【AI RAG知识库】03.环境准备
掌柜智库项目(RAG)实战
(3)AI Agent RAG知识库-环境搭建
3. 环境准备
3.1 虚拟环境创建
3.1.1 安装uv
使用 uv 方式创建虚拟环境,如果之前用其他方式安装过 uv 则此处会自动识别出 uv 路径,如果没安装过 uv 直接点击 安装 uv via pip
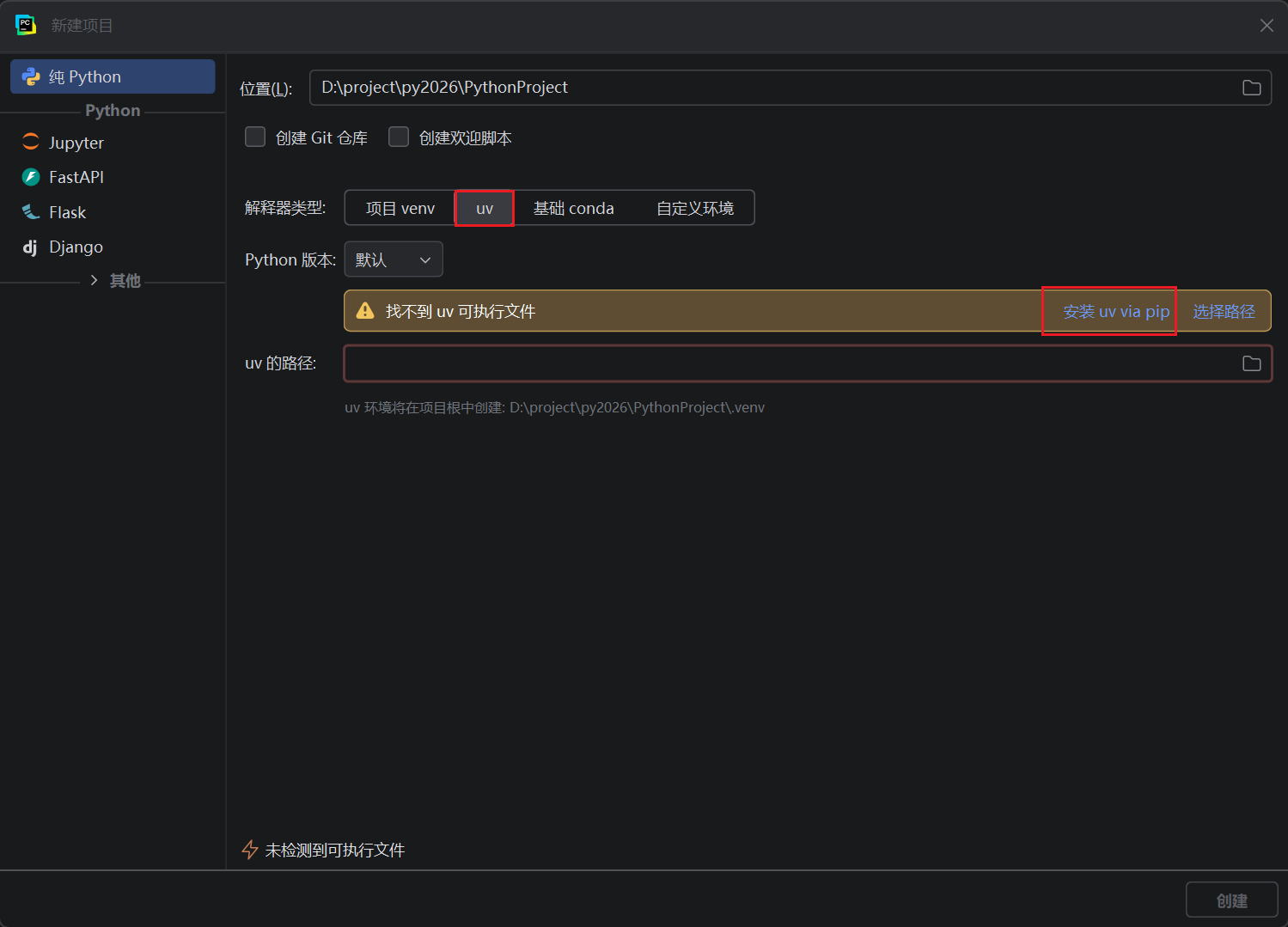
PyCharm版本没有 uv 选项,则选择 自定义环境,类型选 uv,然后再点击 安装 uv via pip
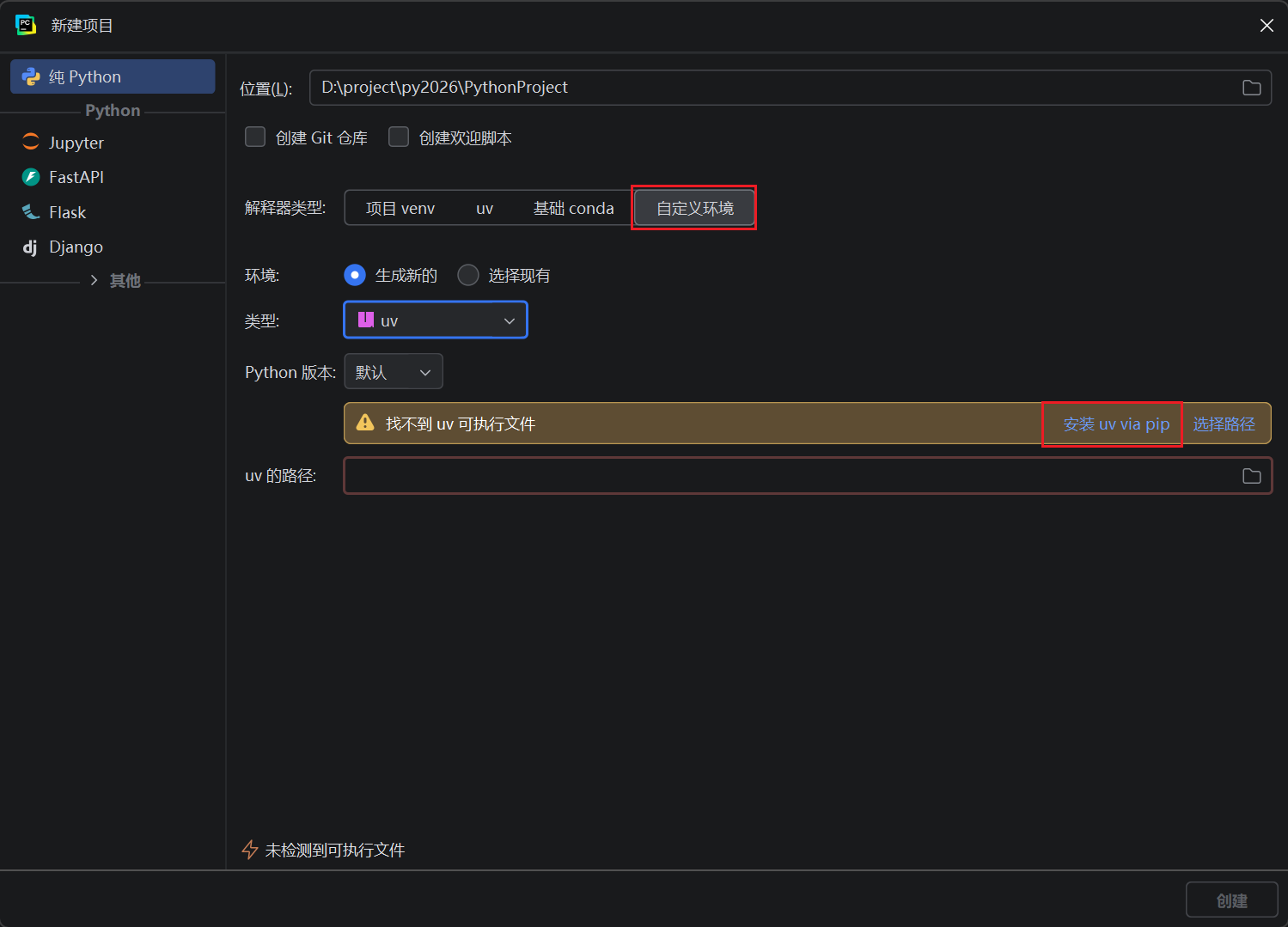
安装完uv 后将 uv 路径配置在系统的 Path 环境变量中:例如我的路径是 C:\Users\用户名\AppData\Roaming\Python\Scripts
3.1.2 配置镜像源
为uv命令配置国内镜像源。
以管理员身份运行Windows PowerShell
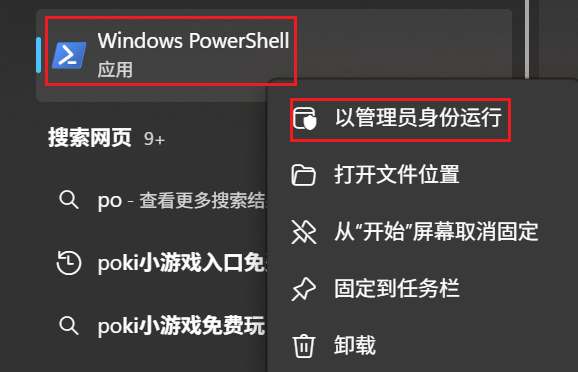
如果运行报如下错误:

则在 Windows PowerShell 中设置安全策略允许本地脚本执行,方式如下:
Set-ExecutionPolicy Unrestricted -Scope CurrentUser
然后执行以下命令创建uv配置文件
# 在用户目录创建文件夹
mkdir -Force $env:APPDATA\uv
# 在文件夹中创建文件
New-Item -Path $env:APPDATA\uv\uv.toml -ItemType File
编辑 uv.toml 文件,添加以下内容
# 清华镜像(推荐)
index-url = "https://pypi.tuna.tsinghua.edu.cn/simple"
# 阿里镜像
# index-url = "https://mirrors.aliyun.com/pypi/simple/"
# 可选:添加信任源(避免安装报错)
# trusted-host = ["pypi.tuna.tsinghua.edu.cn"]
3.1.3 安装指定版本的Python解释器
打开命令行终端,执行以下命令安装 python 3.11
# 列出已安装版本
uv python list
uv python install 3.11
回到 PyCharm 创建项目的页面,选择 Python版本为 3.11,定义项目名称为 knowledge_base 然后创建项目
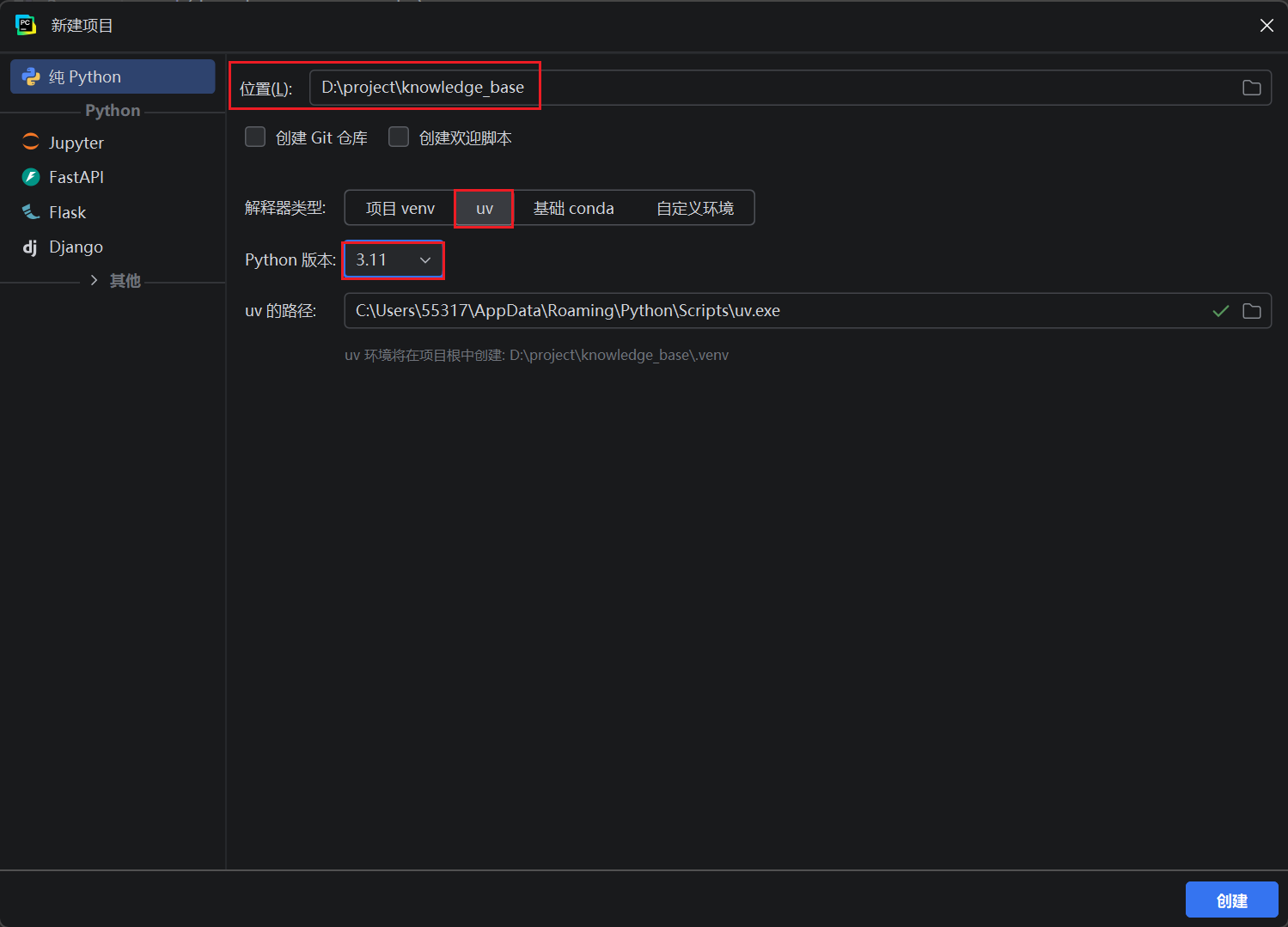
项目创建成功后,根目录下自动生成一个 pyproject.toml 文件。在 uv 虚拟环境中,pyproject.toml 是项目依赖和配置的核心文件,相当于项目的 “身份卡 + 依赖清单”,uv 会通过这个文件统一管理项目的 Python 版本、依赖包、构建规则等,是 uv 实现 “跨环境一致性” 的关键。
3.1.4 激活当前虚拟环境
打开 PyCharm的终端,当前虚拟环境会自动被激活
3.2 基础结构搭建
3.2.1 配置文件导入
