用了 lark-cli 一个月,AI 操作飞书再也没出过岔子——说说真实体验
飞书 CLI 是什么,为什么 45 天拿到 1 万 Star
larksuite/cli 是飞书团队今年 3 月 28 日开源的官方 CLI 工具,GitHub 当前 star 数 10.9k(截至 2026-05-16 实测),最新版本 v1.0.32,Go 语言开发,通过 npm 分发,MIT 协议。
一句话描述它的定位:专为人类和 AI Agent 双重设计的飞书命令行工具。
「专为 AI 设计」这几个字是认真的,不是蹭热度。它配套了 24 个结构化 AI Agent Skills,可以直接通过 npx skills add larksuite/cli -y -g 安装到 Claude Code 或 Cursor 里,让 AI 工具直接读懂怎么操作飞书的各个模块,而不是靠 AI 自己从 --help 里猜。
覆盖范围上:17 个核心业务域,200+ 精心封装命令,底层可调用 2500+ 飞书 OpenAPI。
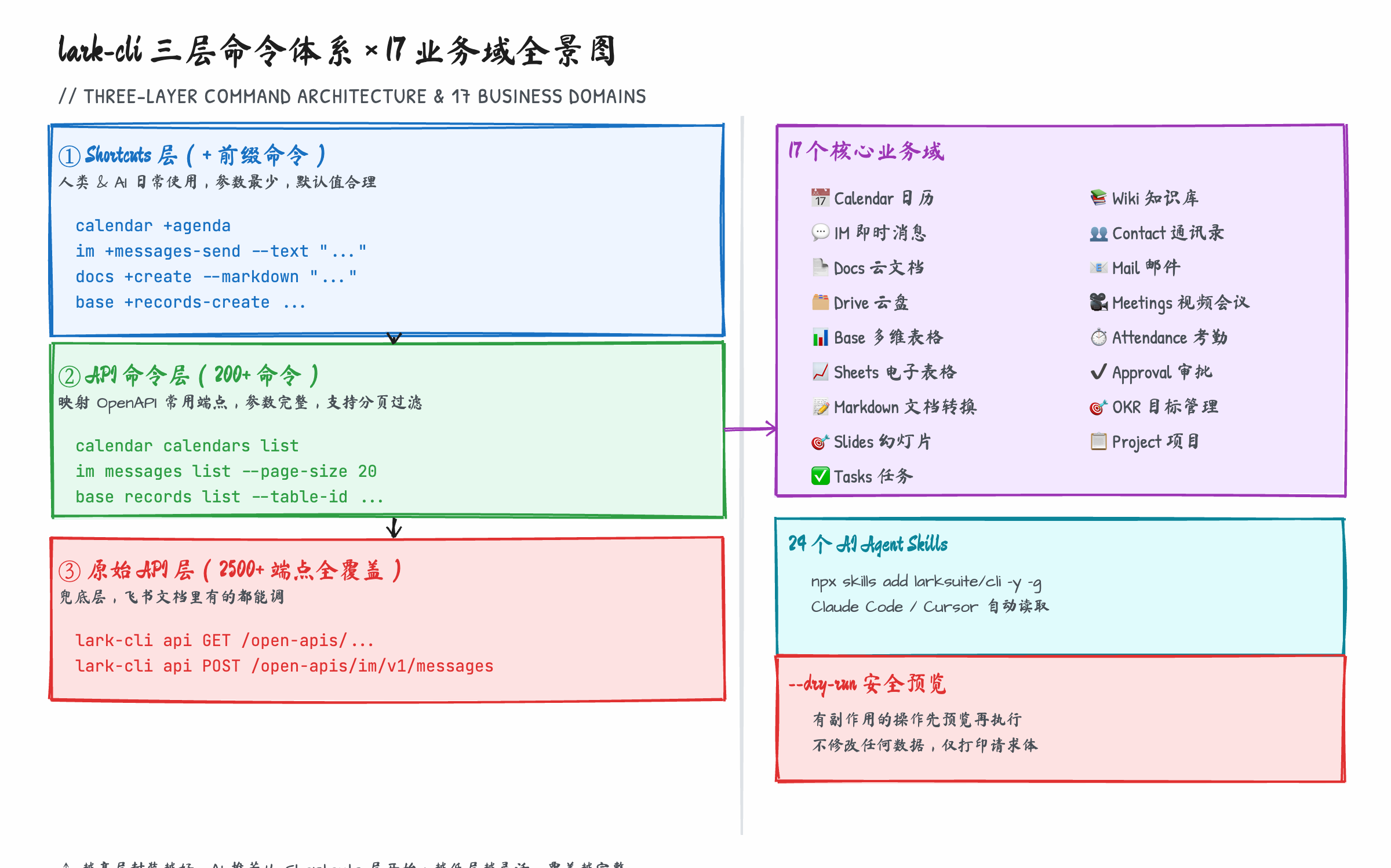
图:lark-cli 三层命令体系——Shortcuts(+前缀)→ API 命令层 → 原始 API 层,覆盖消息、文档、日历等 17 个业务域
为什么能快速拿到 1 万 star?
