让HR也能自己开发MCP Server的MCP实战课
在上一篇文章中,我们介绍了MCP的基本概念、架构和价值。今天,我们将进入实战环节,手把手教大家如何使用Python开发MCP服务器和客户端,并展示一个实用的MySQL数据库查询与可视化示例。
在上一篇文章中,我们介绍了MCP的基本概念、架构和价值。今天,我们将进入实战环节,手把手教大家如何使用Python开发MCP服务器和客户端,并展示一个实用的MySQL数据库查询与可视化示例。

第一部分:开发一个简单的MCP Server
让我们从一个简单的入门示例开始,开发一个"李明成绩查询"的MCP服务器,它可以查询李明的语文、数学和英语成绩。
环境准备
首先,确保你的系统已安装Python 3.10或更高版本。我们将使用pip工具来管理Python环境:
# 创建项目目录 mkdir score-mcp cd score-mcp # 创建并激活虚拟环境 # MacOS/Linux python -m venv venv source venv/bin/activate # Windows python -m venv venv venv\Scripts\activate # 安装依赖 pip install "mcp[cli]"
创建我们的第一个MCP服务器
现在,让我们创建一个简单的MCP服务器,它提供查询李明成绩的功能。
创建一个名为score_server.py的文件:
import asyncio
from mcp.server.fastmcp import FastMCP
from mcp.server.stdio import stdio_server
from mcp.types import CallToolResult
# 创建一个FastMCP服务器实例
mcp = FastMCP("score-query")
# 李明的成绩数据
SCORE_DATA = {
"语文": 85,
"数学": 92,
"英语": 78
}
@mcp.tool()
async def get_score(subject: str) -> CallToolResult:
'''
获取李明的某一科目成绩。
参数:
subject: 科目名称,可以是"语文"、"数学"或"英语"
返回:
科目对应的成绩信息
'''
if subject in SCORE_DATA:
return CallToolResult(
result=f"李明的{subject}成绩是: {SCORE_DATA[subject]}分"
)
else:
return CallToolResult(
result=f"没有找到{subject}科目的成绩。可用的科目有:语文、数学、英语"
)
if __name__ == "__main__":
print("李明的成绩查询MCP服务器已启动。")
mcp.run(transport='stdio')
这个服务器只提供了一个简单的工具:get_score,用于查询李明在特定科目的成绩。我们使用了三引号注释(这里是十分关键的)来描述参数,这符合Python的文档字符串格式。
是不是贼简单,感觉公司那几个一点技术不懂、想法又特别多的HR(无恶意)借助Cursor都能开发出自己想要的MCP Server了。(事实确实如此!)
运行MCP服务器
将上面的代码保存到score_server.py文件中,然后在终端中运行:
python score_server.py
服务代码已经完成。现在是时候开发一个客户端来使用这个服务器了!
第二部分:开发一个MCP客户端
现在,让我们创建一个简单的客户端来连接和使用我们刚刚创建的MCP服务器。我们将保持客户端代码简洁,只专注于连接服务器并查询成绩。
说明:客户端代码相对来说会比服务端要复杂一些,对于不做技术的小伙伴或者不做Agent开发的研发一般也不会需要自己写 MCP Client,可以跳过这一部分!
创建新的项目目录
# 创建客户端目录 cd .. # 回到上级目录 mkdir score-mcp-client cd score-mcp-client # 创建并激活虚拟环境 # MacOS/Linux python -m venv venv source venv/bin/activate # Windows python -m venv venv venv\Scripts\activate # 安装依赖 pip install "mcp[cli]" openai python-dotenv
实际上跟Server放到同一个项目、同一个环境也是可以的。
创建客户端代码
创建一个名为score_client.py的文件:
import asyncio
import os
import json
import sys
from typing import Dict, Any, Optional, List, Union
from contextlib import AsyncExitStack
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from openai import OpenAI
from dotenv import load_dotenv
import logging
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler(sys.stdout)
]
)
# 加载环境变量
load_dotenv()
# 获取OpenAI API密钥
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
OPENAI_BASE_URL = os.getenv("OPENAI_BASE_URL")
if not OPENAI_API_KEY:
logging.error("错误: 未设置OPENAI_API_KEY环境变量。请在.env文件中添加你的API密钥。")
sys.exit(1)
class ScoreMCPClient:
def __init__(self):
"""初始化成绩查询客户端"""
# 初始化会话和客户端对象
self.session = None
self.exit_stack = AsyncExitStack()
# 初始化OpenAI客户端
openai_config = {}
if OPENAI_API_KEY:
openai_config["api_key"] = OPENAI_API_KEY
if OPENAI_BASE_URL:
openai_config["base_url"] = OPENAI_BASE_URL
self.openai = OpenAI(**openai_config)
# 保存对话历史
self.conversation_history = []
self.tools = []
async def connect_to_server(self, server_script_path: str):
"""连接到成绩查询MCP服务器
Args:
server_script_path: 服务器脚本路径(.py文件)
"""
logging.info(f"正在连接到李明的成绩查询服务器...")
