AI工程的进化密码:Harness Engineering让模型调用不再是终点,Agent系统才是新起点!
Harness的产品有它的合理性,它的的确确需要更加概括性的一个表达。Harness核心强调是控制。
Harness是有构建的控制,Harness也被大家配上词元:马具、马鞍等,从词元大家也能大概理解Harness的概念。马具、马鞍的诞生,是为了让人更好的驾驭马,让马按照人的思维去执行。要不然马就会像野马一样,不受控制,今天往左跑,明天往右跑。
简而言之,Harness是从工程角度,对模型输出进行控制。
我会从这个责任到底是什么,它所对应的范围是什么,它里面的组成是什么,它对应的模块是什么,一层层带大家熟悉Harness。
为什么现在模型的可执行的任务变得很复杂,它是怎么一步步变复杂的,变复杂后,我们对于模型去解决问题的时候,我们要去做的控制,做的管理责任也在变高,所以模型变大了,我们工程的责任也在变大,它到底怎么回事,我们会去推论这个过程。然后我们会去定义Harness放在哪里是比较合适的。我们之前有些定义,会把它们归到Harness的范畴里面,但是它只会有部分是属于Harness。最后我们会沟通,如果我们要系统性的学习Harness系统,我们要学哪些关键模型。
从单次请求到 Agent 任务,系统责任发生了什么变化
单次请求的主要风险是“回答得不好”。Function Calling 之后,模型的输出开始代表⼀个行动请求;进⼊ Agent Loop(包含ReAct Loop)后,行动会根据观察结果持续发⽣;进⼊长任务后,工作空间、任务状态、副作用、验证和恢复都需要跨越多轮甚至多个会话。
可以用“模型、数据、控制”三要素来理解这种变化:
- 模型: 提供基础智能(理解、判断、规划和表达能力);
