隐马尔可夫模型(HMM)
教程hmmlearn实现隐马尔可夫模型(HMM)。HMM 是一种生成概率模型,其中可观察到的序列 X变量由一系列内部隐藏状态生成Z. 不直接观察隐藏状态。假设隐藏状态之间的转换具有(一阶)马尔可夫链的形式。它们可以由开始概率向量指定π和转移概率矩阵 A. Observable 的发射概率可以是任何带参数的分布θ以当前隐藏状态为条件。HMM 完全由下式确定 π, A和θ.HMM存在三个基本问题:给定
教程
hmmlearn实现隐马尔可夫模型(HMM)。HMM 是一种生成概率模型,其中可观察到的序列 X变量由一系列内部隐藏状态生成Z. 不直接观察隐藏状态。假设隐藏状态之间的转换具有(一阶)马尔可夫链的形式。它们可以由开始概率向量指定π和转移概率矩阵 A. Observable 的发射概率可以是任何带参数的分布θ以当前隐藏状态为条件。HMM 完全由下式确定 π, A和θ.
HMM存在三个基本问题:
-
给定模型参数和观测数据,估计隐藏状态的最佳序列。
-
给定模型参数和观测数据,计算模型似然度。
-
仅给定观察到的数据,估计模型参数。
第一个和第二个问题可以分别通过称为维特比算法和前向后向算法的动态规划算法来解决。最后一个可以通过迭代期望最大化 (EM) 算法解决,称为 Baum-Welch 算法。
可用型号
|
具有高斯发射的隐马尔可夫模型。 |
|
|
具有高斯混合排放的隐马尔可夫模型。 |
|
|
具有多项(离散)排放的隐马尔可夫模型。 |
继续阅读有关如何使用自定义发射概率实现 HMM 的详细信息。
构建 HMM 并生成样本
您可以通过将上述参数传递给构造函数来构建 HMM 实例。然后,您可以通过调用从 HMM 生成样本 sample()。
import numpy as np
from hmmlearn import hmm
np.random.seed(42)
model = hmm.GaussianHMM(n_components=3, covariance_type="full")
model.startprob_ = np.array([0.6, 0.3, 0.1])
model.transmat_ = np.array([[0.7, 0.2, 0.1],
[0.3, 0.5, 0.2],
[0.3, 0.3, 0.4]])
model.means_ = np.array([[0.0, 0.0], [3.0, -3.0], [5.0, 10.0]])
model.covars_ = np.tile(np.identity(2), (3, 1, 1))
X, Z = model.sample(100)转移概率矩阵不必是遍历的。例如,一个左右 HMM 可以定义如下:
lr = hmm.GaussianHMM(n_components=3, covariance_type="diag",
init_params="cm", params="cmt")
lr.startprob_ = np.array([1.0, 0.0, 0.0])
lr.transmat_ = np.array([[0.5, 0.5, 0.0],
[0.0, 0.5, 0.5],
[0.0, 0.0, 1.0]])如果缺少任何必需的参数,sample() 将引发异常:
model = hmm.GaussianHMM(n_components=3)
X, Z = model.sample(100)Traceback (most recent call last):
...
sklearn.exceptions.NotFittedError: This GaussianHMM instance is not fitted yet. Call 'fit' with appropriate arguments before using this method.
固定参数
每个 HMM 参数都有一个字符代码,可用于自定义其初始化和估计。EM 算法需要一个起点来进行,因此在训练之前,每个参数都被分配一个随机值或从数据计算的值。可以挂钩到这个过程并明确地提供一个起点。这样做
-
确保参数的字符代码缺失
init_params,然后 -
将参数设置为所需的值。
例如,考虑一个具有显式初始化转移概率矩阵的 HMM:
model = hmm.GaussianHMM(n_components=3, n_iter=100, init_params="mcs")
model.transmat_ = np.array([[0.7, 0.2, 0.1],
[0.3, 0.5, 0.2],
[0.3, 0.3, 0.4]])类似的技巧适用于参数估计。如果您想将某些参数固定为特定值,请 params在训练前从中删除相应字符并设置参数值。
训练 HMM 参数并推断隐藏状态
您可以通过调用该fit()方法来训练 HMM。输入是串联的观察序列(又名样本)以及序列长度的矩阵(请参阅使用多个序列)。
注意,由于 EM 算法是一种基于梯度的优化方法,它通常会陷入局部最优。通常,您应该尝试fit 使用各种初始化运行并选择得分最高的模型。
可以通过该score()方法计算模型的分数。
predict()通过调用方法可以获得推断出的最优隐藏状态 。predict可以使用解码器算法指定该方法。目前支持 Viterbi 算法 ( "viterbi") 和最大后验估计 ( "map")。
这一次,输入是单个观察值序列。请注意,其中的状态remodel将与生成模型中的状态不同。
remodel = hmm.GaussianHMM(n_components=3, covariance_type="full", n_iter=100)
remodel.fit(X)
GaussianHMM(...
