43.llama_index-使用(在线模型调用、本地调用、厂商sdk调用)
内容参考于:图灵AI大模型全栈
安装llama_index
pip install llama-index
安装完后,如下图红框它默认带大语言模型(llms)和向量模型(embeddings)的openAI,还有它的代码(core)
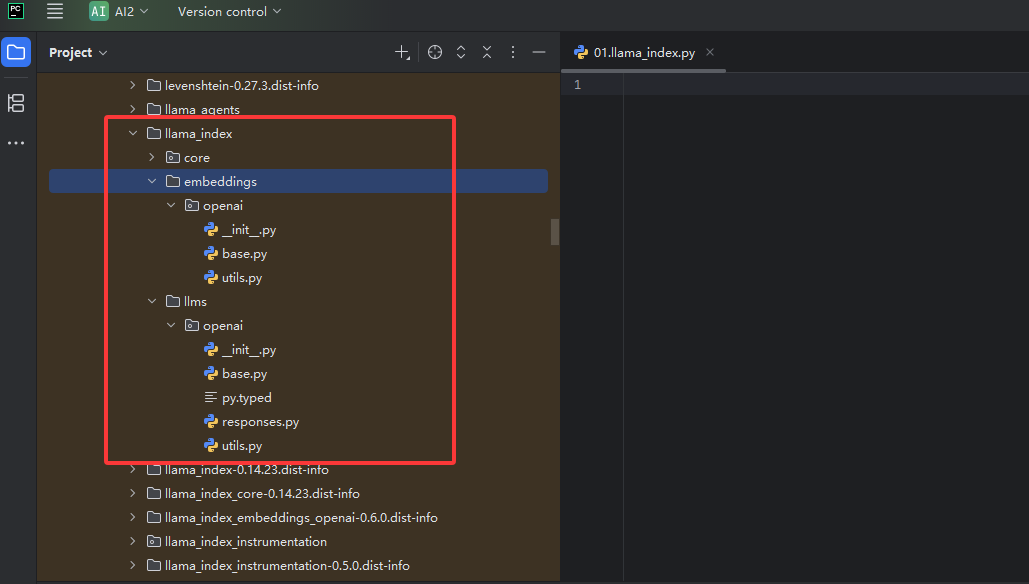
LLamaIndex模型的调用
效果图:
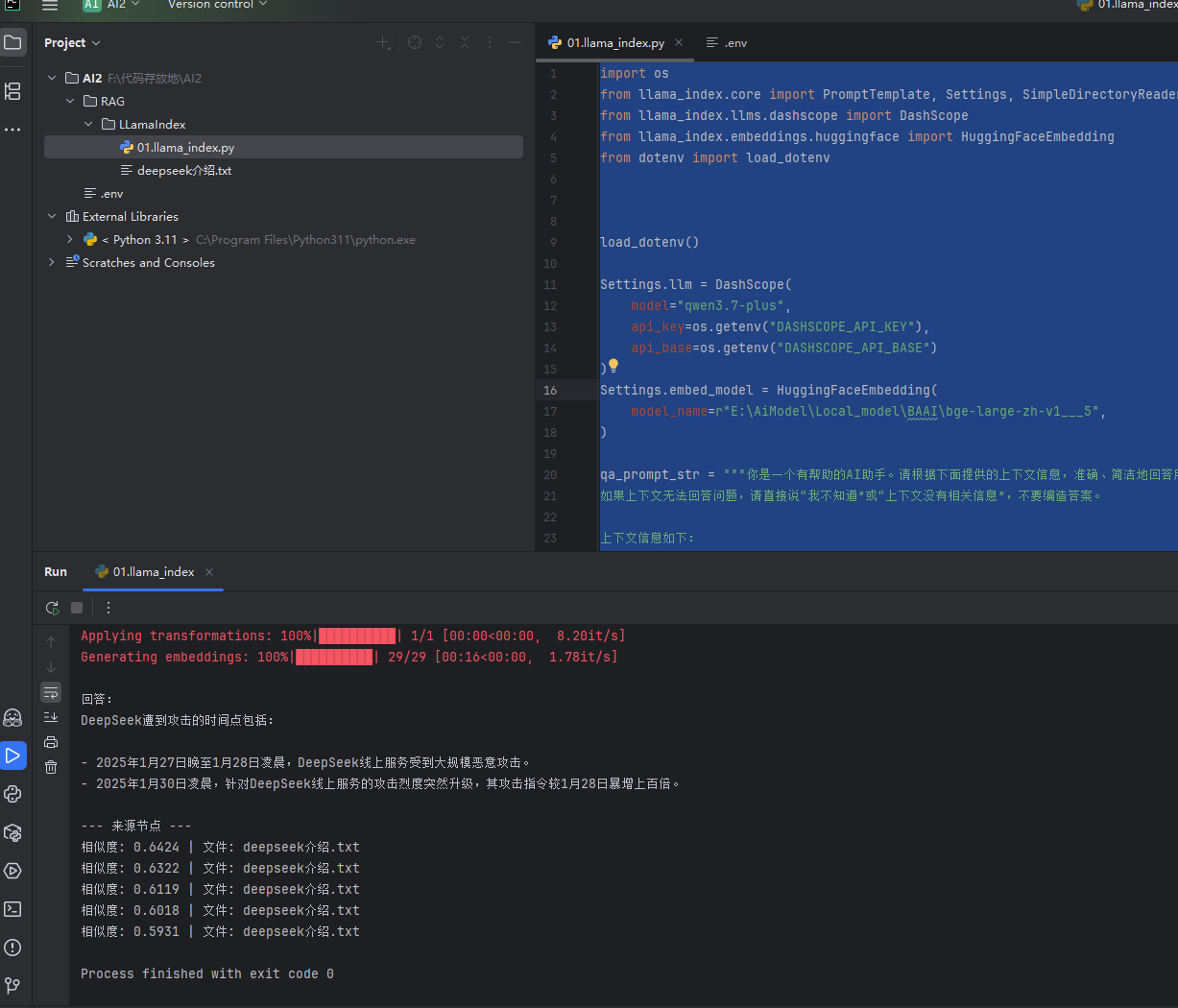
调用下方的代码需要安装
# 代码运行之前需要安装下方的两个库 # pip install llama-index-embeddings-huggingface # 使用本地的embedding模型 # pip install llama-index-llms-dashscope # 千问模型 import os from llama_index.core import PromptTemplate, Settings, SimpleDirectoryReader, VectorStoreIndex from llama_index.llms.dashscope import DashScope from llama_index.embeddings.huggingface import HuggingFaceEmbedding from dotenv import load_dotenv load_dotenv() Settings.llm = DashScope( model="qwen3.7-plus", api_key=os.getenv("DASHSCOPE_API_KEY"), api_base=os.getenv("DASHSCOPE_API_BASE") ) Settings.embed_model = HuggingFaceEmbedding( model_name=r"E:\AiModel\Local_model\BAAI\bge-large-zh-v1___5", ) qa_prompt_str = """你是一个有帮助的AI助手。请根据下面提供的上下文信息,准确、简洁地回答用户的问题。 如果上下文无法回答问题,请直接说“我不知道”或“上下文没有相关信息”,不要编造答案。 上下文信息如下: {context_str} 用户问题:{query_str} 请用中文回答: """ qa_prompt = PromptTemplate(qa_prompt_str) documents = SimpleDirectoryReader( input_files=['./deepseek介绍.txt'] # 可选:限制文件类型 ).load_data() print(f"加载了 {len(documents)} 个文档") # 构建向量索引(会自动 chunk + embedding) index = VectorStoreIndex.from_documents( documents, show_progress=True ) # 创建 Query Engine,并使用自定义提示词 query_engine = index.as_query_engine( similarity_top_k=5, # 检索前 5 个最相关片段 text_qa_template=qa_prompt, # 使用自定义提示词 streaming=False # 如果想流式输出可设为 True ) question = 'deepseek什么时候遭到攻击?' response = query_engine.query(question) print("\n回答:") print(response.response) # 如果想看检索到的上下文来源: print("\n--- 来源节点 ---") for node in response.source_nodes: print(f"相似度: {node.score:.4f} | 文件: {node.metadata.get('file_name')}")
LLamaIndex默认调用