中文职场 AI 工具这个赛道,之前一直缺一个像样的「飞书 × AI Agent」基础设施。钉钉没有官方 CLI,企业微信的机器人 API 裸调体验差,Notion AI 又是英文产品。飞书团队这次直接出手,把 2500+ 个 API 包成了 200+ 条能让人和 AI 直接用的命令,还附带了 Skills 集成——这个组合在 3 月底发出来,正好踩在 Claude Code 和 MCP 生态爆发的节点上。
涨粉不是靠噱头,靠的是真实填补了一个空缺。
10 分钟装好并跑通第一条命令
环境准备
本文环境: macOS / zsh / Node.js 18+(
node --version验证)
Windows 用户:PowerShell 同样支持,但 JSON 参数格式有细节差异,文末 FAQ 有说明
前置确认:
- 已有飞书账号,能正常登录
- Node.js ≥ 16(
node --version验证) - 飞书开放平台有应用或能创建(下面会引导)
安装 lark-cli
npx @larksuite/cli@latest install
这条命令会把 lark-cli 安装到全局,安装完成后验证:
lark-cli --version
预期输出类似:
lark-cli version 1.0.32
初始化应用凭证
lark-cli 需要一个飞书应用的 App ID 和 App Secret 来调用 API。如果你没有现成的应用,去飞书开放平台新建一个「企业自建应用」,5 分钟能搞定。
lark-cli config init
这条命令会进入交互式引导,依次要求输入:
- App ID(
cli_开头的字符串) - App Secret(一长串字符)
- 应用所在飞书域名(通常是默认值直接回车)
踩坑记录:如果你的飞书是独立域名(非 feishu.cn),初始化时要手动改域名,不能直接回车。公司用飞书的同学留意一下。
授权登录
lark-cli auth login --recommend
--recommend 参数会自动勾选常用权限范围(消息、日历、文档等),省去逐个确认的麻烦。执行后会弹出浏览器授权页,用你的飞书账号登录,点授权。
登录完成后验证状态:
lark-cli auth status
看到 ✓ Logged in as [你的名字] 就说明全部搞定了。
第一条命令:查今天的日程
lark-cli calendar +agenda
预期输出:今天的会议列表,包含时间、标题、参与者。
如果日历是空的,说明命令本身跑通了,只是今天没有安排。可以加 --next-day 查明天的:
lark-cli calendar +agenda --next-day
注意 + 前缀:这是 lark-cli 的 Shortcuts 层——+agenda 是精心封装的快捷命令,参数少、默认值合理、输出可读。和原始 API 命令相比,这是推荐给日常使用的入口。
三层命令体系:为什么要设计这么复杂
很多人装好之后就开始用 + 前缀命令,用着用着发现有些场景满足不了,然后不知道该怎么办。
理解这个三层结构,能让你在碰壁的时候知道去哪里找答案。
第一层:Shortcuts(+ 前缀)
面向日常使用,参数最少,默认值最合理。覆盖 80% 的高频场景。例:
lark-cli calendar +agenda
lark-cli im +messages-send --chat-id "oc_xxx" --text "周报已提交"
lark-cli docs +create --title "5月站会纪要" --markdown "# 5月16日站会\n..."
