大模型为什么会说话?一文图解 Transformer:从 Token 到 Agent 的底层引擎
这是一篇面向 Agent 开发者的 Transformer 入门长文。它不从公式堆起,而是从一次真实的大模型调用开始,逐层拆开:文本怎样变成 Token,Token 怎样互相“看见”,Decoder 为什么适合生成,Encoder 为什么适合检索,以及 RAG + Agent 为什么需要它们配合。
如果你已经会调用大模型接口,但总觉得 LLM 里面像一团雾,这篇文章的目标就是把雾拨开一点。
先给一句总纲:
大模型不是一次性写出完整答案,而是在给定上下文后,反复预测下一个 Token,并把新 Token 接回上下文。
Agent、RAG、工具调用、长期记忆、System Prompt,本质上都是围绕这件事展开:把更有用的信息放进上下文,让模型下一步预测更可靠。
下面我们按这条链路展开。
1. 先从一次大模型调用说起
在 Agent 系统中,我们通常不会只把用户问题直接扔给模型。一次完整请求里可能包含:
- 系统指令:规定模型身份、目标、禁止事项;
- 用户输入:当前这一次真正要解决的问题;
- 历史对话:让模型知道前文已经说过什么;
- Few-shot 示例:告诉模型希望它模仿什么格式;
- 工具定义:告诉模型能调用哪些外部能力;
- 工具结果:搜索、数据库、代码执行、API 返回的新信息;
- 检索内容:RAG 从知识库里找出的相关片段;
- 用户画像:偏好、长期记忆、业务背景。
这些内容看起来类型不同,但进入 LLM 之前都会合并成同一种东西:上下文。
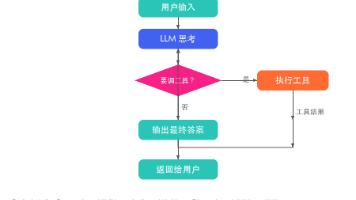
所以,Agent 并不是“让模型在运行时学会新知识”。它更像一个上下文调度器:
- 先把任务信息整理给模型;
- 让模型生成下一步;
- 如果下一步是工具调用,就执行工具;
- 把工具结果放回上下文;
- 再让模型继续生成。
外层看起来像规划、记忆、检索、行动,内层仍然是 Transformer 在做下一 Token 预测。
2. 文本进入模型前,会被拆成 Token
模型并不直接处理字符串。用户输入的中文、英文、标点、空格,都会先被 Tokenizer 转成离散符号。
以一句话为例:
今天状态不错,我们继续研究 Transformer。
它可能被切成:
今天 | 状态 | 不错 | , | 我们 | 继续 | 研究 | Transformer | 。
真实切分结果取决于具体 tokenizer。Token 不等于人类语法里的“词”,它可能是一个字、一个子词、一个标点,也可能是一段常见字符组合。
这里要分清三层:
- Token:文本被切出来的基本单位;
- Token ID:词表里的整数编号;
- Embedding:由 ID 查表得到的高维向量。
ID 只是编号,本身没有语义。真正进入模型计算的是向量。训练过程中,模型会把“用法接近”的 Token 映射到相近的向量区域。
另外,Transformer 还需要知道顺序。因为注意力机制本身只看一组向量,如果不额外提供位置信息,它无法区分“我吃鱼”和“鱼吃我”。
3. Transformer 的核心是注意力,不是“神秘理解力”
Transformer 论文的标题叫 Attention Is All You Need,它把注意力机制放到了架构中心。
注意力可以理解成一句话:
当前这个 Token 在更新自己的表示时,应该从上下文里的哪些 Token 借信息,分别借多少。
例如:
小明把钥匙放进抽屉,晚上他又把它拿了出来。
当模型处理“它”时,最应该关注的是“钥匙”,而不是“小明”或“晚上”。
经典写法是:
Attention(Q, K, V) = Softmax(QK^T / sqrt(d_k)) V
不用被公式吓到。它只是在做三步:
- Query 和 Key 做匹配,得到分数;
- Softmax 把分数变成权重;
- 按权重把 Value 汇总起来。
如果说 Embedding 让 Token 有了“坐标”,那么注意力就是让 Token 之间开始交换信息。
4. 多头注意力:模型同时从多个角度阅读
真实模型不会只做一套注意力。Multi-Head Attention 会把同一段文本投影到多个子空间,让多个注意力头并行工作。
你可以把它理解成多位读者同时看一段话:
- 一个读者关注语法结构;
- 一个读者关注实体指代;
- 一个读者关注前后因果;
- 一个读者关注格式和边界;
- 一个读者关注长距离依赖。
一个 Transformer Block 里通常还会有:
- 残差连接:保留原信息,帮助深层网络训练;
- LayerNorm:稳定每层输出的数值分布;
- 前馈网络 FFN:对每个位置做非线性变换;
- 多层堆叠:一层层形成更抽象的表示。
5. 一眼分清 Encoder 和 Decoder:谁能看全局,谁只能看过去
理解 Encoder 和 Decoder,不要先背结构图,先记住这个差异:
Encoder 通常能看完整输入。Decoder 在生成时只能看已经出现的前文。