3.2.1.1 在项目的跟目录中放入以下配置文件
资料
.env文件(不提交到Git,配置apikey).env.example文件(提交到Git,不要配置正确的 apikey)
3.2.1.2 测试环境变量的读取
安装依赖(环境变量加载器)
uv add python-dotenv
或
pip uv install python-dotenv
使用 uv add 或 uv pip install 都以可为当前虚拟环境安装依赖。区别如下
- 使用
uv add安装的依赖会自动添加到pyproject.toml中,但是不能在命令中直接使用--index-url参数指定镜像源,只能通过前面的uv.toml文件指定 - 使用
uv pip install则不会将依赖添加到pyproject.toml中,但是可以在命令中直接使用--index-url参数指定镜像源
测试环境变量的读取
# test/01-env和系统环境变量的优先级.py
import os
from dotenv import load_dotenv
# 加载.env文件
load_dotenv(override=True)
print(os.getenv("OPENAI_API_KEY"))
# 实际默认逻辑:override=False
# - 如果系统环境变量不存在 → 用.env里的值
# - 如果系统环境变量已存在 → 系统变量优先级更高
# 想让.env覆盖系统变量,需显式传 override=True
# load_dotenv(override=True)
# 示例:假设系统有环境变量 MY_KEY=system_val,.env里 MY_KEY=dotenv_val
print(os.getenv("MY_KEY"))
# load_dotenv() → 输出 system_val(系统优先级高)
# load_dotenv(override=True) → 输出 dotenv_val(.env覆盖系统)
3.2.2 统一日志
3.2.2.1 安装依赖
loguru 是 Python 中一款开箱即用、功能强大且极简的日志工具,核心作用是替代 Python 标准库的 logging 模块,解决原生日志配置繁琐、用法不友好的问题。我用新手能看懂的方式讲清楚它的核心作用和优势:
uv add loguru
或
pip uv install loguru
3.2.2.2 日志模块代码
资料
app/core/logger.py
3.2.2.3 测试日志记录
"""
项目日志工具类
基于loguru实现,支持.env配置控制台/文件双输出,自动生成logs/app_年月日.log
特性:
1. 配置驱动:通过.env开关输出、修改日志级别
2. 自动路径:文件日志默认输出到 项目根/logs/app_YYYYMMDD.log
3. 自动清理:按配置保留日志,自动删除过期文件
4. 中文友好:utf-8编码,彻底解决中文乱码
5. 异步安全:开启异步入队,支持多线程/异步场景,避免日志错乱
6. 开箱即用:项目所有模块直接导入logger即可使用
7. 位置终极精准:穿透loguru内部+工具类自身,完美显示业务模块实际调用位置
