AI 生产力工具设计:从模型调用到效率闭环的工程化实践
AI 生产力工具设计:从模型调用到效率闭环的工程化实践
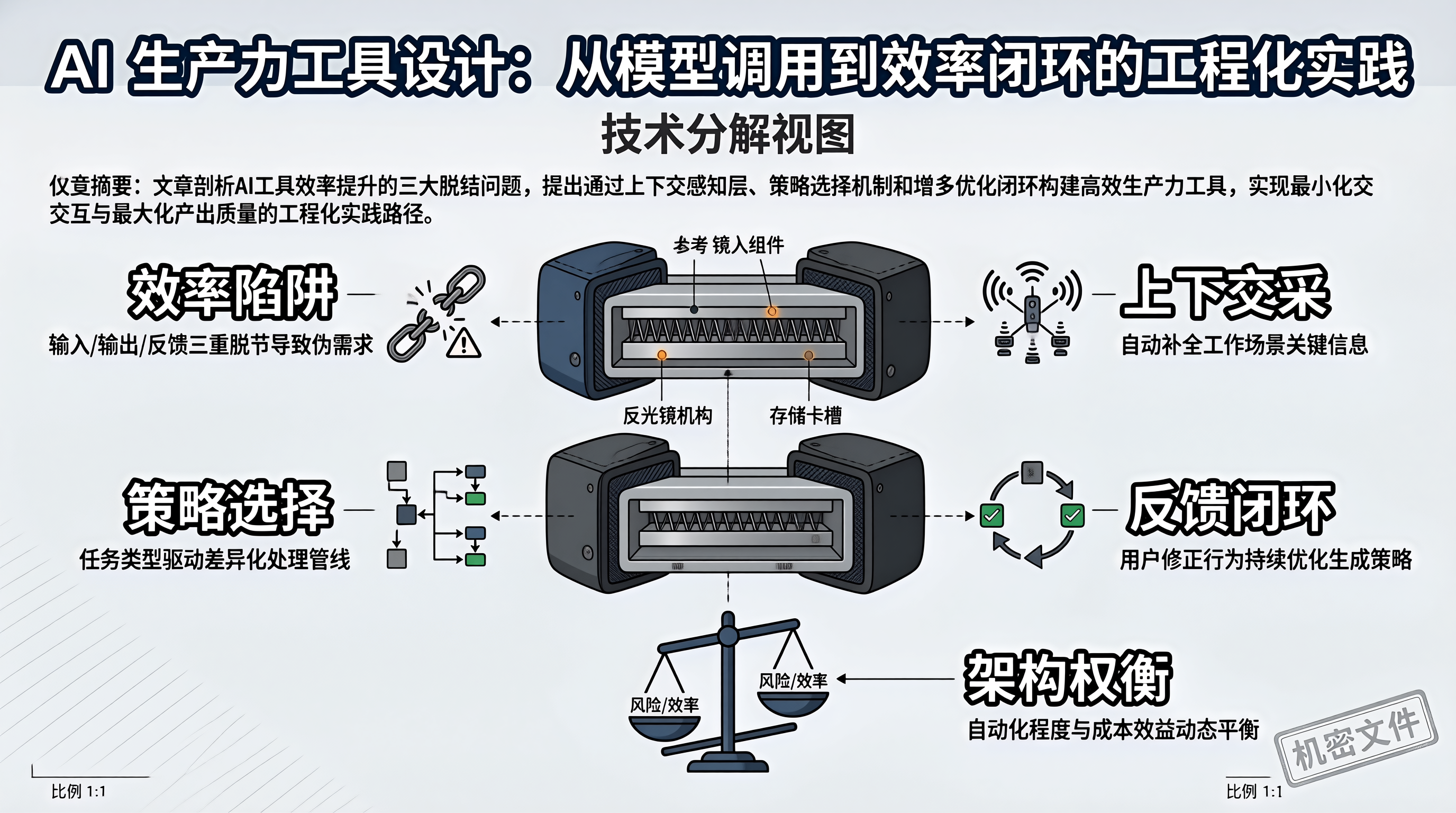
一、效率工具的伪需求陷阱:AI 加持不等于生产力提升
AI 生产力工具市场正在经历一场泡沫。大量工具的卖点停留在"接入 GPT-4"或"支持多轮对话",但用户使用后的真实反馈往往是:工具确实能生成内容,但生成的内容需要大量人工修正,总体效率反而不如手动完成。这不是 AI 能力不足,而是工具设计没有触及效率提升的本质。
AI 生产力工具的核心痛点在于三个脱节。第一,输入与意图脱节:用户需要花大量时间编写 Prompt 来描述需求,这个"描述需求"的过程本身就消耗了效率。第二,输出与场景脱节:AI 生成的内容是通用的,但用户需要的是特定格式的、可直接使用的输出。第三,反馈与优化脱节:用户修正了 AI 的输出,但工具没有从修正中学习,下次生成同样的问题。
真正提升效率的 AI 工具,应该遵循一个原则:最小化人机交互次数,最大化单次交互的产出质量。用户只需要提供最少的必要信息,工具负责补全上下文、选择策略、生成可直接使用的输出。
二、AI 生产力工具架构:上下文感知与策略选择
一个高效的 AI 生产力工具,其核心不是模型本身,而是围绕模型构建的上下文感知层和策略选择层。上下文感知层负责理解用户当前的工作场景,自动补全必要信息;策略选择层负责根据任务类型选择最优的处理流程。
flowchart TD
A[用户触发操作] --> B[上下文采集器]
B --> C[当前文件内容]
B --> D[项目结构信息]
B --> E[最近操作历史]
B --> F[用户偏好配置]
C --> G[上下文融合器]
D --> G
E --> G
F --> G
G --> H[策略选择器]
H --> I{任务类型判断}
I -- 代码补全 --> J[局部上下文策略]
I -- 文档生成 --> K[全局结构策略]
I -- 重构建议 --> L[依赖分析策略]
I -- 测试生成 --> M[接口推断策略]
J --> N[Prompt 组装器]
K --> N
L --> N
M --> N
N --> O[模型调用]
O --> P[输出后处理]
P --> Q[格式适配]
P --> R[差异高亮]
P --> S[操作建议]
Q --> T[用户确认/修正]
R --> T
S --> T
T --> U[反馈采集]
U --> V[偏好更新]
V --> F
style B fill:#e3f2fd
style H fill:#fff3e0
style P fill:#e8f5e9
上下文采集:自动补全用户未表达的信息
上下文采集器的目标是:用户只说"帮我写个测试",工具就能自动推断出要测试哪个函数、函数的输入输出类型、项目中使用的测试框架,然后生成可直接运行的测试代码。这需要工具具备对项目结构和代码语义的理解能力。
策略选择:不同任务用不同管线
代码补全只需要当前文件和光标附近的上下文,使用局部上下文策略即可;文档生成需要理解整个模块的结构和接口,需要全局结构策略;重构建议需要分析函数的调用链和依赖关系,需要依赖分析策略。不同策略对应不同的上下文范围和 Prompt 模板,避免所有任务都用同一种方式处理。
三、生产级 AI 工具实现:上下文感知与增量优化
上下文采集器
// tools/contextCollector.ts
// 上下文采集器:自动收集用户当前工作环境的信息
// 核心原则:只采集与当前任务相关的上下文,避免 Token 浪费
interface WorkContext {
// 当前文件的完整内容
currentFile: FileInfo;
// 与当前文件有依赖关系的文件(最多 5 个)
relatedFiles: FileInfo[];
// 项目的包管理信息(框架、库版本)
projectMeta: ProjectMeta;
// 用户最近 10 次操作的摘要
recentActions: ActionSummary[];
// 用户的偏好配置
userPreferences: UserPreferences;
}
interface FileInfo {
path: string;
content: string;