第二层:API 命令
映射飞书 OpenAPI 里约 100 个最常用的端点,参数完整,支持分页、过滤等精细控制。当 Shortcuts 不够用时用这层:
lark-cli calendar calendars list
lark-cli im messages list --chat-id "oc_xxx" --page-size 20
第三层:原始 API(lark-cli api)
直接调用任意飞书 OpenAPI 端点,完全覆盖 2500+ 接口。这是兜底层,理论上飞书文档里有的操作这里都能做:
lark-cli api GET /open-apis/calendar/v4/calendars
lark-cli api POST /open-apis/im/v1/messages --body '{"receive_id":"oc_xxx","msg_type":"text","content":"{\"text\":\"hello\"}"}'
对 AI 来说,这个分层设计很聪明。AI 在用 Shortcuts 层的时候,错误率最低,因为封装好的参数少,选错的可能性小。当 Shortcuts 不够用时,AI 可以降级到 API 命令层,最后才用原始 API——这个梯度和人类的使用习惯一样。
核心场景演示
发消息(IM)
发消息是最高频的场景,也是最怕 AI 搞错的场景。
# 发送文本消息到某个群
lark-cli im +messages-send \
--chat-id "oc_a0553eeea09c272383c7c87de0b53f87" \
--text "今天的代码审查会议推迟到 16:30,请注意"
# 发送 Markdown 格式消息(飞书支持富文本)
lark-cli im +messages-send \
--chat-id "oc_xxx" \
--msg-type interactive \
--text "**会议提醒**\n\n📅 时间:今天 16:30\n📍 地点:6 楼会议室 A"
chat-id 怎么拿?飞书 PC 端打开某个群,URL 里有 oc_ 开头的那串字符就是。
踩坑记录:
--chat-id要填群的 ID,不是群名称。很多人第一次用会把群名称直接填进去,然后报「找不到会话」的错。
查询和创建日历事件
# 查今天日程(最常用)
lark-cli calendar +agenda
# 查指定日期范围
lark-cli calendar +agenda --start-date 2026-05-16 --end-date 2026-05-20
# 输出为 CSV,方便导入其他工具
lark-cli calendar +agenda --format csv > this-week-agenda.csv
文档操作
# 创建一个新文档,用 Markdown 内容初始化
lark-cli docs +create \
--title "2026-05-16 周报" \
--markdown "# 本周进展\n\n## 完成事项\n- 功能 A 上线\n- Bug 修复 3 个\n\n## 下周计划\n- 功能 B 开发"
