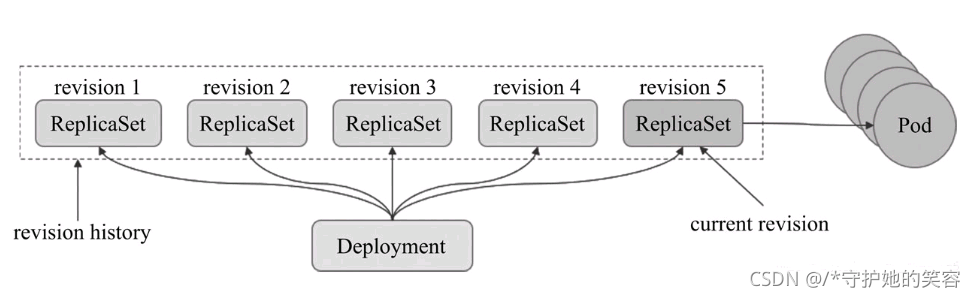
控制器模型
-
在Kubernetes架构中,有一个叫做
kube-controller-manager的组件。这个组件,是一系列控制器的集合。其中每一个控制器,都以独有的方式负责某种编排功能。而Deployment正是这些控制器中的一种。它们都遵循Kubernetes中一个通用的编排模式,即:控制循环 -
用一段语言伪代码,描述这个控制循环
for {
实际状态 := 获取集群中对象X的实际状态
期望状态 := 获取集群中对象X的期望状态
if 实际状态 == 期望状态 {
什么都不做
}else{
执行编排动作,将实际状态调整为期望状态
}
}
-
在具体实现中,实际状态往往来自于Kubernetes集群本身。比如Kubelet通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,或者控制器主动收集的它感兴趣的信息,这些都是常见的实际状态的来源;期望状态一般来自用户提交的YAML文件,这些信息都保存在Etcd中
-
对于Deployment,它的控制器简单实现如下:
- Deployment Controller从Etcd中获取到所有携带 “app:nginx”标签的Pod,然后统计它们的数量,这就是实际状态
- Deployment对象的replicas的值就是期望状态
- Deployment Controller将两个状态做比较,然后根据比较结果,确定是创建Pod,还是删除已有Pod
环境准备
- 首先需要有一套集群
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 43d v1.21.0
node1 Ready <none> 43d v1.21.0
node2 Ready <none> 43d v1.21.0
[root@master ~]#
- 然后我们创建一个文件用来放后面的测试文件,创建一个命名空间,后面测试都在这个命名空间做
[root@master ~]#
[root@master ~]# mkdir deploy
[root@master ~]# cd deploy
[root@master deploy]# kubectl create ns deploy
namespace/deploy created
[root@master deploy]# kubens deploy
Context "context" modified.
Active namespace is "deploy".
[root@master deploy]#
[root@master deploy]# kubectl get pods
No resources found in deploy namespace.