# 创建服务器参数
server_params = StdioServerParameters(
command="python",
args=[server_script_path],
env=None
)
try:
# 建立连接
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
read_stream, write_stream = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(read_stream, write_stream))
# 初始化连接
await self.session.initialize()
logging.info("服务器连接成功初始化")
# 列出可用工具
response = await self.session.list_tools()
self.tools = response.tools
logging.info(f"\n服务器可用工具: {[tool.name for tool in self.tools]}")
return True
except Exception as e:
logging.error(f"连接到服务器时出错: {e}")
return False
async def process_message(self, query: str) -> str:
"""处理用户消息,由GPT-4o决定是否调用工具
Args:
query: 用户查询
Returns:
处理结果
"""
if not self.session:
return "错误: 未连接到服务器"
# 将用户消息添加到历史
self.conversation_history.append({
"role": "user",
"content": query
})
# 格式化工具定义以符合OpenAI API要求
formatted_tools = []
for tool in self.tools:
formatted_tools.append({
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"parameters": tool.inputSchema
}
})
# 调用GPT-4o
try:
logging.info(f"发送请求到GPT-4o:{query}...")
response = self.openai.chat.completions.create(
model="gpt-4o",
messages=self.conversation_history,
tools=formatted_tools,
tool_choice="auto"
)
# 处理响应
response_message = response.choices[0].message
final_text = []
logging.info(f"GPT-4o的响应: {response_message}")
# 检查是否有工具调用
if hasattr(response_message, 'tool_calls') and response_message.tool_calls:
logging.info(f"GPT-4o决定调用工具,共 {len(response_message.tool_calls)} 个工具调用")
# 添加助手消息到历史
self.conversation_history.append({
"role": "assistant",
"content": None,
"tool_calls": [
{
"id": tool_call.id,
"type": "function",
"function": {
"name": tool_call.function.name,
"arguments": tool_call.function.arguments
}
}
for tool_call in response_message.tool_calls
]
})
# 处理每个工具调用
for tool_call in response_message.tool_calls:
tool_id = tool_call.id
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
logging.info(f"处理工具调用: {function_name} (ID: {tool_id})")
final_text.append(f"[查询: {function_args}]")
# 调用MCP工具
try:
result = await self.session.call_tool(
name=function_name,
arguments=function_args
)
# 处理工具结果
tool_result = ""
if hasattr(result, 'isError') and result.isError:
# 工具调用出错
tool_result = "工具调用失败"
if hasattr(result, 'content') and result.content:
for content_item in result.content:
if hasattr(content_item, 'text'):
tool_result = content_item.text
# 尝试从错误信息中提取结果
if "input_value=" in tool_result:
import re
match = re.search(r"input_value=(\{.*?\})", tool_result)
if match:
try:
value_dict = eval(match.group(1))
if 'result' in value_dict:
tool_result = value_dict['result']
except:
pass
else:
# 工具调用成功
tool_result = json.dumps(result)
logging.info(f"工具调用结果: {tool_result[:100]}...")
# 添加工具响应到历史
self.conversation_history.append({
"role": "tool",
"tool_call_id": tool_id,
"content": tool_result
})
except Exception as e:
tool_result = f"工具调用错误: {str(e)}"
logging.error(f"工具调用失败: {str(e)}")
# 添加错误响应到历史
self.conversation_history.append({
"role": "tool",
"tool_call_id": tool_id,
"content": tool_result
})
# 所有工具调用完成后,再次调用GPT-4o处理结果
logging.info("所有工具调用处理完毕,再次调用GPT-4o处理结果")
follow_up_response = self.openai.chat.completions.create(
model="gpt-4o",
messages=self.conversation_history
)
follow_up_message = follow_up_response.choices[0].message
final_text.append(follow_up_message.content)
# 将GPT-4o的最终响应添加到历史
self.conversation_history.append({
"role": "assistant",
"content": follow_up_message.content
})
else:
# GPT-4o没有调用工具,直接返回响应
logging.info("GPT-4o直接回答,未调用工具")
# 将助手消息添加到历史
self.conversation_history.append({
"role": "assistant",
"content": response_message.content
})
final_text.append(response_message.content)
return "\n".join(final_text)
except Exception as e:
error_msg = f"处理请求时出错: {str(e)}"
logging.error(error_msg)
return error_msg
async def interactive_loop(self):
"""运行交互式查询循环"""
print("\n成绩查询客户端已启动!")
print("与李明的成绩查询助手对话,GPT-4o将自动决定何时调用工具")
print("您可以进行连续对话,系统会保留对话历史")
print("输入'退出'或'exit'结束程序")
while True:
try:
query = input("\n> ").strip()
if not query:
continue
if query.lower() in ["退出", "exit", "quit"]:
break
print("处理中...")