from llama_index.llms.openai import OpenAI from dotenv import load_dotenv import os # 从 .env 文件加载环境变量(避免密钥硬编码到代码中) load_dotenv() # 实例化 LLM,配置核心参数 llm = OpenAI( model="gpt-4o-mini", api_key=os.getenv("OPENAI_API_KEY"), # 读取环境变量中的密钥 api_base="https://api.openai.com/v1", # 支持OpenAI的模型地址 temperature=0.7, # 生成随机性:0 更确定,1 更发散 max_tokens=1024, # 单次回复最大 token 数 timeout=60, # 请求超时时间(秒) ) if __name__ == "__main__": prompt = "请用一句话解释什么是大语言模型" # 调用补全接口 response = llm.complete(prompt) # 通过 .text 获取纯文本结果(直接打印 response 会输出对象信息) print("提问:", prompt) print("回答:", response.text)
其它模型调用
调用其它的都在openai的like里,这个需要安装,LLamaIndex它不自带,需要作为插件的方式安装OpenAI-Like,安装指令如下,它兼容所有模型,它虽然兼容所有模型,但是它没办法精细化,就是说有些模型提供了一些参数,它就没办法搞
pip install llama-index-llms-openai-like效果图:
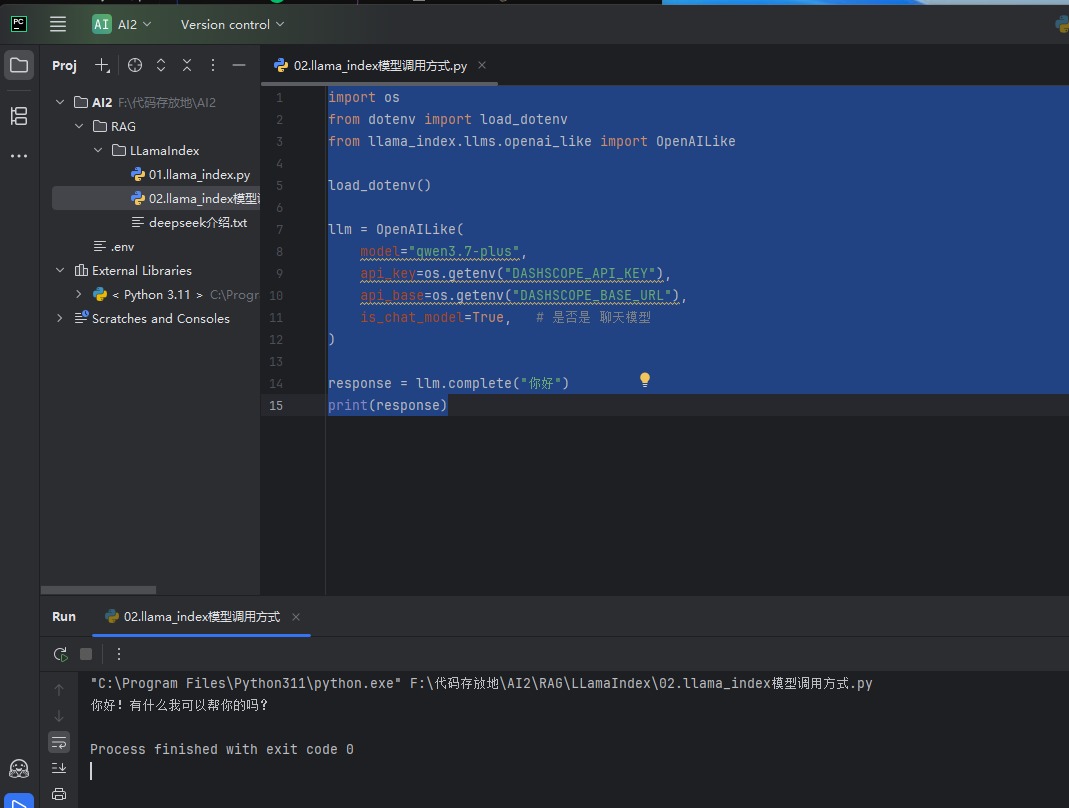
代码:
# 导入操作系统交互模块,用来读取系统环境变量(后面从环境变量里取API密钥和接口地址) import os # 导入 dotenv 库的环境变量加载函数,作用是读取 .env 文件里的配置,写入到系统环境变量中 # 好处:敏感的密钥、地址不写死在代码里,更安全,换环境只需要改 .env 文件 from dotenv import load_dotenv # 从 llama_index 框架中导入 OpenAILike 大模型类 # 作用:这是 LlamaIndex 专门用来接入「兼容 OpenAI 接口协议」的第三方大模型的工具类 # 通义千问、DeepSeek、智谱等支持 OpenAI 格式接口的模型,都可以用这个类来对接,不用单独写适配代码 from llama_index.llms.openai_like import OpenAILike # 执行加载 .env 文件 # 执行完这行之后,.env 里的 DASHSCOPE_API_KEY、DASHSCOPE_BASE_URL 就会被读到系统环境变量里 # 后面 os.getenv() 才能取到对应的值 load_dotenv() # 初始化大模型实例 llm,后面所有调用大模型的操作都通过这个对象来完成 llm = OpenAILike( # 指定要使用的模型名称,这里是通义千问 3.7-plus 版本 model="qwen3.7-plus", # 从环境变量中读取 API 密钥,对应 .env 文件里的 DASHSCOPE_API_KEY 配置项 api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量中读取接口基础地址,对应 .env 文件里的 DASHSCOPE_BASE_URL 配置项 # 因为是第三方模型,不是官方 OpenAI,必须指定自己的接口地址 api_base=os.getenv("DASHSCOPE_BASE_URL"), # 标记当前模型是聊天模型(对话式模型) # 作用:告诉 LlamaIndex 这个模型支持多轮对话格式,内部会按聊天接口的格式去请求 # 如果是纯补全模型就设为 False,现在主流大模型基本都是聊天模型 is_chat_model=True, # 是否是 聊天模型 ) # 调用大模型的 complete 方法,发送一句内容,获取模型的补全回复 # complete 是基础的单轮补全接口,输入一段文本,模型返回续写/回复的内容 response = llm.complete("你好") # 打印模型返回的结果 # 返回的 response 是 LlamaIndex 封装的响应对象,直接打印会输出回复的文本内容 print(response)
调用本地模型