Encoder 的双向注意力适合“读懂一整段”:
- 分类;
- 语义匹配;
- Embedding;
- 文档检索;
- rerank 重排;
- 信息抽取。
Decoder 的因果遮罩适合“从左到右写下去”:
- 聊天;
- 写作;
- 代码生成;
- 工具调用决策;
- Agent 的下一步行动规划。
生成任务不能偷看未来答案,所以今天多数通用对话模型都以 Decoder-only 为主。
再换一个更生活化的说法:
Encoder 像“阅卷老师”。它拿到的是完整卷面,可以从头到尾反复看,所以更适合判断“这段话是什么意思”“两段话像不像”“哪篇文档更相关”。它输出的通常不是一段新文字,而是一个更适合比较、分类、检索的语义表示。
Decoder 像“接龙写作者”。它只能看到已经写出来的内容,不能提前看到后面的答案,所以它每一步都要根据前文决定下一个 Token 写什么。聊天、写作、代码生成、工具调用参数生成,都天然符合这种“从左到右继续写”的模式。
所以在实际工程里,经常会看到这样的组合:Embedding / rerank 模型用 Encoder 思路做“找得准”,聊天模型用 Decoder 思路做“写得顺”。一个负责理解和筛选,一个负责表达和行动。
6. 三类常见 Transformer:理解型、生成型、转换型
Transformer 不是单一形态。按使用 Encoder 和 Decoder 的方式,常见三类。
Encoder-only:把文本读成表示
这类模型的目标不是长篇续写,而是得到高质量语义表示。BERT 是代表。很多 Embedding 模型、reranker 模型也属于这一类或借鉴这一类思想。
典型用途:
- “这两句话是不是语义相近”;
- “这篇文档是否匹配用户问题”;
- “这一段文本属于哪个类别”;
- “从候选答案中挑出最相关的一条”。
Decoder-only:根据前文继续生成
这类模型围绕自回归生成设计。给定前面的 Token,它预测下一个 Token,再把结果接回去继续预测。
GPT 系列是这个方向的代表。今天常见的对话模型、代码模型、Agent 主模型,大多都是 Decoder-only 或以它为核心。
典型用途:
- 多轮对话;
- 长文生成;
- 代码补全;
- 函数调用参数生成;
- Agent 任务分解和下一步决策。
Encoder-Decoder:读一个序列,写另一个序列
原始 Transformer 用于机器翻译,就是 Encoder-Decoder 架构。Encoder 读源语言,Decoder 生成目标语言。T5 也把多种 NLP 任务统一成 text-to-text。
典型用途:
- 翻译;
- 摘要;
- 改写;
- 输入输出结构差异较大的序列转换任务。
7. Decoder 是怎样“一个字一个字”写出回答的
大模型回答看起来像一段完整文字,其实内部是循环过程。
这里有三个概念很重要:
- Hidden State:模型内部的语义状态,还不是词;
- Logits:每个候选 Token 的未归一化分数;
- Softmax 概率:把分数转换成概率分布。
Temperature、top-p、top-k 等参数,影响的是从概率分布里怎么选 Token。
温度低,输出更稳,容易重复高概率表达。温度高,输出更发散,可能更有创造性,也可能更不稳定。
8. 训练和推理:一个改权重,一个用权重
很多人会把“把资料发给模型”和“让模型学会资料”混在一起。
普通 API 调用属于推理阶段。推理不会更新模型参数。
训练阶段会计算损失并通过反向传播更新权重。推理阶段只使用已经训练好的权重做前向计算。
所以,当你把一份企业文档塞进 Prompt,模型只是“这次看到了它”。下一次如果你不再提供这份文档,模型不会因为上次看过就自动记住。
长期记忆、知识库、RAG、数据库,本质上都是外部存储。它们让系统在下一次调用时重新把相关信息找出来,再放进上下文。
9. RAG + Agent 为什么常常是 Encoder 和 Decoder 协作
在实际项目里,单靠一个聊天模型往往不够。一个可靠的知识库 Agent,通常要把“找资料”和“写答案”拆开。
这个链路里的角色很清楚:
- Embedding 模型负责把问题和文档放进同一个语义空间;
- 向量库负责快速召回相似内容;
- reranker 负责把候选结果重新排序;
- Decoder LLM 负责阅读证据并生成回答;
- Agent loop 负责判断是否继续检索、调工具或结束任务。
这也是为什么“知识库问答效果差”不一定是聊天模型不够强。问题可能出在切分、召回、重排、证据组织、Prompt 模板、工具返回格式中的任一环。
10. 大模型和 Agent 到底有什么区别
很多人会把“大模型”和“Agent”混在一起。它们当然关系很近,但不是一回事。
大模型是能力内核:给它上下文,它负责理解输入、预测下一个 Token、生成回答或结构化意图。
Agent 是运行系统:它把大模型放进一个循环里,负责拆任务、补上下文、调用工具、读取工具结果、判断是否继续。