response = await self.process_message(query)
print(f"\n{response}")
except KeyboardInterrupt:
print("\n操作已取消")
break
except EOFError:
break
except Exception as e:
print(f"\n错误: {str(e)}")
async def cleanup(self):
"""清理资源"""
try:
if self.exit_stack:
await self.exit_stack.aclose()
except Exception as e:
logging.error(f"清理资源时出错: {e}")
async def main():
client = ScoreMCPClient()
try:
if await client.connect_to_server("score_server.py"):
await client.interactive_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
asyncio.run(main())
设置API密钥
你需要创建一个.env文件并添加你的OpenAI API密钥:
OPENAI_API_KEY=你的OpenAI_API_密钥 OPENAI_BASE_URL=三方代理商地址或 https://api.openai.com/v1
运行客户端
现在,让我们运行客户端来测试与服务器的连接:
python score_client.py
如果一切正常,你应该会看到客户端连接到服务器。我们在命令询问 “语文成绩是多少”, LLM就会调用get_score工具查询李明的数学成绩,然后根据调用结果回答。
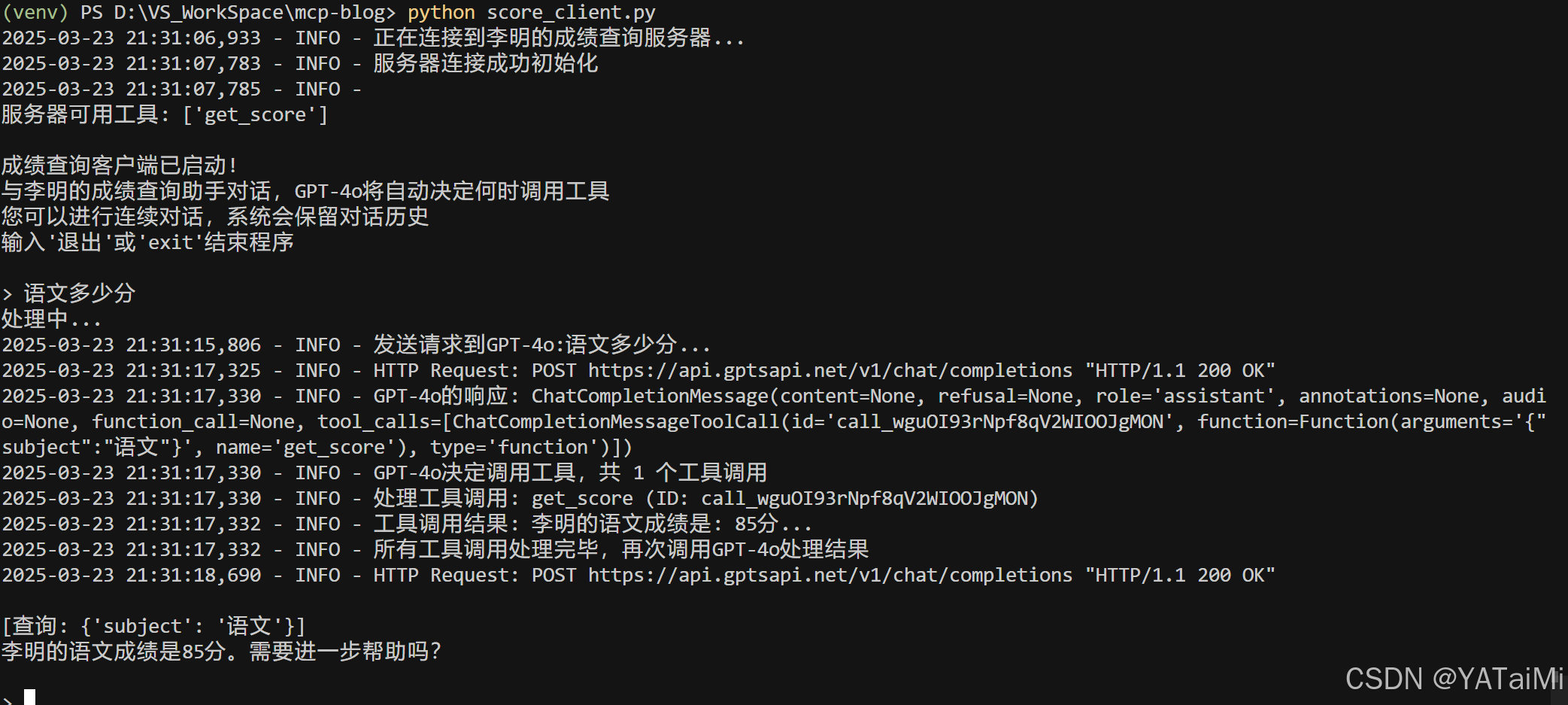
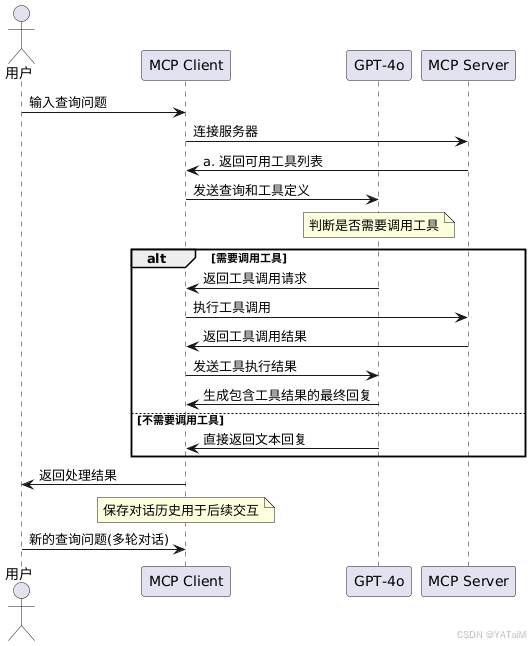
让我们来概括一下客户端的运行流程:
-
Client启动时通过命令挂起并连接Server(就是我们在Cursor里配置的mcp.json里的command),在这里是python D:/VS_WorkSpace/mcp-blog/score_server.py -
Client先查出Server总共有哪些tool -
在用户提问是将tool一同传给 LLM,由LLM决定是否调用、调用哪个工具
-
客户端根据 LLM 返回的要调用的tool以及要传入的parameters 调用
Server提供的tool (AI本身是不能执行方法的) -
Server tool 返回参数再传给LLM,LLM 总结后给出最终回复
好了,现在李明妈妈直接可以通过问AI就能知道李明的分数了。李明不需要再麻烦自己亲自跟妈妈讲了,不知道他会有多开心呢!