如下图本地使用Ollama运行了一个deepseek-r1:32b模型
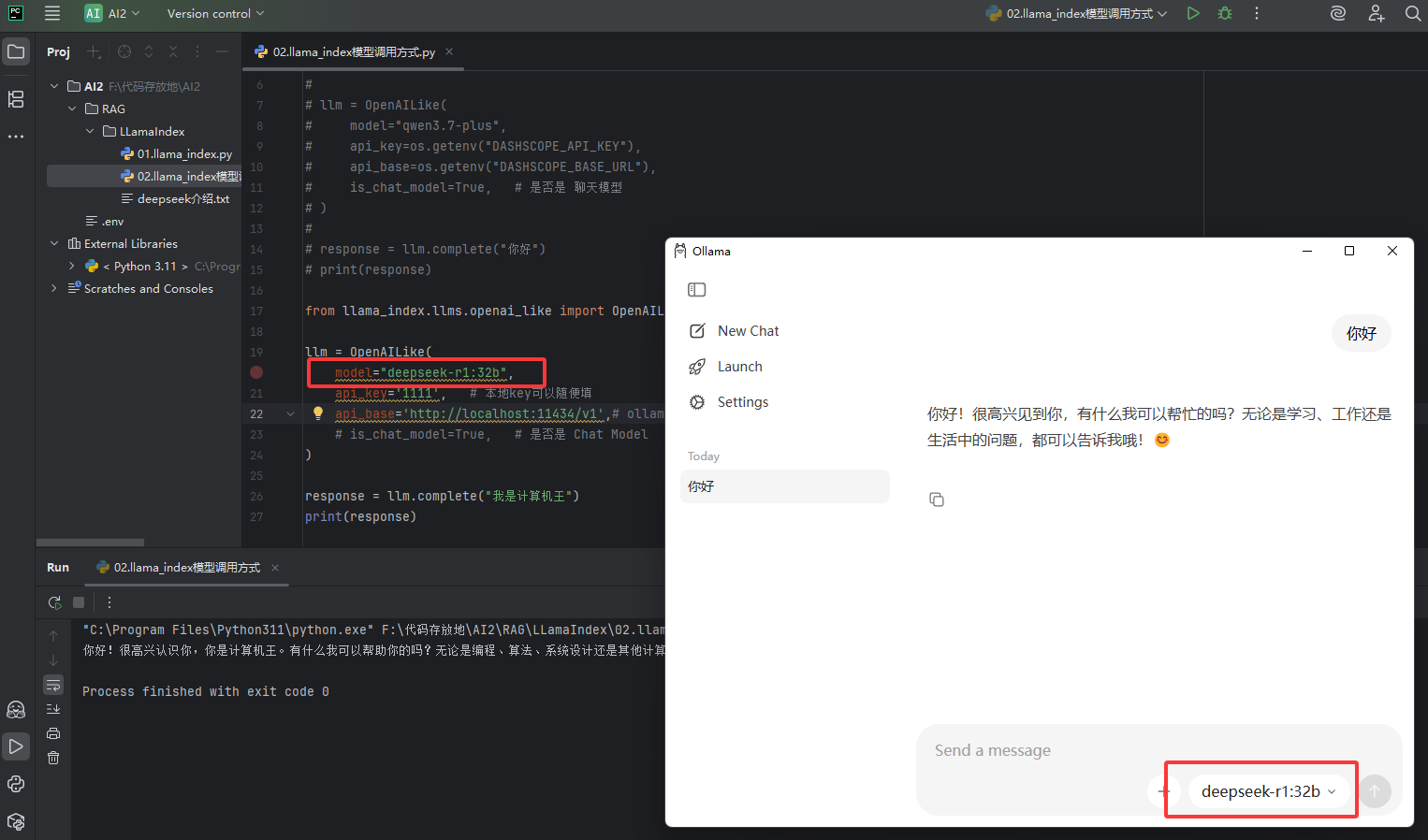
效果图:
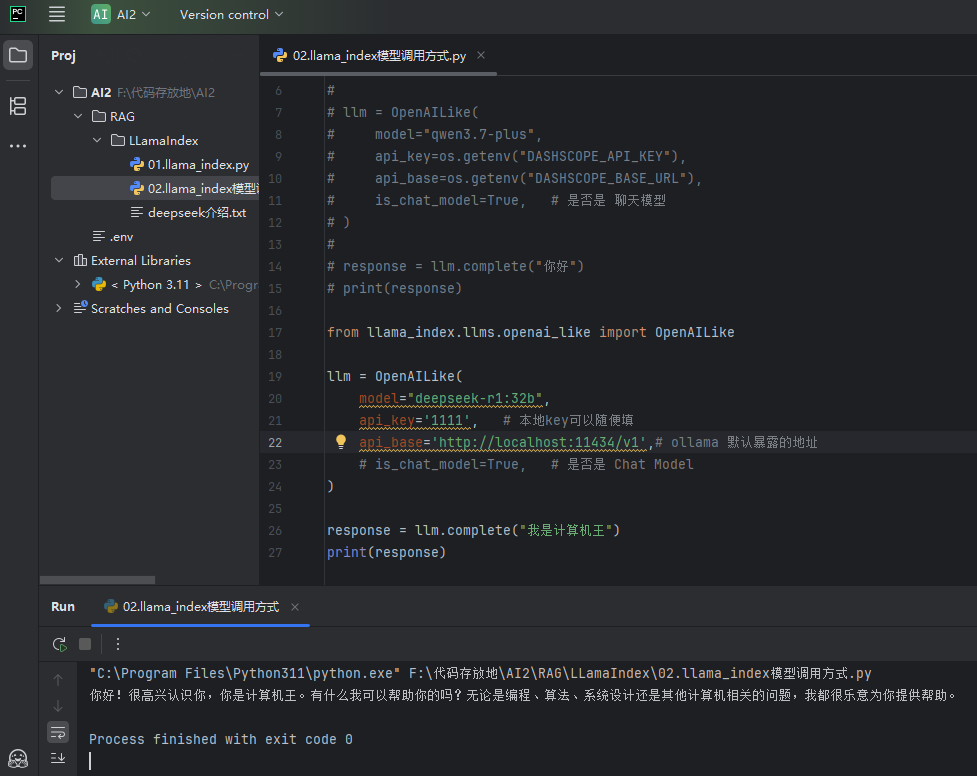
代码
# 从 llama_index 框架中导入 OpenAILike 大模型适配类 # 作用:专门用来对接「兼容 OpenAI 接口协议」的大模型服务 # Ollama 本地启动后,默认暴露的接口完全兼容 OpenAI 格式,所以可以直接用这个类对接,不用单独写适配代码 from llama_index.llms.openai_like import OpenAILike # 创建大模型实例,对接本地 Ollama 运行的开源大模型 llm = OpenAILike( # 指定要调用的模型名称,必须和你本地 Ollama 里拉取运行的模型名完全一致 # 这里是 deepseek-r1 的 32b 参数版本,需要提前执行 ollama pull deepseek-r1:32b 拉取到本地才能用 model="deepseek-r1:32b", # API 密钥参数:本地 Ollama 服务默认不需要身份认证 # 但 OpenAI 协议要求这个字段必填,所以本地用随便填一个字符串就行,不会校验真假 api_key='1111', # 本地key可以随便填 # 接口基础地址:Ollama 启动后默认在本地 11434 端口提供服务 # 末尾的 /v1 是兼容 OpenAI 协议的固定路径,和 Ollama 的接口规则对应 api_base='http://localhost:11434/v1',# ollama 默认暴露的地址 # 标记当前模型是否为对话聊天模型,这里被注释掉了,会使用框架的默认值 # 补充说明:deepseek-r1 是对话型模型,打开这个参数后,框架会用聊天消息格式去请求,对话效果更符合预期 # is_chat_model=True, # 是否是 Chat Model ) # 调用大模型的 complete 补全接口,传入输入文本,获取模型的回复 # complete 是单轮补全接口:输入一段文本,模型直接返回对应的生成内容 response = llm.complete("我是计算机王") # 打印模型返回的响应结果 # response 是 LlamaIndex 封装的响应对象,直接打印会输出模型生成的纯文本内容 print(response)
精细化的调用
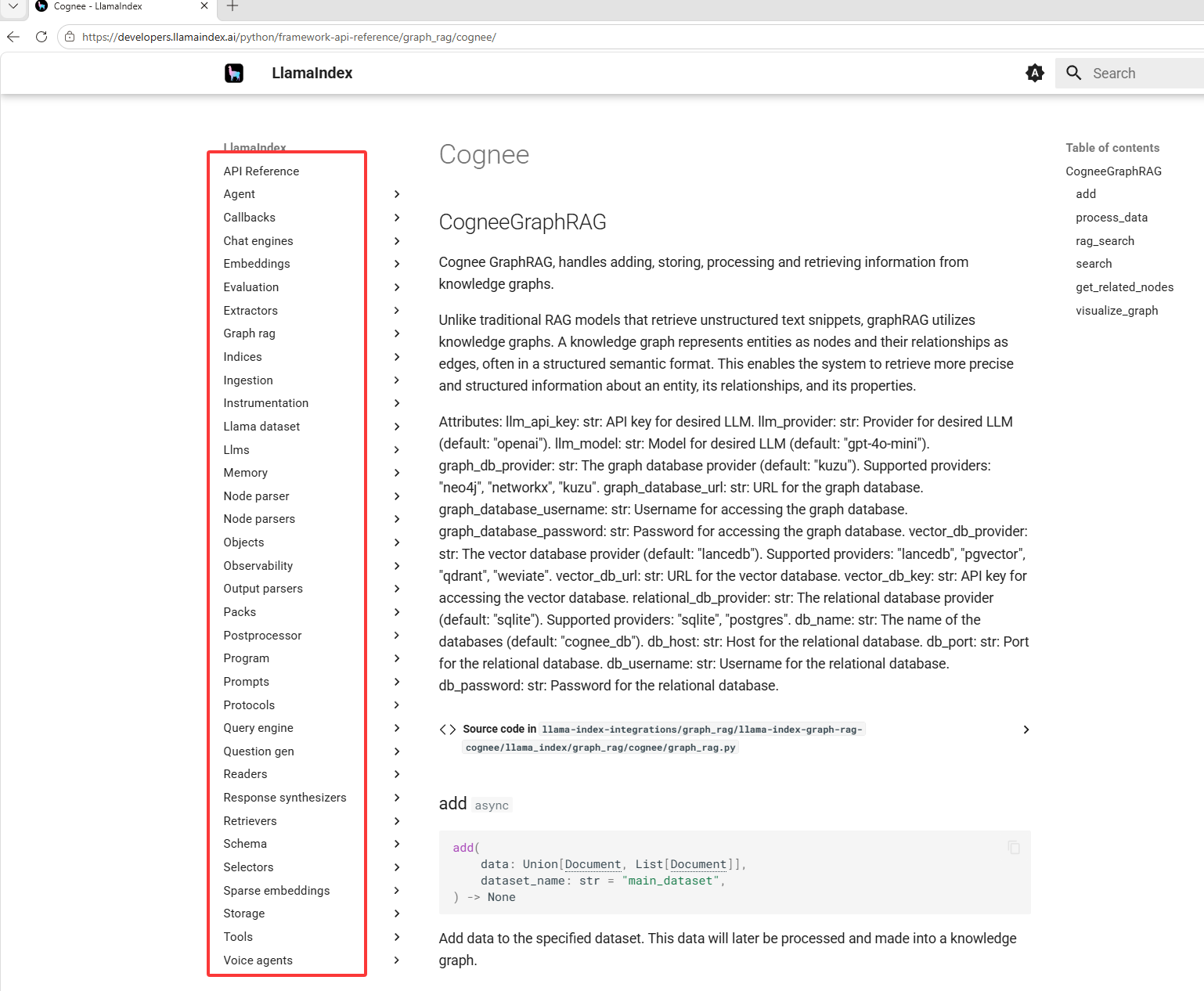
LLamaIndex对每个模型厂商提供了sdk,精细化的调用要每个厂商自己实现
进入地址后下图红框位置是针对模型划分的分类,如果看不懂英文可以翻译成中文
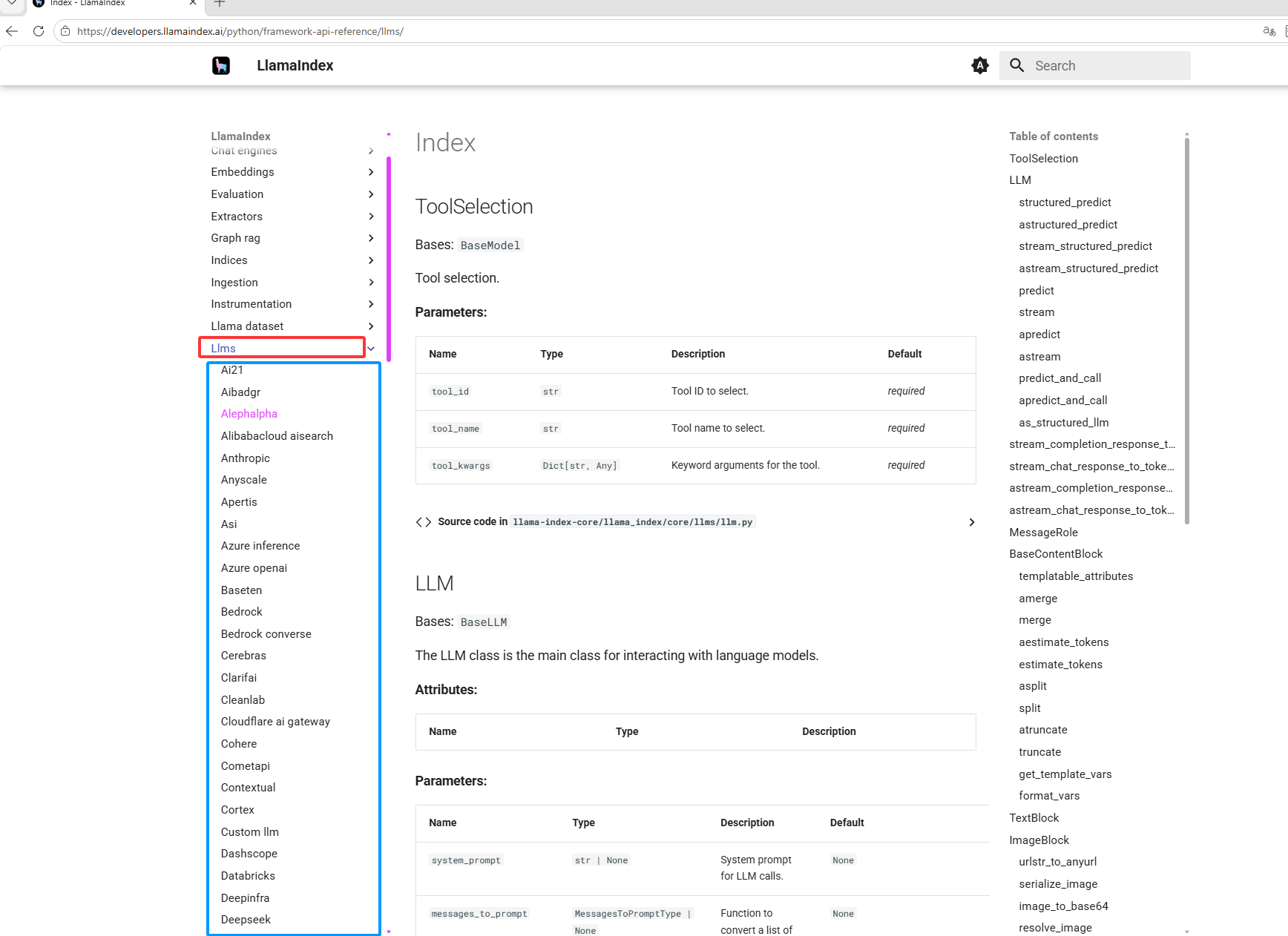
点击下图红框打开分类(llms大模型),就可以看到每个厂商提供的库了如下图蓝框,如果下图蓝框不知道谁是谁,那就截个图给ai,让ai告诉你
如下图红框,千问的模型
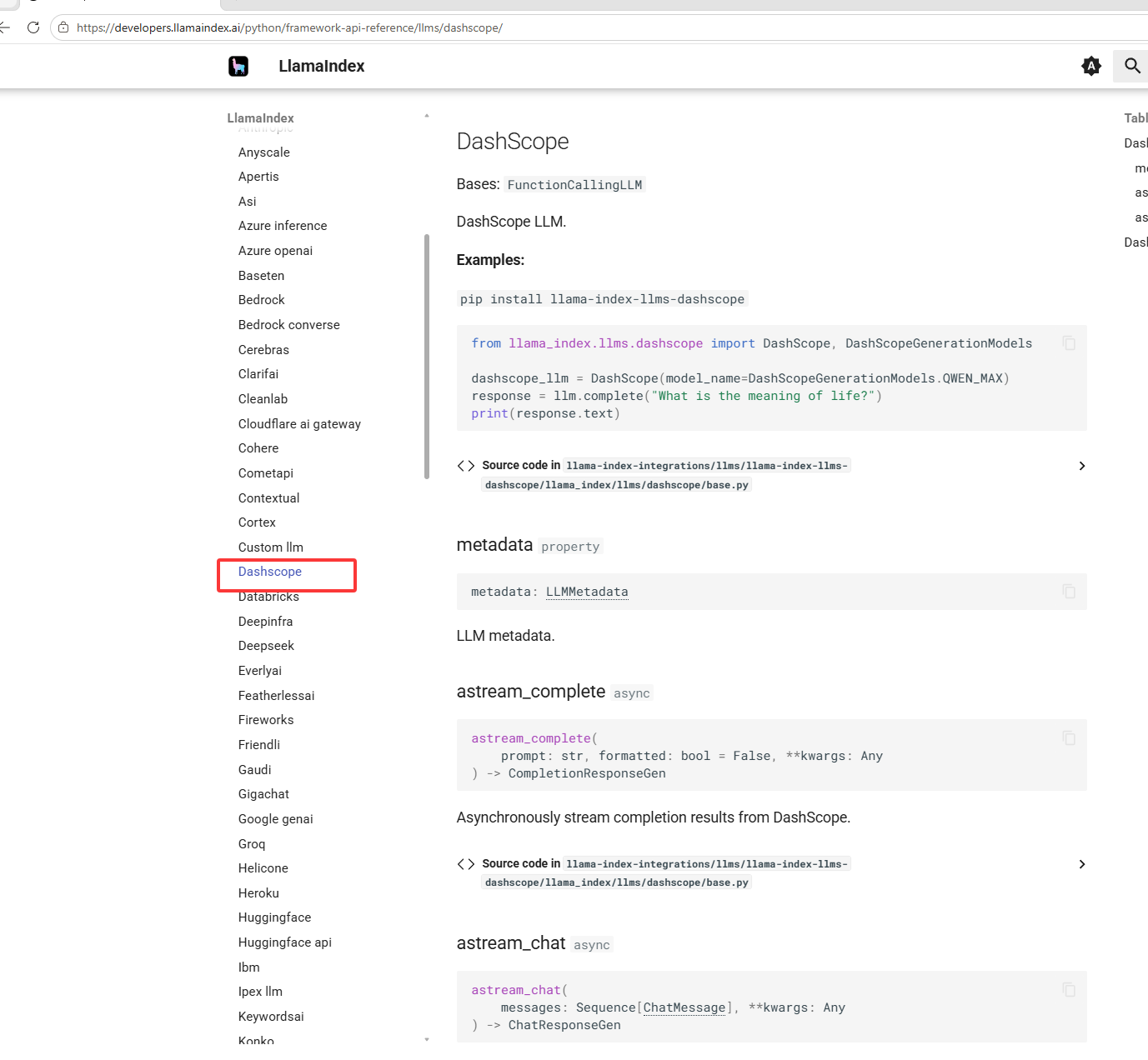
调用千问
import os from dotenv import load_dotenv load_dotenv() from llama_index.llms.dashscope import DashScope,DashScopeGenerationModels # 推荐写法 llm = DashScope( model_name='qwen3.7-max', # 或 QWEN_MAX、QWEN_TURBO 等 api_key=os.getenv("DASHSCOPE_API_KEY"), # 或直接传入 ) response = llm.complete("你好") print(response)调用Ollama,点击下图红框,然后复制下图蓝框安装Ollama库

效果图:
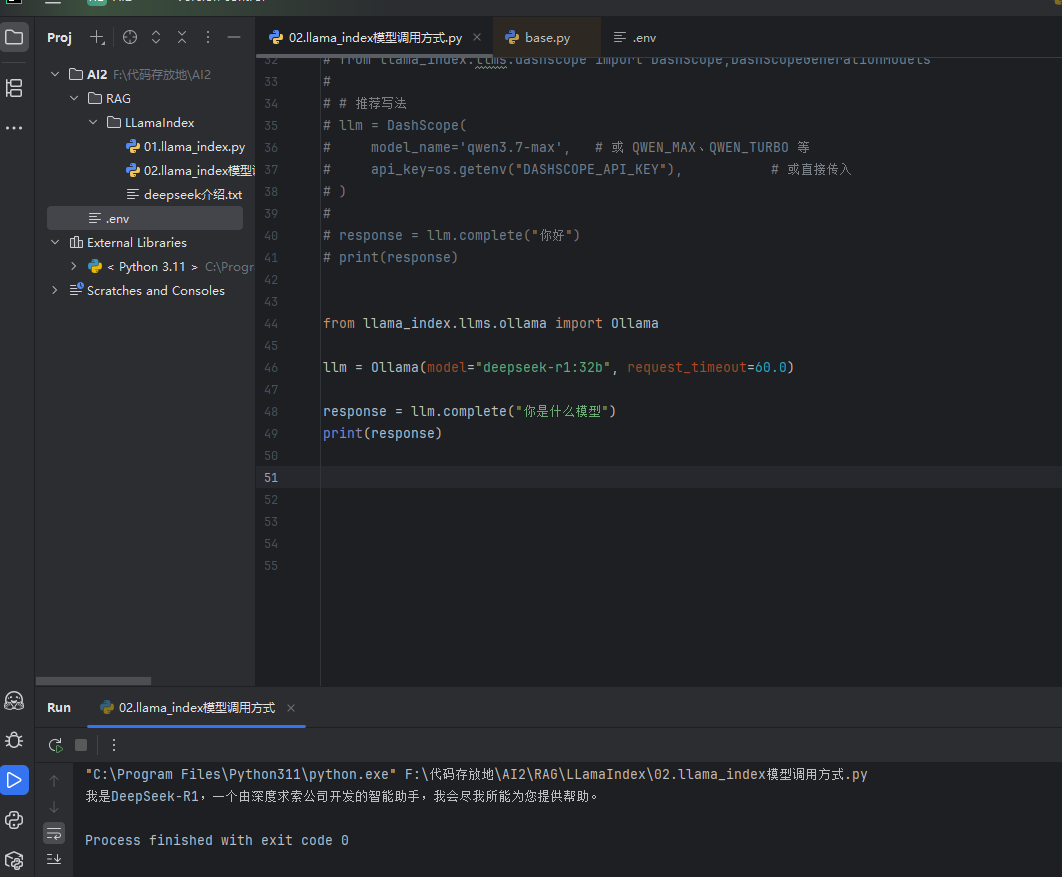