# 读取某篇文档内容(需要文档 token)
lark-cli docs content get --doc-token "doxcnXXXXXX"
多维表格(Base)
多维表格是飞书里最复杂的模块,也是 AI 最容易出错的地方。
# 查询某张表的记录
lark-cli base +records-list \
--app-token "bascnXXXXXX" \
--table-id "tblXXXXXX" \
--page-size 20
# 新增一条记录
lark-cli base +records-create \
--app-token "bascnXXXXXX" \
--table-id "tblXXXXXX" \
--fields '{"任务名称": "接入 lark-cli", "负责人": "码哥", "状态": "进行中"}'
多维表格操作最好配合 --dry-run 使用,下一节重点讲这个。
dry-run:AI 时代的「后悔药」
这是整篇文章最想讲的一个机制。
背景:AI 操作办公系统最大的心理障碍是「不可逆」。发出去的消息收不回来,写错的多维表格数据可能被别人看到,误操作日历事件可能影响团队。这种不可逆性,让很多人在 AI 真正能帮到他们的场景里踩了刹车。
lark-cli 的 --dry-run 解决的就是这个问题。
dry-run 的工作原理
加上 --dry-run 参数后,lark-cli 会:
- 完整构建 API 请求(包括认证 token、请求体、目标端点)
- 把请求的所有参数以可读格式打印到终端
- 不发送任何实际请求,不改变任何数据
lark-cli im +messages-send \
--chat-id "oc_a0553eeea09c272383c7c87de0b53f87" \
--text "今天的站会已结束,会议纪要见文档链接" \
--dry-run
输出类似:
[DRY RUN] POST /open-apis/im/v1/messages
receive_id_type: chat_id
receive_id: oc_a0553eeea09c272383c7c87de0b53f87
msg_type: text
content: {"text":"今天的站会已结束,会议纪要见文档链接"}
→ 以上请求未执行。确认无误后去掉 --dry-run 重新运行。
你可以在这个输出里核对:群 ID 对不对、消息内容对不对、API 端点对不对——全部确认后再去掉 --dry-run 执行真实操作。
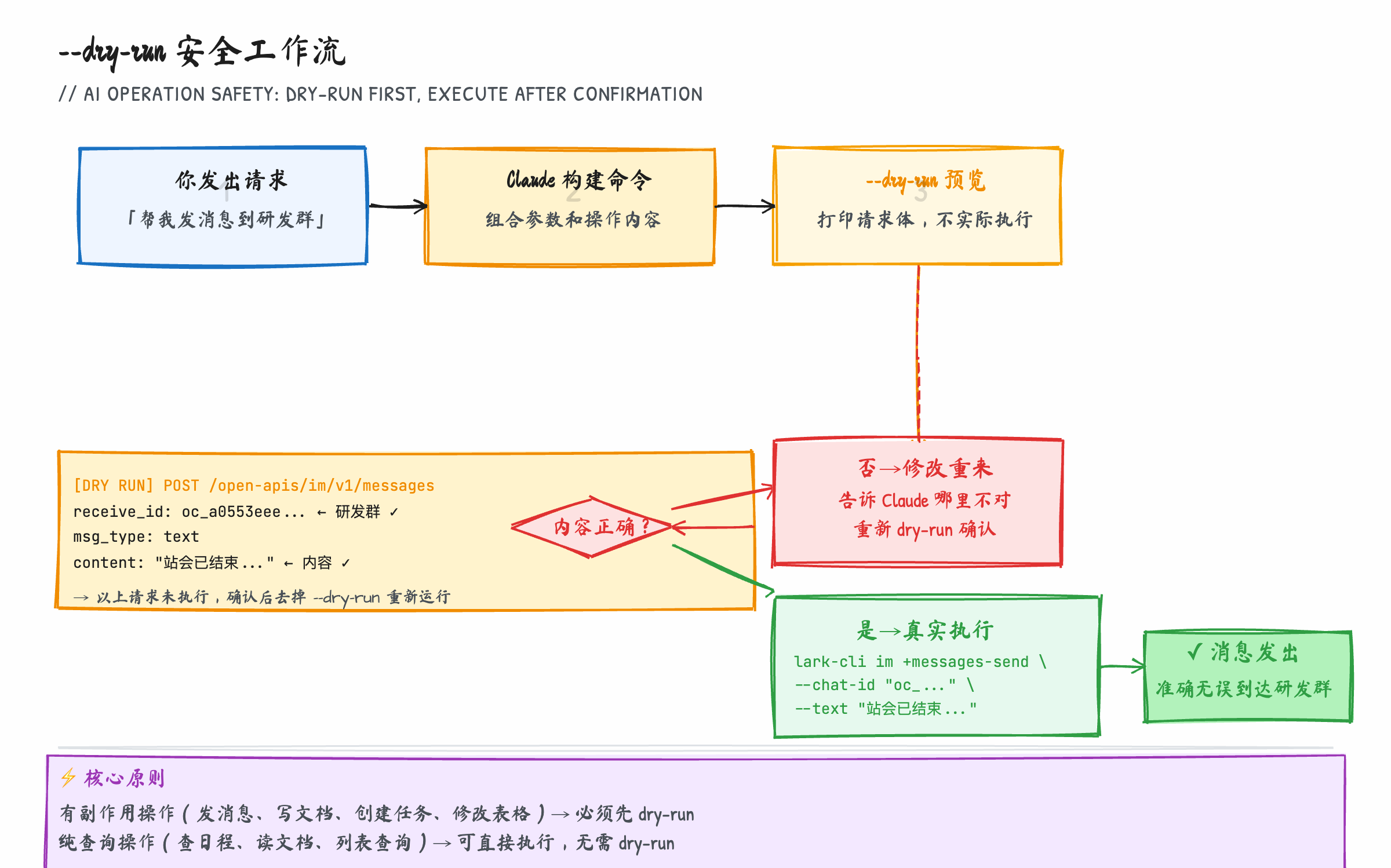
图:dry-run 工作流——AI 生成命令后先预览,人确认内容无误再执行,适合所有有副作用的操作
什么时候必须用 dry-run
不是所有命令都有副作用,查询操作不需要 dry-run。以下这几类必须先 dry-run:
| 操作类型 | 典型命令 | 为什么必须 dry-run |
|---|---|---|
| 发送消息 | im +messages-send |
发出去收不回,群发更是灾难 |