"""
import sys
import inspect
from pathlib import Path
import os
from dotenv import load_dotenv
from loguru import logger
# -------------------------- 第一步:加载.env配置文件 --------------------------
load_dotenv()
# -------------------------- 第二步:读取.env配置(带默认值,防止配置缺失) --------------------------
LOG_CONSOLE_ENABLE = os.getenv("LOG_CONSOLE_ENABLE", "True").lower() == "true"
LOG_CONSOLE_LEVEL = os.getenv("LOG_CONSOLE_LEVEL", "INFO").upper()
LOG_FILE_ENABLE = os.getenv("LOG_FILE_ENABLE", "True").lower() == "true"
LOG_FILE_LEVEL = os.getenv("LOG_FILE_LEVEL", "INFO").upper()
LOG_FILE_RETENTION = os.getenv("LOG_FILE_RETENTION", "7 days")
# -------------------------- 第三步:定义日志路径(自动推导项目根) --------------------------
PROJECT_ROOT = Path(__file__).resolve().parent.parent.parent
LOG_DIR = PROJECT_ROOT / "logs"
LOG_FILE_NAME = "app_{time:YYYYMMDD}.log"
LOG_FILE_PATH = LOG_DIR / LOG_FILE_NAME
# -------------------------- 第四步:定义日志格式(彩色、结构化、易读) --------------------------
LOG_FORMAT = (
"<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> | "
"<level>{level: <8}</level> | "
"<cyan>{name: <20}</cyan>:<cyan>{function: <15}</cyan>:<cyan>{line: <4}</cyan> - "
"<level>{message}</level>"
)
# -------------------------- 第五步:初始化日志配置(核心方法) --------------------------
def init_logger():
"""
初始化全局日志配置
1. 移除loguru默认控制台输出(避免重复打印)
2. 根据.env配置开启/关闭控制台输出