- 数据: 理解、学习预训练基础知识之上,额外补充的信息:
- 私域(公司、组织)知识性信息的补充;
- 公域但具有时效性的信息的补充;
- 任务推进过程中间,状态、产物的管理。
- 控制: 模型输出的过程进行编排管理、状态暂存、容错。
模型的演变:问答/聊天/对话机器人 —> 知识库/AI搜索/Deep Reseach —> 单Agent应用 —> 多Agent应用
详细的,大家可以去看下我之前写的文章 2023-2026大模型应用演进史:从指令对话到系统自治,每一步都踩中技术风口!。
Harness Engineering 主要讨论第三部分,并把“控制”从输出格式和⼀次⼯具调⽤,扩展到整个 Agent 任务⽣命周期。
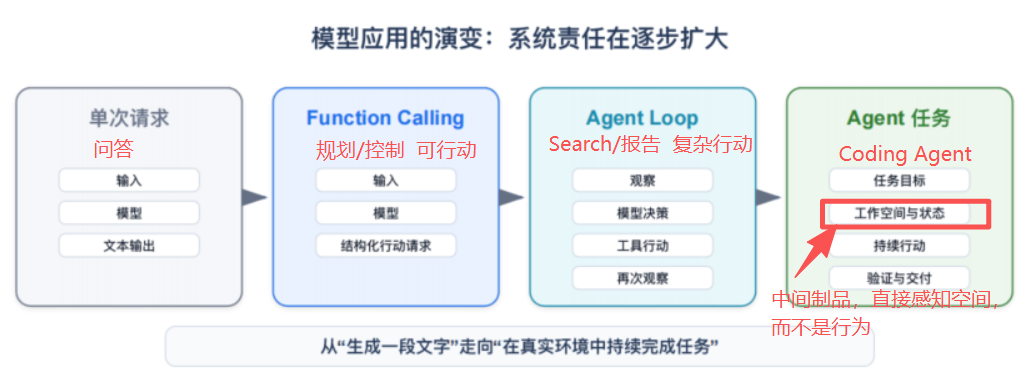
Function Calling流程图:
Function Calling 和 Agent Loop 是转折点,但还不是终点
| 阶段 | 模型输出代表什么 | 系统新增责任 |
|---|---|---|
| 单次请求 | ⼀段⽂本或结构化结果 | 输⼊、输出格式、超时、基本审计 |
| Function Calling | ⼀个外部行动请求 | 工具选择、参数校验、执⾏、错误回传 |
| Agent Loop / ReAct | 下一步行动决策 | 循环、观察、重试、停止条件、预算 |
| Agent 任务 | 对真实目标的持续推进 | 工作空间、状态、记忆、权限、验证、恢复、服务化 |
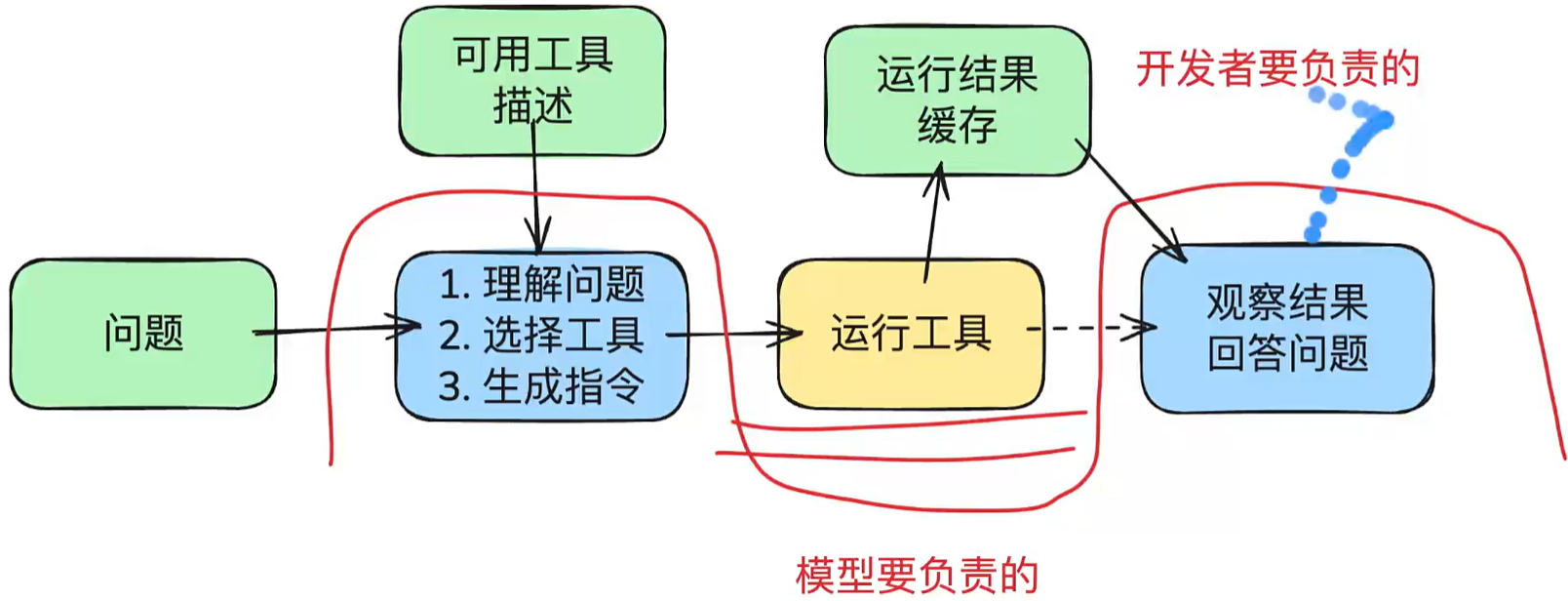
“Agent Loop” 这⼀行有明确的学术原型。Yao 等⼈在 ReAct(ICLR 2023)中提出让模型把推理和行动交错生成:推理用来规划、跟踪和处理异常,行动用来与外部环境交换信息。这条“推理 - 行动 - 观察”的回路,正是后面要反复用到的责任起点。
