不再依赖 OpenAI:开源 AI 技术栈如何让你构建完全自主的智能应用
不再依赖 OpenAI:开源 AI 技术栈如何让你构建完全自主的智能应用
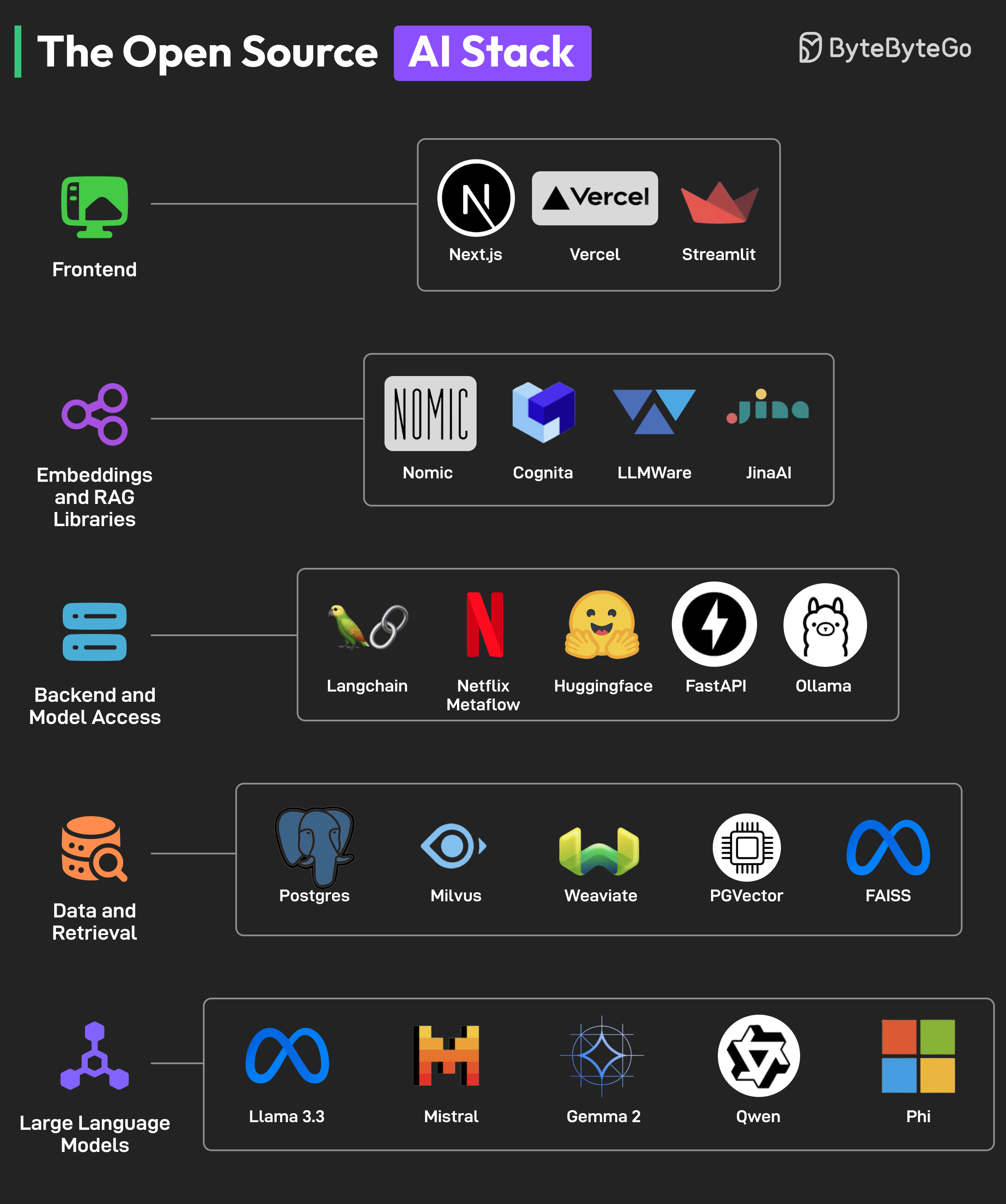
一张来自 ByteByteGo 的技术全景图,揭示了从 LLM 到前端的五层开源生态,正在重新定义我们构建 AI 应用的方式。
引言:开源 AI 的"安卓时刻"
2023 年,当 ChatGPT 以摧枯拉朽之势席卷全球时,大多数人认为构建 AI 应用的门槛高不可攀——只有拥有数千张 GPU 集群的科技巨头才有资格入场。然而,开源社区给出了截然不同的答案。
短短两年时间,一个完整、成熟、可替代商业闭源方案的开源 AI 技术栈已经悄然成型。从底层的大语言模型到用户交互界面,每一层都有多个活跃的开源项目在竞争与协作中快速进化。这张来自 ByteByteGo 的开源 AI 技术栈全景图,正是这一生态的完美缩影。
五层架构,十余个核心项目,零授权费用。 这不是未来的愿景,而是今天每一位开发者都能触手可及的现实。
本文将逐层拆解这张技术图谱,带你理解每一层的作用、核心项目的差异,以及它们如何协同工作,最终让你能够独立构建不依赖任何商业 API 的完全自主的智能应用。
第一层:大语言模型层(LLM)——智能应用的大脑
技术栈的最底层,也是整个架构的核心,是大语言模型层。如果说一个 AI 应用是一位专业人士,那么 LLM 就是它的大脑——决定了它的知识储备、推理能力和表达水平。
为什么开源 LLM 已经可用?
开源 LLM 的发展速度超出了所有人的预期。Meta 发布的 Llama 系列模型打破了"大模型只能由巨头训练"的神话,而 Mistral、Google、微软和阿里巴巴的相继入场,则让开源模型在性能上快速逼近甚至部分超越了商业模型。