3. 根据.env配置开启/关闭文件输出(自动创建logs文件夹)
4. 配置日志格式、级别、分割、保留策略
:return: 配置完成的loguru logger实例
"""
# 1. 移除loguru默认的控制台输出
logger.remove()
# 2. 配置控制台输出(若.env开启)
if LOG_CONSOLE_ENABLE:
logger.add(
sink=sys.stdout,
level=LOG_CONSOLE_LEVEL,
format=LOG_FORMAT,
colorize=True,
enqueue=True
)
# 3. 配置文件输出(若.env开启)
if LOG_FILE_ENABLE:
LOG_DIR.mkdir(parents=True, exist_ok=True)
logger.add(
sink=LOG_FILE_PATH,
level=LOG_FILE_LEVEL,
format=LOG_FORMAT,
rotation="00:00",
retention=LOG_FILE_RETENTION,
encoding="utf-8",
enqueue=True,
backtrace=True,
diagnose=True
)
return logger
# -------------------------- 第六步:初始化并终极修正全局logger --------------------------
base_logger = init_logger()
def fix_log_position(record):
"""遍历调用栈,跳过loguru内部帧+工具类自身帧,提取业务代码实际调用位置"""
for frame in inspect.stack():
# 终极过滤:排除loguru内部 + 排除工具类logger.py自身,直接定位业务模块
if ("_logger.py" in frame.filename or frame.function == "_log") or "logger.py" in frame.filename:
continue
# 更新日志字段为业务代码实际位置
record.update(
name=frame.filename.split("/")[-1].split("\\")[-1],
function=frame.function,
line=frame.lineno
)
break
# 应用终极修复,导出全局可用的logger
logger = base_logger.patch(fix_log_position)
# -------------------------- 测试代码(验证修复效果) --------------------------
if __name__ == '__main__':
logger.info("【测试】logger.py内部调用(仅测试,业务模块调用会显示正确文件名)")
print(f"日志文件输出路径:{LOG_FILE_PATH}")
修改.env文件中的日志配置进行测试,例如 LEVEL、ENABLE