第三部分:开发实用的MySQL数据库查询与可视化服务器
现在,让我们进一步深入,创建一个更实用的MCP服务器,它可以:
-
连接到MySQL数据库
-
执行SQL查询
-
生成数据可视化
这种服务器在生产环境中非常有用,可以让AI助手直接查询公司数据库并生成可视化报表。
项目设置
# 创建项目目录 mkdir mysql-viz-mcp cd mysql-viz-mcp # 创建并激活虚拟环境 # MacOS/Linux python -m venv venv source venv/bin/activate # Windows python -m venv venv venv\Scripts\activate # 安装依赖 pip install "mcp[cli]" aiomysql pandas matplotlib
创建MySQL服务器
创建一个名为mysql_server.py的文件:
"""
MySQL数据库MCP服务器
提供与MySQL数据库交互的通用工具和提示模板
"""
import mysql.connector
import pandas as pd
import matplotlib.pyplot as plt
import io
import base64
import json
import logging
import os
import sys
from typing import Dict, List, Any, Optional
from datetime import datetime, date
from mcp.server.fastmcp import FastMCP
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[logging.StreamHandler(sys.stderr)]
)
logger = logging.getLogger('mysql_mcp_server')
# 从环境变量获取数据库连接配置
DB_CONFIG = {
"host": os.environ.get("DB_HOST", "localhost"),
"user": os.environ.get("DB_USER", "root"),
"password": os.environ.get("DB_PASSWORD", ""),
"database": os.environ.get("DB_NAME", "demo"),
"charset": 'utf8mb4',
"use_unicode": True,
"get_warnings": True
}
logger.info(f"从环境变量加载数据库配置: {DB_CONFIG['host']}/{DB_CONFIG['database']}")
# 初始化MCP服务器
server = FastMCP(name="mysql-server", description="MySQL数据库交互服务器")
def get_db_connection():
"""创建并返回数据库连接"""
try:
return mysql.connector.connect(**DB_CONFIG)
except Exception as e:
logger.error(f"数据库连接错误: {str(e)}")
return None
def json_serialize(obj):
"""处理特殊类型的JSON序列化"""
if isinstance(obj, (datetime, date)):
return obj.isoformat()
elif hasattr(obj, 'decimal') or str(type(obj)) == "<class 'decimal.Decimal'>":
# 处理Decimal类型
return float(obj)
raise TypeError(f"Object of type {type(obj)} is not JSON serializable")
# ======= 数据库工具 =======
@server.tool()
async def execute_query(query: str) -> Dict[str, Any]:
"""执行SQL查询并返回结果
Args:
query: SQL查询语句
Returns:
查询结果或错误信息
"""
try:
logger.info(f"执行SQL查询: {query}")
conn = get_db_connection()
if not conn:
logger.error("数据库连接失败")
return {"error": "无法连接到数据库"}
cursor = conn.cursor(dictionary=True)
cursor.execute(query)
# 检查是否是SELECT查询
if query.strip().upper().startswith(("SELECT", "SHOW", "DESCRIBE")):
results = cursor.fetchall()
logger.debug(f"查询返回 {len(results)} 条结果")
try:
# 确保结果是可JSON序列化的
serializable_results = json.loads(
json.dumps(results[:1000], default=json_serialize)
)
logger.info("成功序列化查询结果")
return {
"success": True,
"query_type": "SELECT",
"row_count": len(results),
"results": serializable_results
}
except Exception as e:
logger.error(f"JSON序列化失败: {str(e)}")
return {"error": f"结果序列化失败: {str(e)}"}
else:
# 对于INSERT, UPDATE, DELETE等查询
conn.commit()
logger.info(f"更新操作影响了 {cursor.rowcount} 行")
return {
"success": True,
"query_type": "UPDATE",
"affected_rows": cursor.rowcount,
"message": f"查询执行成功,影响了{cursor.rowcount}行"
}
except Exception as e:
logger.error(f"查询执行失败: {str(e)}")
return {"error": str(e)}
finally:
if 'conn' in locals() and conn is not None and conn.is_connected():
cursor.close()
conn.close()
logger.debug("数据库连接已关闭")
@server.tool()
async def get_tables() -> Dict[str, Any]:
"""获取数据库中的所有表
Returns:
表列表及其行数和结构
"""
try:
logger.info("获取所有表信息")
# 执行查询获取所有表
tables_result = await execute_query("SHOW TABLES")
if "error" in tables_result:
logger.error(f"获取表列表失败: {tables_result['error']}")
return tables_result
tables = []
for table_row in tables_result["results"]:
table_name = list(table_row.values())[0]
logger.debug(f"处理表: {table_name}")