[root@master deploy]#
Deployment使用
常用代码
查看deployment
命令:kubectl get deploy -o wide
[root@master deploy]# kubectl get deploy -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
web1 1/1 1 1 18s nginx nginx app1=web1
[root@master deploy]#
对应关系呢如下图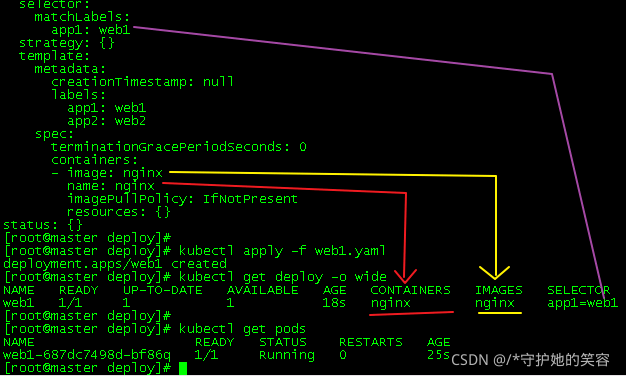
查看deploy详细内容
命令:kubectl describe deployments.apps deploy_name【deployments.apps是tab出来的内容,缩写为deploy】
[root@master http]# kubectl describe deployments.apps web1
Name: web1
Namespace: deploy
CreationTimestamp: Tue, 31 Aug 2021 16:11:25 +0800
Labels: app=web1
Annotations: deployment.kubernetes.io/revision: 1
Selector: app1=web1
Replicas: 2 desired | 2 updated | 2 total | 2 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app1=web1
app2=web2
Containers:
nginx:
Image: nginx
Port: <none>
Host Port: <none>
Requests:
cpu: 400m
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Progressing True NewReplicaSetAvailable
Available True MinimumReplicasAvailable
OldReplicaSets: <none>
NewReplicaSet: web1-ffffb5589 (2/2 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 10m (x2 over 20m) deployment-controller Scaled up replica set web1-ffffb5589 to 4
Normal ScalingReplicaSet 4m42s (x2 over 11m) deployment-controller Scaled down replica set web1-ffffb5589 to 3
Normal ScalingReplicaSet 4m12s deployment-controller Scaled down replica set web1-ffffb5589 to 2
[root@master http]#
创建deploy【yaml文件方式】
yaml文件生成并解释
代码:kubectl create deploy web1 --image=nginx --dry-run=client -o yaml > web1.yaml 【代码比较基础,就不解释了,代码意思我在后面用图片表示了】
[root@master deploy]# kubectl create deploy web1 --image=nginx --dry-run=client -o yaml > web1.yaml
[root@master deploy]# cat web1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web1
name: web1
spec:
replicas: 1
selector:
matchLabels:
app: web1
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: web1
spec:
containers:
- image: nginx
name: nginx
resources: {}
status: {}
[root@master deploy]#
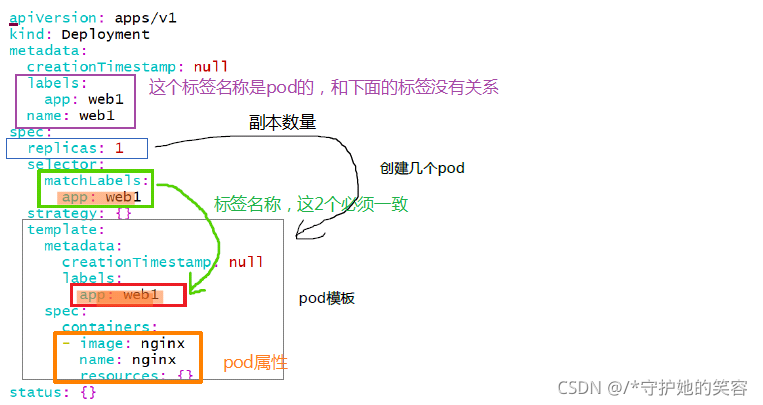
编辑yaml文件并生成pod
上面生成的呢,只是一个默认模版罢了,我们需要修改其中的某些地方,让这个文件更加合理哦。
[root@master deploy]# cat web1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web1
name: web1
spec:
replicas: 1
selector:
matchLabels:
app1: web1 #这个标签是可以自定义的,增加个1是为例和上面app有区别
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app1: web1 # 也可以定义多个标签,只要其中一个和上面的app1能对应上就行
app2: web2
spec:
terminationGracePeriodSeconds: 0 #0秒删除
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent #镜像获取策略
resources: {}
status: {}
[root@master deploy]#
[root@master deploy]# kubectl apply -f web1.yaml
deployment.apps/web1 created
[root@master deploy]# kubectl get deploy -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