让我们看看图中列出的五大开源模型家族:
| 模型 | 开发方 | 核心特点 | 适用场景 |
|---|---|---|---|
| Llama 3.3 | Meta | 生态最完善,社区支持最强,工具链成熟 | 通用任务、企业部署、微调定制 |
| Mistral | Mistral AI | 推理效率极高,MoE 架构创新 | 高并发场景、资源受限环境 |
| Gemma 2 | 轻量但性能不俗,谷歌生态集成 | 移动/边缘设备、研究实验 | |
| Qwen | 阿里巴巴 | 中文能力顶尖,代码能力强 | 中文应用、编程助手 |
| Phi | 微软 | 体积小、质量高,教科书级训练数据 | 教育场景、低资源部署 |
一个关键的认知转变
对于初学者来说,最需要理解的一点是:开源模型 ≠ 落后模型。
以 Llama 3.3 70B 为例,它在多项基准测试中已经接近 GPT-4 的早期版本。而 Mistral 的 Mixtral 8x7B 模型采用的混合专家架构(Mixture of Experts),更是用不到一半的计算资源实现了相当的质量水平。这意味着,你完全可以在自己的服务器上运行一个媲美 ChatGPT 的模型,而不需要支付每千字几分钱的 API 费用。
本地化部署的意义
选择开源 LLM 不仅仅是成本考量。数据隐私、离线可用性、定制化能力和长期可控性是企业级应用的四大刚需。当医疗、金融、法律等敏感行业的数据不能离开内网时,开源 LLM 就成了唯一的选择。
第二层:数据与检索层(Data and Retrieval)——智能应用的记忆系统
有了大脑,还需要记忆。人类专家之所以专业,不仅因为他们聪明,更因为他们掌握了大量的领域知识。AI 应用也是如此——没有高质量的数据支撑,再强大的模型也只是"泛泛而谈"的空谈者。
这一层解决的核心问题是:如何让 AI 记住并检索你的私有数据?