ReAct Loop流程图:
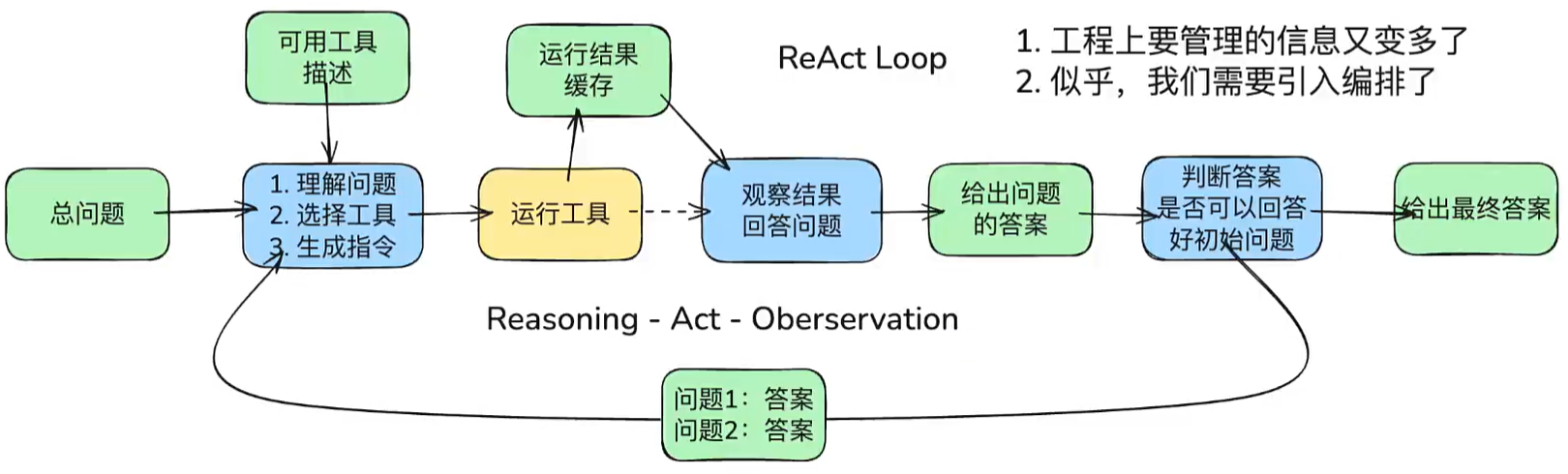
ReAct Loop并不处理复杂任务的问题,它是原子节点,对单个任务或者循环推进是有帮助的。ReAct Loop是一步一步的推进,所以它对复杂问题的拆解与编排并没有那么好。
ReAct Loop可以解决70-80%的问题,但是遇到复杂的问题就不尽人意,所以就衍生了Agent Loop,并且Harness(控制)的苗头露出来了一点。
Agent Loop流程图:
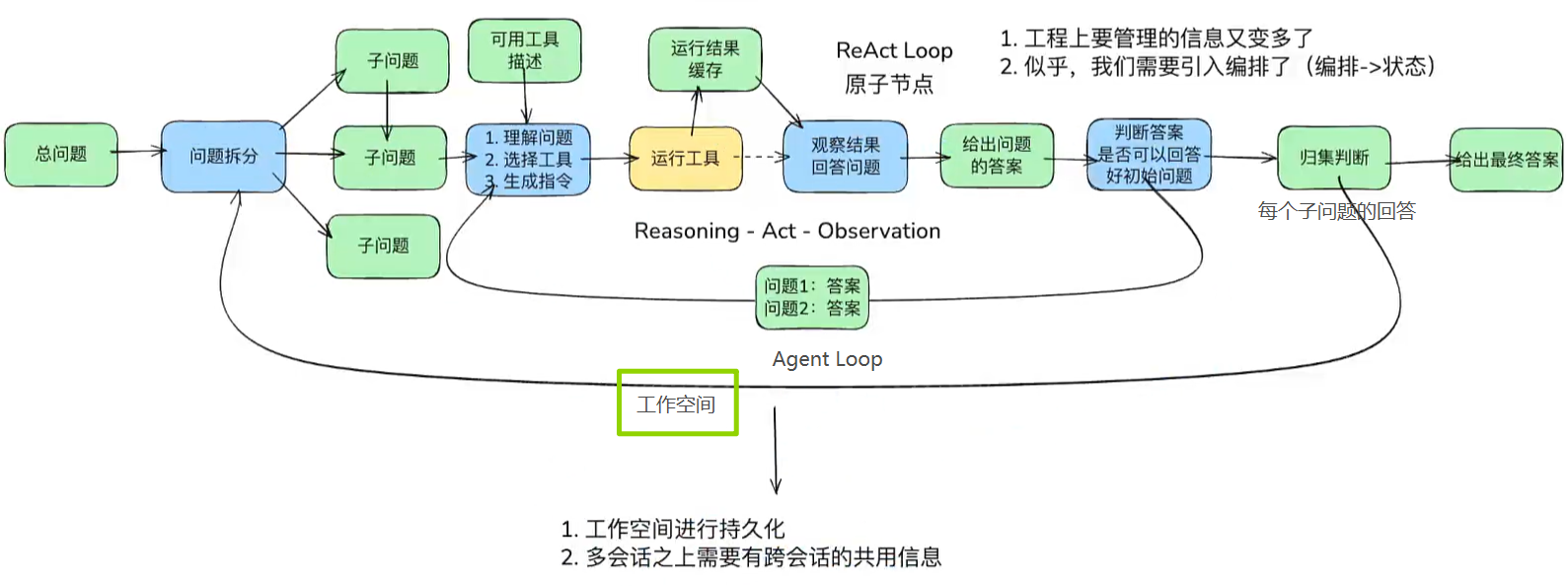
模型的能力没有消失。变化在于:任务结果不再等于模型最后生成的文字,结果越来越多地存在于⽂件、数据库、浏览器、工单、代码仓库和其他外部系统⾥。
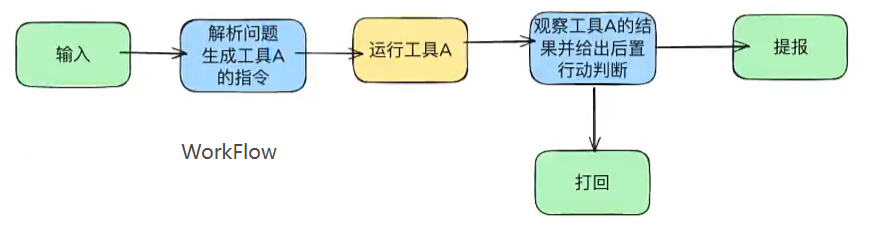
Anthropic 在《Building Effective Agents》(2024-12)里把这条演变线收成⼀个常被引用的区分:Workflow 是⽤预先写好的代码路径去编排模型和⼯具,Agent 则是让模型自己动态决定流程(编排)和⼯具调用。
WorkFlow流程图:
**Agentic WorkFlow流程图: **
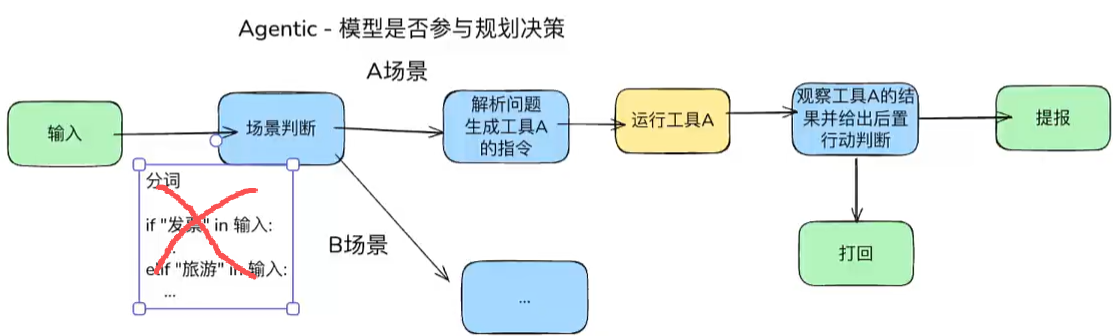
他们同时给出⼀条务实原则——先用最简方案,只在确有收益时才增加复杂度,因为 Agent 用更高的延迟和成本换取⾃主性,并不总是划算。
这正好引出下⼀个问题:当任务复杂到必须交给 Agent ⾃⼰推进时,单靠“把循环跑久一点”够不够?