web1 1/1 1 1 18s nginx nginx app1=web1
[root@master deploy]#
[root@master deploy]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web1-687dc7498d-bf86q 1/1 Running 0 25s
[root@master deploy]#
删除pod测试
因为前面说过,这个会自动生成pod,所以我们删除pod以后,deploy会自动给我们生成pod的
【注意看运行时间,可以看出是否自动生成的哈】
[root@master deploy]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web1-687dc7498d-bf86q 1/1 Running 0 4m54s
[root@master deploy]#
[root@master deploy]# kubectl delete pod web1-687dc7498d-bf86q
pod "web1-687dc7498d-bf86q" deleted
[root@master deploy]#
[root@master deploy]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web1-687dc7498d-cmpz6 1/1 Running 0 3s
[root@master deploy]#
修改副本数【scale】
方式1【建议】
- 命令:
kubectl scale deployment deploy_name --replicas=数量 - 如:我现在是3副本【初始一个,通过下面方式2改为了3个】,现在我修改为10个
注:如果数量一下子增多了,需要等一会状态才会变成Running
[root@master deploy]# kubectl scale deployment web1 --replicas=10
deployment.apps/web1 scaled
[root@master deploy]#
[root@master deploy]# kubectl scale deployment web1 --replicas=10
deployment.apps/web1 scaled
[root@master deploy]#
[root@master deploy]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web1-687dc7498d-4kcdj 0/1 ContainerCreating 0 4s
web1-687dc7498d-72rzd 1/1 Running 0 5m44s
web1-687dc7498d-86mrg 0/1 ContainerCreating 0 4s
web1-687dc7498d-bvbmn 0/1 ContainerCreating 0 4s
web1-687dc7498d-cmpz6 1/1 Running 0 9m12s
web1-687dc7498d-f6qrz 0/1 ContainerCreating 0 4s
web1-687dc7498d-jfv4v 0/1 ContainerCreating 0 4s
web1-687dc7498d-sfplz 0/1 ContainerCreating 0 4s
web1-687dc7498d-sx9d4 0/1 ContainerCreating 0 4s
web1-687dc7498d-wzgr2 1/1 Running 0 5m44s
[root@master deploy]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web1-687dc7498d-4kcdj 1/1 Running 0 95s
web1-687dc7498d-72rzd 1/1 Running 0 7m15s
web1-687dc7498d-86mrg 1/1 Running 0 95s
web1-687dc7498d-bvbmn 1/1 Running 0 95s
web1-687dc7498d-cmpz6 1/1 Running 0 10m
web1-687dc7498d-f6qrz 1/1 Running 0 95s
web1-687dc7498d-jfv4v 0/1 ImagePullBackOff 0 95s
web1-687dc7498d-sfplz 0/1 ImagePullBackOff 0 95s
web1-687dc7498d-sx9d4 0/1 ErrImagePull 0 95s
web1-687dc7498d-wzgr2 1/1 Running 0 7m15s
[root@master deploy]#
方式2
- 命令:
kubectl edit deploy deploy_name
回车以后会进入一个配置文件,找到spec下面的replicas,就是副本数量了
spec:
progressDeadlineSeconds: 600
replicas: 1
"/tmp/kubectl-edit-5qrme.yaml" 70L, 2397C written
- 如:我现在改为3
[root@master deploy]# kubectl edit deploy web1
....
spec:
progressDeadlineSeconds: 600
replicas: 3
"/tmp/kubectl-edit-5qrme.yaml" 70L, 2397C written
...
#注:只修改这一个地方,其他地方不要修改
- 上面修改了以后呢,pod数量就会自动更新了
注:在线修改pod是不行的,直接修改yaml文件也是不行。
[root@master deploy]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
web1 3/3 3 3 11m
[root@master deploy]#