# 获取表的行数
count_result = await execute_query(f"SELECT COUNT(*) as count FROM `{table_name}`")
row_count = 0
if "error" not in count_result and count_result["results"]:
row_count = count_result["results"][0]["count"]
# 获取表结构
structure_result = await execute_query(f"DESCRIBE `{table_name}`")
structure = structure_result.get("results", []) if "error" not in structure_result else []
try:
# 确保数据是可JSON序列化的
serializable_structure = json.loads(
json.dumps(structure, default=json_serialize)
)
logger.debug(f"表 {table_name} 结构序列化成功")
tables.append({
"name": table_name,
"row_count": row_count,
"structure": serializable_structure
})
except Exception as e:
logger.error(f"表 {table_name} 结构序列化失败: {str(e)}")
return {"error": f"表结构序列化失败: {str(e)}"}
logger.info(f"成功获取 {len(tables)} 个表的信息")
return {
"success": True,
"database": DB_CONFIG["database"],
"table_count": len(tables),
"tables": tables
}
except Exception as e:
logger.error(f"获取表信息失败: {str(e)}")
return {"error": str(e)}
@server.tool()
async def visualize_data(query: str, x_column: str, y_column: str, chart_type: str = "bar") -> Dict[str, Any]:
"""执行查询并可视化结果
Args:
query: SQL查询语句
x_column: X轴列名
y_column: Y轴列名
chart_type: 图表类型 (bar, line, scatter, pie)
Returns:
包含Base64编码图表的结果
"""
try:
# 执行查询
query_result = await execute_query(query)
if "error" in query_result:
return query_result
if not query_result.get("results"):
return {"error": "查询没有返回结果"}
# 将结果转换为DataFrame
df = pd.DataFrame(query_result["results"])
# 检查列是否存在
if x_column not in df.columns:
return {"error": f"列 '{x_column}' 不在结果中"}
if y_column not in df.columns:
return {"error": f"列 '{y_column}' 不在结果中"}
# 创建图表
plt.figure(figsize=(10, 6))
if chart_type == "bar":
plt.bar(df[x_column], df[y_column])
plt.title(f"{y_column} by {x_column}")
elif chart_type == "line":
plt.plot(df[x_column], df[y_column], marker='o')
plt.title(f"{y_column} vs {x_column}")
elif chart_type == "scatter":
plt.scatter(df[x_column], df[y_column])
plt.title(f"{y_column} vs {x_column} (Scatter)")
elif chart_type == "pie":
# 饼图需要正的值
if (df[y_column] < 0).any():
return {"error": "饼图不能包含负值"}
plt.pie(df[y_column], labels=df[x_column], autopct='%1.1f%%')
plt.title(f"Distribution of {y_column}")
else:
return {"error": f"不支持的图表类型: {chart_type}"}
plt.xlabel(x_column)
plt.ylabel(y_column)
plt.xticks(rotation=45)
plt.tight_layout()
# 将图表转换为Base64字符串
buffer = io.BytesIO()
plt.savefig(buffer, format='png')
buffer.seek(0)
image_base64 = base64.b64encode(buffer.read()).decode('utf-8')
plt.close()
return {
"success": True,
"chart_type": chart_type,
"x_column": x_column,
"y_column": y_column,
"row_count": len(df),
"chart_image": image_base64
}
except Exception as e:
logger.error(f"可视化数据失败: {str(e)}")
return {"error": str(e)}
@server.tool()
async def show_tables_info() -> Dict[str, Any]:
"""获取数据库中的所有表及其结构信息
Returns:
包含所有表及其结构的字典
"""
try:
logger.info("获取数据库表结构信息")
# 获取所有表
tables_result = await execute_query("SHOW TABLES")
if "error" in tables_result:
return tables_result
tables_info = []
for table_row in tables_result["results"]:
table_name = list(table_row.values())[0]
logger.info(f"获取表 {table_name} 的结构")
# 获取表结构
structure_result = await execute_query(f"DESCRIBE `{table_name}`")
if "error" not in structure_result:
structure = structure_result.get("results", [])
# 获取表行数
count_result = await execute_query(f"SELECT COUNT(*) as count FROM `{table_name}`")
row_count = 0
if "error" not in count_result and count_result.get("results"):
row_count = count_result["results"][0]["count"]