可以用一张对照表记住:
| 对比项 | 大模型 LLM | Agent |
|---|---|---|
| 核心职责 | 根据上下文生成下一个 Token | 围绕目标组织上下文并循环执行 |
| 输入 | Prompt、历史、检索片段、工具结果 | 用户目标、环境状态、工具集合、记忆系统 |
| 输出 | 文本、JSON、工具调用意图、代码片段 | 完整任务结果、行动链路、工具执行后的综合答案 |
| 是否会主动行动 | 不会,模型本身只是生成 | 会,通过外部程序执行搜索、API、文件、代码等工具 |
| 是否自动记住新知识 | 不会,普通推理不改参数 | 可以把信息写入外部记忆或知识库,下次再取出来 |
| 典型比喻 | 大脑里的语言预测器 | 带工具箱和工作流的执行者 |
所以,大模型解决的是“下一步该说什么”,而 Agent 解决的是“为了完成目标,下一步该做什么”。
这也是 Agent 开发的关键:不要只关心模型回答得漂不漂亮,更要关心它能不能拿到正确上下文、选择正确工具、把工具结果再组织回下一轮推理。
11. 把整条链路再压缩成一张图
最后,用一张 Mermaid 图把大模型应用里的关键层次串起来。
如果把技术细节都收起来,只保留工程视角,可以这样理解:
- Tokenizer 把人类语言变成模型能处理的单位;
- Embedding 把离散 Token 放进向量空间;
- 注意力让每个 Token 从上下文中提取相关信息;
- Encoder 适合把文本读懂、压成表示;
- Decoder 适合根据前文继续生成;
- Agent 通过循环补充上下文,让 Decoder 一步步完成复杂任务。
12. 几个常见误解
误解一:大模型把资料看一遍就永久学会了
不会。普通推理只改变输入上下文,不改变模型权重。除非做训练、微调或把资料写入外部记忆系统,否则它不会永久进入模型本体。
误解二:上下文越长,答案一定越好
不一定。长上下文会增加成本,也会带来噪声。优秀的 RAG 系统不是把所有资料塞给模型,而是把最相关、最可信、最结构化的证据放进去。
误解三:Embedding 模型和聊天模型可以互相替代
通常不适合。Embedding 模型擅长语义匹配,聊天模型擅长生成。一个负责“找得准”,一个负责“讲得清”。
误解四:Agent 的智能全部来自工具数量
工具多不等于 Agent 强。关键在于模型是否能读懂当前状态,是否能选择正确工具,工具结果是否能以清晰格式回到上下文。
13. 结尾:理解 Transformer 后,再看 Agent 会清楚很多
Transformer 不是魔法盒子。它的底层路线可以简化成:
文本 -> Token -> 向量 -> 注意力 -> 隐藏状态 -> Logits -> 概率 -> 下一个 Token
Agent 的路线可以简化成:
组织上下文 -> 让模型生成下一步 -> 执行工具或检索 -> 把结果放回上下文 -> 继续
这两条路线合在一起,就是今天大模型应用的基础形态。
你不一定需要记住所有公式,但至少应该建立这个判断:
应用层做得好不好,很大程度取决于你能不能把正确的信息,在正确的时机,以正确的结构交给模型。
这就是 Prompt、RAG、Memory、Tool Calling、Agent Loop 背后的共同逻辑。
参考图解资料
如果你想继续看更成熟的可视化图解,可以参考这些资料。本文的图解重排思路,主要借鉴它们“逐步展开、少讲公式、先讲数据流”的表达方式:
- Jay Alammar, The Illustrated Transformer
- Harvard NLP, The Annotated Transformer
- Lilian Weng, Attention? Attention!
- Hugging Face NLP Course, Transformer models
- Polo Club of Data Science, Transformer Explainer
参考资料
- Vaswani et al., 2017, Attention Is All You Need
- Devlin et al., 2018, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Radford et al., 2018, Improving Language Understanding by Generative Pre-Training
- Raffel et al., 2019, Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- Hugging Face, Summary of the tokenizers
- OpenAI Docs, Tokens
- Harvard NLP, The Annotated Transformer

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)