[root@master deploy]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web1-687dc7498d-72rzd 1/1 Running 0 2m39s
web1-687dc7498d-cmpz6 1/1 Running 0 6m7s
web1-687dc7498d-wzgr2 1/1 Running 0 2m39s
[root@master deploy]#
方式3
- 额,这种就是通过yaml文件修改完成的,流程如下【不建议用这种】
- 1、编辑yaml文件中的replicas数量
- 2、重新生成deploy文件
[root@master deploy]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
web1 7/10 10 7 18m
[root@master deploy]#
[root@master deploy]# cat web1.yaml | grep rep
replicas: 1
[root@master deploy]#
[root@master deploy]# kubectl apply -f web1.yaml
deployment.apps/web1 configured
[root@master deploy]#
[root@master deploy]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
web1 1/1 1 1 19m
[root@master deploy]#
HPA【自动伸缩】
说明
- 我们上面修改副本数呢,其实数量都是手动执行的,比如某个pod,CPU使用率需求瞬间提高,手动增加副本数,肯定来不及,我们需求呢,就是能够自动根据使用率来伸缩副本数,这个时候就可以通过HPA来完成了
- HPA(horizontal pod autoscalers) ————水平自动伸缩
- 原理:通过检测pod CPU的负载,解决deployment里某pod负载太重,动态伸缩pod的数量来负载均衡。
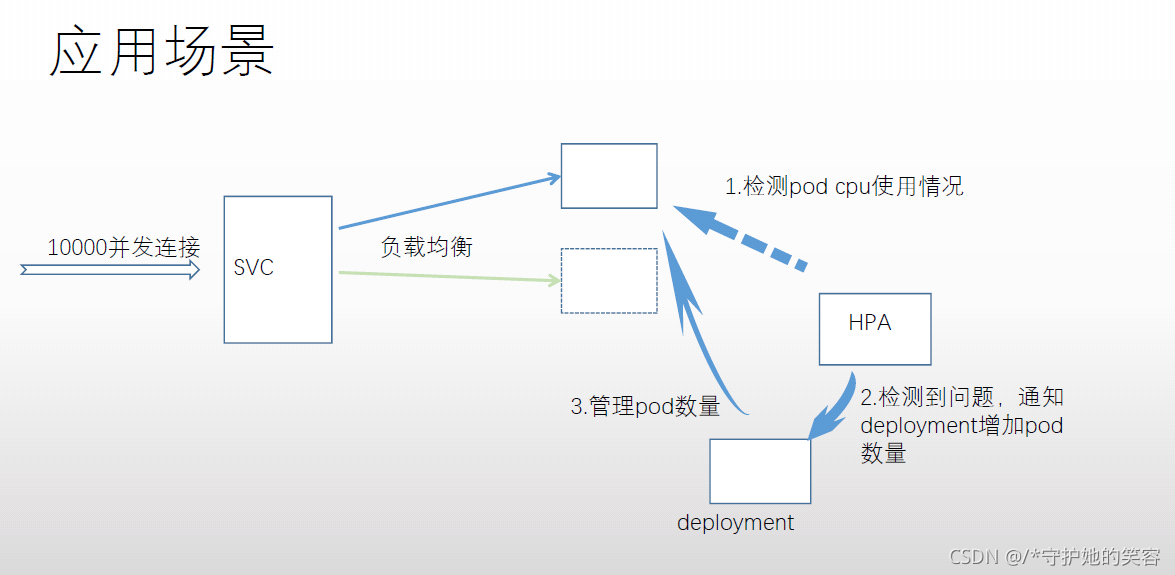
查看hpa
命令:kubectl get hpa
[root@master deploy]# kubectl get hpa
No resources found in deploy namespace.
[root@master deploy]#
创建hpa
- 命令:
kubectl autoscale deployment deploy_name --min=最小数量 --max=最大数量 - 如:我给web1创建一个hpa,最小数量为2,最大为5【现在副本是1,正常的话会自动给我把副本变成2】
[root@master deploy]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
web1 1/1 1 1 16h
[root@master deploy]#
[root@master deploy]# kubectl autoscale deployment web1 --min=2 --max=5
horizontalpodautoscaler.autoscaling/web1 autoscaled
[root@master deploy]#
[root@master deploy]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web1 Deployment/web1 <unknown>/80% 2 5 1 30s
[root@master deploy]#
# 等了一会,数量已经变成最小的2了。
[root@master deploy]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
web1 2/2 2 2 16h
[root@master deploy]# k
注:HPA的优先级是高于修改副本数scale的【说优先级有点绝对了,只是HPA会实时监控,所以比我们手动定义来得勤,但可以用优先级来这么理解】,也就是说,如果我们使用HPA定义了最大数5和最小数2,我们使用上面的修改副本数方式修改了副本数量,最终都会根据CPU使用率来由HPA判断生成副本数量。像我上面,因为没有使用率,所以我无论修改副本数为多少,最终pod数量都会为2。
删除hpa
命令:kubectl delete hpa hpa_name
解决当前cpu的使用量为unknown
查看:kubectl get hpa下的TARGETS,一般情况为unknown,如下【下图是下面”HPA测试“中步骤】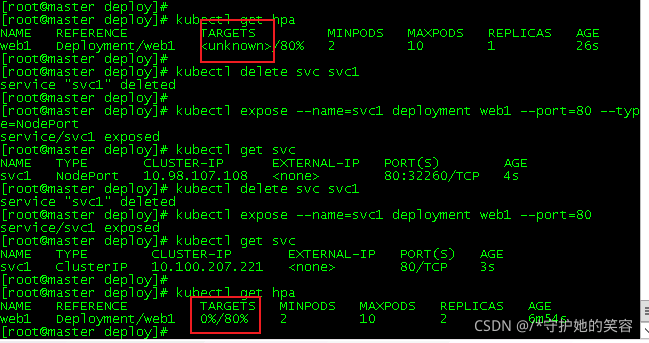
下面两种方式,任选其一,我使用的是方式1【建议这种,简单】
HPA测试
- 先删除之前创建的hpa和deploy,然后修改配置文件
[root@master deploy]# kubectl delete hpa web1
horizontalpodautoscaler.autoscaling "web1" deleted
[root@master deploy]# kubectl delete -f web1.yaml
deployment.apps "web1" deleted
[root@master deploy]# cat web1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web1
name: web1
spec:
replicas: 1
selector:
matchLabels:
app1: web1
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app1: web1
app2: web2
spec:
terminationGracePeriodSeconds: 0