# ===================== 日志配置 =====================
# 控制台日志:True=开启/False=关闭,级别可选(DEBUG/INFO/WARNING/ERROR/CRITICAL)
LOG_CONSOLE_ENABLE=True
LOG_CONSOLE_LEVEL=INFO
# 文件日志:True=开启/False=关闭,级别与控制台可独立设置
LOG_FILE_ENABLE=True
LOG_FILE_LEVEL=INFO
# 日志文件保留天数(自动删除过期日志,避免磁盘占满)
LOG_FILE_RETENTION=7 days
3.2.4 准备提示词和导入工具
资料
promptsapp/core/load_prompt.py
3.2.5 导入utils和tools
资料
app/toolapp/utils
3.2.6 大模型&客户端
资料
app/clientsapp/conf`` ``app/lm
3.2.6 PDF文件
资料
设备手册放入项目根目录doc文件夹
3.3 安装torch
**torch:**PyTorch 深度学习框架,为向量模型(BGE-M3)提供运行环境,支撑模型的加载、推理、张量计算,是大部分深度学习模型的基础依赖。
安装哪个版本:
- cu124 源
| 显卡架构 | 算力版本 | 显卡系列 | 具体型号 |
|---|---|---|---|
| Blackwell | sm_100 | RTX 50 系列 | RTX 5090、5080、5070、5060、5050、5060 Ti、5070 Ti、5080 Ti、5090 Ti |
| Ada Lovelace | sm_89 | RTX 40 系列 | RTX 4090、4080、4070、4070 Ti、4060、4060 Ti、4050、RTX 4000 SFF、RTX 5000、RTX 6000 |
| Ampere | sm_86 | RTX 30 系列 | RTX 3090 Ti、3090、3080 Ti、3080、3070 Ti、3070、3060 Ti、3060、3050、RTX A2000、A3000、A4000、A5000、A6000 |
| Turing | sm_75 | RTX 20 系列 | RTX 2080 Ti、2080 Super、2080、2070 Super、2070、2060 Super、2060、Titan RTX、RTX 5000、6000、8000 |
| Turing | sm_75 | GTX 16 系列 | GTX 1660 Ti、1660 Super、1660、1650 Super、1650 |
| Pascal | sm_61 | GTX 10 系列 | GTX 1080 Ti、1080、1070 Ti、1070、1060、1050 Ti、1050、Titan Xp、Titan X |
| Maxwell | sm_52 | GTX 9 系列 | GTX 980 Ti、980、970、960、950、Titan X |
- 给 PyTorch 装上 “GPU 加速器”,只有你的电脑 / 服务器有 NVIDIA GPU,且装了对应驱动,才能用上这个加速器;如果没有 GPU,装了也没用(PyTorch 会自动降级到 CPU 运行)。
