Spark2.0机器学习系列之10: 聚类(高斯混合模型 GMM)
Spark GMM 高斯混合模型概念 参数设置 模型评估 代码
在Spark2.0版本中(不是基于RDD API的MLlib),共有四种聚类方法:
(1)K-means
(2)Latent Dirichlet allocation (LDA)
(3)Bisecting k-means(二分k均值算法)
(4)Gaussian Mixture Model (GMM)。
基于RDD API的MLLib中,共有六种聚类方法:
(1)K-means
(2)Gaussian mixture
(3)Power iteration clustering (PIC)
(4)Latent Dirichlet allocation (LDA)**
(5)Bisecting k-means
(6)Streaming k-means
多了Power iteration clustering (PIC)和Streaming k-means两种。
本文将介绍其中的一种高斯混合模型 ,Gaussian Mixture Model (GMM)。其它方法在我的Spark机器学习系列里面,都会介绍。
混合模型:通过密度函数的线性合并来表示未知模型 p(x) <script type="math/tex" id="MathJax-Element-856">p(x)</script>
为什么提出混合模型,那是因为单一模型与实际数据的分布严重不符,但是几个模型混合以后却能很好的描述和预测数据。
高斯混合模型(GMM),说的是把数据可以看作是从数个高斯分布中生成出来的。虽然我们可以用不同的分布来随意地构造 XX Mixture Model ,但是 GMM是最为流行。另外,Mixture Model 本身其实也是可以变得任意复杂的,通过增加 Model 的个数,我们可以任意地逼近任何连续的概率密分布。
二维情况下高斯分布模拟产生数据的分布是椭圆,如下图:
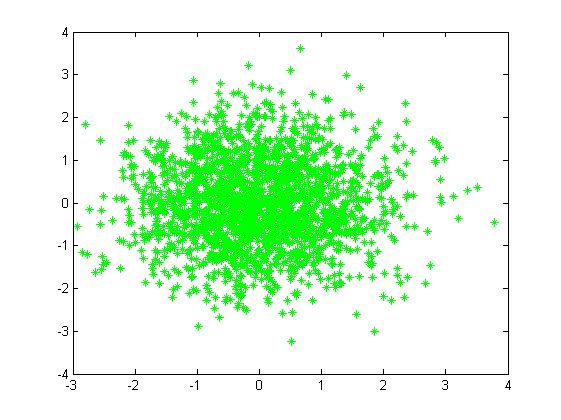
对于下面图(a)观测数据,单一的高斯概率分布函数(一个椭圆)无法表达,仔细看图(a)近似包含三个椭圆,所以可以将三个高斯概率分布函数线性组合起来,各个函数有不同的参数 N(σi,μi) <script type="math/tex" id="MathJax-Element-857">\mathcal{N}(\sigma_i,\mu_i)</script>和权重 πi <script type="math/tex" id="MathJax-Element-858">\pi_i</script>。线性组合

<script type="math/tex" id="MathJax-Element-860">~~~~~~</script>更一般地,GMM认为数据是从 K <script type="math/tex" id="MathJax-Element-861">K</script>个高斯函数组合而来的,即
<script type="math/tex" id="MathJax-Element-863">~~~~~~</script>隐含 K <script type="math/tex" id="MathJax-Element-864">K</script>个高斯函数,
<script type="math/tex" id="MathJax-Element-866">~~~~~~</script>如果估计未知参数 π,μ,σ <script type="math/tex" id="MathJax-Element-867">\pi,\mu,\sigma</script>,我们首先得分析以下最大似然估计:
<script type="math/tex" id="MathJax-Element-869">~~~~~~</script>由于在对数函数里面又有加和,我们没法直接用求导解方程的办法直接求得最大值。为了解决这个问题,采用了EM方法。
EM算法可参考我的另一篇文章
《机器学习算法(优化)之二:期望最大化(EM)算法》 http://blog.csdn.net/qq_34531825/article/details/52856948.