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: 400m #1核CPU=1000m(微核心)
status: {}
[root@master deploy]#
- 创建deploy【限制最高使用cpu80】,并绑定一个svc
[root@master deploy]# kubectl apply -f web1.yaml
deployment.apps/web1 created
[root@master deploy]# kubectl top nodes
W0831 16:11:37.254838 114815 top_node.go:119] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 343m 8% 2243Mi 61%
node1 335m 8% 957Mi 26%
node2 140m 3% 786Mi 21%
[root@master deploy]#
[root@master deploy]# kubectl autoscale deployment web1 --min=2 --max=10 --cpu-percent=80
horizontalpodautoscaler.autoscaling/web1 autoscaled
[root@master deploy]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web1 Deployment/web1 <unknown>/80% 2 10 0 13s
[root@master deploy]#
[root@master deploy]# kubectl expose --name=svc1 deployment web1 --port=80
service/svc1 exposed
[root@master deploy]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc1 ClusterIP 10.100.207.221 <none> 80/TCP 3s
[root@master deploy]#
[root@master http]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web1 Deployment/web1 0%/80% 2 10 2 40m
- 模拟使用率
现在呢,我们安装一个命令,并且模拟大量请求【下面的IP是上面svc查看到的ip】
还有另外一种方式【我没有使用这个方法】:进入到某pod里,执行多个cat /dev/zero > /dev/null &
观察pod的数目变化,及hpa的cpu使用量
[root@master deploy]# yum install httpd-tools -y
[root@master deploy]# ab -t 600 -n 1000000 -c 1000 http://10.100.207.221/index.html
- 关注hpa的cPU使用率和副本数量变化
并且这个时候的pod数量也会跟着增加哈,只是创建时间略有不同。
命令:kubectl get hpa可以查看动态变化的哈,参数意思如下图哦。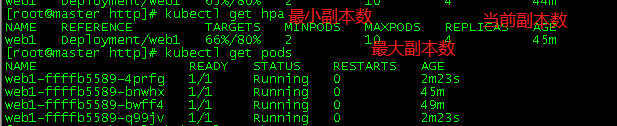
[root@master http]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web1 Deployment/web1 0%/80% 2 10 2 42m
[root@master http]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web1 Deployment/web1 22%/80% 2 10 2 42m
[root@master http]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web1 Deployment/web1 22%/80% 2 10 2 42m
[root@master http]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web1 Deployment/web1 65%/80% 2 10 4 44m
[root@master http]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web1 Deployment/web1 65%/80% 2 10 4 44m
[root@master http]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web1 Deployment/web1 66%/80% 2 10 4 45m
[root@master http]# kubectl top pod
W0831 17:08:08.985645 49694 top_pod.go:140] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag
NAME CPU(cores) MEMORY(bytes)
web1-ffffb5589-4prfg 298m 7Mi
web1-ffffb5589-bnwhx 310m 8Mi
web1-ffffb5589-bwff4 351m 8Mi
web1-ffffb5589-klhv4 257m 6Mi
[root@master http]#
-
总结
上面呢,就是一个hpa的测试了,动态调整pod数量来均衡使用率【上面top中可以看到每个pod都有cpu使用率的哦】,应该能理解吧。
如果我们结束这个测试,cpu降下来以后,pod数量是不会立即减少的,默认是5分钟才会变动【为了防止pod的抖动】 -
下面是5分钟以后的top使用率,可以看到pod数量已经变为2个了,至此,deploy的内容就结束了,最后将hpa和svc删除,免得后面内容测试出问题,不知道是为啥。。。.