// 文件的语义摘要,用于减少 Token 消耗
summary: string;
language: string;
}
export class ContextCollector {
// 采集与当前任务相关的上下文
async collect(trigger: UserTrigger): Promise<WorkContext> {
const currentFile = await this.readCurrentFile(trigger.filePath);
// 根据任务类型决定采集范围
const scope = this.determineScope(trigger.type);
const relatedFiles = await this.findRelatedFiles(
trigger.filePath,
scope.maxRelatedFiles
);
const projectMeta = await this.readProjectMeta();
const recentActions = this.getRecentActions(trigger.userId);
const userPreferences = await this.loadPreferences(trigger.userId);
return {
currentFile,
relatedFiles,
projectMeta,
recentActions,
userPreferences,
};
}
// 根据任务类型确定上下文采集范围
// 避免所有任务都采集全量上下文,浪费 Token
private determineScope(taskType: TaskType): ContextScope {
const scopes: Record<TaskType, ContextScope> = {
'code-completion': {
maxRelatedFiles: 2, // 补全只需少量上下文
maxContentLength: 2000, // 限制单文件内容长度
includeProjectMeta: false,
},
'doc-generation': {
maxRelatedFiles: 5,
maxContentLength: 5000,
includeProjectMeta: true,
},
'refactor-suggestion': {
maxRelatedFiles: 10, // 重构需要更广的依赖分析
maxContentLength: 8000,
includeProjectMeta: true,
},
'test-generation': {
maxRelatedFiles: 3,
maxContentLength: 4000,
includeProjectMeta: true, // 需要知道测试框架
},
};
return scopes[taskType];
}
// 查找与当前文件有依赖关系的文件
private async findRelatedFiles(
filePath: string,
maxCount: number
): Promise<FileInfo[]> {
// 基于 import 语句分析依赖关系
// 优先选择被当前文件直接 import 的文件
const imports = await this.analyzeImports(filePath);
// 对依赖文件按相关性排序
const ranked = imports
.sort((a, b) => b.importCount - a.importCount)
.slice(0, maxCount);
return Promise.all(
ranked.map(async (imp) => ({
path: imp.path,
content: await this.readFileContent(imp.path),
summary: await this.generateSummary(imp.path),
language: this.detectLanguage(imp.path),
}))
);
}
// 生成文件摘要:将完整文件压缩为语义描述
// 用于在 Token 预算有限时提供关键信息