# 从 llama_index 框架中导入 Ollama 原生大模型适配类 # 作用:LlamaIndex 官方专门为 Ollama 本地大模型工具做的原生对接类 # 和之前的 OpenAILike 区别:这是专门给 Ollama 做的适配,不用手动填接口地址、密钥,直接指定模型名就能用,更简单、兼容性更好 from llama_index.llms.ollama import Ollama # 创建 Ollama 大模型实例,对接本地运行的 Ollama 服务 llm = Ollama( # 指定要调用的模型名称,必须和你本地 Ollama 里已经下载运行的模型名完全一致 # 这里用 deepseek-r1 的 32b 参数版本,需要提前执行 ollama pull deepseek-r1:32b 把模型拉取到本地才能用 model="deepseek-r1:32b", # 请求超时时间,单位是秒,这里设置为60秒 # 为什么要设置:本地跑大模型生成速度慢(尤其是参数大的模型),默认的超时时间比较短 # 如果模型还在生成、还没返回结果就到超时时间了,程序会直接报错。设长一点可以避免生成慢导致的请求失败 request_timeout=60.0 ) # 调用大模型的 complete 补全接口,传入问题文本,获取模型的回复 # complete 是单轮补全接口:只传这一句输入,模型直接返回回答,不带历史对话上下文 response = llm.complete("你是什么模型") # 打印模型返回的结果 # response 是 LlamaIndex 封装的响应对象,直接打印会输出模型生成的纯文本回答 print(response)
每个模型调用的时候都是通过llm.complete方法,这个complete它只能传入字符串,它返回的原本内容
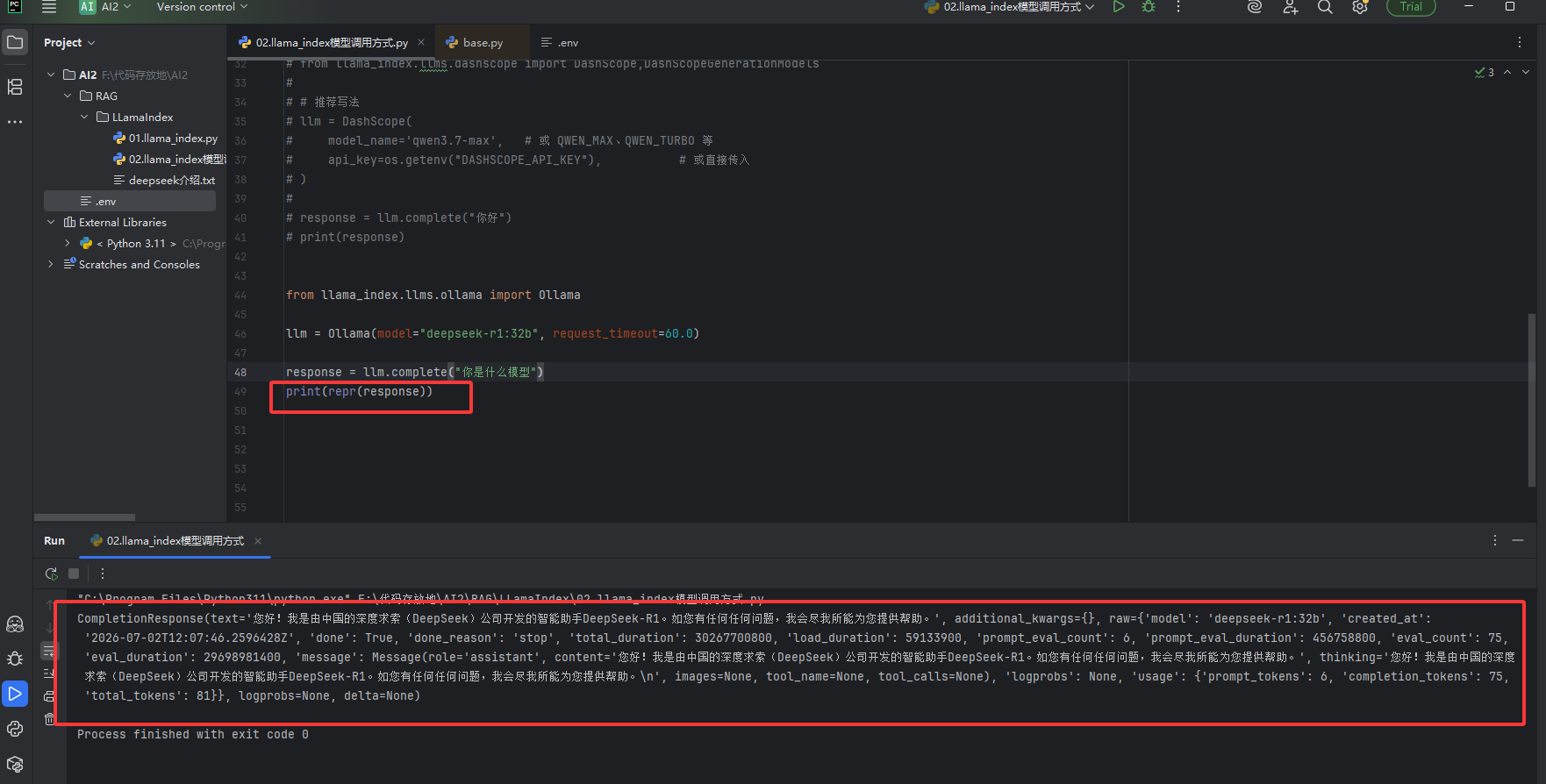
如下图它的说明
{
// ========== 最外层:LlamaIndex 统一封装的响应格式 ==========
// 这是 LlamaIndex 给所有大模型统一的返回结构,方便不同模型之间通用
"text": "您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。",
// 作用:大模型生成的纯文本回答,是我们最常用的字段
// 平时取回答内容直接拿这个字段就行,和 print(response) 输出的内容一致
"additional_kwargs": {},
// 作用:附加参数字典,一般用来放扩展信息,这里是空的,普通场景用不到
"raw": {
// ========== raw 层:Ollama 接口原生返回的完整原始数据 ==========
// 作用:保存 Ollama 官方返回的全部详细信息,包含耗时、token、模型状态等
// 平时写业务不用管,排查问题、统计性能的时候看这里
"model": "deepseek-r1:32b",
// 作用:实际响应的模型名称,确认返回的就是你调用的 deepseek-r1:32b
"created_at": "2026-07-02T12:10:22.4304663Z",
// 作用:本次响应生成的时间戳,UTC 标准时间,用来记录调用时间
"done": true,
// 作用:生成是否完成,true=已经生成结束,false=还在生成中
// 流式输出的时候会先返回 false,生成完再返回 true
"done_reason": "stop",
// 作用:生成结束的原因
// stop = 正常结束(内容说完了、遇到停止符)
// 其他可能值:length = 达到最大长度被截断
"total_duration": 29771743300,
// 作用:整个请求从开始到结束的总耗时,单位是纳秒
// 换算:29771743300 纳秒 ≈ 29.8 秒,就是这次请求一共花了近30秒
"load_duration": 58388700,
// 作用:模型加载耗时,单位纳秒,≈ 58 毫秒
// 这里很快是因为模型已经在 Ollama 里运行着了,不用重新从硬盘加载
"prompt_eval_count": 6,
// 作用:你的输入问题(提示词)的 token 数量
// token 是大模型的最小计算单位,大概 1 个 token 对应 1~2 个汉字