[root@master http]# kubectl top pod
W0831 17:14:35.078617 56989 top_pod.go:140] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag
NAME CPU(cores) MEMORY(bytes)
web1-ffffb5589-bnwhx 0m 8Mi
web1-ffffb5589-bwff4 0m 8Mi
[root@master http]#
[root@master http]#
[root@master http]#
[root@master http]# kubectl delete svc svc1
service "svc1" deleted
[root@master http]# kubectl delete hpa web1
horizontalpodautoscaler.autoscaling "web1" deleted
[root@master http]#
deployment-健壮性测试
执行:kubectl get pod -o wide
查看pod运行在哪个pod上,比如运行在node2上的,那么我们将node2关机,现运行在node2上的pod就会漂到node1上运行了
这个比较直观,关机重启浪费我时间,我就不测试了,具体的看下图哦。

kubernetes-升级镜像【更换镜像】
说明
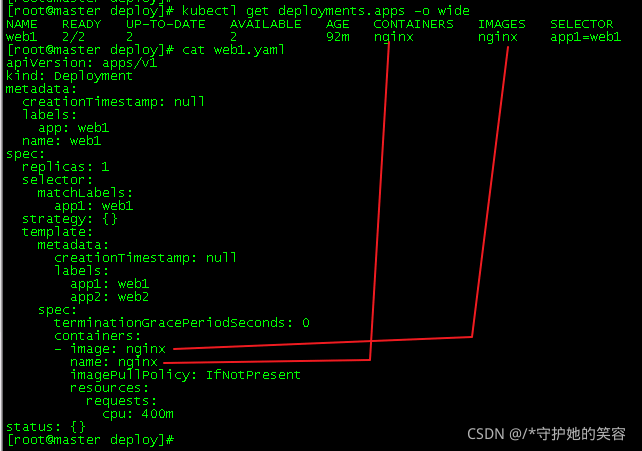
既然是升级镜像,我觉得应该有必要放一下deploy命令结果和yaml文件中的对应关系,如下:
- 我们修改deploy的镜像时候,本质上是删除掉现有的pod,然后用新镜像创建新pod
- 镜像更换不能乱更换,比如现在使用的是nginx的镜像,更换就必须也更换为nginx的镜像,只是版本不同罢了,这样能理解吧?