private async generateSummary(filePath: string): Promise<string> {
const content = await this.readFileContent(filePath);
// 提取导出的函数签名、类型定义和注释
const exports = this.extractExports(content);
return exports.map((e) => `${e.type} ${e.name}: ${e.signature}`).join('\n');
}
private async readCurrentFile(path: string): Promise<FileInfo> {
return { path, content: '', summary: '', language: '' };
}
private async readProjectMeta(): Promise<ProjectMeta> {
return { framework: '', dependencies: {} };
}
private getRecentActions(userId: string): ActionSummary[] {
return [];
}
private async loadPreferences(userId: string): Promise<UserPreferences> {
return { preferredStyle: '', language: 'zh-CN' };
}
private async analyzeImports(filePath: string): Promise<any[]> {
return [];
}
private async readFileContent(path: string): Promise<string> {
return '';
}
private detectLanguage(path: string): string {
return 'typescript';
}
private extractExports(content: string): any[] {
return [];
}
}
增量优化引擎:从用户修正中学习
// tools/incrementalOptimizer.ts
// 增量优化引擎:记录用户对 AI 输出的修正,优化后续生成策略
// 核心思想:每次用户修正都是一次隐式的反馈信号
interface UserCorrection {
taskId: string;
// AI 的原始输出
originalOutput: string;
// 用户修正后的版本
correctedOutput: string;
// 修正的类型分类
correctionType: 'format' | 'style' | 'logic' | 'accuracy';
// 修正的粒度:微调还是重写
granularity: 'minor' | 'major';
}
export class IncrementalOptimizer {
private correctionHistory: UserCorrection[] = [];
// 记录用户的修正行为
recordCorrection(correction: UserCorrection): void {
this.correctionHistory.push(correction);
// 当积累足够的修正数据时,触发偏好更新
if (this.correctionHistory.length % 10 === 0) {
this.updatePreferences();
}
}
// 基于修正历史更新用户偏好
private updatePreferences(): void {
// 统计修正类型的分布
const typeDistribution = this.countByType();
// 如果用户频繁修正格式问题,在 Prompt 中强化格式约束
if ((typeDistribution.format ?? 0) > 5) {
this.enhanceFormatConstraint();
}