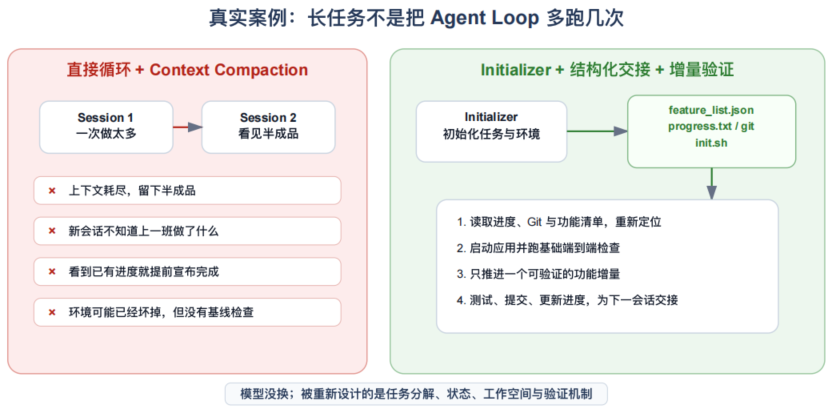
一个公开的长任务案例:同一个模型,为什么循环跑仍然不够
案例背景:2025年11月26日,进行Anthropic 的跨上下文长任务实验
- 实验对象:Claude Agent SDK 中的前沿编码模型 Opus 4.5;系统已经具备工具调用和上下文压缩(compaction)。
- 任务方式:给模型一个高层目标(网址),例如构建一个
claude.ai风格的完整 Web 应用;当一个上下文窗口结束后,用新会话继续循环推进。 - 要回答的问题:有了强模型、工具、Agent Loop 和上下文压缩,为什么长任务仍然不能自然变成稳定交付?
稳定出现的失败模式:
- Agent 试图一次完成太多工作,上下文耗尽时留下半实现、未说明的代码;
- 新会话不知道上一会话到底做了什么,只能从仓库现状重新猜;
- 项目已有部分功能后,后续会话容易把“已有进展”误判成“全部完成”;
- 环境已经损坏时,Agent 仍继续增加功能,使错误继续累积。
这个案例说明: 循环和上下文压缩只解决“继续调用模型”,并没有自动解决目标分解、跨会话状态、工作基线、完成证据和交接。
注意边界: 这不是一个通用 Benchmark 排名,而是一个工程案例。它能证明的重点是:跨上下文长任务需要外部状态、基线检查和验收工件;不能简单推出“所有长任务都按这一套实现”。
想了解更详细的,大家可以看下这篇文章 Anthropic — Effective harnesses for long-running agents。
他们没有重新训练模型,而是重做模型周围的任务结构和运行约束(SDD + TDD):
| 观察到的失败 | 加入的系统工件或规则 | 为什么有用 |
|---|---|---|
| 一次做太多、上下文中断 | 初始会话把高层目标展开为完整功能清单;后续会话一次只推进一个功能 | 把“整个项目”改造成有限、可选择、可检查的下一步 |
| 新会话失忆 | claude-progress.txt 与 Git 历史 |
新会话读取外部事实,而不是依赖压缩后的聊天摘要猜测 |
| 不知道怎样启动和检查系统 | initializer 生成 init.sh;新会话先启动应用并做基础端到端检查 |
先确认当前基线可工作,再增加新变化 |
| 提前宣布完成 | 功能清单初始全部标记为 failing;端到端测试通过后才允许改为 passing | “完成”由外部验收结果决定,不由模型一句话决定 |
这个案例把 Harness 问题说得很具体:模型负责提出和执行下一步,但任务能否持续推进,取决于模型之外怎样管理目标、环境、状态、证据和交接。 后面所有抽象的范围和责任地图,都可以回到这张表来对照。
Harness 这个词到底在说什么
“Harness”来自传统软件工程里的 test harness:它不是被测对象本身,而是为被测对象提供输入、运行环境、观测和断言的一套外部装置。Agent harness 沿用了这个隐喻,只是对象从“被测程序”变成了“需要持续观察、行动和修正的模型(多模型请求执行过程)”。
公开讨论里没有一个已经稳定下来的唯一口径。不同作者分别在回答不同问题:
一个 Agent 产品里除了模型还包含什么?
使用现成 Coding Agent 时,团队怎样在外层提高质量?
当 Agent 成为主要生产者后,仓库和组织怎样变化?