// 这里输入“你是什么模型”一共被拆成了 6 个 token
"prompt_eval_duration": 424280600,
// 作用:模型处理/理解你输入问题的耗时,单位纳秒,≈ 0.42 秒
"eval_count": 75,
// 作用:模型生成回答的 token 数量,这次输出一共 75 个 token
"eval_duration": 29237495300,
// 作用:生成回答的总耗时,单位纳秒,≈ 29.2 秒
// 补充:可以算出生成速度 75 token / 29.2秒 ≈ 2.6 token/秒
// 这是 32B 大模型在普通电脑上的正常速度,每秒生成 2~3 个字
"message": {
// ========== message 层:对话格式的详细内容 ==========
"role": "assistant",
// 作用:消息角色,assistant = 助手(模型)发的消息
// 对应的 user 就是用户发的消息
"content": "您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。",
// 作用:模型的正式回答内容,和最外层 text 一致
"thinking": "您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。\n",
// 作用:DeepSeek-R1 模型的「思考过程」
// R1 是推理模型,会先内部思考再输出答案,复杂问题这里会有很长的推理链
// 这个简单问题思考内容和答案差不多
"images": null,
// 作用:图片内容,null 表示这是纯文本对话,没有传图片
"tool_name": null,
"tool_calls": null
// 作用:工具调用相关,null 表示这次没有调用任何工具
// 如果是联网、查数据库的场景,这里会有调用工具的信息
},
"logprobs": null,
// 作用:每个 token 的生成概率,没开启这个功能就是 null
// 一般用来做评分、概率分析,普通问答用不到
"usage": {
// ========== usage 层:token 用量统计 ==========
// 作用:统计本次调用消耗的 token 总数,用来算成本、统计用量
"prompt_tokens": 6,
// 输入(问题)消耗的 token 数
"completion_tokens": 75,
// 输出(回答)消耗的 token 数
"total_tokens": 81
// 本次调用一共消耗的 token 数
}
},
"logprobs": null,
// 同上面的 logprobs,LlamaIndex 外层也留了这个字段
"delta": null
// 作用:流式输出的增量内容,同步调用就是 null
// 流式输出时,每次推送的新内容会放在这个字段里
}
除了llm.complete,还有下方的三个
| 方法 | 输入类型 | 输出类型 | 是否支持多轮对话历史 | 是否实时输出(流式) | 推荐使用场景 |
|---|---|---|---|---|---|
| complete | 纯字符串(prompt) | 完整响应(CompletionResponse) | 不支持 | 否(一次性返回) | 简单单句补全、测试、快速实验 |
| stream_complete | 纯字符串(prompt) | 生成器(逐 token 返回) | 不支持 | 是 | 需要实时显示文字(如聊天框打字效果) |
| chat | ChatMessage 列表 | 完整响应(ChatResponse) | 支持 | 否(一次性返回) | 多轮对话、带 system prompt、正式对话 |
| stream_chat | ChatMessage 列表 | 生成器(逐 token 返回) | 支持 | 是 | 多轮实时对话(最推荐用于聊天界面) |
流式输出,就是我们现在用的大模型一个字一个字的蹦,如下图效果图,它返回多次
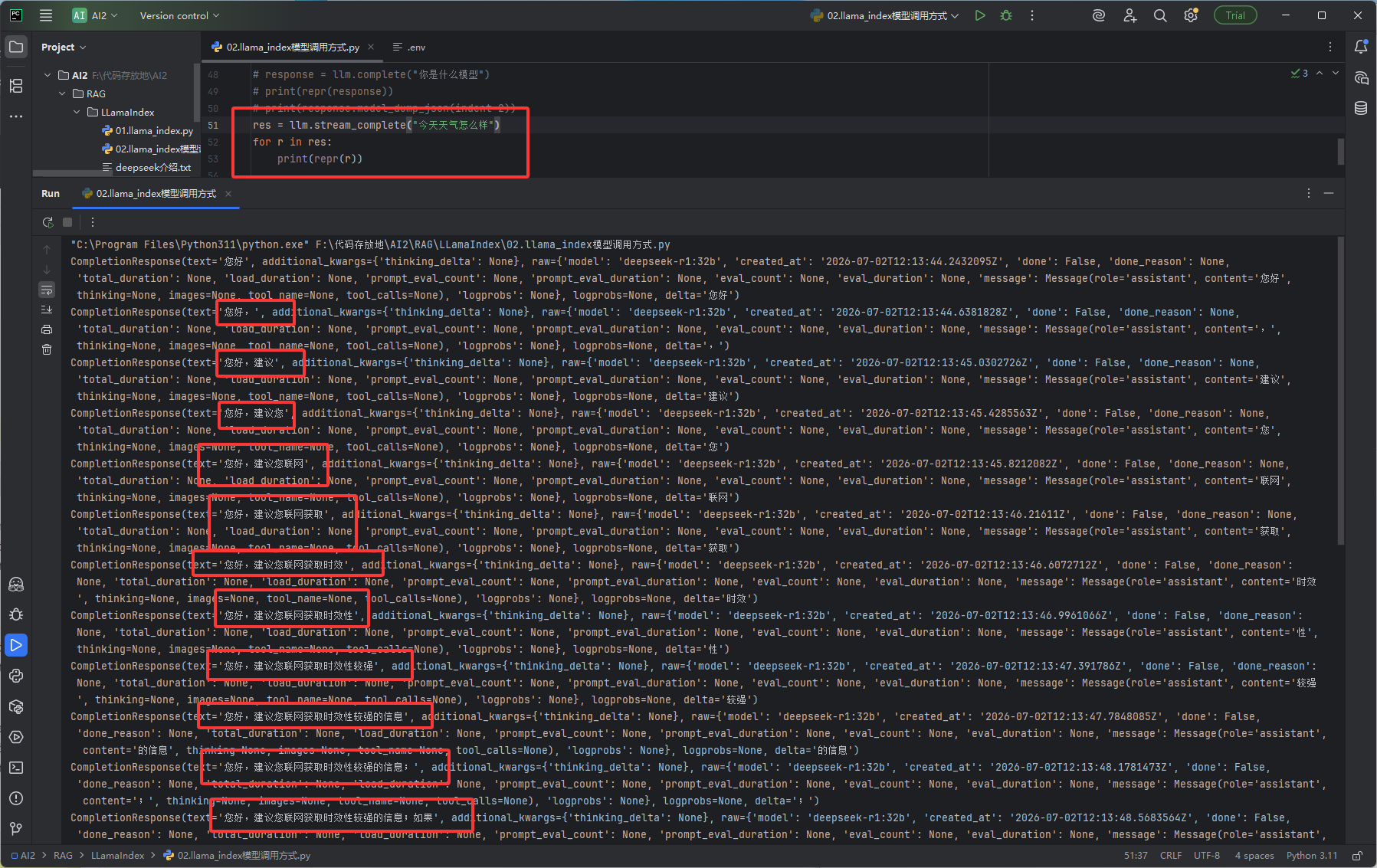