向量数据库:AI 的"长期记忆"
图中的五个项目代表了两种技术路线:
专用向量数据库:
- Milvus:企业级分布式向量数据库,支持十亿级向量检索,适合大规模生产环境
- Weaviate:内置语义搜索和向量化能力,开发者体验优秀,GraphQL 接口友好
- FAISS:Facebook 开源的高效相似度搜索库,单机性能极强,适合嵌入应用内部
传统数据库的向量扩展:
- Postgres + PGVector:在世界上最流行的关系型数据库上直接扩展向量能力,适合已有 PostgreSQL 基础设施的团队
为什么这一层如此重要?
想象你在构建一个法律助手。通用 LLM 虽然懂一些法律知识,但它不知道你们律所的案例库、不知道你经手的具体案件、不了解你们团队的办案风格。向量数据库的作用,就是把这些私有知识"注入"到 AI 的记忆中,让它在回答问题时能够参考你的专属资料。
这就是**RAG(检索增强生成)**技术的核心:先将你的文档切分成片段,转化为向量存入数据库;当用户提问时,系统先检索最相关的片段,再让 LLM 基于这些片段生成答案。这样既保证了回答的准确性,又避免了幻觉问题。
第三层:后端与模型访问层(Backend and Model Access)——连接一切的神经系统
大脑和记忆都有了,但如何让它们协同工作?这就是后端与模型访问层的职责——它是整个技术栈的"神经系统",负责协调数据流、管理模型调用、处理业务逻辑。
五个核心项目的分工
| 项目 | 角色定位 | 核心价值 |
|---|---|---|
| LangChain | LLM 应用开发框架 | 将模型、数据、工具串联成链式工作流 |
| Hugging Face | 模型托管与推理平台 | 开源模型的"GitHub",提供海量预训练模型 |
| FastAPI | 高性能 API 框架 | 用 Python 快速构建模型服务接口 |
| Ollama | 本地模型运行工具 | 一行命令在本地运行任何开源 LLM |
| Netflix Metaflow | ML 工作流编排 | 管理从数据准备到模型部署的完整流水线 |
从入门到生产的路径
对于初学者,Ollama 是最佳的起点。你只需要在终端输入 ollama run llama3.3,就能在本地下载并运行 Llama 3.3 模型。不需要配置 GPU 集群,不需要编写复杂的推理代码,它帮你处理了模型下载、量化压缩、推理服务化等所有繁琐工作。
当你开始构建更复杂的应用时,LangChain 就成了不可或缺的伙伴。它提供了一整套抽象,让你可以轻松地将文档加载、向量检索、模型调用、输出解析等环节串联起来。比如,一个 RAG 应用的核心逻辑在 LangChain 中只需要十几行代码就能实现。
FastAPI 则负责将这些能力包装成标准的 REST API,让你的前端应用或其他服务能够方便地调用。Hugging Face 不仅是模型的托管平台,它的 Transformers 库和推理 API 让模型调用变得异常简单。
而当你的应用进入生产环境,需要处理大规模数据和复杂的训练流水线时,Netflix Metaflow 这样的工作流编排工具则能确保整个过程的可复现性和可扩展性。
第四层:嵌入与 RAG 库层(Embeddings and RAG Libraries)——知识增强的加速器
第三层提供了基础框架,第四层则提供了专门优化 RAG 和嵌入技术的工具库。这一层是整个技术栈中最新兴、也最具创新活力的部分。