把这些说法按“离运行内核的远近”叠起来,就是一座从运行内核到组织外层的金字塔——越靠下越基础,越靠上越外层。

常见视角与代表来源
这些视角不需要互相排斥,它们只是分析单位不同。这里优先列业界影响力较高的来源;其中“用户外层”一类更多是开发者社区的共识,也一并标出,便于判断其分量。
| 层次(自底向上) | 代表来源 | 它把 Harness 看成什么 | 容易误读的地方 |
|---|---|---|---|
| 运行内核(严格运行时) | 综合 Anthropic、SWE-agent 等公开实践 | 循环、环境行动接口、任务感知上下文与独立控制 | 易被误读成唯一标准;更适合当作范围的内核 |
| 执行与托管运行时 | Microsoft Agent Framework;Anthropic 长任务案例 | Shell、文件、Sandbox、审批、长会话与托管执行 | 易只看到工具环境,忽略状态和验证 |
| 用户外层控制 | 开发者社区常见观点(个人/团队博客,如 martinfowler.com 等) | 文档、Skills、Lint、测试、Review 等 Guides 与 Sensors | 常把 Harness 等同于“围绕 Coding Agent 搭工作流”,弱化运行时的行为控制与验证 |
| 失败 → 回归的工程方法 | Reflexion(Shinn 等,NeurIPS 2023);Eval 回归实践 | 把每次失败沉淀为反思、规则、工具或回归检查 | 它是改进方法,不是完整 Harness 本体 |
| Agent-first 交付系统 | OpenAI,Harness engineering: leveraging Codex in an agent-first world | 仓库知识、CI、架构约束、角色与组织围绕 Agent 重构 | 不能把全部组织变革都等同为运行时 |
还有一种“广义非模型层”口径(LangChain,The Anatomy of an Agent Harness):把模型以外的一切——prompt、工具、Skills、MCP、Sandbox、编排——都算 Harness。
它适合回答“Agent 产品除了模型还需要什么”,但用于边界判断时过宽。
“用户外层”这种看法在开发者博客里非常常见,往往把 Harness 直接理解成“怎样围绕 Coding Agent 搭一套工作流”。它抓住了外层的重要性,但容易忽略运行内核。OpenAI 的 agent-first 实践给出了同一思路更系统、可验证的版本:证据 · 最外层:把“模型看不见的东西”做成系统资产。
OpenAI 这个案例不是在说“文档越多越好”,而是在说明 Agent-first Operating Materials 怎么从“人读的说明”变成“Agent 能发现、执行、验证的系统资产”。
- 旧做法: 把规则堆进一个巨型
AGENTS.md。问题很直接:上下文被挤占,约束没有主次,规则容易陈旧,也很难用机械检查确认它还有效。 - 新做法: 把
AGENTS.md收成约百行的目录入口,把真实知识放进版本化docs/,把复杂工作写成带进度和决策记录的 execution plan,再用 Lint/CI、结构测试、日志和 Trace 给 Codex 反馈。 - 为什么有效: 模型不是凭一大段提示“记住所有规则”,而是先拿到地图,再按任务逐步读取更深的材料;质量规则也不只停在文字里,而是变成可运行、可失败、可修复的检查。
含义: 金字塔最外层不是“多写几句提示”,而是把仓库知识、计划和质量约束做成 Agent 可发现、可执行、可验证的系统资产。它主要对应第三层 Operating Materials,不等同于最里面的运行与控制系统。
先统一四层概念
行业语境里常见 Agent Harness、Runtime Harness、runtime substrate 等叫法,边界并不完全一致。为了避免同一个词在不同层次之间跳动,先把四层概念分开:
- Agent Harness / Agent 运行与控制系统:紧贴在模型外面的那一层,把模型变成能在环境中持续行动、同时受到约束和验证的系统——循环、工具、工作空间、状态、记忆、权限、验证、恢复都在这里;
- Harness Engineering:设计、评估、部署并持续改进上面这套系统的工程工作;
- Agent-first Operating Materials:为了智能系统能够正常工作,进行的相关材料组织,包括但不限于Skills管理、AGENTS.md、Spec管理、Test Case管理等;
- Agent-first Organization:再往外,围绕 Agent 重构协作关系、交付流程、角色定位和岗位定责的组织方式。

如上图所示,模型在最里面,Harness 工程讨论的核心对象是 1+2:紧贴模型的 Agent Harness,以及围绕它展开的设计、评估、部署和持续改进。
需要澄清一种很常见的说法:有人把 Harness 直接理解成“围绕 Coding Agent 搭一套文档、Skills、AGENTS.md 工作流”。这类做法更接近第三层 Agent-first Operating Materials,确实有用,但它不等同于 1+2 这套运行与工程体系。
确定了对象,下一步不急着判断“什么才算完整”,而是先把它的合理范围圈出来。
先圈定 Harness 的合理范围
与其急着判断“什么才算完整的 Harness、什么不算”,不如先把它的范围圈出来。Harness 不是某一个工具,而是模型外面那一圈“让模型能在真实环境里持续、安全地完成任务”的系统。它既有清楚的上下界,也有清楚的内部责任。
上界和下界:模型在下,组织在上

- 下界 · 模型(L0):权重和推理能力是 Harness 包裹、调度的核心,本身不是 Harness 的机器部件;
- 主体 · L1–L4:指导与上下文、行动与环境、任务运行与服务、质量与交付,这四层是 Harness 的技术主体;
- 上界 · 治理与组织(L5):身份、审批、成本、平台模板大多属于更外层的 operating model,只有被编码成运行策略的那一部分才进入 Harness。
范围内部:四类责任
把 L1–L4 再压一压,Harness 的范围可以用四类责任圈定。它们不是“通过/不通过”的考试,而是“这块地盘由哪几种责任组成”:
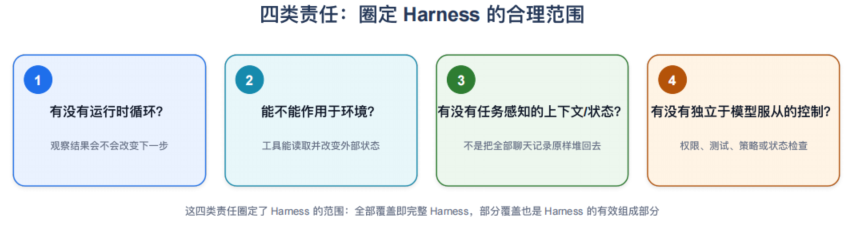
| 责任 | 它负责什么 | 代表来源 / 依据 |
|---|---|---|
| 运行闭环 | 让“推理—行动—观察”持续迭代,上一步的观察能改变下一步 | ReAct(ICLR 2023) |
| 环境行动 | 通过接口读取并改变外部环境:写文件、运行命令、操作浏览器、调用业务系统 | SWE-agent ACI(NeurIPS 2024);Model Context Protocol(MCP,2024) |
| 上下文与状态 | 按任务筛选进出窗口的信息,并把状态留在窗口之外 | Anthropic《Effective context engineering for AI agents》(2025) |
| 独立控制 | 用权限、预算、测试、策略,不依赖模型自觉地约束和验证 | OpenAI《A Practical Guide to Building Agents》的 guardrails;Anthropic《Demystifying evals for AI agents》 |
这里列出的来源不是在分别定义“完整 Harness”,而是在支撑四类责任为什么成立:
- ReAct 说明闭环原型;
- SWE-agent 与 MCP 说明环境接口会改变行动能力;
- context engineering 说明进入窗口的信息会改变行为;
- guardrails 和 evals 则说明风险与完成度需要由外部机制约束和验收。
为什么要先把范围和责任讲清楚?