# 从 llama_index 框架中导入 Ollama 原生大模型适配类
# 作用:LlamaIndex 官方专门为 Ollama 本地大模型做的原生对接类
# 比通用的 OpenAILike 适配性更好,支持流式输出、模型管理等 Ollama 专属特性
from llama_index.llms.ollama import Ollama
# 创建 Ollama 大模型实例,对接本地运行的 Ollama 服务
llm = Ollama(
# 指定调用的模型名,必须和本地 Ollama 已下载的模型名完全一致
model="deepseek-r1:32b",
# 请求超时时间,单位:秒
# 流式生成也受这个时间限制,本地大模型生成速度慢,超时设太短会中途报错
request_timeout=60.0
)
# 调用流式补全接口,发起生成请求
# 方法区别:
# complete():同步阻塞,等模型把所有内容全部生成完,一次性返回完整结果
# stream_complete():流式生成,不等待全部生成完,返回一个可迭代对象
# 模型每生成一小段内容,就推送一段,实现「打字机」效果
# 适用场景:大参数模型本地生成慢,流式可以边生成边看,不用长时间干等
res = llm.stream_complete("今天天气怎么样")
# 遍历流式返回的迭代器,每收到一段新内容就执行一次循环
# 变量 r:每一轮循环拿到的「片段响应对象」,包含当前生成的增量文本、状态等信息
for r in res:
# repr() 函数:把对象转成「官方字符串表示」,会完整显示对象的类型、内部所有字段
# 和直接 print(r) 的区别:
# print(r) 只会打印里面的文本内容,看不到对象结构
# print(repr(r)) 会打印完整的对象信息,适合调试用,能看清每次推送了什么数据
print(repr(r))
跟我们用的豆包一个字一个字往外蹦的效果:
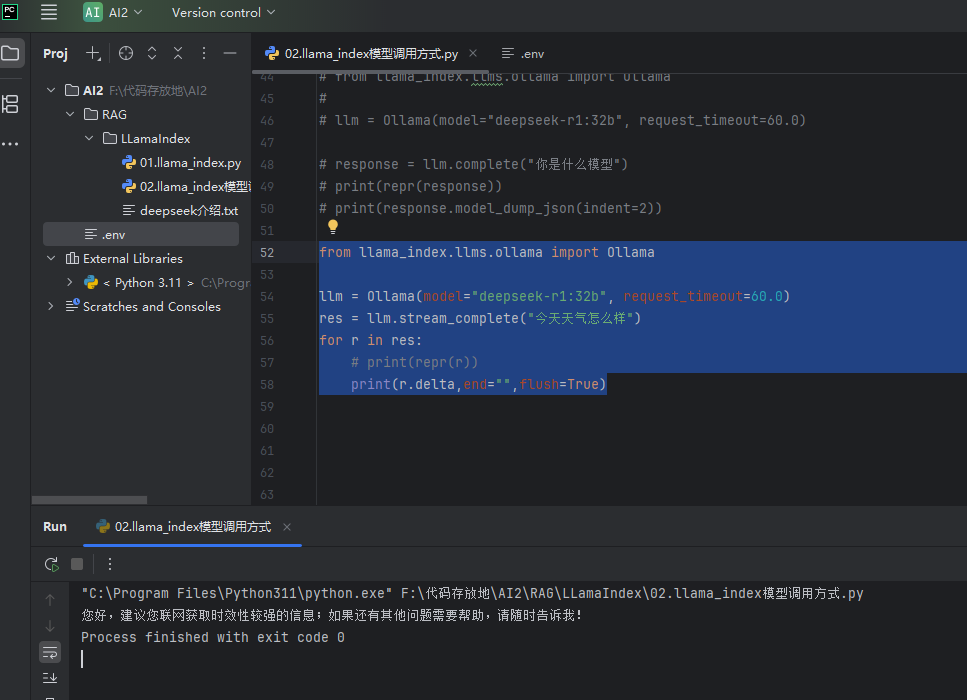
# 从 llama_index 框架中导入 Ollama 原生大模型适配类
# 作用:LlamaIndex 官方专门为 Ollama 本地大模型做的原生对接,完美支持流式输出等特性
from llama_index.llms.ollama import Ollama
# 初始化 Ollama 大模型实例,对接本地运行的模型服务
llm = Ollama(
model="deepseek-r1:32b", # 指定调用的本地模型名称,需和 Ollama 中已拉取的模型名一致
request_timeout=60.0 # 请求超时时间,单位秒;本地大模型生成慢,设长一点避免中途超时报错
)
# 调用流式补全接口,发起生成请求
# stream_complete 与 complete 的核心区别:
# complete:同步阻塞,等模型全部生成完,一次性返回完整结果
# stream_complete:流式生成,立即返回一个可迭代对象,模型每生成一小段就推送一段,实现打字机效果
# 适合本地大参数模型生成慢的场景,不用长时间干等结果
res = llm.stream_complete("今天天气怎么样")
# 遍历流式迭代器,每收到一段新的增量内容,就执行一次循环
# 变量 r:当前片段的响应对象,包含本次新增的文本、完整文本等信息
for r in res:
# 注释掉的调试代码:打印完整对象的结构,用来排查字段、看每次推送的完整信息
# print(repr(r))
# 逐段打印增量文本,实现连续的打字机效果
# 参数拆解:
# 1. r.delta:本次推送的「增量文本」,也就是这一轮新生成的内容片段,不是完整回答
# 与之对应的 r.text 是「截止到当前的完整回答」,会越来越长
# 2. end="":print 默认每次打印完会自动加换行符,设为空字符串就不会换行
# 所有片段会连续拼接在同一行,模拟正常的文字输出效果
# 3. flush=True:强制刷新输出缓冲区
# 原理:Python 默认会把输出内容攒到一定量才真正打印到屏幕
# 不加这个参数,流式内容可能会「攒一堆突然蹦出来」,没有逐字的流畅感
# 强制刷新可以保证每生成一个字就立刻显示,实现实时打字机效果
print(r.delta, end="", flush=True)
complete和stream_complete只能单次对话,如果想要跟聊天一样需要使用chat和stream_chat