# 获取表前5条数据作为示例
sample_result = await execute_query(f"SELECT * FROM `{table_name}` LIMIT 5")
samples = []
if "error" not in sample_result:
samples = sample_result.get("results", [])
tables_info.append({
"name": table_name,
"row_count": row_count,
"structure": structure,
"sample_data": samples
})
return {
"success": True,
"database": DB_CONFIG["database"],
"tables_count": len(tables_info),
"tables": tables_info
}
except Exception as e:
logger.error(f"获取表结构信息失败: {str(e)}")
return {"error": str(e)}
@server.tool()
async def get_table_columns(table_name: str) -> Dict[str, Any]:
"""获取指定表的列信息
Args:
table_name: 表名
Returns:
表列信息
"""
try:
logger.info(f"获取表 {table_name} 的列信息")
# 检查表是否存在
tables_result = await execute_query("SHOW TABLES")
if "error" in tables_result:
return tables_result
table_exists = False
for table_row in tables_result["results"]:
if table_name == list(table_row.values())[0]:
table_exists = True
break
if not table_exists:
return {"error": f"表 '{table_name}' 不存在"}
# 获取表结构
structure_result = await execute_query(f"DESCRIBE `{table_name}`")
if "error" in structure_result:
return structure_result
columns = structure_result.get("results", [])
return {
"success": True,
"table": table_name,
"columns_count": len(columns),
"columns": columns
}
except Exception as e:
logger.error(f"获取表列信息失败: {str(e)}")
return {"error": str(e)}
# ======= 提示模板 =======
@server.prompt()
def sql_query_builder() -> str:
"""SQL查询构建器提示模板"""
return """
请帮我构建一个SQL查询来从数据库中检索信息。
数据库当前包含以下表:
{tables_info}
我需要一个查询来解决以下问题:
{problem_description}
请提供完整的SQL查询,并解释查询的每个部分。
"""
@server.prompt()
def data_analysis_report() -> str:
"""数据分析报告生成提示模板"""
return """
请基于以下数据生成一份详细的分析报告:
```
{data}
```
报告应包括:
1. 数据概述和主要指标
2. 关键趋势和模式分析
3. 异常值和特殊情况识别
4. 业务洞察和建议
请使用专业的语言和格式,使报告易于理解和实用。
"""
# ======= 资源 =======
@server.resource("mysql://schema/{table}")
async def get_table_schema(table: str) -> str:
"""获取表结构"""
try:
structure_result = await execute_query(f"DESCRIBE `{table}`")
if "error" in structure_result:
return f"Error: {structure_result['error']}"
structure = structure_result.get("results", [])
return json.dumps(structure, default=json_serialize, indent=2)
except Exception as e:
return f"Error: {str(e)}"
@server.resource("mysql://data/{table}")
async def get_table_data(table: str) -> str:
"""获取表数据"""
try:
data_result = await execute_query(f"SELECT * FROM `{table}` LIMIT 50")
if "error" in data_result:
return f"Error: {data_result['error']}"
data = data_result.get("results", [])
return json.dumps(data, default=json_serialize, indent=2)
except Exception as e:
return f"Error: {str(e)}"
@server.resource("mysql://info")
async def get_database_info() -> str:
"""获取数据库信息"""
try:
# 获取数据库版本
version_result = await execute_query("SELECT VERSION() as version")
if "error" in version_result:
return f"Error: {version_result['error']}"
version = version_result.get("results", [{}])[0].get("version", "Unknown")
# 获取数据库状态
status_result = await execute_query("SHOW STATUS")
if "error" in status_result:
status = []
else:
status = status_result.get("results", [])
# 获取所有表
tables_info = await get_tables()
if "error" in tables_info:
tables = []
else:
tables = tables_info.get("tables", [])
info = {
"database": DB_CONFIG["database"],
"version": version,
"host": DB_CONFIG["host"],
"tables": [table["name"] for table in tables],
"table_count": len(tables)
}
return json.dumps(info, default=json_serialize, indent=2)
except Exception as e:
return f"Error: {str(e)}"
# 启动服务器
if __name__ == "__main__":
logger.info("启动MySQL数据库MCP服务器...")