因为 Agent 的任务表现并不只取决于模型——同一个模型,换一套接口,结果就明显不同:证据 · 固定模型,换一层环境行动接口,结果就变。
SWE-agent 论文里的 ACI(Agent-Computer Interface)不是一个抽象标签,而是模型和计算机之间的交互层:模型能发哪些命令、命令怎样改变仓库、执行后返回什么反馈。
实验固定 GPT-4 Turbo,只换这一层接口。
- Shell-only: 模型直接用 Linux shell,自己组合
ls、cd、cat、grep、sed、重定向等命令。它很灵活,但动作太碎:定位代码要串很多命令,编辑多行代码容易写坏,命令无输出时模型也很难判断“到底发生了什么”。 - SWE-agent ACI: 仍然建立在 shell 之上,但额外提供面向模型的搜索、文件查看、行级编辑和反馈格式。比如搜索结果会被压缩成更容易读的列表,文件查看器一次给 100 行上下文,
edit命令能按行替换片段,编辑后还会返回更新后的视图。 - No edit 消融: 保留其他接口设计,但拿掉专用编辑器,模型又要回到
sed、重定向、整文件改写这类 shell 式编辑方式。
结果差异很直接:SWE-agent ACI 在 SWE-bench Lite 上解决率为 18.0%,Shell-only 为 11.0%,只拿掉专用编辑器会降到 10.3%。这不是模型“更聪明了”,而是同一个模型看到的环境状态、可选动作和错误反馈变了。
含义: “环境行动”不是简单地把工具塞给模型,而是在设计模型能怎样看见环境、怎样修改环境、出错后怎样知道并恢复。接口设计越贴近模型的行动方式,Agent 越容易把一次次动作串成有效任务进展。
SWE-agent 这个例子主要证明的是“环境行动”这块责任,不等于它已经覆盖了 Harness 的全部四类责任。只改搜索、查看、编辑接口,仍然是在改 Harness 的 有效组成部分;完整 Harness 还要把运行闭环、上下文与状态、独立控制一起设计进去。所以判断一个机制时,先问它改变了模型看到的状态、能做的动作、反馈和恢复方式,还是改变了其他几类责任。
哪些概念和模块其实是 Harness 的一部分
有了范围,很多看起来“和 Harness 并列”的概念,其实都是它内部的组成部分。下面对每一个,只问三件事:它实际承担什么职责、影响什么效果、因此对应哪一层。
| 概念 / 术语 | 实际承担的职责 | 影响的效果 | 对应层 |
|---|---|---|---|
| Prompt Engineering | 把意图表达成模型能遵循的指令 | 模型理解与遵循指令的程度 | 指导与上下文 |
| Context Engineering | 每一步筛选进入窗口的信息 | 长任务里模型是否被噪声淹没 | 指导与上下文 → 任务运行与服务 |
| Agent Loop / ReAct | 在“推理—行动—观察”之间迭代 | 能否根据反馈持续推进而不空转 | 任务运行与服务 |
| Tools / MCP / ACP | 把外部能力标准化暴露给模型 | 模型能不能、以多大成本接到外部能力 | 行动与环境 |
| Sandbox / 容器 | 隔离执行、约束权限 | 副作用是否可控、是否安全 | 行动与环境 |
| Workspace / 文件 / 浏览器 | 提供可读写的执行空间 | 任务结果能否真正落到外部世界 | 行动与环境 |
| 状态 / Progress / Checkpoint / 记忆 | 在窗口之外保存进度与决策 | 跨会话、崩溃后能否接续而不重来 | 任务运行与服务 |
| Tests / Policy / Eval | 用外部证据判定完成、拦截风险 | “完成”是否可信、失败能否归因 | 质量与交付 |
| Agent Framework / SDK | 提供拼装上述部件的原语 | 决定搭建成本,本身不决定成败 | 跨层(实例化后才落地) |
结论:这些概念不是 Harness 的竞争对手,而是它在不同职责、不同层上的组成部分;每一个单独都不构成完整 Harness,但都是它的必要零件。一句话压下来:
- Prompt 在说“希望模型怎样做”;
- Loop 在说“模型什么时候继续想和行动”;
- Harness 在说“这件事在哪里运行、能做什么、状态怎样保存、结果怎样验收、出错怎样恢复”——前两者都是它的一部分。
范围的边缘:什么在里面,什么在外面
为了不让范围无限扩张,也标清楚三处边缘:
- 模型本身(L0):Harness 包裹它、调度它,但模型不是 Harness 的机器部件;
- 组织运营模式(L5):角色、流程、治理大多在外层;只有被编码成权限、审批、预算等运行策略时,才有一部分进入 Harness;