- `cu124` 对应 CUDA 12.4,你的 NVIDIA 驱动版本需≥`545.23`(可通过 `nvidia-smi` 查看驱动版本);
- 如果驱动版本低(比如只支持 CUDA 12.1),需换 `cu121` 源(`https://download.pytorch.org/whl/cu121`),否则会报错。
- cpu 源
- PyTorch 的 “基础版”,不管有没有 GPU,都只能用 CPU 干活,优点是体积小、不挑环境,缺点是速度慢。
下载PyTorch:
正常情况下使用 uv add 就可以安装依赖,但是对于PyTorch来说最好去官网下载和计算机对应的版本,因为国内普通镜像源大概率是CPU-only 版本,可能没有适配最新 CUDA 的版本。
# uv add torch # PyTorch核心库:张量计算+GPU/TPU加速+深度学习模型构建
# 包含 CUDA 12.8 加速模块,支持 NVIDIA GPU 运算
uv pip install --force-reinstall torch --index-url https://download.pytorch.org/whl/cu124
# 使用 CPU
uv add torch torchvision torchaudio
验证 PyTorch 是否正常加载:
# test/03-cuda测试.py
try:
import torch
print(f"✅ PyTorch 加载成功!版本:{torch.__version__}")
print(f"✅ CUDA 状态:{torch.cuda.is_available()}(CPU版显示False正常)")
print(f"✅ CUDA 设备数:{torch.cuda.device_count()}")
print(f"✅ CUDA 设备名称:{torch.cuda.get_device_name(0)}")
except Exception as e:
print(f"❌ PyTorch 加载失败:{e}")
3.4 其他相关依赖
- langgraph:LangChain 生态的工作流框架,用于搭建大模型应用的任务流程编排(如定义多步骤任务的执行顺序、分支逻辑、状态管理),适配复杂的知识图谱 / 文档处理流程。
- langchain:大模型应用开发核心框架,封装了大模型调用、提示词管理、工具链整合、数据处理等通用能力,是连接业务代码与大模型的核心中间层。
- langchain_openai:LangChain 对 OpenAI 系列模型的专属封装,兼容 OpenAI / 国产大模型(千问 / 即梦 AI 等)的 OpenAI 风格 API,简化大模型客户端初始化与调用。
- pymilvus:Milvus 向量数据库的 Python 客户端,用于向量的增删改查、数据库连接与操作,是大模型应用中存储嵌入向量(Embedding)的核心依赖。
- minio:MinIO 对象存储的 Python SDK,实现文件(图片 / PDF / 文档)的上传、下载、删除、桶管理,适配分布式文件存储场景。