| 创建/修改文档 | docs +create |
内容错了所有人都能看到 |
| 多维表格写入 | base +records-create |
数据格式错了可能影响整个表 |
| 日历事件创建 | calendar events create |
发邀请给错误的人是社交事故 |
| 任务创建/修改 | task +create |
指派给了错误负责人 |
查询类操作(+agenda、base +records-list、docs content get)不改变任何数据,不需要 dry-run。
在 AI 工作流里使用 dry-run
当你让 Claude Code 帮你操作飞书时,正确的工作流是:
你:帮我把今天的站会纪要发到"后端研发群",内容是 [xxx]
Claude:我来构建这条发送命令,先 dry-run 给你确认一下
[Claude 执行 lark-cli im +messages-send ... --dry-run]
输出:
receive_id: oc_a0553eeea09c272383c7c87de0b53f87 ← 后端研发群 ✓
content: "今天站会纪要:..." ← 内容 ✓
你:确认,发送
Claude:[去掉 --dry-run 执行真实发送]
这个流程的关键在:Claude 不应该跳过 dry-run 直接执行有副作用的操作。如果你发现 Claude 在没有确认的情况下直接发消息,可以在 Claude Code 的 CLAUDE.md 里加一条 rule:「调用 lark-cli 执行任何写入操作前,必须先 dry-run 并等待我确认」。
与 Claude Code 集成:Skills 是核心
安装 CLI 只是第一步。让 Claude Code 真正「懂飞书」,需要安装配套的 AI Agent Skills。
安装 Skills
npx skills add larksuite/cli -y -g
这条命令会把 24 个飞书 Skills 安装到你的全局 Claude Code Skills 目录。安装完成后重启 Claude Code,让它重新加载 Skills 定义。
Skills 做了什么
每个 Skill 文件(SKILL.md)里描述了:
- 这个模块有哪些可用命令
- 每个命令的参数说明和典型使用场景
- 常见报错的处理方式
- 什么时候用 user identity(以你自己的身份操作),什么时候用 bot identity(以应用 bot 的身份操作)
24 个 Skills 覆盖的核心模块:
lark-shared:认证、配置、身份切换(这是「总闸」)lark-calendar:日历和日程管理lark-im:消息发送和群聊管理lark-doc:文档读写和 Markdown 转换lark-drive:云盘文件管理lark-base:多维表格操作lark-sheets:电子表格lark-task:任务管理lark-mail:邮件lark-wiki:知识库- ... 以及会议、审批、考勤、OKR 等

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)