从"能用"到"好用"的跨越
基础的 RAG 实现很简单——切分文档、生成向量、相似度检索、送入 LLM 生成答案。但在实际应用中,你会遇到无数细节问题:
- 文档切分得太粗,关键信息被淹没;切分得太细,上下文丢失
- 用户的问题和文档的表述方式不同,导致检索不到相关内容
- 检索到的内容中包含过时或矛盾的信息
- 不同领域的数据需要不同的嵌入模型
这就是 Nomic、Cognita、LLMWare 和 Jina AI 要解决的问题。
四个项目的差异化定位
Nomic:以 Nomic Embed 嵌入模型闻名,这是第一个在 MTEB 基准上超越 OpenAI Ada-002 的开源嵌入模型。Nomic 的核心信念是"嵌入模型应该像 LLM 一样被认真对待"——它们也需要大规模高质量的训练数据和严格的评估标准。
Cognita:一个面向生产环境的 RAG 框架,强调模块化和可扩展性。它允许你轻松替换嵌入模型、向量数据库、重排序器等组件,就像搭积木一样定制你的 RAG pipeline。
LLMWare:专注于企业文档处理,特别适合处理 PDF、Word、PPT 等非结构化文档。它内置了 OCR、表格提取、文档解析等能力,让"把一堆企业文档变成知识库"这件事变得简单。
Jina AI:提供了完整的神经搜索基础设施,从嵌入生成到多模态检索一应俱全。它的特色在于多模态能力——不仅能处理文本,还能处理图像、音频、视频等多种数据类型。
嵌入模型的选择策略
初学者常犯的一个错误是:随便选一个嵌入模型就用。实际上,嵌入模型的选择直接影响 RAG 的效果。通用场景下,Nomic Embed 或 BGE(智源)是不错的选择;中文场景下,应该选择专门在中文语料上训练过的模型;代码检索则需要 CodeBERT 或类似的代码专用嵌入模型。
第五层:前端层(Frontend)——用户与 AI 的交互窗口
技术栈的最顶层是前端层——这是用户直接接触的部分,决定了你的 AI 应用给人什么样的第一印象。
AI 应用的前端有什么不同?
传统的前端开发关注的是信息展示和用户操作。AI 应用的前端则需要额外处理:
- 流式响应:LLM 生成文本是一个字一个字"流"出来的,前端需要实时展示
- 对话管理:维护多轮对话的上下文,支持历史记录查看
- 富文本交互:代码高亮、Markdown 渲染、引用溯源等功能
- 多模态输入/输出:支持图片、语音、文件的输入和展示
三个前端方案的选择
Next.js + Vercel:这是构建生产级 AI Web 应用的黄金组合。Next.js 的 Server Actions 让你可以直接在后端调用 AI 模型,Vercel 的 AI SDK 提供了流式响应的现成解决方案,Vercel Edge Network 则确保全球低延迟访问。如果你要构建一个面向用户的 AI 产品,这是首选方案。
Streamlit:数据科学家和 AI 原型开发者的最爱。用纯 Python 就能构建出漂亮的交互界面,不需要写一行 HTML/CSS。它的座右铭是"让数据脚本变成可共享的应用"。如果你需要快速验证一个 AI 想法,或者构建内部使用的数据工具,Streamlit 能让你在几小时内完成从代码到可访问应用的转变。
两者的关系可以这样理解:Streamlit 负责快速验证和内部工具,Next.js + Vercel 负责面向用户的生产级产品。
五层协同:为什么完整的技术栈如此重要
理解了每一层的独立作用后,更重要的是理解它们的协同效应。一个完整的开源 AI 技术栈意味着什么?