如果我现在是使用的nginx镜像,我更换为非nginx的镜像,那么就会报错【我集群没有外网,nginx也没有多余的版本,所以我下面都是更换到非nginx的镜像,所以更换后是报错的哈】
所以呢,这个使用场景其实就是,自己弄的镜像,后期该镜像升级了,需要更换为升级后的镜像,而已。 - 改的镜像,如果是没有外网的话,必须要注意,改的镜像必须是node节点上已有镜像才行哦【docker images查看】。
不记录到历史版本修改镜像
方式1【推荐】
命令:
kubectl set image deploy deploy_name 容器名【CONTAINERS】=镜像名【IMAGES】:latest#【:latest如果是默认的可以忽略】
[root@master deploy]# kubectl get deployments.apps -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
web1 2/2 2 2 108m nginx nginx app1=web1
[root@master deploy]#
[root@master deploy]# kubectl set image deploy web1 nginx=calico/cni
deployment.apps/web1 image updated
[root@master deploy]#
[root@master deploy]# kubectl get deployments.apps -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
web1 2/2 1 2 109m nginx calico/cni app1=web1
[root@master deploy]#
[root@master deploy]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web1-5ff8df68cc-5rkbb 0/1 CrashLoopBackOff 5 3m9s 10.244.166.188 node1 <none> <none>
web1-5ff8df68cc-jglc6 0/1 Error 5 3m11s 10.244.166.187 node1 <none> <none>
web1-ffffb5589-bwff4 1/1 Running 0 114m 10.244.166.180 node1 <none> <none>
[root@master deploy]#
方式2
- 命令:
kubectl edit deploy deploy_name
里面的spec中找到image,直接在后面定义即可
spec:
containers:
- image: calico/cni:v3.19.1
imagePullPolicy: IfNotPresent
- 因为我通过方式1已经改为calico的镜像了,所以当前镜像的pod是error状态,现在我们改回nginx的镜像。
[root@master deploy]# kubectl edit deploy web1
...
spec:
containers:
- image: calico/cni:v3.19.1
imagePullPolicy: IfNotPresent
改回来以后呢,状态就变成running了哦。
[root@master deploy]# kubectl get deployments.apps -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
web1 2/2 2 2 124m nginx nginx app1=web1
[root@master deploy]#
[root@master deploy]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web1-ffffb5589-6zlk7 1/1 Running 0 46s 10.244.166.189 node1 <none> <none>
web1-ffffb5589-bwff4 1/1 Running 0 124m 10.244.166.180 node1 <none> <none>
[root@master deploy]#
查看修改历史版本
命令:kubectl rollout history deployment
[root@master deploy]# kubectl rollout history deployment
deployment.apps/web1
REVISION CHANGE-CAUSE
2 <none>
3 <none>
4 <none>
[root@master deploy]#
这个呢,如果我们使用上面的不记录是不会看到的,只有加上记录参数以后的修改,才能在这看到哦,下面有说如何记录修改版本信息
记录历史版本修改镜像
记录的话呢,不管是方式1还是方式2,都只需要在命令后面加上一行参数即可:--record=true【可缩写为--record】
我2样都说是因为,我修改镜像只能修改其他的镜像,会报错,需要修改回去,所以也是方式1修改错误的,方式2修改回去。
注:版本记录并不会全部记录,只会记录几条而已。
方式1【推荐】
命令:
kubectl set image deploy deploy_name 容器名【CONTAINERS】=镜像名【IMAGES】:latest#【:latest如果是默认的可以忽略】
- 修改和查看如下
[root@master deploy]# kubectl rollout history deployment
deployment.apps/web1
REVISION CHANGE-CAUSE
2 <none>
3 <none>
4 <none>
[root@master deploy]# kubectl set image deploy web1 nginx=calico/cni:v3.19.1 --record=true
deployment.apps/web1 image updated
[root@master deploy]#
[root@master deploy]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
web1 2/2 1 2 141m
[root@master deploy]# kubectl get pdos -o wide
error: the server doesn't have a resource type "pdos"
[root@master deploy]#
[root@master deploy]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web1-5ff8df68cc-qlmh7 0/1 Error 2 17s 10.244.166.190 node1 <none> <none>
web1-ffffb5589-6zlk7 1/1 Running 0 18m 10.244.166.189 node1 <none> <none>
web1-ffffb5589-bwff4 1/1 Running 0 141m 10.244.166.180 node1 <none> <none>
[root@master deploy]#
[root@master deploy]# kubectl rollout history deployment
deployment.apps/web1
REVISION CHANGE-CAUSE
2 <none>
4 <none>
5 kubectl set image deploy web1 nginx=calico/cni:v3.19.1 --record=true
[root@master deploy]#
方式2
- 命令:
kubectl edit deploy deploy_name
里面的spec中找到image,直接在后面定义即可
spec:
containers:
- image: calico/cni:v3.19.1
imagePullPolicy: IfNotPresent
- 因为我通过方式1已经改为calico的镜像了,所以当前镜像的pod是error状态,现在我们改回nginx的镜像。
[root@master deploy]# kubectl edit deploy web1 --record=true
...