- Eval Harness(评测装置):它是“运行并给 Agent 打分”的同名邻近对象,和 Agent 执行业务任务时所用的 Harness 不是一回事。
既然 Prompt、上下文、循环、工具、状态、验证都是 Harness 的组成部分,那么“学习 Harness Engineering”就有了清楚的对象:把这几类责任各自的工程问题学透,再把它们组织成一个能持续运行的系统。 下一步,先看 Agent 任务在生命周期里会逼出哪些具体问题。
Agent 任务在生命周期里会逼出哪些具体问题
第一节给的是演变全景——责任为什么变多。这一节换成任务生命周期的视角,把“具体会遇到哪些问题”摆出来:这些问题正是下一节责任地图的来源。
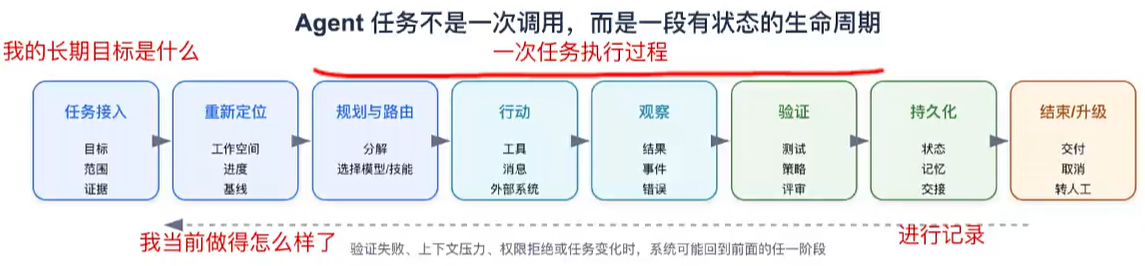
任务开始前:目标与环境没有被说清楚
| 常见问题 | 发生原因 | 系统保障 |
|---|---|---|
| 只写“做什么”,没有“什么算完成” | 验收条件留在人脑里 | 任务契约:意图、范围、验收证据、预算、升级条件 |
| Workspace 已有半成品,Agent 却按空项目理解 | 模型只看到局部上下文 | Orient:读取目录、版本、进度、基线测试与未完成列表 |
| 模型能看到工具,却不知道权限边界 | 身份和授权不是语言问题 | 运行时绑定身份、最小权限、网络和数据范围 |
| 一开始加载全部文档和工具 | 上下文噪声和选择负担过高 | 渐进式披露:按任务加载 Skills、知识和工具定义 |
行动过程中:非确定性决策遇到有副作用的现实系统
| 常见问题 | 发生原因 | 系统保障 |
|---|---|---|
| 选错工具或参数 | 工具语义不清、功能重叠 | 清晰命名、Schema、类型校验、可行动错误信息 |
| 超时后重复执行写操作 | Agent 不知道前一次是否部分成功 | 幂等键、状态查询、事务、重试策略、回滚 |
| 循环持续但没有进展 | 模型在局部反馈里重复同一策略 | step / time / cost budget、no-progress 检测、重新规划 |
| 试图执行高风险动作 | Prompt 里的“不要”不具强制力 | Policy gate、审批、只读/可逆/不可逆分级 |
| 工具输出淹没上下文 | 外部结果过大且未经整理 | 过滤、分页、截断、摘要与 Context manifest |
长任务与服务化阶段:聊天记录无法承担全部状态
| 常见问题 | 发生原因 | 系统保障 |
|---|---|---|
| Context reset 后重复劳动 | 决策和进度只存在于聊天历史 | Progress、Plan、Decision log、Checkpoint、Handoff |
| 进程崩溃后从头开始 | 环境与任务状态没有一致快照 | Workspace snapshot、可重放事件、恢复状态机 |
| 外部系统持续发来消息 | 单次 request/response 模型不适合异步会话 | 会话身份、消息收发、队列、并发控制与取消 |
| 流式输出和后台任务无法关联 | 运行过程没有统一事件模型 | Event stream、Run ID、状态事件、消费端协议 |
| 模型宣布完成但结果不完整 | 生成者同时充当验收者 | Tests、状态断言、独立 Reviewer、人工升级 |
| 失败无法复现和改进 | 只保存最终回复 | Trace、工具调用、环境快照、Harness 版本与 Eval 回归 |
从问题到一张责任地图:要掌握的关键模块
把上面这些问题按归属收拢,就得到一张责任地图。它不是某个产品的模块结构,而是从 Agent 任务生命周期抽象出来的;具体实现可以拆分或合并,关键是每项系统责任都有明确归属。它既是“运行时模块”,也是 Harness 工程要逐块掌握的关键能力——同一张图,两种读法。
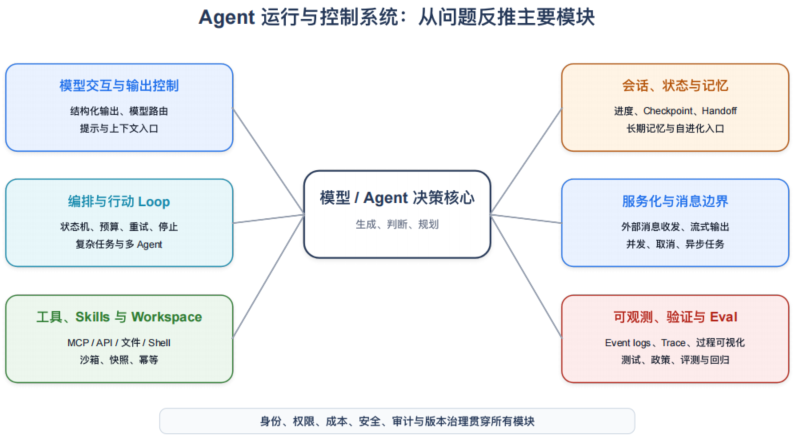
六块责任:是什么,解决什么问题
| 责任块 | 典型内容 | 主要解决的问题 | 对应层 |
|---|---|---|---|
| 模型交互与输出控制 | Structured Output、Function Calling、模型路由、上下文入口 | 把开放式生成转成系统可消费的决策与数据 | 指导与上下文 |
| 编排与行动 Loop | 状态机、路由、计划、重试、停止、子任务、多 Agent | 让任务按观察结果持续推进,同时保持边界和预算 | 任务运行与服务 |
| 工具、Skills 与 Workspace | MCP/API、Shell、文件、浏览器、Skill、Sandbox、快照 | 让模型获得行动力和过程知识,并把副作用限制在可控环境 | 行动与环境 |