EM算法模型参数估计
<script type="math/tex" id="MathJax-Element-11">~~~~~~</script>每个GMM由K个Gaussian component分布组成。我以一维Gaussian函数,GMM模型有3个隐含component为例,通俗的说明。
E过程:
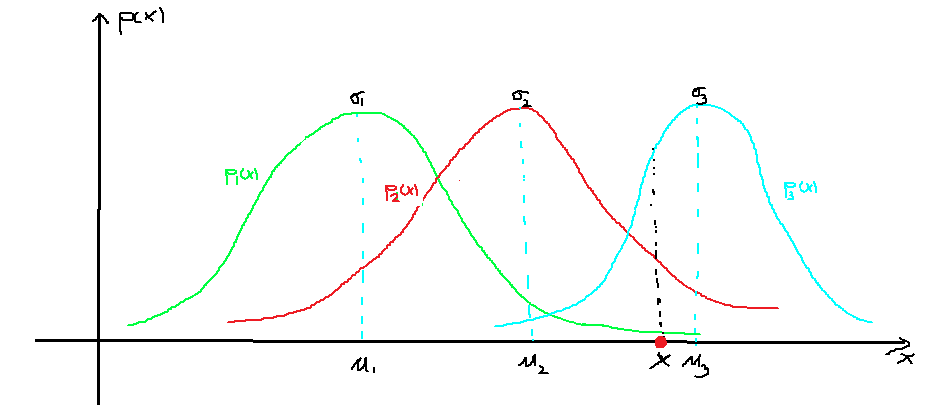
<script type="math/tex" id="MathJax-Element-12">~~~~~~</script>假定我们通过迭代(或者初始化),假设已经已经知道了GMM模型的三个component Gaussian函数的参数 θ(t)=(σ(t)1,μ(t)1)、(σ(t)2,μ(t)2)、(σ(t)3,μ(t)3) <script type="math/tex" id="MathJax-Element-13">\theta^{(t)}=(\sigma_1^{(t)},\mu_1^{(t)})、(\sigma_2^{(t)},\mu_2^{(t)})、(\sigma_3^{(t)},\mu_3^{(t)})</script>,且这三个函数分别以 π(t)1=0.3、π(t)2=0.3、π(t)3=0.4 <script type="math/tex" id="MathJax-Element-14">\pi_1^{(t)}=0.3、\pi_2^{(t)}=0.3、\pi_3^{(t)}=0.4</script>的概率被GMM模型选中(即 π(t)i为第i个component的权重 <script type="math/tex" id="MathJax-Element-15">\pi_i^{(t)}为第i个component 的权重</script>)。
<script type="math/tex" id="MathJax-Element-16">~~~~~~</script>高斯混合模型为 p(x|θ)=0.3∗N(x;μ1,σ1)+0.3∗N(x;μ2,σ2)+0.4∗N(x;μ3,σ3) <script type="math/tex" id="MathJax-Element-17">p(x|\theta)=0.3*\mathcal{N}(x;\mu_1,\sigma_1)+0.3*\mathcal{N}(x;\mu_2,\sigma_2)+0.4*\mathcal{N}(x;\mu_3,\sigma_3)</script>
<script type="math/tex" id="MathJax-Element-18">~~~~~~</script>迭代的第t步,对于观测到的 x <script type="math/tex" id="MathJax-Element-19">x</script>点,那么他究竟是3个隐含的Gaussina曲线中的那一个产生的呢?应该说都有可能,只是产生的概率大小不一样而已。如图中的x点,它由
<script type="math/tex" id="MathJax-Element-32">~~~~~~</script>更一般地,GMM认为数据是从 K <script type="math/tex" id="MathJax-Element-33">K</script>个高斯函数组合而来的,即
<script type="math/tex" id="MathJax-Element-35">~~~~~~</script>隐含 K <script type="math/tex" id="MathJax-Element-36">K</script>个高斯函数,
<script type="math/tex" id="MathJax-Element-39">~~~~~~</script>(1)E:对于观测点 xi <script type="math/tex" id="MathJax-Element-40">x_i</script>,是由第 k <script type="math/tex" id="MathJax-Element-41">k</script>个component产生的概率为
<script type="math/tex" id="MathJax-Element-43">~~~~~~</script>(2)M: xi <script type="math/tex" id="MathJax-Element-44">x_i</script>可以看作是有各部分加和而成的,其中由第k个component产生部分自然为: γ(xi,k)xi <script type="math/tex" id="MathJax-Element-45">\gamma(x_i,k)x_i</script>,所以可以认为第k个component产生了如下的数据:
<script type="math/tex" id="MathJax-Element-47">~~~~~~</script>而由于每个 Component 都是一个标准的 Gaussian 分布,可以很容易分布求出最大似然所对应的参数值:
<script type="math/tex" id="MathJax-Element-48">~~~~~~</script>
<script type="math/tex" id="MathJax-Element-53">~~~~~~</script>这样就完成了参数的更新,重复E步骤进行下一次迭代,直到算法收敛。
模型参数K设置及聚类结果评估
大家可能会想到,上图(a)中的数据分布太具有实验性质了,实际中那有这样的数据,但GMM牛逼的地方就在于通过增加 Model 的个数(也就是组成成分的数量K,其实就是我们的分类个数),可以任意地逼近任何连续的概率密分布。所以呢,理论上是绝对支持的,而实际上呢,对于多维特征数据我们往往难以可视化,所以难把握的地方也就在这里,如何选取K 值?换句化说聚类(无监督分类)拿什么标准如何评估模型的好坏?因为如果对结果有好评价指标的话,那么我们就可以实验不同的K,选出最优的那个K就好了,到底有没有呢?
这个话题又比较长,有人认为聚类的评估一定要做预先标注,没有Index总是让人觉得不靠谱,不是很让人信服。但是也有不同学者提出了大量的评估方法,主要是考虑到不同聚类算法的目标函数相差很大,有些是基于距离的,比如k-means,有些是假设先验分布的,比如GMM,LDA,有些是带有图聚类和谱分析性质的,比如谱聚类,还有些是基于密度的,所以难以拿出一个统一的评估方法,但是正是有这么些个原理上的不同,记着不与算法本身的原理因果颠倒的情况下,那么针对各类方法还是可以提出有针对性的评价指标的,如k-means的均方根误差。其实更应该嵌入到问题中进行评价,很多实际问题中,聚类仅仅是其中的一步,可以对比不聚类的情形(比如人为分割、随机分割数据集等等),所以这时候我们评价『聚类结果好坏』,其实是在评价『聚类是否能对最终结果有好的影响』。(本部分来综合了知乎上的部分问答:如有不妥之处,敬请告知。http://www.zhihu.com/question/19635522)
关于聚类的评估问题,我计划再写另外一篇文章《Spark聚类结果评估浅析》,不知道能否写好。
CSDN上还有文章可参考: 聚类算法初探(七)聚类分析的效果评测 http://blog.csdn.net/itplus/article/details/10322361
//训练模型
val gmm=new GaussianMixture().setK(2).setMaxIter(100).setSeed(1L)
val model=gmm.fit(dataset)
//输出model参数
for(i<-0 until model.getK){
println("weight=%f\nmu=%s\nsigma=\n%s\n" format(model.weights(i), model.gaussians(i).mean, model.gaussians(i).cov))
//weight是各组成成分的权重
//nsigma是样本协方差矩阵
//mu(mean)是各类质点位置 参考文献:
(1)混合高斯模型算法http://www.cnblogs.com/CBDoctor/archive/2011/11/06/2236286.html
(2) 聚类算法初探(七)聚类分析的效果评测 http://blog.csdn.net/itplus/article/details/10322361
(3)知乎 http://www.zhihu.com/question/19635522
(4)Rachel-Zhang的CSDN博客 GMM的EM算法实现 http://blog.csdn.net/abcjennifer/article/details/8198352
(5)漫谈 Clustering (3): Gaussian Mixture Model http://blog.pluskid.org/?p=39

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)