logger.info(f"数据库配置: {DB_CONFIG}")
logger.info("使用stdio传输方式")
try:
server.run(transport='stdio')
except Exception as e:
logger.error(f"服务器运行失败: {str(e)}")
sys.exit(1)
在Cursor中配置和使用
现在,我们将展示如何在Cursor中配置和使用这个MySQL数据库查询与可视化服务器。
配置mcp.json文件
在Cursor的配置目录中创建或编辑mcp.json文件:
{
"mcpServers": {
"mysql-server": {
"command": "python",
"args": [
"D:\\VS_WorkSpace\\mcp_class\\mysql_server.py"
],
"env": {
"DB_HOST": "localhost",
"DB_USER": "root",
"DB_PASSWORD": "123456",
"DB_NAME": "test"
}
}
}
}
在Cursor中使用

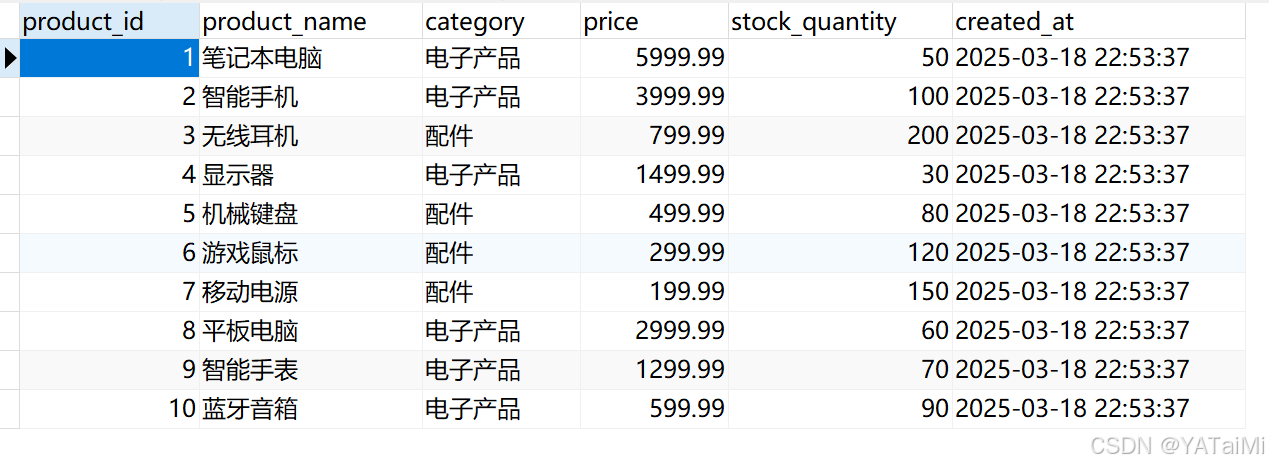
配置好后保存,如上篇文章所说的信号灯变成绿色,就可以通过自然语言提示与你的数据库交互了,这是我们的测试表:
1. "哪款产品价格最高"
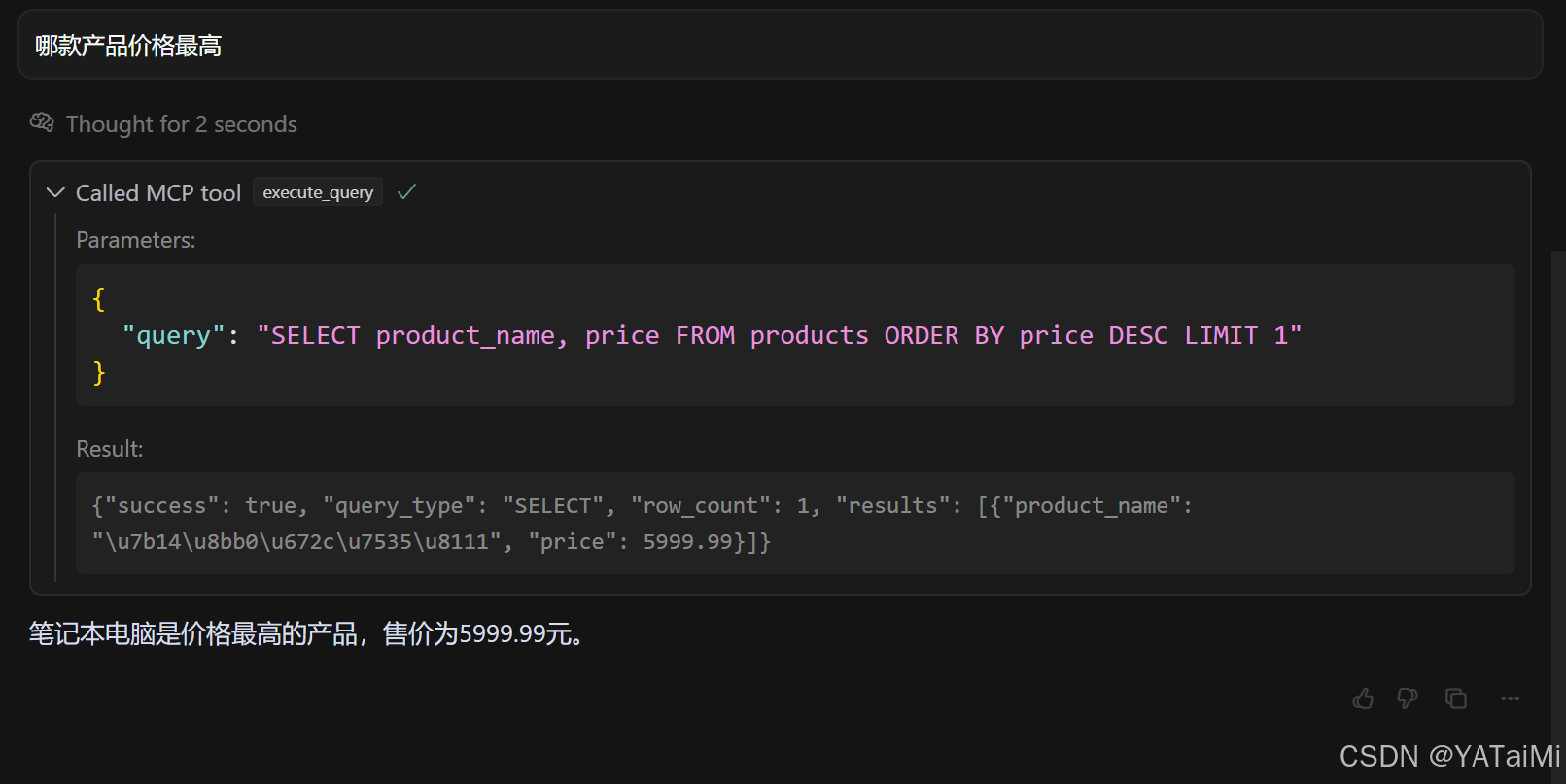
2. "帮我给产品的价格绘制一个柱状图"
返回的是base64编码,我们复制到一个工具网站上看一下:
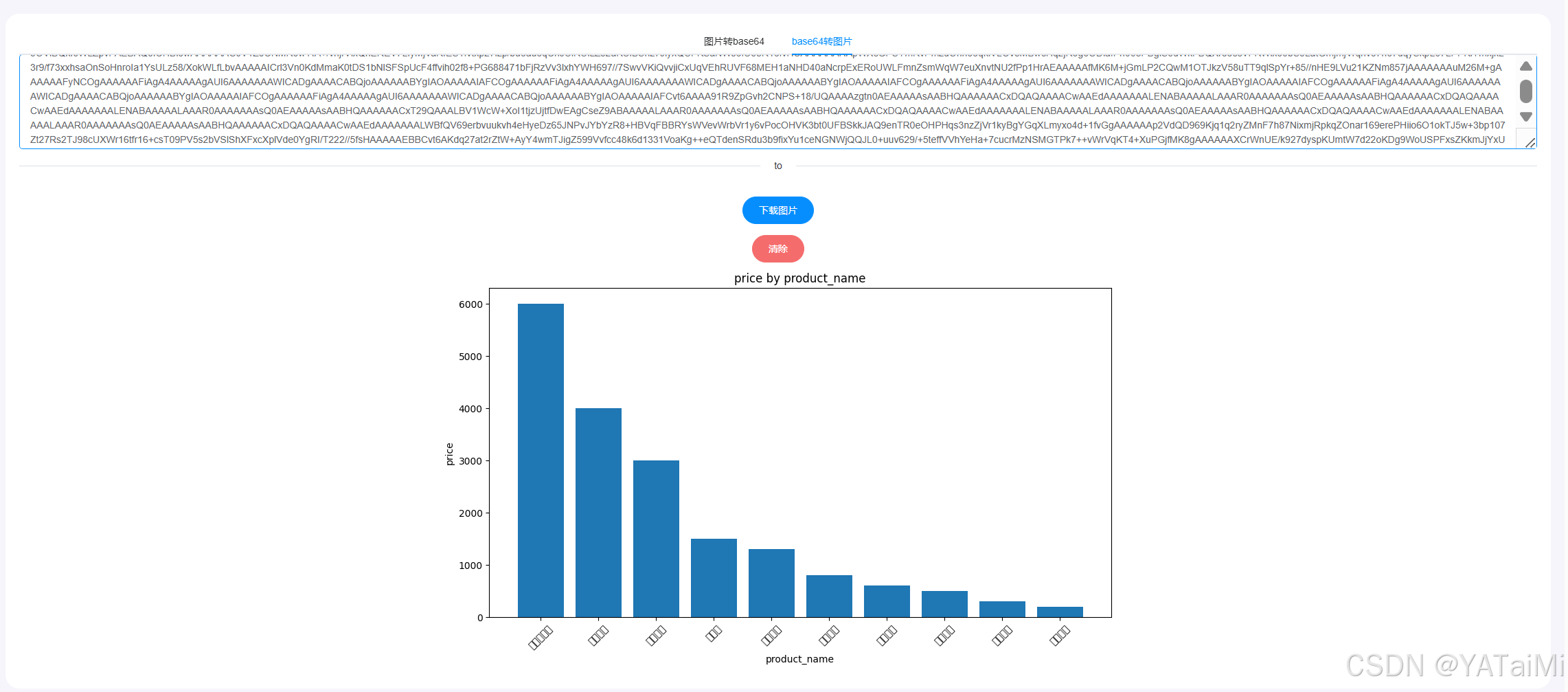
中文有点乱码,但问题不大。
小结
通过本教程,我们实现了:
-
创建一个简单的李明成绩查询MCP服务器
-
开发了一个基础的MCP客户端来连接和使用服务器
-
构建了一个实用的MySQL数据库查询与可视化服务器
-
学习了如何在Cursor中配置和使用这些服务器
这些例子展示了MCP的强大功能,特别是在数据查询和数据可视化方面。通过MCP,AI助手可以安全地访问和操作你的数据,为你提供更深入的分析和洞察。
下期预告
在下一篇文章中,我们将探讨如何使用Spring AI来开发MCP项目,特别面向那些使用Java作为主要开发语言的企业。我们将展示如何在Java生态系统中实现MCP服务器,以及如何将其集成到现有的企业应用中。
敬请期待!
如果你在实践过程中遇到任何问题,或者对MCP有任何疑问,欢迎在评论区留言,我会尽快回复!

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)