spec:
containers:
- image: calico/cni:v3.19.1
imagePullPolicy: IfNotPresent
改回来以后呢,状态就变成running了哦,且历史版本里也有记录。
[root@master deploy]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web1-ffffb5589-6stfl 1/1 Running 0 36s 10.244.166.129 node1 <none> <none>
web1-ffffb5589-bwff4 1/1 Running 0 160m 10.244.166.180 node1 <none> <none>
[root@master deploy]#
[root@master deploy]# kubectl rollout history deployment
deployment.apps/web1
REVISION CHANGE-CAUSE
2 <none>
5 kubectl set image deploy web1 nginx=calico/cni:v3.19.1 --record=true
6 kubectl edit deploy web1 --record=true
[root@master deploy]#
切换到某指定版本【版本回滚】
-
命令:
kubectl rollout undo deployment --to-revision=版本序号
版本序号查看:kubectl rollout history deployment -
如下:我在上面记录的2个版本之间切换一下。
[root@master deploy]# kubectl rollout history deployment
deployment.apps/web1
REVISION CHANGE-CAUSE
2 <none>
5 kubectl set image deploy web1 nginx=calico/cni:v3.19.1 --record=true
6 kubectl edit deploy web1 --record=true
[root@master deploy]#
[root@master deploy]# kubectl rollout undo deployment --to-revision=5
deployment.apps/web1 rolled back
[root@master deploy]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web1-5ff8df68cc-d5w5z 0/1 CrashLoopBackOff 1 10s 10.244.166.130 node1 <none> <none>
web1-5ff8df68cc-kqdtb 0/1 CrashLoopBackOff 1 7s 10.244.166.131 node1 <none> <none>
web1-ffffb5589-bwff4 1/1 Running 0 23h 10.244.166.180 node1 <none> <none>
[root@master deploy]# kubectl rollout history deployment
deployment.apps/web1
REVISION CHANGE-CAUSE
2 <none>
6 kubectl edit deploy web1 --record=true
7 kubectl set image deploy web1 nginx=calico/cni:v3.19.1 --record=true
[root@master deploy]# kubectl rollout undo deployment --to-revision=6
deployment.apps/web1 rolled back
[root@master deploy]#
[root@master deploy]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web1-ffffb5589-bwff4 1/1 Running 0 23h 10.244.166.180 node1 <none> <none>
web1-ffffb5589-g6cns 1/1 Running 0 5s 10.244.166.132 node1 <none> <none>
[root@master deploy]# kubectl rollout history deployment
deployment.apps/web1
REVISION CHANGE-CAUSE
2 <none>
7 kubectl set image deploy web1 nginx=calico/cni:v3.19.1 --record=true
8 kubectl edit deploy web1 --record=true
[root@master deploy]#
滚动升级
-
我们前面说过,镜像修改实际上是,删除原pod用新镜像的模版创建新pod。
-
假如现在有5个副本数,这些副本数是一次性删除呢,还是逐个删除再创建呢?
-
其实,这个是可以人为控制的,就是”滚动升级“,创建好的pod呢,有一个参数
strategy,这个就是定义一次删除数量和创建数量,定义规则有2种
1、是百分比形式:25%
2、就是直接定义个数。
-
定义这个呢,就必须使用上面的方式2来修改
-
命令:
kubectl edit deploy deploy_name -
如下图,这是默认的,是以百分比形式存在的,一次删除和创建四分之一的pod
这个比较直观,我就不测试了。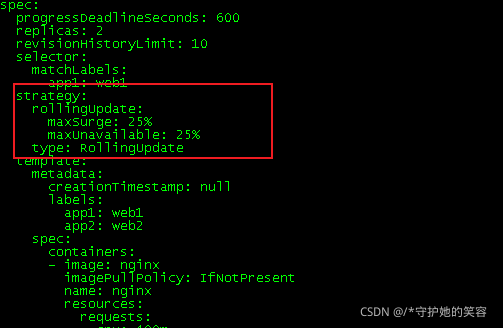

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)