类比:构建一所医院
- LLM 层 = 医学院培养出来的医生(具备基础医学知识)
- 数据层 = 医院的病历库和医学文献库(专科知识和历史案例)
- 后端层 = 医院的挂号、分诊、检验、手术安排系统(流程协调)
- RAG 层 = 专科诊断指南和检验标准(提升诊断准确率的工具和方法)
- 前端层 = 医院的门诊大厅和诊室(患者接触的部分)
没有病历库,再好的医生也只能凭经验看病;没有高效的医院管理系统,再多资源也会混乱;没有舒适的就诊环境,患者体验就会大打折扣。每一层都不可替代,每一层都值得精心挑选。
开源栈 vs 闭源栈
| 维度 | 开源技术栈 | 闭源方案(如 OpenAI API) |
|---|---|---|
| 成本 | 硬件投入 + 运维人力 | 按使用量付费,规模越大越贵 |
| 数据隐私 | 数据完全本地化,零泄露风险 | 数据需传输至第三方服务器 |
| 定制化 | 模型可微调,系统可深度改造 | 只能调整提示词和参数 |
| 可控性 | 不依赖任何单一供应商 | 受限于供应商的政策和价格变动 |
| 上手难度 | 需要一定的工程能力 | 几行代码即可调用 |
| 社区支持 | 活跃的开发者社区,丰富的教程 | 官方文档和专业支持 |
关键洞察:开源和闭源不是非此即彼的选择。许多成功的 AI 应用采用混合策略——用开源模型处理敏感数据和常规任务,用商业 API 处理需要顶尖性能的复杂任务。
实战指南:如何选择你的第一套开源 AI 技术栈
面对这么多选择,初学者往往会感到不知所措。以下是针对不同场景的推荐组合:
场景一:快速体验(零基础,想先看看效果)
Ollama(运行 Llama 3.3) + Streamlit
预计时间:30 分钟内跑通
硬件要求:8GB 以上内存(CPU 即可,有 GPU 更好)
学习重点:理解 LLM 的基本交互方式
场景二:个人知识库(想让 AI 读我的文档并回答)
Ollama(运行 Llama 3.3) + LangChain + PGVector + Nomic Embed + Streamlit
预计时间:1-2 天
硬件要求:16GB 内存 + 10GB 存储
学习重点:RAG 原理、向量检索、文档处理
场景三:面向用户的产品(要上线给其他人用)
Llama 3.3(云端部署) + Milvus + LangChain + Cognita + Next.js + Vercel
预计时间:2-4 周
硬件要求:云服务器(推荐至少一张 NVIDIA T4 GPU)
学习重点:系统架构设计、高并发处理、模型优化
场景四:企业内部助手(处理敏感业务数据)
Qwen(或 Llama 3.3 微调版) + Milvus + LLMWare + FastAPI + Next.js
预计时间:1-3 个月
硬件要求:企业内部 GPU 服务器或私有化云部署
学习重点:模型微调、企业安全合规、系统集成
未来展望:开源 AI 技术栈的演进方向
站在 2025 年观察这个技术栈,我们可以清晰地看到三个演进趋势:
趋势一:模型层将进一步"商品化"
随着更多高质量开源模型的出现(如 DeepSeek、Command R+ 等),模型的差异化将不再是应用成功的关键。如何用好模型——通过 RAG、微调、Agent 架构等手段——将成为核心竞争力。
趋势二:RAG 将进化为 “Agent + 工具调用”
简单的文档问答正在向更复杂的AI Agent演进。未来的 AI 应用不仅能检索知识,还能调用 API、执行代码、操作数据库、发送邮件——真正成为能完成端到端任务的数字助手。LangChain 的 Agent 框架和 Cognita 的模块化设计正是为这一趋势做准备。
趋势三:前端将重新定义人机交互
AI 应用的前端正在经历一场静默的革命。从 ChatGPT 的对话界面到 Claude 的Artifacts,从 Perplexity 的引用溯源到 Vercel 的流式响应组件,新一代用户界面正在形成。谁能设计出最自然、最高效的人机协作界面,谁就将在下一代应用竞争中占据优势。
结语:属于开发者的 AI 民主化时代
回到那张技术栈全景图。它不仅仅是一张工具清单,更是开源社区写给全世界开发者的一封信:AI 不再是少数人的特权,每一个人都可以参与构建智能应用。
从 Meta 开源 Llama 的那一刻起,AI 的"安卓时刻"就已经到来。就像安卓让智能手机从 iPhone 的追赶者变成了全球数十亿人的数字入口,开源 AI 技术栈正在让智能应用从科技巨头的展厅走进每一个开发者的电脑。
你不需要 billion 级的预算,不需要数百人的研究团队。你只需要一台电脑、一颗好奇的心,以及这张地图作为指引。
开始构建吧。未来属于那些动手的人。
延伸阅读与资源
10倍开发者的 Dify 魔法书:从零构建全栈 AI 应用
后端工程师转型AI第一课-Ollama 与私有化大模型实战

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)