// 如果用户频繁修正代码风格,提取风格偏好
if ((typeDistribution.style ?? 0) > 3) {
this.extractStylePreferences();
}
}
// 将修正历史转化为 Prompt 中的约束条件
buildCorrectionHints(): string {
if (this.correctionHistory.length === 0) return '';
// 提取最近 5 次修正的模式
const recentCorrections = this.correctionHistory.slice(-5);
const patterns = this.extractPatterns(recentCorrections);
if (patterns.length === 0) return '';
return `基于用户历史偏好的约束:\n${patterns.map((p) => `- ${p}`).join('\n')}`;
}
private countByType(): Record<string, number> {
const counts: Record<string, number> = {};
for (const c of this.correctionHistory) {
counts[c.correctionType] = (counts[c.correctionType] ?? 0) + 1;
}
return counts;
}
private extractPatterns(corrections: UserCorrection[]): string[] {
// 从修正中提取模式化的偏好
// 例如:用户总是将单引号改为双引号 → 偏好双引号
return [];
}
private enhanceFormatConstraint(): void {
// 在后续的 Prompt 中增加格式约束的权重
}
private extractStylePreferences(): void {
// 从修正中提取代码风格偏好
}
}
四、AI 生产力工具的架构权衡:自动化程度与用户控制权的平衡
预判 vs 确认:工具可以预判用户意图并自动执行,也可以给出建议让用户确认。完全自动化效率最高,但出错时影响也最大;每步确认最安全,但交互次数过多会降低效率。合理的策略是:低风险操作(如代码格式化)自动执行,高风险操作(如文件删除、数据库写入)必须确认。
上下文窗口与成本:上下文越丰富,模型理解越准确,但 Token 消耗也越大。对于频繁触发的操作(如代码补全),应该使用最小的有效上下文;对于低频但高价值的操作(如架构建议),可以投入更多上下文。上下文预算应该根据操作频率和单次价值来分配。
本地模型 vs 云端模型:本地模型(如 Ollama 运行的 CodeLlama)延迟低、无 API 成本,但能力有限;云端模型能力强,但有延迟和成本。对于实时性要求高的场景(如代码补全),本地模型是更优选择;对于需要深度推理的场景(如架构分析),云端模型不可替代。
反馈闭环的冷启动问题:增量优化引擎需要积累足够的修正数据才能发挥作用。新用户的前几次使用体验,完全取决于默认策略的质量。因此,默认策略必须基于大量用户的聚合数据来设计,而非从零开始。
五、总结
AI 生产力工具的核心竞争力,在于最小化人机交互次数、最大化单次交互的产出质量。落地路线如下:
第一,构建上下文感知层。自动采集用户当前的工作环境信息,包括文件内容、项目结构、操作历史和偏好配置。用户只需要提供最少的必要信息,工具负责补全上下文。
第二,实施策略选择机制。不同任务类型使用不同的上下文范围和 Prompt 模板。代码补全用局部上下文,文档生成用全局结构,重构建议用依赖分析。避免所有任务都用同一种方式处理。
第三,建立增量优化闭环。记录用户对 AI 输出的修正行为,从中提取偏好模式,优化后续生成策略。每次修正都是一次隐式反馈,让工具在使用中持续进化。
第四,根据操作频率和风险等级选择自动化程度。低风险高频操作自动执行,高风险低频操作必须确认。自动化程度的设定应该基于实际出错率和修正成本,而非主观判断。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)