Keras实现GRU 与LSTM
目录LSTM 变种——GRU的原理GRU 与LSTM的对比Keras实现GRUkeras中使用gru/LSTM,如何选择获得最后一个隐状态还是所有时刻的隐状态LSTM的网络结构图:C是一个记忆单元, U和W是网络LSTM模型的参数(权值矩阵),i、f、o分别称之为输入门、遗忘门、输出门。σ表示sigmoid激活函数 ;s(t)是t时刻,LSTM隐藏层的激活值...
目录
keras中使用gru/LSTM,如何选择获得最后一个隐状态还是所有时刻的隐状态
LSTM的网络结构图:
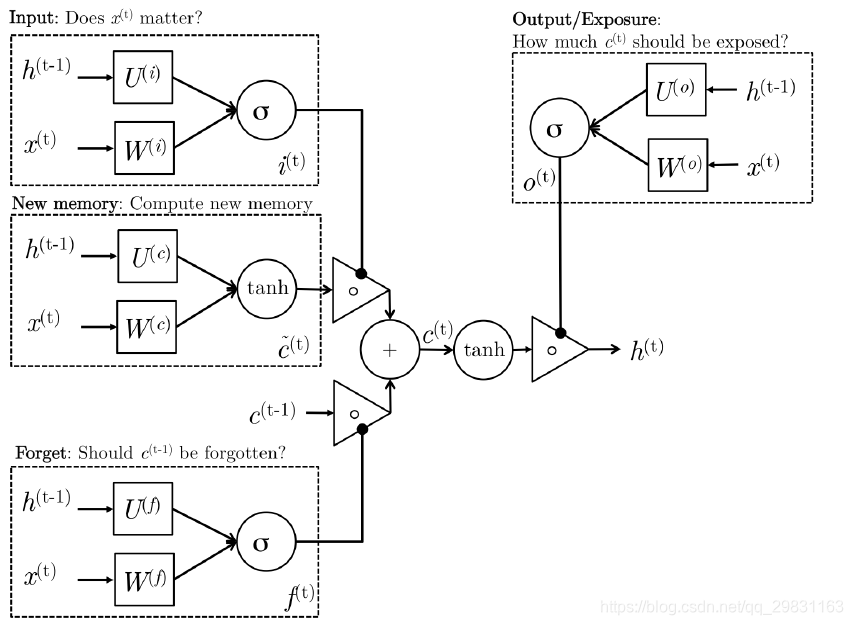
C是一个记忆单元, U和W是网络LSTM模型的参数(权值矩阵),
i、f、o分别称之为输入门、遗忘门、输出门。
σ表示sigmoid激活函数 ;s(t)是t时刻,LSTM隐藏层的激活值
LSTM在t时刻的输入包含:
- X(t) : t时刻网络的输入数据
- S(t-1) : t-1时刻隐藏层神经元的激活值
- C(t-1) :
输出就是t时刻隐层神经元激活值S(t)
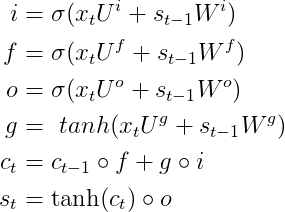
# keras实现LSTM网络
# Hyper parameters
batch_size = 128
nb_epoch = 10
input_shape = (nb_time_steps, dim_input_vector)
#nb_time_steps时间步 , dim_input_vector 表示输入向量的维度,也等于n_features,列数
X_train = X_train.astype('float32') / 255.
X_test = X_test.astype('float32') / 255.