| 会话、状态与记忆 | Session、Progress、Checkpoint、短期/长期记忆、Handoff | 在多轮、多会话和长任务中维持连续性 | 任务运行与服务 |
| 服务化与消息边界 | API/Worker、外部消息收发、Streaming、Cancel、Concurrency | 把 Agent 作为长期运行的信息系统能力对外提供 | 任务运行与服务 |
| 可观测、验证与 Eval | Event logs、Trace、解析与可视化、Tests、Policy、Eval、Regression | 还原过程、独立验收、归因失败、持续改进 | 质量与交付 |
多 Agent 与自我成长,是这张地图上的两条重要分支,而不是两个独立的新世界:
- 多 Agent 主要扩展“编排与行动 Loop、会话与状态、消息边界和验证”。Cognition 在《Don’t Build Multi-Agents》(2025)里给出两条务实经验:
- 共享完整的 agent 轨迹,而不只是把几条消息转发给子 Agent;
- 带副作用的行动本身包含隐含决策,多个 Agent 同时写就容易出现冲突决策。
- 用 Claude Code subagent 举例:子 Agent 通常负责调查和回答问题,不直接并行写代码。这里要带走的不是“永远不要多 Agent”,而是多 Agent 一旦进入系统,就要明确共享什么上下文、谁能写、谁来合并和验证。
- 自我成长 主要扩展“状态与记忆”和“可观测与 Eval”。Reflexion(NeurIPS 2023)展示了一条不更新权重的路径:让 Agent 把失败反思成语言、存入情景记忆,在后续尝试中改进决策——这正是“失败 → 回归”闭环的学术原型。
每个场景都要考虑 Harness,但不需要同样厚
一个简单的只读问答,本身已经有一层很薄的 Harness:消息历史、超时、格式和日志。一个需要跨系统写入、运行数小时、能够取消和恢复的 Agent,则需要明显更厚的运行与控制层。
完整 Harness 不是“每一层都塞满功能”,而是至少形成行动、状态、控制与验证的闭环,并且厚度与任务风险相匹配——任务持续多久、是否有不可逆副作用、路径是否需要动态探索、结果是否容易被独立验证、失败后的成本有多高,共同决定它该多厚。
![![[Pasted image 20260702173353.png]]](https://i-blog.csdnimg.cn/direct/5e723deb4bf44ad6bd44faf03e6179e9.png)
总结
- 起点是系统责任变化:模型从生成文字走向触发行动以后,工具、状态、权限、验证和恢复都变成系统责任;
- 先圈范围,再谈组成:Harness 的范围向下不含模型、向上不到组织,主体是 L1–L4 四层、四类责任;
- 相邻概念都是它的一部分:Prompt、上下文、循环、工具、状态、验证不是竞争对手,而是各自承担一类职责、对应某一层的零件;
- 关键证据是“模型固定、Harness 变,结果就变”:SWE-agent 的接口实验和 Anthropic 的长任务案例都指向同一点——任务表现是整套系统的属性;
- 责任地图就是要学的关键模块,厚度跟风险匹配:短、低风险、只读任务可以很薄;长任务、有副作用、服务化的 Agent 需要更完整的运行与控制层。
后续大家可以沿着本章的责任地图展开——它既是系统责任,也是逐块掌握的能力面:
| 责任 / 能力块 | 后续单元会展开 |
|---|---|
| 请求、输出与决策 | 结构化输出、模型路由、任务分解、反思与多步编排 |
| 工具、MCP 与 Skills | 工具调用回路、MCP 生态接入、Skills 撰写/选择/执行/校验 |
| 运行环境与安全边界 | Shell、文件、浏览器、Sandbox、权限、审批、幂等与风险分级 |
| 状态、记忆与协作 | Workspace、Checkpoint、长期记忆、自我成长、多 Agent 分发与回收 |
| 服务化、消息与用户入口 | API/Worker、流式输出、外部 IM、取消、并发与用户可见过程 |
| 观测、Eval 与治理 | Event logs、Trace、过程回放、Eval、成本、安全、审计与上线形态 |
其中自我成长和多 Agent 协作是两条重要分支,但不能代表全部 Harness 工程。更完整的看法是:先把模型请求变成可执行任务,再让任务接入工具和环境,保存状态、完成交接、服务化运行,并持续被观察、验证和治理。
模型提供基础智能;Harness 把这种智能接入系统,变成可以持续行动、被约束、被观察、被验证和被改进的任务能力。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)