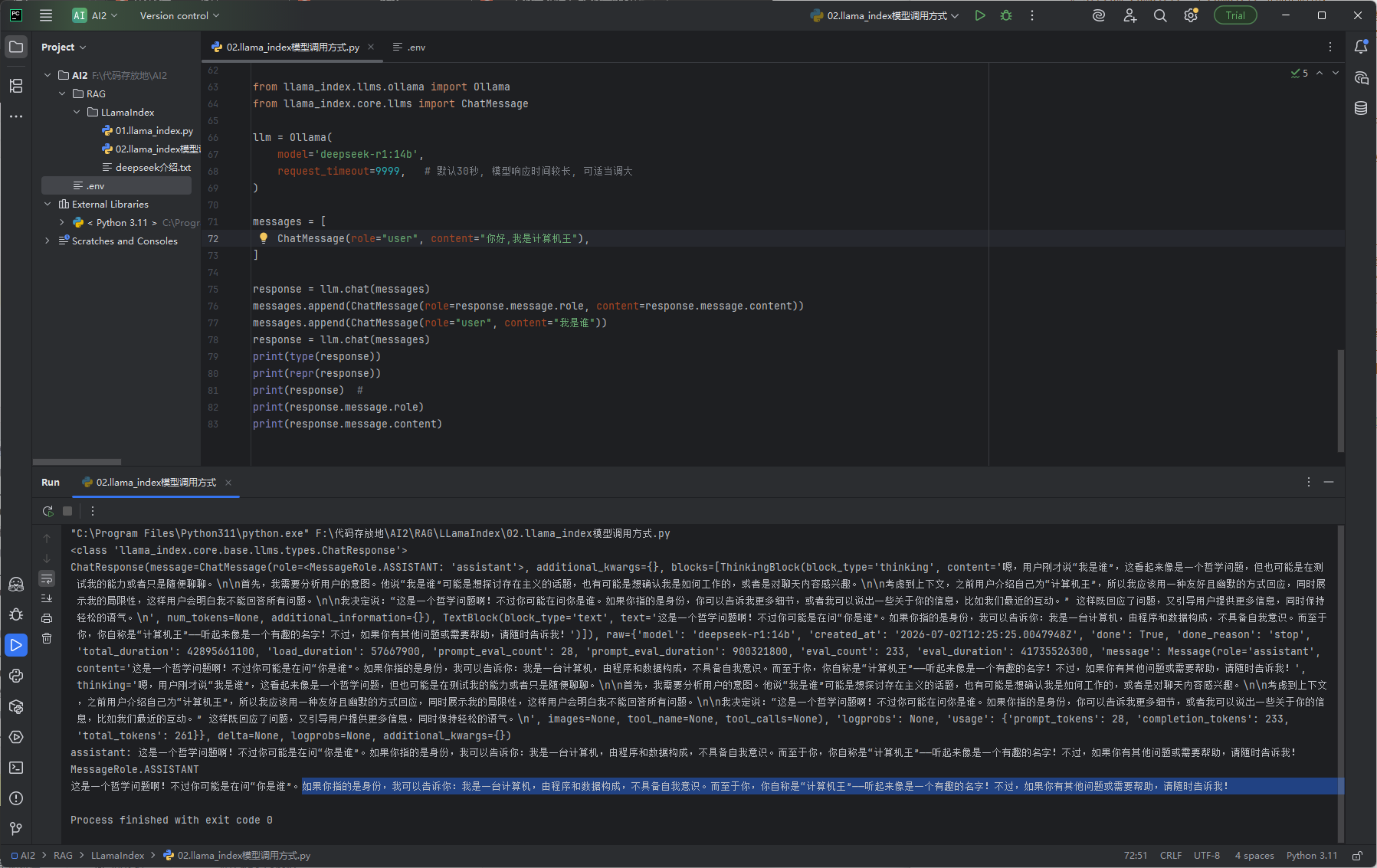
chat方法
效果图:
代码
# 从 llama_index 框架中导入 Ollama 原生大模型适配类 # 作用:对接本地 Ollama 运行的大模型,原生支持聊天、流式输出等对话能力 from llama_index.llms.ollama import Ollama # 从 LlamaIndex 核心模块导入 ChatMessage 聊天消息类 # 作用:封装单条对话消息,区分角色(用户/助手/系统),是实现多轮对话的标准数据结构 from llama_index.core.llms import ChatMessage # 初始化 Ollama 大模型实例 llm = Ollama( model='deepseek-r1:14b', # 指定调用的本地模型名称,需提前用 ollama pull 拉取到本地 request_timeout=9999, # 请求超时时间,单位:秒 # 本地模型生成速度慢,默认30秒很容易超时,设大一些避免长回复中途报错 ) # ========== 第一轮对话:初始化对话历史 ========== # 构造对话消息列表,列表的顺序就是对话的先后顺序 # 多轮对话的核心:所有历史消息都存在这个列表里,每次调用模型都把完整列表传进去 # 模型就能看到全部上下文,实现「记忆」效果 messages = [ # 第一条消息:用户的提问 ChatMessage(role="user", content="你好,我是计算机王"), ] # 第一次调用聊天接口:传入初始消息,得到模型第一轮回复 response = llm.chat(messages) # ========== 关键:维护对话历史,实现多轮记忆 ========== # 把模型第一轮的回复,追加到消息列表里 # 作用:把助手的回答存进历史,下一轮提问时模型就能看到自己之前说过什么 # response.message.role 固定是 assistant,response.message.content 是回复的具体内容 messages.append(ChatMessage(role=response.message.role, content=response.message.content)) # 把用户的第二个新问题,也追加到消息列表末尾 # 作用:形成完整的「用户问→助手答→用户再问」的对话链 messages.append(ChatMessage(role="user", content="我是谁")) # ========== 第二轮对话:带完整历史提问 ========== # 第二次调用聊天接口,传入包含两轮历史的完整消息列表 # 模型会基于全部上下文回答,所以能记得上一轮用户说自己是「计算机王」 response = llm.chat(messages) # 以下是不同方式打印第二轮的响应结果,用于调试和查看结构 print(type(response)) # 打印返回对象的类型,固定为 ChatResponse(聊天响应类) print(repr(response)) # 打印响应对象的完整内部结构,包含所有字段,适合调试排查问题 print(response) # # 直接打印对象,LlamaIndex 做了优化,默认输出模型回复的纯文本内容 print(response.message.role) # 打印回复消息的角色,固定为 assistant(助手) print(response.message.content) # 打印模型第二轮回复的纯文本内容,是业务代码最常用的属性 # 因为带了上下文,模型这里会回答你是「计算机王」
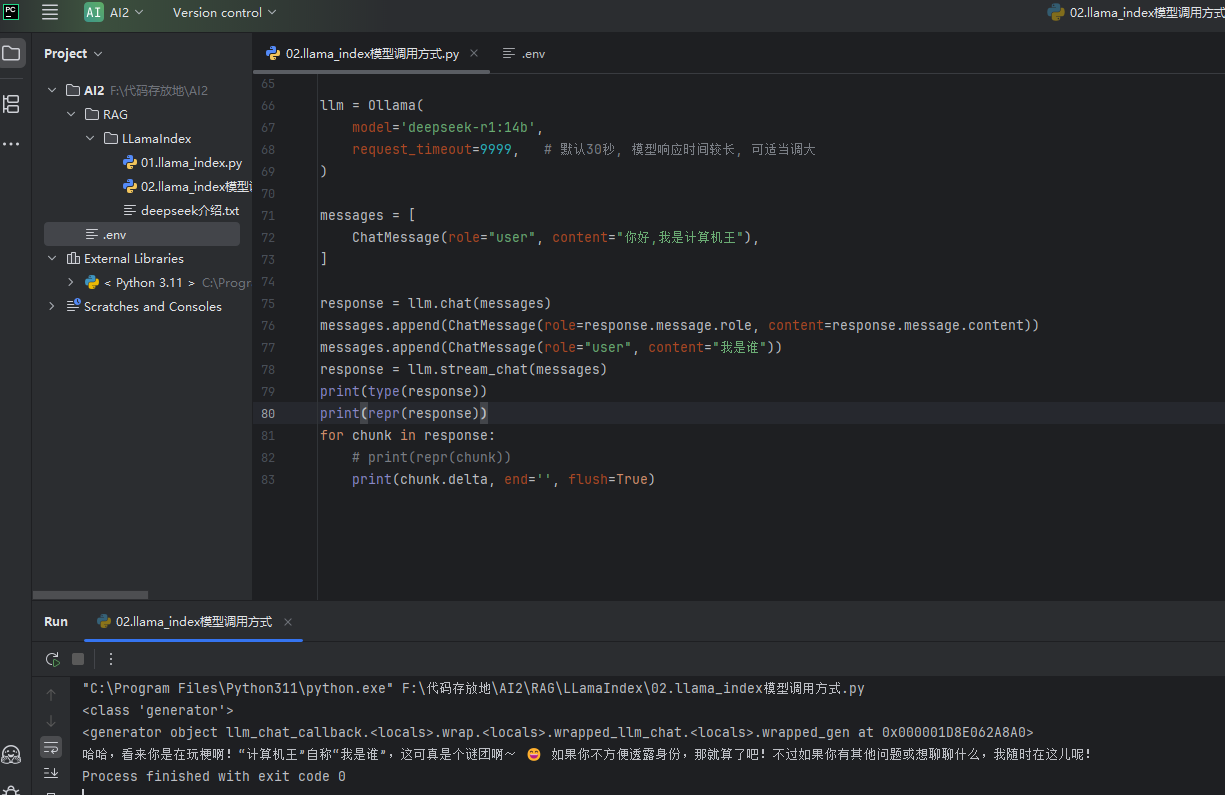
stream_chat方法
效果图:
代码