- numpy:Python 数值计算基础库,提供高性能数组操作,支撑向量计算、数据预处理等数值相关逻辑。
- pandas:高效数据处理库,以 DataFrame 结构处理结构化数据(如解析后的 PDF 文本、任务日志),支持数据筛选、清洗、转换。
- regex:增强版正则表达式库,兼容 Python 原生 re 库,支持更复杂的正则匹配(如 Markdown 图片引用、PDF 文本提取后的内容匹配)。
- magic-pdf:基于大模型的智能 PDF 解析库(MinerU 是其核心内核),解决传统 PDF 解析的格式错乱、图片 / 表格提取失败、公式识别差等问题,能精准提取 PDF 中的文本、图片、表格、公式,保留原文档排版结构,同时支持将解析结果输出为 Markdown/HTML 等易处理格式,是大模型应用中 PDF 文档预处理的核心工具。
- FlagEmbedding:智源研究院开源的嵌入模型(Embedding)工具库,封装了 BGE-M3 等优秀的向量模型,一键实现文本 / 图片的向量化转换(将自然语言转为计算机可识别的向量),适配检索增强生成(RAG)场景的向量检索需求。
#uv add python-dotenv
#uv add loguru
#uv pip install --force-reinstall torch --index-url https://download.pytorch.org/whl/cu128
uv add numpy
uv add langgraph
uv add grandalf
uv add fastapi
uv add minio
#前面安装langgraph时已经关联安装的依赖
#uv add requests
#uv add pydantic
# LangChain & LangGraph
uv add langchain
uv add langchain_openai
uv add langchain_community
# Web Framework
uv add uvicorn
uv add python-multipart
# Database & Storage
#PyMilvus 团队在 2.4.0 版本后做了明确的包职责拆分,避免主包依赖冗余:
#pymilvus(主包):仅包含 Milvus 向量数据库的核心操作(连接、增删改查、索引创建等);
#pymilvus-model(独立包):专门包含嵌入函数、模型封装、混合检索等功能(如BGEM3EmbeddingFunction、各类向量编码器均在此包中)。
uv add pymilvus
uv add pymilvus-model
uv add pymongo
# AI & Models
uv add pandas
uv add modelscope
uv add FlagEmbedding
uv add magic-pdf
uv add regex
----------------------

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)