Z2 = remodel.predict(X)监控收敛
EM 算法迭代次数的上限由n_iter 参数决定。训练继续进行,直到n_iter执行了步骤或分数的变化低于指定的阈值tol。请注意,根据数据,EM 算法可能会或可能不会在给定的步骤数内实现收敛。
您可以使用该monitor_属性来诊断收敛:
remodel.monitor_
ConvergenceMonitor(
history=[...],
iter=10,
n_iter=100,
tol=0.01,
verbose=False,
)
remodel.monitor_.converged
True处理多个序列
到目前为止,所有示例都使用单个观察序列。多序列情况下的输入格式有点牵强,最好通过例子来理解。
考虑两个一维序列:
X1 = [[0.5], [1.0], [-1.0], [0.42], [0.24]]
X2 = [[2.4], [4.2], [0.5], [-0.24]]要将两个序列传递给fit()or predict(),首先将它们连接成一个数组,然后计算一个序列长度数组:
X = np.concatenate([X1, X2])
lengths = [len(X1), len(X2)]X最后,只需使用and调用所需的方法lengths:
hmm.GaussianHMM(n_components=3).fit(X, lengths)保存和加载 HMM
训练后,HMM 可以很容易地与标准 pickle模块一起保存以备将来使用:
import pickle
with open("filename.pkl", "wb") as file: pickle.dump(remodel, file)
with open("filename.pkl", "rb") as file: pickle.load(file)使用自定义发射概率实现 HMM
如果要实现自定义发射概率(例如泊松),则必须继承BaseHMM并覆盖以下方法
|
在拟合之前初始化模型参数。 |
|
|
在拟合之前验证模型参数。 |
|
|
BaseHMM._generate_sample_from_state(状态[, ...]) |
从给定组件生成随机样本。 |
|
计算模型下的每组分排放对数概率。 |
|
|
计算模型下的每个分量概率。 |
|
|
初始化 M 步所需的足够统计量。 |
|
|
从给定的样本中更新足够的统计数据。 |
|
|
执行 EM 算法的 M 步。 |
可选地,只有一个_compute_likelihood和 _compute_log_likelihood需要被覆盖,基本实现将提供另一个。
Sampling from HMM
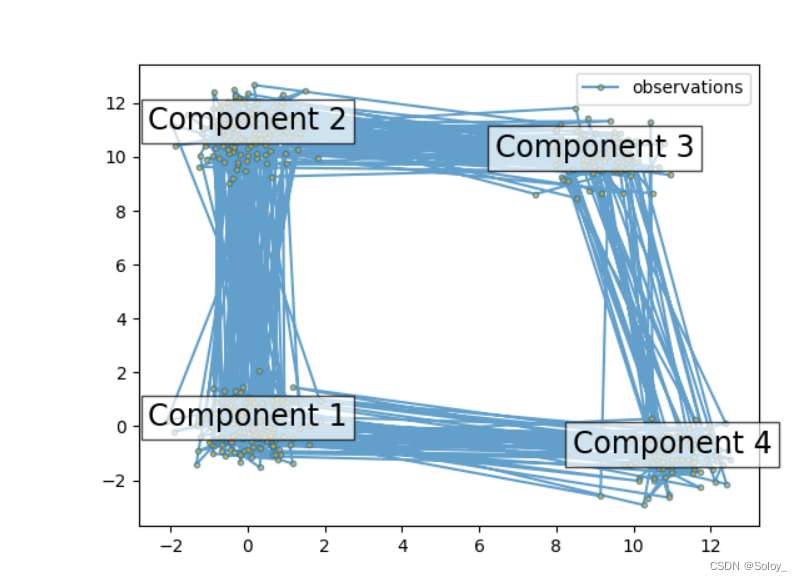
此脚本显示如何从隐马尔可夫模型 (HMM) 中采样点:我们使用具有指定均值和协方差的 4 状态模型。
该图显示了随着它们之间的转换而生成的观察序列。我们可以看到,正如我们的转换矩阵所指定的,组件 1 和 3 之间没有转换。
import numpy as np
import matplotlib.pyplot as plt
from hmmlearn import hmm
# Prepare parameters for a 4-components HMM
# Initial population probability
startprob = np.array([0.6, 0.3, 0.1, 0.0])
# The transition matrix, note that there are no transitions possible
# between component 1 and 3
transmat = np.array([[0.7, 0.2, 0.0, 0.1],
[0.3, 0.5, 0.2, 0.0],
[0.0, 0.3, 0.5, 0.2],
[0.2, 0.0, 0.2, 0.6]])
# The means of each component
means = np.array([[0.0, 0.0],
[0.0, 11.0],
[9.0, 10.0],
[11.0, -1.0]])
# The covariance of each component
covars = .5 * np.tile(np.identity(2), (4, 1, 1))
# Build an HMM instance and set parameters
model = hmm.GaussianHMM(n_components=4, covariance_type="full")
# Instead of fitting it from the data, we directly set the estimated
# parameters, the means and covariance of the components
model.startprob_ = startprob
model.transmat_ = transmat
model.means_ = means
model.covars_ = covars
# Generate samples
X, Z = model.sample(500)
# Plot the sampled data
plt.plot(X[:, 0], X[:, 1], ".-", label="observations", ms=6,
mfc="orange", alpha=0.7)
# Indicate the component numbers
for i, m in enumerate(means):
plt.text(m[0], m[1], 'Component %i' % (i + 1),
size=17, horizontalalignment='center',
bbox=dict(alpha=.7, facecolor='w'))
plt.legend(loc='best')
plt.show()
欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)