# 从 llama_index 框架中导入 Ollama 原生大模型适配类 # 作用:对接本地 Ollama 运行的大模型,原生支持聊天、流式输出等完整对话能力 from llama_index.llms.ollama import Ollama # 从 LlamaIndex 核心模块导入 ChatMessage 聊天消息类 # 作用:封装单条对话消息,区分角色(用户/助手/系统),是实现多轮对话的标准数据结构 from llama_index.core.llms import ChatMessage # 初始化 Ollama 大模型实例 llm = Ollama( model='deepseek-r1:14b', # 指定调用的本地模型名称,需提前用 ollama pull 拉取到本地 request_timeout=9999, # 请求超时时间,单位:秒 # 本地模型生成速度慢,默认30秒很容易超时,设大一些避免长回复中途报错 ) # ========== 第一轮对话:初始化对话上下文 ========== # 构造对话消息列表,列表顺序就是对话的先后顺序 # 多轮对话的核心:所有历史消息都存在这个列表里,每次调用模型都传入完整列表 # 模型就能看到全部上下文,实现「记忆」效果 messages = [ # 第一条消息:用户的初始提问 ChatMessage(role="user", content="你好,我是计算机王"), ] # 第一次调用同步聊天接口:传入初始消息,得到模型第一轮完整回复 # 这里用同步 chat 是因为第一轮要拿到完整回复,再维护到历史消息里 response = llm.chat(messages) # ========== 维护对话历史(关键步骤) ========== # 把模型第一轮的回复追加到消息列表里 # 作用:把助手的回答存入历史,下一轮提问时模型能看到自己之前说过什么 messages.append(ChatMessage(role=response.message.role, content=response.message.content)) # 把用户的第二个新问题也追加到消息列表末尾 # 作用:形成「用户问→助手答→用户再问」的完整对话链,为第二轮提问做准备 messages.append(ChatMessage(role="user", content="我是谁")) # ========== 第二轮对话:流式聊天接口 ========== # 调用流式聊天接口 stream_chat,传入带完整历史的消息列表 # 和 chat 方法的核心区别: # chat() :同步阻塞,等模型全部生成完,一次性返回完整结果 # stream_chat():流式生成,立即返回一个可迭代对象,模型每生成一小段就推送一段 # 实现「打字机」效果,不用长时间干等,适合本地生成慢的大模型 response = llm.stream_chat(messages) # 打印流式返回对象的类型,用于调试 print(type(response)) # 打印流式返回对象的完整结构表示,用于调试查看对象属性 print(repr(response)) # 遍历流式迭代器,每收到一段新的增量内容,就执行一次循环 # chunk:每一轮循环拿到的「片段响应对象」,包含本次新增的文本等信息 for chunk in response: # 注释掉的调试代码:打印每个片段的完整结构,用来排查字段 # print(repr(chunk)) # 逐段打印增量文本,实现连续的打字机效果 # 参数拆解: # 1. chunk.delta:本次推送的「增量文本」,也就是这一轮新生成的内容片段,不是完整回答 # 对应的 chunk.message.content 是「截止到当前的完整回答」 # 2. end='':print 默认每次打印完会自动加换行符,设为空字符串就不会换行 # 所有片段会连续拼接在同一行,模拟正常的文字输出效果 # 3. flush=True:强制刷新输出缓冲区 # Python 默认会把输出内容攒到一定量才真正打印到屏幕 # 不加这个参数,流式内容可能会「攒一堆突然蹦出来」,没有逐字的流畅感 # 强制刷新可以保证每生成一个字就立刻显示,实现实时打字机效果 print(chunk.delta, end='', flush=True)
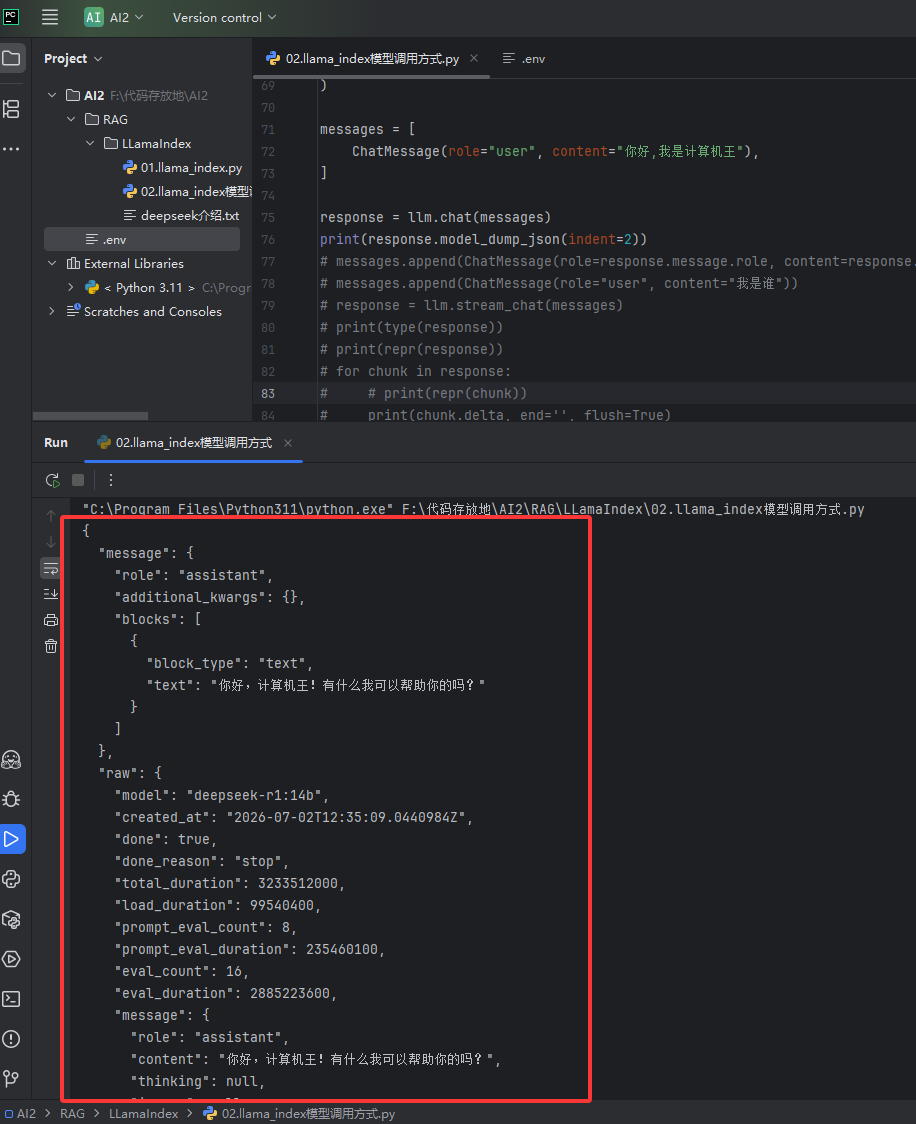
我们要的就一个答案为什么大模型会返回如下图这么多内容呢?如果我们使用了多个大模型,下图的红框的信息就可以用来做日志,可以看什么模型返回了什么,什么时间回复的


欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)