Y_train = np_utils.to_categorical(y_train, nb_classes) #转为类别向量,nb_classes为类别数目
Y_test = np_utils.to_categorical(y_test, nb_classes)
# Build LSTM network
model = Sequential()
model.add(LSTM(nb_lstm_outputs, input_shape=input_shape))
model.add(Dense(nb_classes, activation='softmax', init=init_weights)) #初始权重
model.summary() #打印模型
plot(model, to_file='lstm_model.png') #绘制模型结构图,并保存成图片
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) #编译模型
history = model.fit(X_train, Y_train, nb_epoch=nb_epoch, batch_size=batch_size, shuffle=True, verbose=1) #迭代训练
score = model.evaluate(X_test, Y_test, verbose=1) #模型评估
print('Test score:', score[0])
print('Test accuracy:', score[1])
LSTM 变种——GRU的原理
参考【(译)理解LSTM网络 ----Understanding LSTM Networks by colah】【 理解GRU网络】
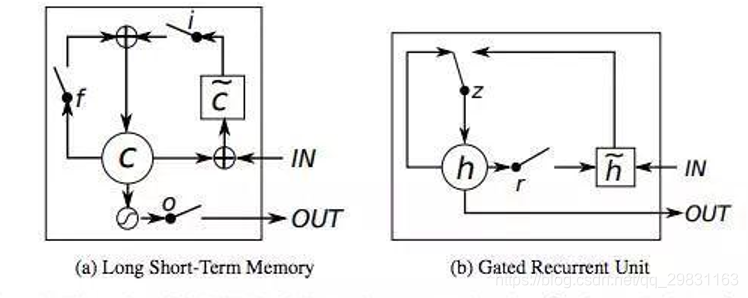
由Cho, et al. (2014) 提出如 fig.13 所示,只有两个门:重置门(reset gate)和更新门(update gate)。它把LSTM中的细胞状态【cell state,单元状态】和隐藏状态进行了合并,最后模型比标准LSTM 结构简单。
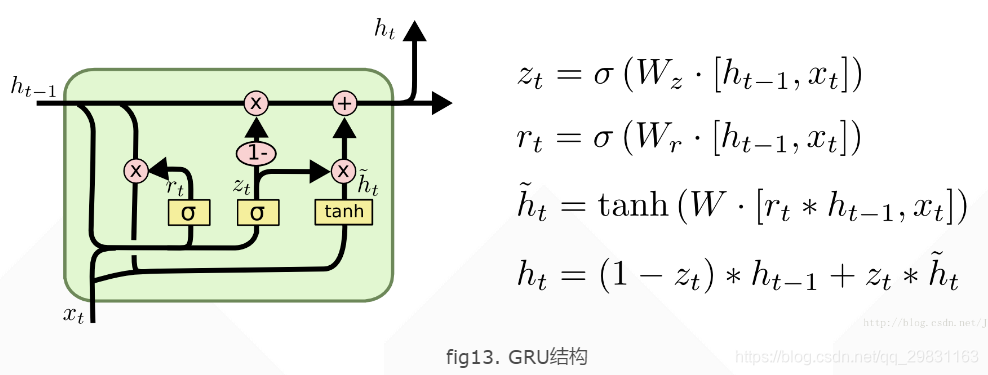
其中, 表示重置门,
表示更新门。重置门决定是否将之前的状态忘记。(作用相当于合并了 LSTM 中的遗忘门和传入门)当
趋于 0 的时候,前一个时刻的状态信息
会被忘掉,隐藏状态
会被重置为当前输入的信息。更新门决定是否要将隐藏状态更新为新的状态
(作用相当于 LSTM 中的输出门)。
GRU 与LSTM的对比
与 LSTM 相比:
(1) GRU 少一个门,同时少了细胞状态
(2) 在 LSTM 中,通过遗忘门和传入门控制信息的保留和传入;GRU 则通过重置门来控制是否要保留原来隐藏状态的信息,但是不再限制当前信息的传入。
(3) 在 LSTM 中,虽然得到了新的细胞状态 Ct,但是还不能直接输出,而是需要经过一个过滤的处理: ; 同样,在 GRU 中, 虽然 (2) 中我们也得到了新的隐藏状态
, 但是还不能直接输出,而是通过更新门来控制最后的输出:
Keras实现GRU
在这里,同样使用Imdb数据集,且使用同样的方法对数据集进行处理,详细处理过程可以参考《使用Keras进行深度学习:(五)RNN和双向RNN讲解及实践》一文。

Keras中的earlystopping【提前终止】 可用于防止过拟合,它在Keras.callbacks中,常用的命令方式:
early_stopping = EarlyStopping(monitor = 'val_loss', patience = 50, verbose = 2)
history = model.fit(train_x, train_y, epochs = 300, batchsize = 20, validation_data =(test_x,test_y), verbose = 2,shuffle =False, callbacks =[early_stopping])参数:
- monitor表示要监视的量,如 目标函数值loss,acc准确率等,
- epoch迭代次数,训练的轮数。
- batch_size :设置批量的大小,每次训练和梯度更新块的大小
- patience : 当earlystop 被激活后【eg.发现loss相比上一轮没有下降】则经过patience 个epoch后再停止训练。
- verbose :信息展示模式/进度表示方式。0表示不显示数据,1表示显示进度条,2表示用只显示一个数据。
- callbacks : 回调函数列表。就是函数执行完后自动调用的函数列表。
- validation_split : 验证数据的使用比例。
- validation_data : 被用来作为验证数据的(X, y)元组。会代替validation_split所划分的验证数据。
- shuffle : 类型为boolean或 str(‘batch’)。是否对每一次迭代的样本进行shuffle操作(可以参见博文Theano学习笔记01--Dimshuffle()函数)。’batch’是一个用于处理HDF5(keras用于存储权值的数据格式)数据的特殊选项。
- show_accuracy:每次迭代是否显示分类准确度。
- class_weight : 分类权值键值对。
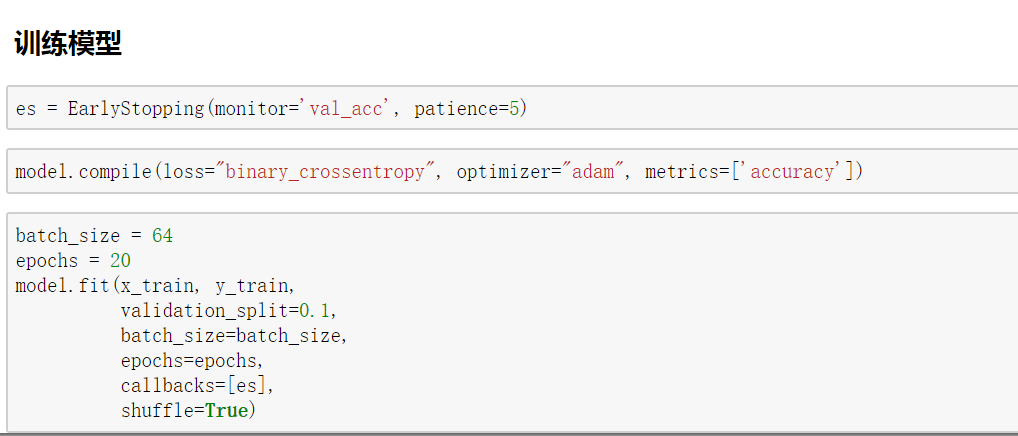
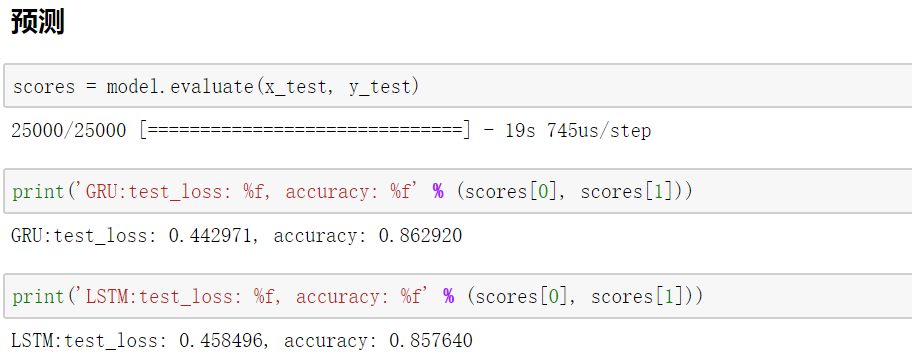
可以发现GRU和LSTM具有同样出色的结果,甚至比LSTM结果好一些。在很多时候,人们更愿意使用GRU来替换LSTM,因为GRU比LSTM少一个门,参数更少,相对容易训练且可以防止过拟合。(训练样本少的时候可以使用防止过拟合,训练样本多的时候则可以节省很多训练时间。)因此GRU是一个非常流行的LSTM变体。同时,希望通过该文能让读者对GRU有更深刻的了解。
keras中使用gru/LSTM,如何选择获得最后一个隐状态还是所有时刻的隐状态
gru_layer=GRU(units=50,activation='relu',return_sequences=True)
当return_sequences为True,返回所有时刻的状态,即(batch_size,time_steps,units)
否则,返回最后的隐状态,即(batch_size,units)
LSTM 超参数调试
以下是手动优化 RNN 超参数时需要注意的一些事:
- 小心出现过拟合,这通常是因为神经网络在“死记”定型数据。过拟合意味着定 型数据的表现会很好,但网络的模型对于样例以外的预测则完全无用。
- 正则化有好处:正则化的方法包括 L1、L2 和丢弃法等。
- 保留一个神经网络不作定型的单独测试集。
- 网络越大,功能越强,但也更容易过拟合。不要尝试用 10,000 个样例来学习一 百万个参数 参数 > 样例数 = 问题。
- 数据基本上总是越多越好,因为有助于防止过拟合。
- 定型应当包括多个 epoch(使用整个数据集定型一次)。
- 每个 epoch 之后,评估测试集表现,判断何时停止(提前停止)。
- 学习速率是最为重要的超参数。可用 deeplearning4j-ui 调试;
- 总体而言,堆叠层是有好处的。
- 对于 LSTM,可使用 softsign(而非 softmax)激活函数替代 tanh(更快且更不 容易出现饱和(约 0 梯度))。
- 更新器:RMSProp、AdaGrad 或 momentum(Nesterovs)通常都是较好的选择。 AdaGrad 还能衰减学习速率,有时会有帮助。
- 最后,记住数据标准化、MSE 损失函数 + 恒等激活函数用于回归、Xavier 权重 初始化
注:本文转自【使用Keras进行深度学习:(七)GRU讲解及实践】 参考LSTM、GRU网络入门学习

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 16
16 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)